I problemi di concorrenza sono difficili allo stesso modo in cui lo è la programmazione multi-thread. A meno che non venga utilizzato l'isolamento serializzabile, può essere difficile codificare transazioni T-SQL che funzioneranno sempre correttamente quando altri utenti apportano modifiche al database contemporaneamente.
I potenziali problemi possono essere non banali anche se la 'transazione' in questione è una semplice SELECT dichiarazione. Per transazioni complesse con più istruzioni che leggono e scrivono dati, il potenziale di risultati ed errori imprevisti in condizioni di elevata simultaneità può diventare rapidamente schiacciante. Tentare di risolvere problemi di simultaneità sottili e difficili da riprodurre applicando suggerimenti di blocco casuali o altri metodi per tentativi ed errori può essere un'esperienza estremamente frustrante.
Per molti aspetti, il livello di isolamento dello snapshot sembra una soluzione perfetta a questi problemi di concorrenza. L'idea di base è che ogni transazione snapshot si comporti come se fosse eseguita sulla propria copia privata dello stato di commit del database, presa nel momento in cui la transazione è iniziata. Fornire all'intera transazione una visione immutabile dei dati impegnati garantisce ovviamente risultati coerenti per le operazioni di sola lettura, ma per quanto riguarda le transazioni che modificano i dati?
L'isolamento dello snapshot gestisce le modifiche ai dati in modo ottimistico, presumendo implicitamente che i conflitti tra autori simultanei saranno relativamente rari. Quando si verifica un conflitto di scrittura, il primo committer vince e la transazione perdente ha il rollback delle modifiche. Ovviamente è un peccato per la transazione di rollback, ma se si tratta di un evento abbastanza raro, i vantaggi dell'isolamento degli snapshot possono facilmente superare i costi di un errore occasionale e di un nuovo tentativo.
La semantica relativamente semplice e pulita dell'isolamento degli snapshot (rispetto alle alternative) può essere un vantaggio significativo, in particolare per le persone che non lavorano esclusivamente nel mondo dei database e quindi non conoscono bene i vari livelli di isolamento. Anche per i professionisti esperti di database, un livello di isolamento relativamente "intuitivo" può essere un gradito sollievo.
Naturalmente, le cose raramente sono così semplici come appaiono all'inizio e l'isolamento delle istantanee non fa eccezione. La documentazione ufficiale fa un ottimo lavoro nel descrivere i principali vantaggi e svantaggi dell'isolamento degli snapshot, quindi la maggior parte di questo articolo si concentra sull'esplorazione di alcuni dei problemi meno noti e sorprendenti che potresti incontrare. Prima, però, una rapida occhiata alle proprietà logiche di questo livello di isolamento:
Proprietà ACIDO e isolamento istantanee
L'isolamento dello snapshot non è uno dei livelli di isolamento definiti nello standard SQL, ma viene ancora spesso confrontato utilizzando i "fenomeni di concorrenza" ivi definiti. Ad esempio, la tabella di confronto seguente è riprodotta dall'articolo tecnico di SQL Server "SQL Server 2005 Row Versioning-Based Transaction Isolation" di Kimberly L. Tripp e Neal Graves:
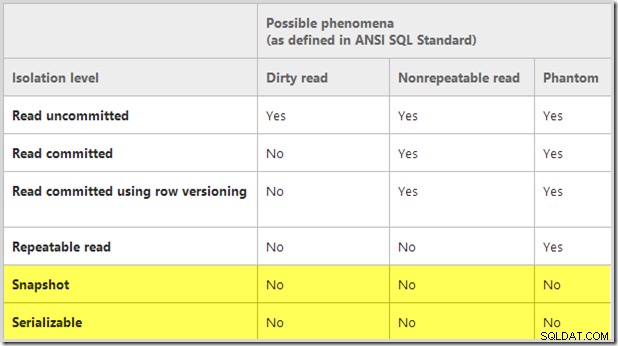
Fornendo una visualizzazione puntuale di dati impegnati , l'isolamento dello snapshot fornisce protezione contro tutti e tre i fenomeni di simultaneità mostrati. Le letture sporche vengono impedite perché sono visibili solo i dati sottoposti a commit e la natura statica dello snapshot impedisce il rilevamento di letture non ripetibili e fantasmi.
Tuttavia, questo confronto (e in particolare la sezione evidenziata) mostra solo che i livelli di isolamento snapshot e serializzabili prevengono gli stessi tre fenomeni specifici. Ciò non significa che siano equivalenti sotto tutti gli aspetti. È importante sottolineare che lo standard SQL-92 non definisce l'isolamento serializzabile in termini di soli tre fenomeni. La sezione 4.28 della norma fornisce la definizione completa:
L'esecuzione di transazioni SQL simultanee a livello di isolamento SERIALIZABLE è garantita per essere serializzabile. Un'esecuzione serializzabile è definita come un'esecuzione delle operazioni di esecuzione simultanea di transazioni SQL che producono lo stesso effetto di alcune esecuzioni seriali di quelle stesse transazioni SQL. Un'esecuzione seriale è quella in cui ogni transazione SQL viene eseguita fino al completamento prima dell'inizio della transazione SQL successiva.
L'entità e l'importanza delle garanzie implicite in questo caso vengono spesso trascurate. Per dirlo in un linguaggio semplice:
Qualsiasi transazione serializzabile eseguita correttamente quando eseguita da sola continuerà a essere eseguita correttamente con qualsiasi combinazione di transazioni simultanee, oppure verrà eseguito il rollback con un messaggio di errore (in genere un deadlock nell'implementazione di SQL Server).
I livelli di isolamento non serializzabili, incluso l'isolamento degli snapshot, non forniscono le stesse forti garanzie di correttezza.
Dati obsoleti
L'isolamento delle istantanee sembra quasi seducente. Le letture provengono sempre da dati impegnati in un singolo momento e i conflitti di scrittura vengono rilevati e gestiti automaticamente. In che modo questa non è una soluzione perfetta per tutte le difficoltà legate alla concorrenza?
Un potenziale problema è che le letture di snapshot non riflettono necessariamente lo stato di commit corrente del database. Una transazione snapshot ignora completamente tutte le modifiche salvate apportate da altre transazioni simultanee dopo l'inizio della transazione snapshot. Un altro modo per dirlo è dire che una transazione snapshot vede dati obsoleti e non aggiornati. Sebbene questo comportamento possa essere esattamente ciò che è necessario per generare un rapporto puntuale accurato, potrebbe non essere altrettanto adatto in altre circostanze (ad esempio, quando viene utilizzato per applicare una regola in un trigger).
Scrivi inclinazione
L'isolamento dello snapshot è anche vulnerabile a un fenomeno in qualche modo correlato noto come write skew. La lettura di dati obsoleti ha un ruolo in questo, ma questo problema aiuta anche a chiarire cosa fa e cosa non fa lo snapshot "rilevamento dei conflitti di scrittura".
L'inclinazione di scrittura si verifica quando due transazioni simultanee leggono ciascuna i dati che l'altra transazione modifica. Non si verifica alcun conflitto di scrittura perché le due transazioni modificano righe diverse. Nessuna delle transazioni vede le modifiche apportate dall'altra, perché entrambe stanno leggendo da un momento prima che fossero apportate tali modifiche.
Un classico esempio di scrittura obliqua è il problema del marmo bianco e nero, ma voglio mostrare un altro semplice esempio qui:
-- Create two empty tables CREATE TABLE A (x integer NOT NULL); CREATE TABLE B (x integer NOT NULL); -- Connection 1 SET TRANSACTION ISOLATION LEVEL SNAPSHOT; BEGIN TRANSACTION; INSERT A (x) SELECT COUNT_BIG(*) FROM B; -- Connection 2 SET TRANSACTION ISOLATION LEVEL SNAPSHOT; BEGIN TRANSACTION; INSERT B (x) SELECT COUNT_BIG(*) FROM A; COMMIT TRANSACTION; -- Connection 1 COMMIT TRANSACTION;
Sotto l'isolamento dello snapshot, entrambe le tabelle in quello script finiscono con una singola riga contenente un valore zero. Questo è un risultato corretto, ma non serializzabile:non corrisponde a nessun eventuale ordine di esecuzione della transazione seriale. In qualsiasi pianificazione veramente seriale, una transazione deve essere completata prima dell'inizio dell'altra, quindi la seconda transazione conteggerebbe la riga inserita dalla prima. Potrebbe sembrare un tecnico, ma ricorda che le potenti garanzie serializzabili si applicano solo quando le transazioni sono veramente serializzabili.
Una sottigliezza nel rilevamento dei conflitti
Un conflitto di scrittura di snapshot si verifica ogni volta che una transazione di snapshot tenta di modificare una riga che è stata modificata da un'altra transazione che ha eseguito il commit dopo l'inizio della transazione di snapshot. Ci sono due sottigliezze qui:
- Le transazioni in realtà non devono cambiare eventuali valori di dati; e
- Le transazioni non devono modificare alcuna colonna comune .
Lo script seguente mostra entrambi i punti:
-- Test table
CREATE TABLE dbo.Conflict
(
ID1 integer UNIQUE,
Value1 integer NOT NULL,
ID2 integer UNIQUE,
Value2 integer NOT NULL
);
-- Insert one row
INSERT dbo.Conflict
(ID1, ID2, Value1, Value2)
VALUES
(1, 1, 1, 1);
-- Connection 1
BEGIN TRANSACTION;
UPDATE dbo.Conflict
SET Value1 = 1
WHERE ID1 = 1;
-- Connection 2
SET TRANSACTION ISOLATION LEVEL SNAPSHOT;
BEGIN TRANSACTION;
UPDATE dbo.Conflict
SET Value2 = 1
WHERE ID2 = 1;
-- Connection 1
COMMIT TRANSACTION; Si noti quanto segue:
- Ogni transazione individua la stessa riga utilizzando un indice diverso
- Nessuno dei due aggiornamenti comporta una modifica ai dati già archiviati
- Le due transazioni "aggiornano" diverse colonne nella riga.
Nonostante tutto, quando la prima transazione viene confermata, la seconda transazione termina con un errore di conflitto di aggiornamento:
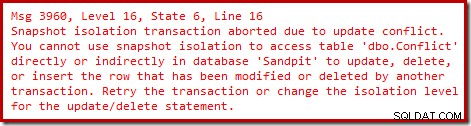
Riepilogo:il rilevamento dei conflitti opera sempre a livello di un'intera riga e un "aggiornamento" non deve modificare effettivamente alcun dato. (Nel caso te lo stavi chiedendo, anche le modifiche ai dati LOB o SLOB fuori riga contano come una modifica alla riga ai fini del rilevamento dei conflitti).
Il problema della chiave esterna
Il rilevamento dei conflitti si applica anche alla riga padre in una relazione di chiave esterna. Quando si modifica una riga figlio con isolamento snapshot, una modifica alla riga padre in un'altra transazione può attivare un conflitto. Come in precedenza, questa logica si applica all'intera riga padre:l'aggiornamento padre non deve influire sulla colonna della chiave esterna stessa. Qualsiasi operazione sulla tabella figlio che richiede un controllo automatico della chiave esterna nel piano di esecuzione può causare un conflitto imprevisto.
Per dimostrarlo, crea prima le seguenti tabelle e dati di esempio:
CREATE TABLE dbo.Dummy
(
x integer NULL
);
CREATE TABLE dbo.Parent
(
ParentID integer PRIMARY KEY,
ParentValue integer NOT NULL
);
CREATE TABLE dbo.Child
(
ChildID integer PRIMARY KEY,
ChildValue integer NOT NULL,
ParentID integer NULL FOREIGN KEY REFERENCES dbo.Parent
);
INSERT dbo.Parent
(ParentID, ParentValue)
VALUES (1, 1);
INSERT dbo.Child
(ChildID, ChildValue, ParentID)
VALUES (1, 1, 1); Ora esegui quanto segue da due connessioni separate come indicato nei commenti:
-- Connection 1 SET TRANSACTION ISOLATION LEVEL SNAPSHOT; BEGIN TRANSACTION; SELECT COUNT_BIG(*) FROM dbo.Dummy; -- Connection 2 (any isolation level) UPDATE dbo.Parent SET ParentValue = 1 WHERE ParentID = 1; -- Connection 1 UPDATE dbo.Child SET ParentID = NULL WHERE ChildID = 1; UPDATE dbo.Child SET ParentID = 1 WHERE ChildID = 1;
La lettura dalla tabella fittizia è lì per garantire che la transazione snapshot sia ufficialmente iniziata. Emissione di BEGIN TRANSACTION non è sufficiente per farlo; dobbiamo eseguire una sorta di accesso ai dati su una tabella utente.
Il primo aggiornamento della tabella Child non causa un conflitto perché l'impostazione della colonna di riferimento su NULL non richiede un controllo della tabella padre nel piano di esecuzione (non c'è nulla da controllare). Il Query Processor non tocca la riga padre nel piano di esecuzione, quindi non si verifica alcun conflitto.
Il secondo aggiornamento della tabella Child attiva un conflitto perché viene eseguito automaticamente un controllo della chiave esterna. Quando il Query Processor accede alla riga padre, viene verificata anche la presenza di un conflitto di aggiornamento. In questo caso viene generato un errore perché la riga padre di riferimento ha subito una modifica confermata dopo l'avvio della transazione snapshot. Nota che la modifica della tabella padre non ha influito sulla colonna della chiave esterna stessa.
Un conflitto imprevisto può verificarsi anche se una modifica alla tabella Figlio fa riferimento a una riga padre che è stata creata da una transazione simultanea (e quella transazione salvata dopo l'avvio della transazione snapshot).
Riepilogo:un piano di query che include un controllo automatico della chiave esterna può generare un errore di conflitto se la riga di riferimento ha subito qualsiasi tipo di modifica (compresa la creazione!) dall'inizio della transazione dello snapshot.
Il problema del troncamento della tabella
Una transazione snapshot avrà esito negativo con un errore se una tabella a cui accede è stata troncata dall'inizio della transazione. Questo vale anche se la tabella troncata non aveva righe con cui iniziare, come dimostra lo script seguente:
CREATE TABLE dbo.AccessMe
(
x integer NULL
);
CREATE TABLE dbo.TruncateMe
(
x integer NULL
);
-- Connection 1
SET TRANSACTION ISOLATION LEVEL SNAPSHOT;
BEGIN TRANSACTION;
SELECT COUNT_BIG(*) FROM dbo.AccessMe;
-- Connection 2
TRUNCATE TABLE dbo.TruncateMe;
-- Connection 1
SELECT COUNT_BIG(*) FROM dbo.TruncateMe; La SELECT finale non riesce con un errore:

Questo è un altro sottile effetto collaterale da verificare prima di abilitare l'isolamento dello snapshot su un database esistente.
La prossima volta
Il prossimo (e ultimo) post di questa serie parlerà del livello di isolamento non vincolato di lettura (affettuosamente noto come "nolock").
[Vedi l'indice per l'intera serie]