Nei miei post di quest'anno ho discusso delle reazioni istintive a vari tipi di attesa, e in questo post continuerò con il tema delle statistiche di attesa e discuterò il PAGEIOLATCH_XX aspettare. Dico "aspetta" ma ci sono davvero diversi tipi di PAGEIOLATCH waits, che ho indicato con i XX alla fine. Gli esempi più comuni sono:
PAGEIOLATCH_SH– (SH sono) in attesa che una pagina di un file di dati venga portata dal disco nel pool di buffer in modo che il suo contenuto possa essere lettoPAGEIOLATCH_EXoPAGEIOLATCH_UP– (EX clusive o UP data) in attesa che una pagina di un file di dati venga portata dal disco nel pool di buffer in modo che il suo contenuto possa essere modificato
Di questi, il tipo di gran lunga più comune è PAGEIOLATCH_SH .
Quando questo tipo di attesa è il più diffuso su un server, la reazione istintiva è che il sottosistema di I/O deve avere un problema e quindi è lì che dovrebbero concentrarsi le indagini.
La prima cosa da fare è confrontare il PAGEIOLATCH_SH conteggio delle attese e durata rispetto alla linea di base. Se il volume delle attese è più o meno lo stesso, ma la durata di ogni attesa di lettura è diventata molto più lunga, allora sarei preoccupato per un problema del sottosistema di I/O, come ad esempio:
- Una configurazione errata/malfunzionamento a livello di sottosistema di I/O
- Latenza di rete
- Un altro carico di lavoro di I/O che causa conflitti con il nostro carico di lavoro
- Configurazione della replica/mirroring del sottosistema di I/O sincroni
Nella mia esperienza, lo schema è spesso il numero di PAGEIOLATCH_SH le attese sono aumentate sostanzialmente rispetto alla quantità di base (normale) ed è aumentata anche la durata dell'attesa (ovvero è aumentato il tempo per un I/O di lettura), poiché il numero elevato di letture sovraccarica il sottosistema di I/O. Questo non è un problema del sottosistema di I/O:SQL Server guida più I/O di quanto dovrebbe essere. L'attenzione ora deve passare a SQL Server per identificare la causa degli I/O aggiuntivi.
Cause di un numero elevato di I/O di lettura
SQL Server dispone di due tipi di letture:I/O logici e I/O fisici. Quando la parte dei metodi di accesso del motore di archiviazione deve accedere a una pagina, chiede al pool di buffer un puntatore alla pagina in memoria (denominata I/O logico) e il pool di buffer controlla i suoi metadati per vedere se quella pagina è già in memoria.
Se la pagina è in memoria, il pool di buffer fornisce il puntatore ai metodi di accesso e l'I/O rimane un I/O logico. Se la pagina non è in memoria, il Buffer Pool emette un I/O "reale" (chiamato I/O fisico) e il thread deve attendere il completamento, incorrendo in un PAGEIOLATCH_XX aspettare. Una volta completato l'I/O e il puntatore è disponibile, il thread viene notificato e può continuare a funzionare.
In un mondo ideale, l'intero carico di lavoro si adatterebbe alla memoria e quindi una volta che il pool di buffer si è "riscaldato" e contiene tutto il carico di lavoro, non sono necessarie più letture, ma solo scritture di dati aggiornati. Tuttavia, non è un mondo ideale e la maggior parte di voi non ha quel lusso, quindi alcune letture sono inevitabili. Finché il numero di letture rimane intorno all'importo di base, non ci sono problemi.
Quando è necessario un numero elevato di letture improvvisamente e inaspettatamente, è un segno che c'è un cambiamento significativo nel carico di lavoro, nella quantità di memoria del pool di buffer disponibile per l'archiviazione di copie in memoria delle pagine o in entrambi.
Ecco alcune possibili cause principali (elenco non esaustivo):
- La pressione della memoria di Windows esterna su SQL Server fa sì che il gestore della memoria riduca le dimensioni del pool di buffer
- Pianifica il rigonfiamento della cache causando il prestito di memoria aggiuntiva dal pool di buffer
- Un piano di query che esegue una scansione dell'indice di tabella/cluster (invece di una ricerca di indice) a causa di:
- un aumento del volume del carico di lavoro
- un problema di sniffing dei parametri
- un indice non cluster obbligatorio che è stato eliminato o modificato
- una conversione implicita
Un modello da cercare che suggerirebbe una scansione dell'indice di tabella/cluster come causa è anche vedere un gran numero di CXPACKET attende insieme a PAGEIOLATCH_SH aspetta. Questo è un modello comune che indica che si verificano grandi scansioni di tabelle parallele/indici cluster.
In tutti i casi, puoi guardare quale piano di query sta causando il PAGEIOLATCH_SH attende utilizzando sys.dm_os_waiting_tasks e altri DMV, e puoi ottenere il codice per farlo nel mio post sul blog qui. Se disponi di uno strumento di monitoraggio di terze parti, potrebbe essere in grado di aiutarti a identificare il colpevole senza sporcarti le mani.
Esempio di flusso di lavoro con SQL Sentry e Plan Explorer
In un esempio semplice (ovviamente artificioso), supponiamo di essere su un sistema client che utilizza la suite di strumenti di SQL Sentry e di vedere un picco nelle attese di I/O nella visualizzazione dashboard di SQL Sentry, come mostrato di seguito:
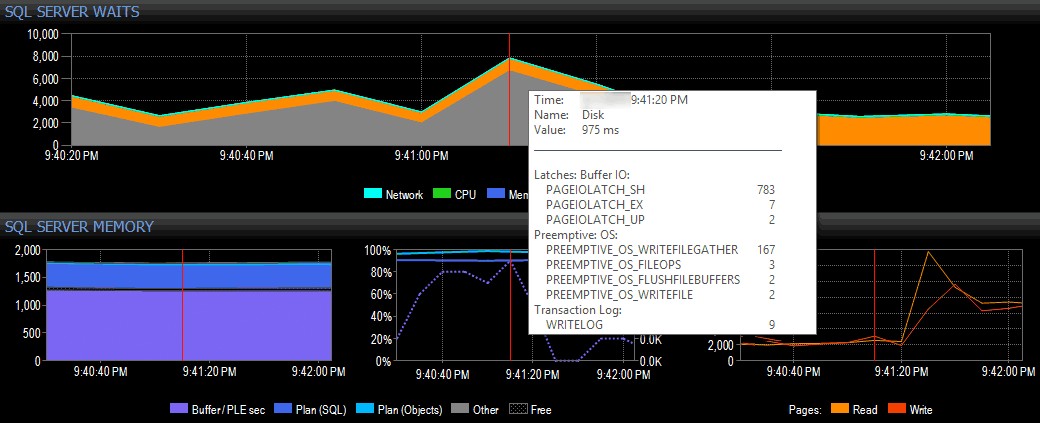
Rilevare un picco nelle attese di I/O in SQL Sentry
Decido di indagare facendo clic con il pulsante destro del mouse su un intervallo di tempo selezionato attorno all'ora del picco, quindi passando alla vista SQL superiore, che mi mostrerà le query più costose che sono state eseguite:
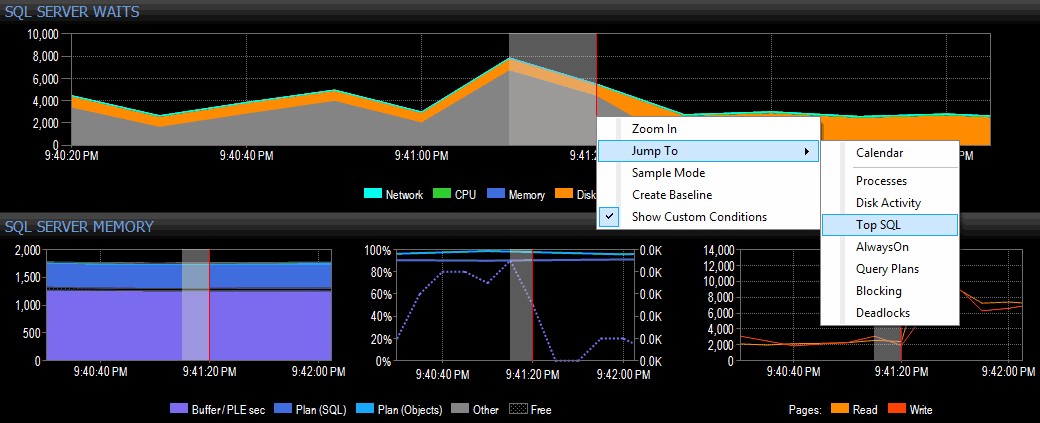
Evidenziazione di un intervallo di tempo e navigazione in Top SQL
In questa visualizzazione, posso vedere quali query di I/O con esecuzione prolungata o elevato erano in esecuzione nel momento in cui si è verificato il picco, quindi scegliere di approfondire i loro piani di query (in questo caso, esiste solo una query di lunga durata, che ha funzionato per quasi un minuto):
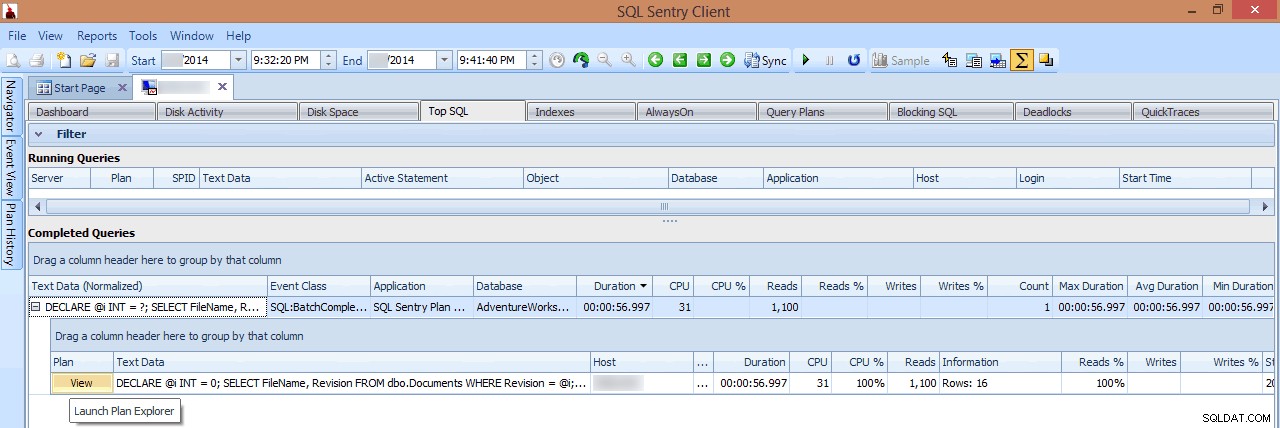
Revisione di una query di lunga durata in Top SQL
Se guardo il piano nel client SQL Sentry o lo apro in SQL Sentry Plan Explorer, vedo immediatamente più problemi. Il numero di letture necessarie per restituire 7 righe sembra troppo elevato, il delta tra le righe stimate e quelle effettive è elevato e il piano mostra una scansione dell'indice che si verifica dove mi sarei aspettato una ricerca:
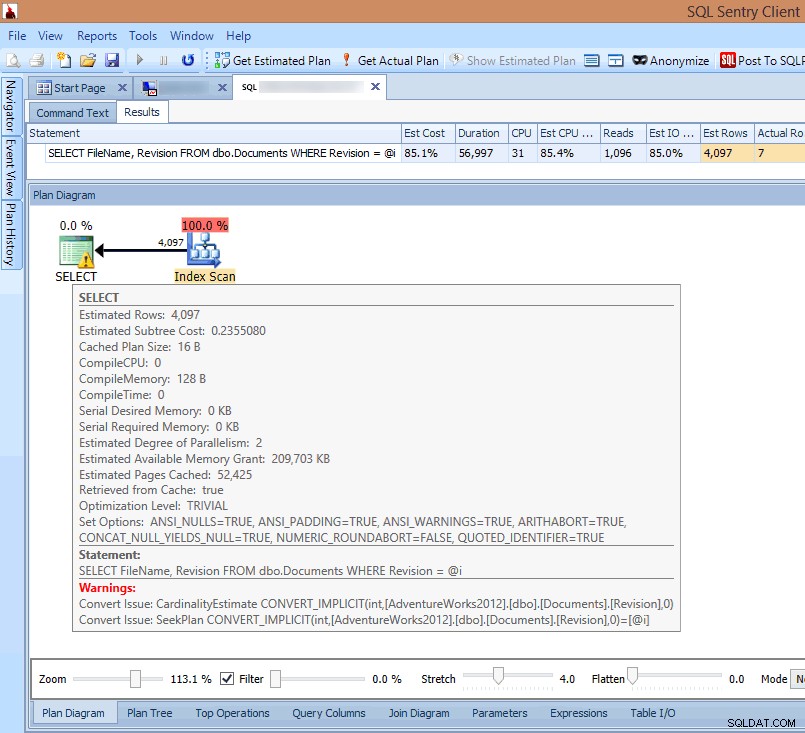
Visualizzazione degli avvisi di conversione implicita nel piano di query
La causa di tutto ciò è evidenziata nell'avviso sul SELECT operatore:È una conversione implicita!
Le conversioni implicite sono un problema insidioso causato da una mancata corrispondenza tra il tipo di dati del predicato di ricerca e il tipo di dati della colonna in cui viene eseguita la ricerca o un calcolo eseguito sulla colonna della tabella anziché sul predicato di ricerca. In entrambi i casi, SQL Server non può utilizzare una ricerca dell'indice nella colonna della tabella e deve invece utilizzare un'analisi.
Questo può apparire in un codice apparentemente innocente e un esempio comune utilizza un calcolo della data. Se hai una tabella che memorizza l'età dei clienti e vuoi eseguire un calcolo per vedere quanti hanno 21 anni o più oggi, potresti scrivere un codice come questo:
WHERE DATEADD (YEAR, 21, [MyTable].[BirthDate]) <= @today;
Con questo codice, il calcolo si trova sulla colonna della tabella e quindi non è possibile utilizzare una ricerca dell'indice, risultando in un'espressione non ricercabile (tecnicamente nota come espressione non SARGable) e una scansione dell'indice di tabella/cluster. Questo può essere risolto spostando il calcolo sull'altro lato dell'operatore:
WHERE [MyTable].[BirthDate] <= DATEADD (YEAR, -21, @today);
In termini di quando un confronto di colonne di base richiede una conversione del tipo di dati che può causare una conversione implicita, il mio collega Jonathan Kehayias ha scritto un eccellente post sul blog che confronta ogni combinazione di tipi di dati e note quando sarà necessaria una conversione implicita.
Riepilogo
Non cadere nella trappola di pensare quell'eccessivo PAGEIOLATCH_XX le attese sono causate dal sottosistema di I/O. In base alla mia esperienza, di solito sono causati da qualcosa che ha a che fare con SQL Server ed è qui che inizierei la risoluzione dei problemi.
Per quanto riguarda le statistiche generali sull'attesa, puoi trovare ulteriori informazioni sull'utilizzo per la risoluzione dei problemi relativi alle prestazioni in:
- Le mie serie di post sul blog SQLskills, a partire dalle statistiche di attesa, o per favore dimmi dove fa male
- La mia libreria Tipi di attesa e classi Latch qui
- Il mio corso di formazione online Pluralsight SQL Server:risoluzione dei problemi delle prestazioni utilizzando le statistiche di attesa
- Sentiera SQL
Nel prossimo articolo della serie, parlerò di un altro tipo di attesa che è una causa comune di reazioni istintive. Fino ad allora, buona risoluzione dei problemi!