La configurazione di un cluster di replica master/slave è un caso d'uso comune nella maggior parte delle organizzazioni. L'utilizzo di MySQL Replication consente la replica dei dati in ambienti diversi e garantisce che le informazioni vengano copiate. È asincrono e a thread singolo (per impostazione predefinita), ma la replica consente anche di configurarlo in modo che sia sincrono (o effettivamente "semi-sincrono") e può eseguire thread slave su più thread o in parallelo.
Questa idea è molto comune e di solito arriva con una semplice configurazione, rendendo il suo slave che funge da ripristino o per soluzioni di backup. Tuttavia, questo ha sempre un prezzo, specialmente quando vengono replicate query errate (come la mancanza di chiavi primarie o univoche) o alcuni problemi con l'hardware (come problemi di I/O di rete o disco). Quando si verificano questi problemi, il problema più comune da affrontare è il ritardo di replica.
Un ritardo di replica è il costo del ritardo per le transazioni o operazioni calcolato dalla differenza di tempo di esecuzione tra il nodo primario/master rispetto al nodo standby/slave. I casi più certi in MySQL si basano sulla replicazione di query errate come la mancanza di chiavi primarie o indici errati, hardware di rete scadente o scheda di rete malfunzionante, una posizione distante tra regioni o zone diverse o alcuni processi come l'esecuzione di backup fisici possono causare il database MySQL per ritardare l'applicazione della transazione replicata corrente. Questo è un caso molto comune quando si diagnosticano questi problemi. In questo blog, verificheremo come affrontare questi casi e cosa guardare se si verifica un ritardo di replica di MySQL.
The "SHOW SLAVE STATUS":il mantra del DBA MySQL
In alcuni casi, questo è il proiettile d'argento quando si ha a che fare con il ritardo di replica e rivela principalmente tutte le cause di un problema nel database MySQL. Esegui semplicemente questa istruzione SQL nel tuo nodo slave che si sospetta stia riscontrando un ritardo di replica.
I campi iniziali comuni da tracciare per i problemi sono,
- Slave_IO_State - Ti dice cosa sta facendo il thread. Questo campo fornisce informazioni dettagliate se l'integrità della replica funziona normalmente, se si verificano problemi di rete come la riconnessione a un master o se impiega troppo tempo per eseguire il commit dei dati che possono indicare problemi del disco durante la sincronizzazione dei dati sul disco. Puoi anche determinare questo valore di stato durante l'esecuzione di SHOW PROCESSLIST.
- Master_Log_File - Nome del file binlog del master in cui è attualmente recuperato il thread di I/O.
- Leggi_Master_Log_Pos - posizione del file binlog dal master in cui è già stato letto il thread di I/O di replica.
- Relay_Log_File - il nome del file del registro di inoltro per il quale il thread SQL sta eseguendo gli eventi
- Relay_Log_Pos - posizione binlog dal file specificato in Relay_Log_File per il quale il thread SQL è già stato eseguito.
- Relay_Master_Log_File - Il file binlog del master che il thread SQL ha già eseguito ed è congruente al valore Read_Master_Log_Pos.
- Seconds_Behind_Master - questo campo mostra un'approssimazione della differenza tra il timestamp corrente sullo slave e il timestamp sul master per l'evento attualmente in elaborazione sullo slave. Tuttavia, questo campo potrebbe non essere in grado di indicare l'esatto ritardo se la rete è lenta perché viene rilevata la differenza in secondi tra il thread SQL slave e il thread I/O slave. Quindi ci possono essere casi in cui può essere catturato con thread I/O slave a lettura lenta, ma ho imparato che è già diverso.
- Slave_SQL_Running_State - lo stato del thread SQL e il valore è identico al valore di stato visualizzato in SHOW PROCESSLIST.
- Recuperato_Gtid_Set - Disponibile quando si utilizza la replica GTID. Questo è l'insieme di GTID corrispondenti a tutte le transazioni ricevute da questo slave.
- Set_Gtid_eseguito - Disponibile quando si utilizza la replica GTID. È l'insieme dei GTID scritti nel log binario.
Ad esempio, prendiamo l'esempio seguente che utilizza una replica GTID e sta riscontrando un ritardo di replica:
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.10.70
Master_User: cmon_replication
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000038
Read_Master_Log_Pos: 826608419
Relay_Log_File: relay-bin.000004
Relay_Log_Pos: 468413927
Relay_Master_Log_File: binlog.000038
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 826608206
Relay_Log_Space: 826607743
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 251
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 45003
Master_UUID: 36272880-a7b0-11e9-9ca6-525400cae48b
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: copy to tmp table
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 36272880-a7b0-11e9-9ca6-525400cae48b:7631-9192
Executed_Gtid_Set: 36272880-a7b0-11e9-9ca6-525400cae48b:1-9191,
864dd532-a7af-11e9-85f2-525400cae48b:1-173,
df68c807-a7af-11e9-9b56-525400cae48b:1-4
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)Diagnosticando problemi come questo, mysqlbinlog può anche essere il tuo strumento per identificare quale query è stata eseguita su una specifica posizione binlog x &y. Per determinarlo, prendiamo Retrieved_Gtid_Set, Relay_Log_Pos e Relay_Log_File. Vedi il comando seguente:
[example@sqldat.com mysql]# mysqlbinlog --base64-output=DECODE-ROWS --include-gtids="36272880-a7b0-11e9-9ca6-525400cae48b:9192" --start-position=468413927 -vvv relay-bin.000004
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/;
/*!50003 SET @example@sqldat.com@COMPLETION_TYPE,COMPLETION_TYPE=0*/;
DELIMITER /*!*/;
# at 468413927
#200206 4:36:14 server id 45003 end_log_pos 826608271 CRC32 0xc702eb4c GTID last_committed=1562 sequence_number=1563 rbr_only=no
SET @@SESSION.GTID_NEXT= '36272880-a7b0-11e9-9ca6-525400cae48b:9192'/*!*/;
# at 468413992
#200206 4:36:14 server id 45003 end_log_pos 826608419 CRC32 0xe041ec2c Query thread_id=24 exec_time=31 error_code=0
use `jbmrcd_date`/*!*/;
SET TIMESTAMP=1580963774/*!*/;
SET @@session.pseudo_thread_id=24/*!*/;
SET @@session.foreign_key_checks=1, @@session.sql_auto_is_null=0, @@session.unique_checks=1, @@session.autocommit=1/*!*/;
SET @@session.sql_mode=1436549152/*!*/;
SET @@session.auto_increment_increment=1, @@session.auto_increment_offset=1/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
SET @@session.lc_time_names=0/*!*/;
SET @@session.collation_database=DEFAULT/*!*/;
ALTER TABLE NewAddressCode ADD INDEX PostalCode(PostalCode)
/*!*/;
SET @@SESSION.GTID_NEXT= 'AUTOMATIC' /* added by mysqlbinlog */ /*!*/;
DELIMITER ;
# End of log file
/*!50003 SET example@sqldat.com_COMPLETION_TYPE*/;
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=0*/;Ci dice che stava cercando di replicare ed eseguire un'istruzione DML che cerca di essere l'origine del ritardo. Questa tabella è una tabella enorme contenente 13 milioni di righe.
Controlla SHOW PROCESSLIST, SHOW ENGINE INNODB STATUS, con la combinazione di comandi ps, top, iostat
In alcuni casi, SHOW SLAVE STATUS non è sufficiente per dirci il colpevole. È possibile che le istruzioni replicate siano interessate da processi interni in esecuzione nello slave del database MySQL. L'esecuzione delle istruzioni SHOW [FULL] PROCESSLIST e SHOW ENGINE INNODB STATUS fornisce anche dati informativi che forniscono informazioni dettagliate sull'origine del problema.
Ad esempio, supponiamo che uno strumento di benchmarking sia in esecuzione causando la saturazione dell'IO del disco e della CPU. È possibile verificare eseguendo entrambe le istruzioni SQL. Combinalo con ps e comandi top.
Puoi anche determinare i colli di bottiglia con la tua memoria su disco eseguendo iostat che fornisce statistiche sul volume corrente che stai cercando di diagnosticare. L'esecuzione di iostat può mostrare quanto è occupato o caricato il tuo server. Ad esempio, preso da uno slave che è in ritardo ma allo stesso tempo sta sperimentando un elevato utilizzo dell'IO,
[example@sqldat.com ~]# iostat -d -x 10 10
Linux 3.10.0-693.5.2.el7.x86_64 (testnode5) 02/06/2020 _x86_64_ (2 CPU)
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.42 3.71 60.65 218.92 568.39 24.47 0.15 2.31 13.79 1.61 0.12 0.76
dm-0 0.00 0.00 3.70 60.48 218.73 568.33 24.53 0.15 2.36 13.85 1.66 0.12 0.76
dm-1 0.00 0.00 0.00 0.00 0.04 0.01 21.92 0.00 63.29 2.37 96.59 22.64 0.01
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.20 392.30 7983.60 2135.60 49801.55 12.40 36.70 3.84 13.01 3.39 0.08 69.02
dm-0 0.00 0.00 392.30 7950.20 2135.60 50655.15 12.66 36.93 3.87 13.05 3.42 0.08 69.34
dm-1 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.06 183.67 0.00 183.67 61.67 1.85
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 1.40 370.93 6775.42 2557.04 46184.22 13.64 43.43 6.12 11.60 5.82 0.10 73.25
dm-0 0.00 0.00 370.93 6738.76 2557.04 47029.62 13.95 43.77 6.20 11.64 5.90 0.10 73.41
dm-1 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.03 107.00 0.00 107.00 35.67 1.07
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 299.80 7253.35 1916.88 52766.38 14.48 30.44 4.59 15.62 4.14 0.10 72.09
dm-0 0.00 0.00 299.80 7198.60 1916.88 51064.24 14.13 30.68 4.66 15.70 4.20 0.10 72.57
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.10 215.50 8939.60 1027.60 67497.10 14.97 59.65 6.52 27.98 6.00 0.08 72.50
dm-0 0.00 0.00 215.50 8889.20 1027.60 67495.90 15.05 60.07 6.60 28.09 6.08 0.08 72.75
dm-1 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.01 32.33 0.00 32.33 30.33 0.91
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.90 140.40 8922.10 625.20 54709.80 12.21 11.29 1.25 9.88 1.11 0.08 68.60
dm-0 0.00 0.00 140.40 8871.50 625.20 54708.60 12.28 11.39 1.26 9.92 1.13 0.08 68.83
dm-1 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.01 27.33 0.00 27.33 9.33 0.28
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 1.70 284.50 8621.30 24228.40 51535.75 17.01 34.14 3.27 8.19 3.11 0.08 72.78
dm-0 0.00 0.00 290.90 8587.10 25047.60 53434.95 17.68 34.28 3.29 8.02 3.13 0.08 73.47
dm-1 0.00 0.00 0.00 2.00 0.00 8.00 8.00 0.83 416.45 0.00 416.45 63.60 12.72
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.30 851.60 11018.80 17723.60 85165.90 17.34 142.59 12.44 7.61 12.81 0.08 99.75
dm-0 0.00 0.00 845.20 10938.90 16904.40 83258.70 17.00 143.44 12.61 7.67 12.99 0.08 99.75
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 1.10 24.60 12965.40 420.80 51114.45 7.93 39.44 3.04 0.33 3.04 0.07 93.39
dm-0 0.00 0.00 24.60 12890.20 420.80 51114.45 7.98 40.23 3.12 0.33 3.12 0.07 93.35
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 3.60 13420.70 57.60 51942.00 7.75 0.95 0.07 0.33 0.07 0.07 92.11
dm-0 0.00 0.00 3.60 13341.10 57.60 51942.00 7.79 0.95 0.07 0.33 0.07 0.07 92.08
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00Il risultato sopra mostra l'utilizzo elevato di IO e scritture elevate. Rivela inoltre che la dimensione media della coda e la dimensione media della richiesta si stanno spostando, il che significa che è un'indicazione di un carico di lavoro elevato. In questi casi, è necessario determinare se esistono processi esterni che fanno sì che MySQL strozzi i thread di replica.
Come può essere d'aiuto ClusterControl?
Con ClusterControl, gestire lo slave lag e determinare il colpevole è molto semplice ed efficiente. Ti dice direttamente nell'interfaccia utente web, vedi sotto:
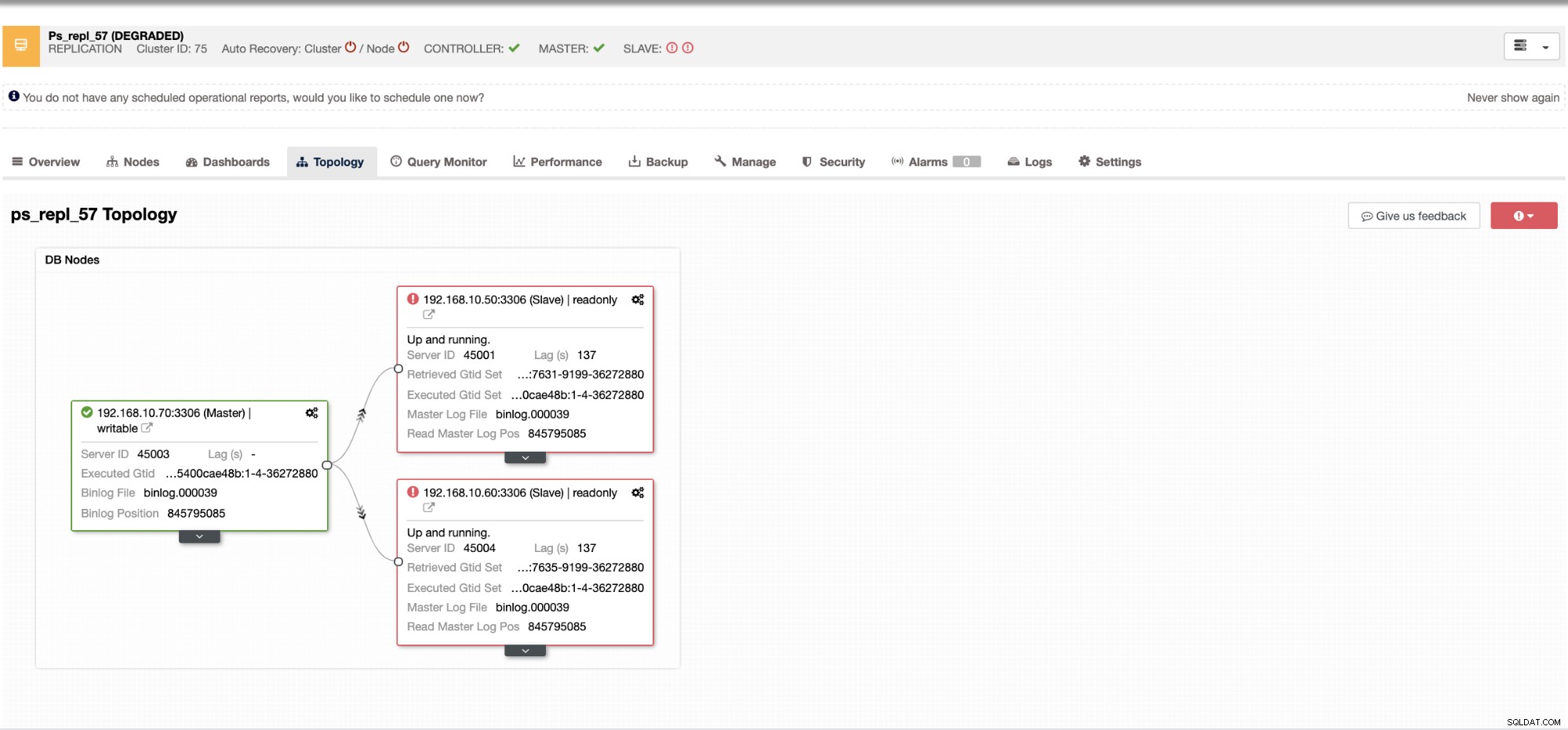
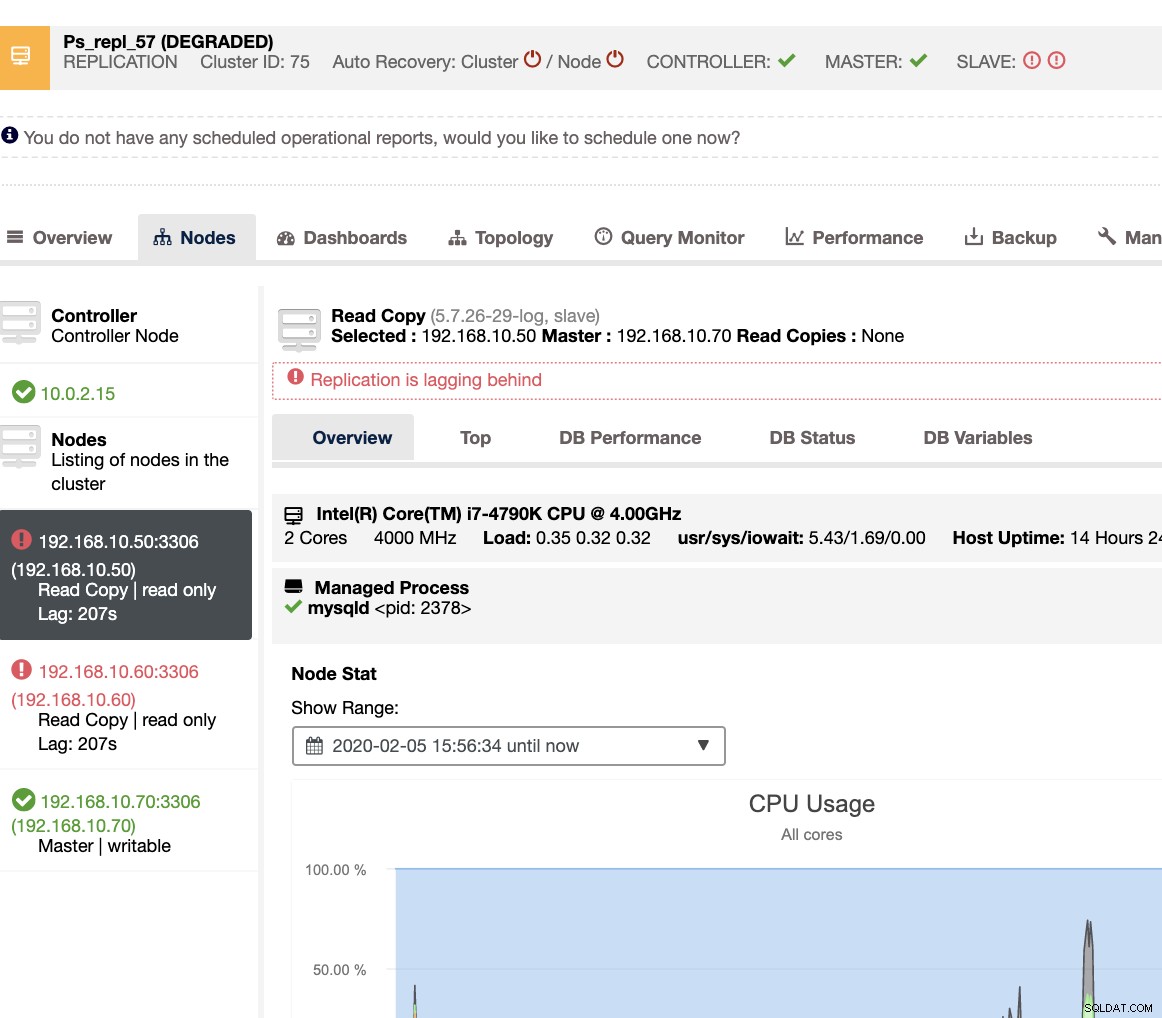
Ti rivela l'attuale ritardo di slave che stanno vivendo i tuoi nodi slave. Non solo, con i dashboard SCUMM, se abilitati, ti fornisce maggiori informazioni su ciò che sta facendo lo stato di salute del tuo nodo slave o anche l'intero cluster:
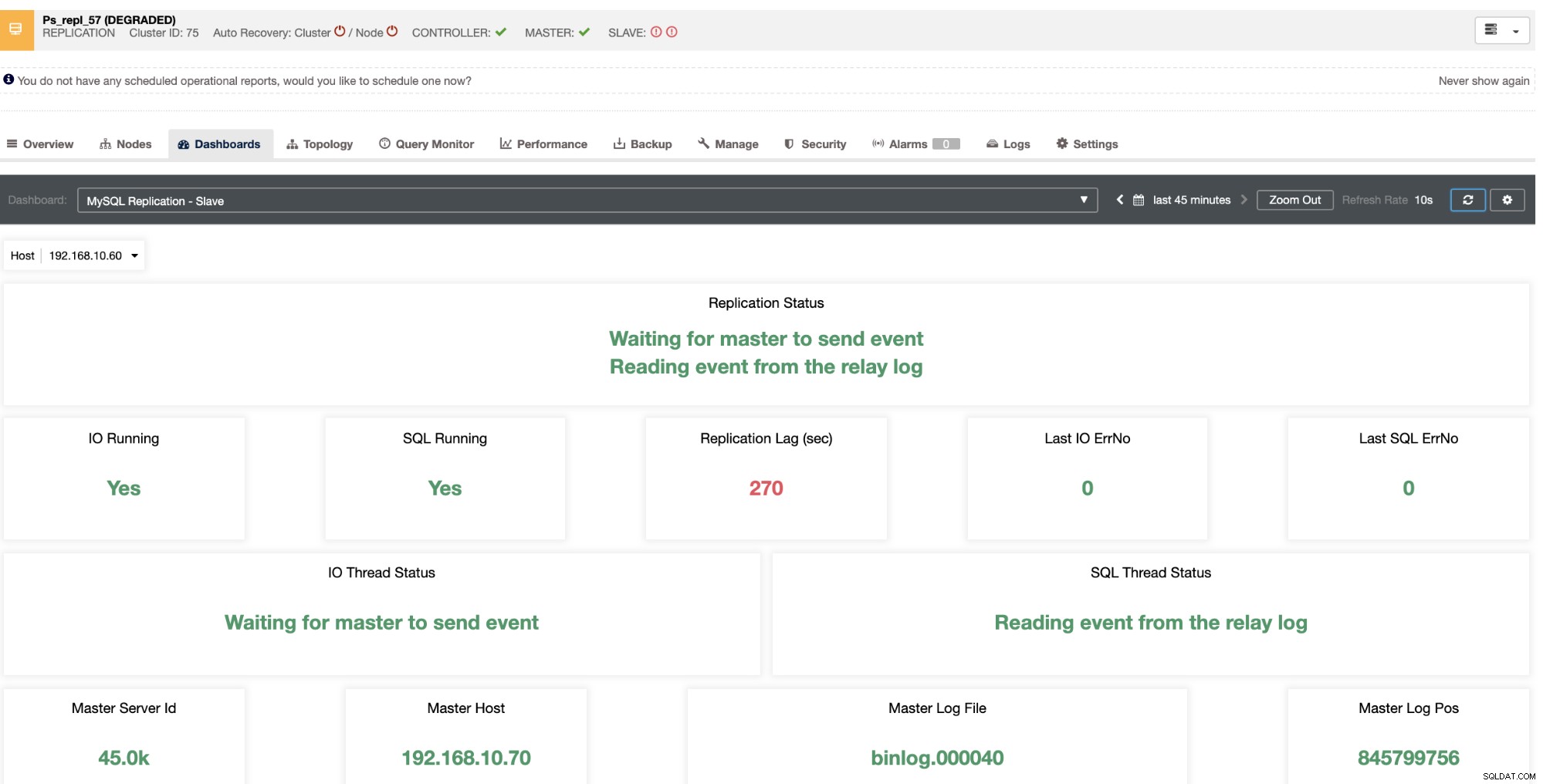


Non solo queste cose sono disponibili in ClusterControl, ma ti fornisce anche la capacità di evitare che si verifichino query errate con queste funzionalità, come mostrato di seguito,
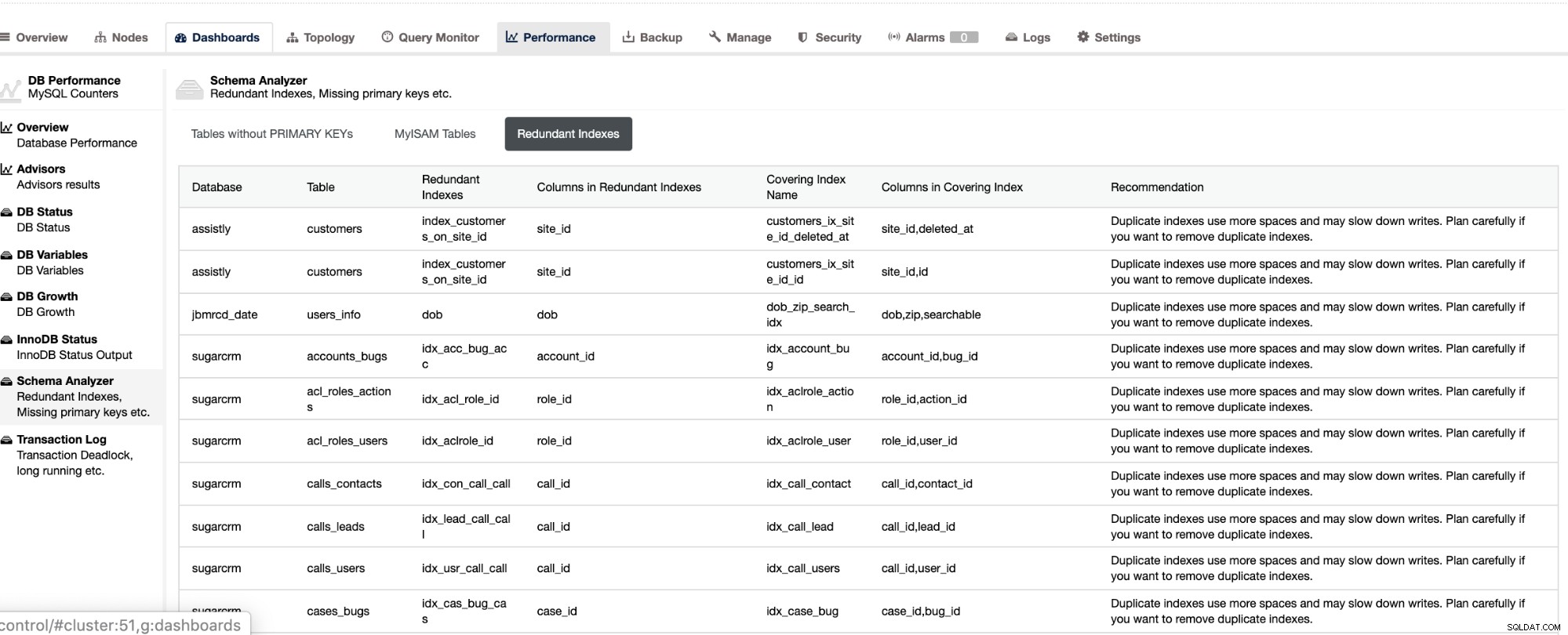
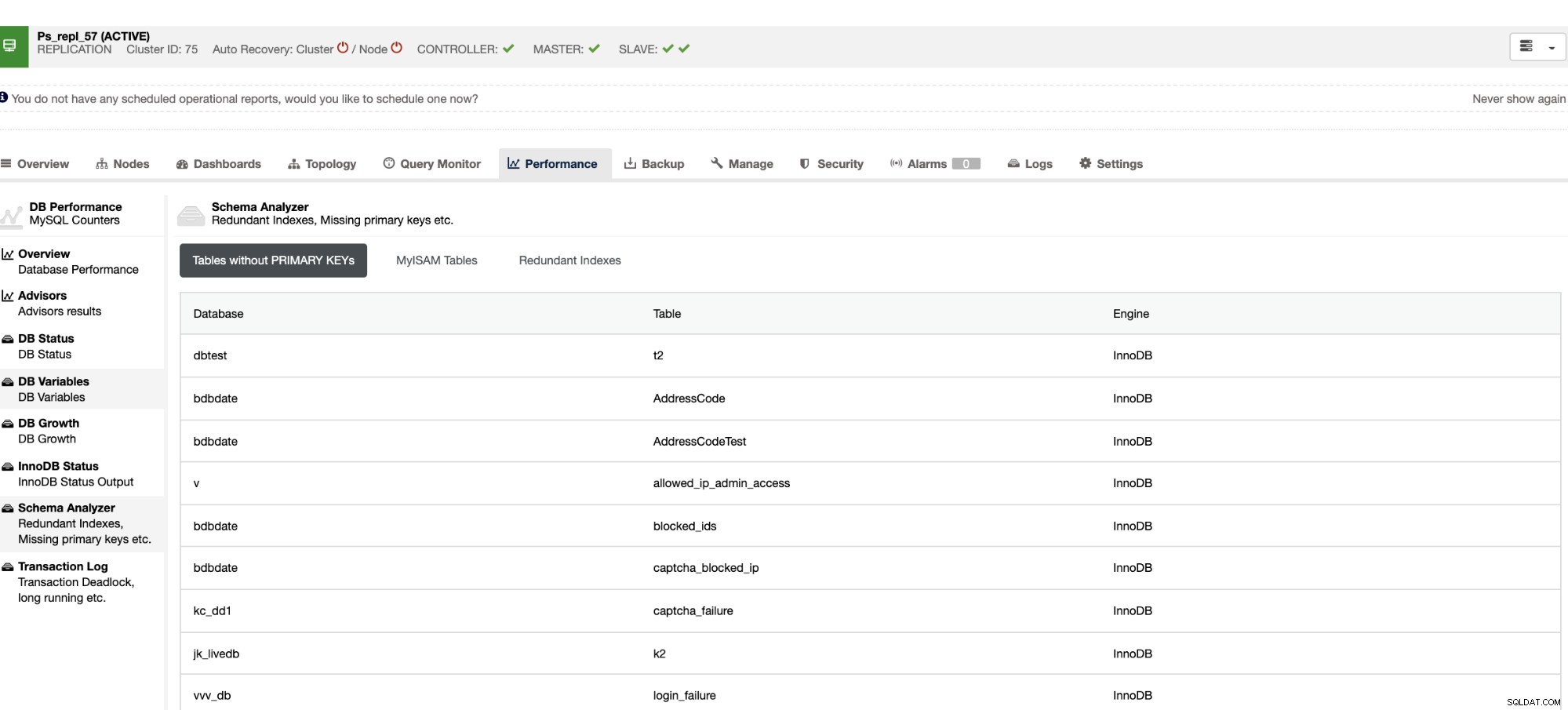
Gli indici ridondanti consentono di determinare che questi indici possono causare problemi di prestazioni per query in arrivo che fanno riferimento agli indici duplicati. Ti dice anche tabelle che non hanno chiavi primarie che di solito sono un problema comune di ritardo dello slave quando una determinata query SQL o transazioni che fanno riferimento a grandi tabelle senza chiavi primarie o univoche quando viene replicata negli slave.
Conclusione
La gestione del ritardo di replica di MySQL è un problema frequente in una configurazione di replica master-slave. Può essere facile da diagnosticare, ma difficile da risolvere. Assicurati di avere le tue tabelle con la chiave primaria o una chiave univoca esistente e determina i passaggi e gli strumenti su come risolvere e diagnosticare la causa dello slave lag. Tuttavia, l'efficienza è sempre la chiave quando si risolvono i problemi.