Qualcuno ha cancellato accidentalmente parte del database. Qualcuno ha dimenticato di includere una clausola WHERE in una query DELETE o ha eliminato la tabella sbagliata. Cose del genere possono e accadranno, è inevitabile e umano. Ma l'impatto può essere disastroso. Cosa puoi fare per proteggerti da tali situazioni e come recuperare i tuoi dati? In questo post del blog, tratteremo alcuni dei casi più tipici di perdita di dati e come puoi prepararti per riprenderti.
Preparativi
Ci sono cose che dovresti fare per garantire un recupero regolare. Esaminiamoli. Tieni presente che non è la situazione "scegli uno":idealmente implementerai tutte le misure di cui parleremo di seguito.
Backup
Devi avere un backup, non c'è modo di evitarlo. Dovresti far testare i tuoi file di backup - a meno che tu non provi i tuoi backup, non puoi essere sicuro che siano buoni e se sarai mai in grado di ripristinarli. Per il ripristino di emergenza è necessario conservare una copia del backup in un luogo esterno al datacenter, nel caso in cui l'intero datacenter non sia disponibile. Per velocizzare il ripristino è molto utile conservare una copia del backup anche sui nodi del database. Se il set di dati è di grandi dimensioni, copiarlo in rete da un server di backup al nodo del database che si desidera ripristinare potrebbe richiedere molto tempo. Mantenere l'ultimo backup in locale può migliorare notevolmente i tempi di ripristino.
Backup logico
Il tuo primo backup, molto probabilmente, sarà un backup fisico. Per MySQL o MariaDB, sarà qualcosa come xtrabackup o una sorta di snapshot del filesystem. Tali backup sono ottimi per il ripristino di un intero set di dati o per il provisioning di nuovi nodi. Tuttavia, in caso di cancellazione di un sottoinsieme di dati, subiscono un sovraccarico significativo. Innanzitutto, non sarai in grado di ripristinare tutti i dati, altrimenti sovrascriverai tutte le modifiche avvenute dopo la creazione del backup. Quello che stai cercando è la possibilità di ripristinare solo un sottoinsieme di dati, solo le righe che sono state rimosse accidentalmente. Per farlo con un backup fisico, dovresti ripristinarlo su un host separato, individuare le righe rimosse, scaricarle e quindi ripristinarle nel cluster di produzione. La copia e il ripristino di centinaia di gigabyte di dati solo per recuperare una manciata di righe è qualcosa che definiremmo sicuramente un sovraccarico significativo. Per evitarlo è possibile utilizzare backup logici:invece di archiviare dati fisici, tali backup archiviano i dati in formato testo. Ciò semplifica l'individuazione dei dati esatti che sono stati rimossi, che possono quindi essere ripristinati direttamente sul cluster di produzione. Per renderlo ancora più semplice, puoi anche dividere tale backup logico in parti ed eseguire il backup di ogni singola tabella in un file separato. Se il tuo set di dati è di grandi dimensioni, avrà senso dividere il più possibile un file di testo di grandi dimensioni. Ciò renderà il backup incoerente, ma nella maggior parte dei casi non è un problema:se sarà necessario ripristinare l'intero set di dati a uno stato coerente, utilizzerai il backup fisico, che è molto più veloce a questo proposito. Se devi ripristinare solo un sottoinsieme di dati, i requisiti di coerenza sono meno severi.
Recupero puntuale
Il backup è solo l'inizio:sarai in grado di ripristinare i tuoi dati fino al punto in cui è stato eseguito il backup ma, molto probabilmente, i dati sono stati rimossi dopo tale periodo. Semplicemente ripristinando i dati mancanti dall'ultimo backup, potresti perdere tutti i dati che sono stati modificati dopo il backup. Per evitarlo, dovresti implementare il Point-In-Time Recovery. Per MySQL significa fondamentalmente che dovrai utilizzare i log binari per riprodurre tutte le modifiche avvenute tra il momento del backup e l'evento di perdita di dati. Lo screenshot qui sotto mostra come ClusterControl può aiutare in questo.
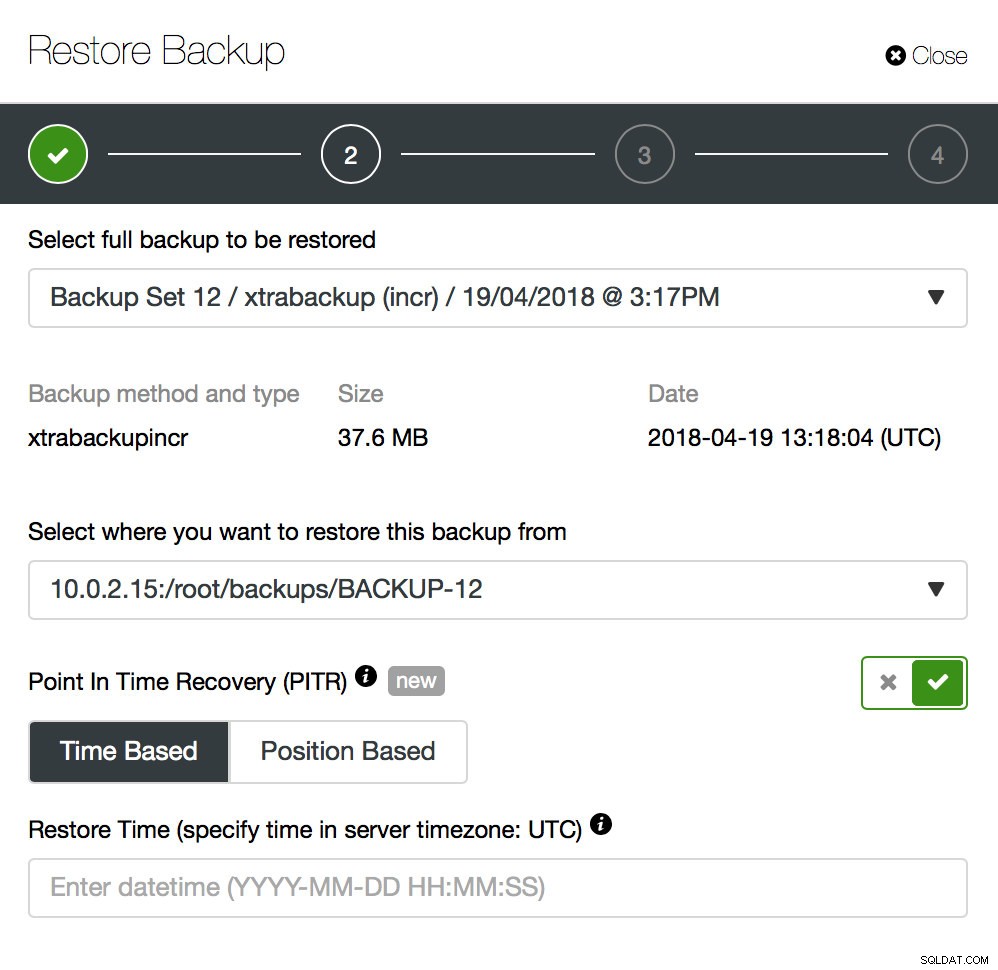
Quello che dovrai fare è ripristinare questo backup fino al momento appena prima della perdita di dati. Dovrai ripristinarlo su un host separato per non apportare modifiche al cluster di produzione. Dopo aver ripristinato il backup, puoi accedere a quell'host, trovare i dati mancanti, scaricarli e ripristinarli nel cluster di produzione.
Schiavo ritardato
Tutti i metodi di cui abbiamo discusso in precedenza hanno un punto dolente comune:il ripristino dei dati richiede tempo. Potrebbe volerci più tempo quando ripristini tutti i dati e poi provi a scaricare solo la parte interessante. Potrebbe volerci meno tempo se si dispone di un backup logico ed è possibile eseguire rapidamente il drill-down dei dati che si desidera ripristinare, ma non è affatto un'attività rapida. Devi ancora trovare un paio di righe in un file di testo di grandi dimensioni. Più è grande, più complicata diventa l'attività:a volte le dimensioni del file rallentano tutte le azioni. Un metodo per evitare questi problemi è avere uno schiavo ritardato. Gli slave in genere cercano di rimanere aggiornati con il master, ma è anche possibile configurarli in modo che mantengano le distanze dal proprio master. Nello screenshot seguente, puoi vedere come utilizzare ClusterControl per distribuire uno schiavo di questo tipo:
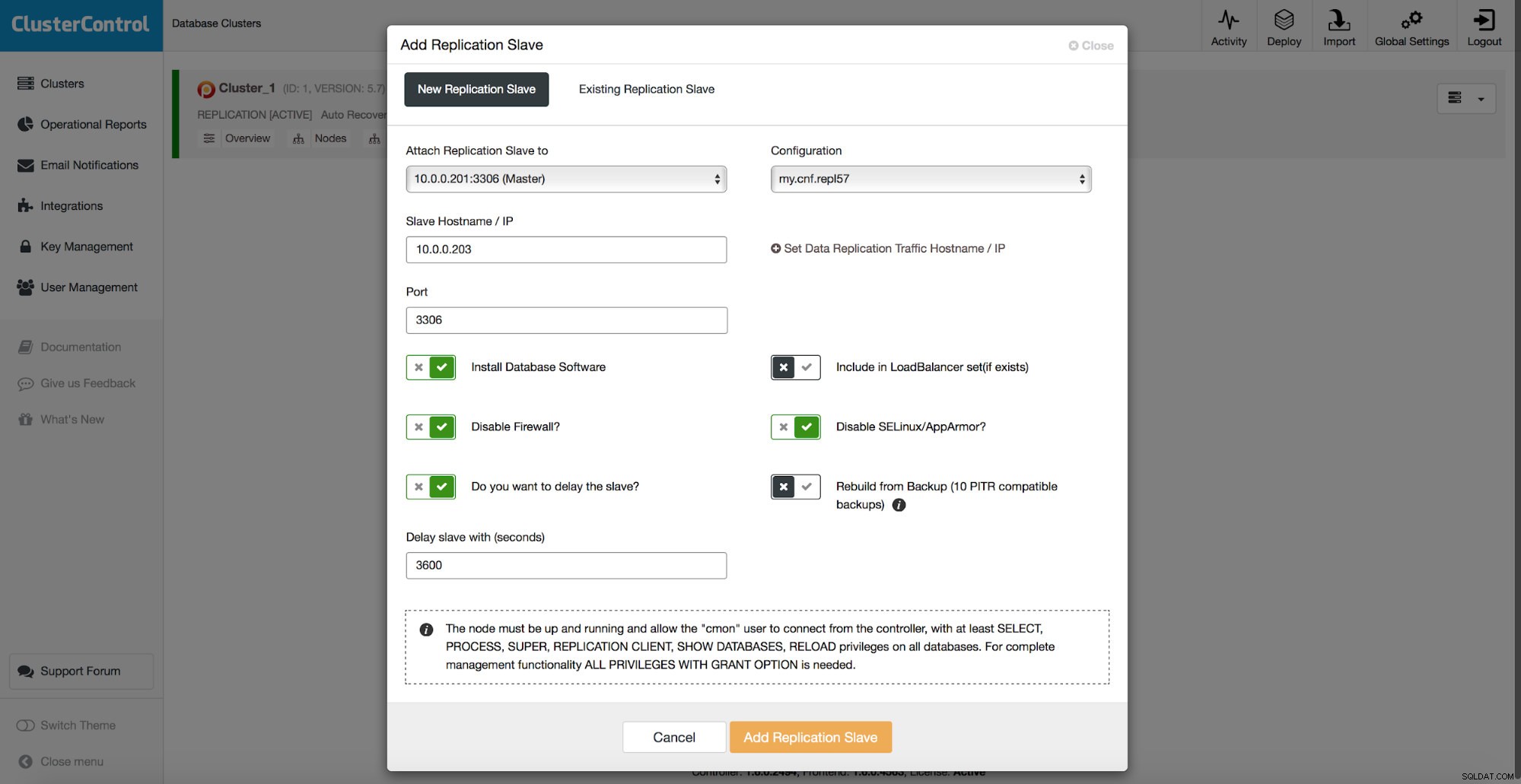
In breve, abbiamo qui un'opzione per aggiungere uno slave di replica all'impostazione del database e configurarlo per essere ritardato. Nello screenshot sopra, lo slave verrà ritardato di 3600 secondi, ovvero un'ora. Ciò ti consente di utilizzare quello slave per recuperare i dati rimossi fino a un'ora dall'eliminazione dei dati. Non dovrai ripristinare un backup, basterà eseguire mysqldump o SELECT ... INTO OUTFILE per i dati mancanti e otterrai i dati da ripristinare sul tuo cluster di produzione.
Ripristino dei dati
In questa sezione, esamineremo un paio di esempi di eliminazione accidentale dei dati e come recuperarli. Esamineremo il ripristino da una perdita completa di dati, mostreremo anche come eseguire il ripristino da una perdita parziale di dati quando si utilizzano backup fisici e logici. Ti mostreremo finalmente come ripristinare le righe eliminate accidentalmente se hai uno slave ritardato nella tua configurazione.
Perdita di dati completa
Accidentale "rm -rf" o "DROP SCHEMA myonlyschema;" è stato eseguito e ti sei ritrovato senza alcun dato. Se ti è capitato di rimuovere anche file diversi dalla directory dei dati MySQL, potrebbe essere necessario eseguire nuovamente il provisioning dell'host. Per semplificare le cose, assumeremo che solo MySQL sia stato interessato. Consideriamo due casi, con uno slave ritardato e senza uno.
Nessuno slave ritardato
In questo caso l'unica cosa che possiamo fare è ripristinare l'ultimo backup fisico. Poiché tutti i nostri dati sono stati rimossi, non dobbiamo preoccuparci dell'attività che si è verificata dopo la perdita di dati perché senza dati non c'è attività. Dovremmo essere preoccupati per l'attività che si è verificata dopo l'esecuzione del backup. Ciò significa che dobbiamo eseguire un ripristino Point-in-Time. Ovviamente, ci vorrà più tempo del semplice ripristino dei dati dal backup. Se il ripristino rapido del database è più importante del ripristino di tutti i dati, puoi anche ripristinare un backup e sistemarlo.
Prima di tutto, se hai ancora accesso ai log binari sul server che vuoi ripristinare, puoi usarli per PITR. Innanzitutto, vogliamo convertire la parte rilevante dei log binari in un file di testo per ulteriori indagini. Sappiamo che la perdita di dati è avvenuta dopo le 13:00:00. Per prima cosa, controlliamo quale file binlog dovremmo esaminare:
example@sqldat.com:~# ls -alh /var/lib/mysql/binlog.*
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:32 /var/lib/mysql/binlog.000001
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:33 /var/lib/mysql/binlog.000002
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:35 /var/lib/mysql/binlog.000003
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:38 /var/lib/mysql/binlog.000004
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:39 /var/lib/mysql/binlog.000005
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:41 /var/lib/mysql/binlog.000006
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:43 /var/lib/mysql/binlog.000007
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:45 /var/lib/mysql/binlog.000008
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:47 /var/lib/mysql/binlog.000009
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:49 /var/lib/mysql/binlog.000010
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:51 /var/lib/mysql/binlog.000011
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:53 /var/lib/mysql/binlog.000012
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:55 /var/lib/mysql/binlog.000013
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:57 /var/lib/mysql/binlog.000014
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:59 /var/lib/mysql/binlog.000015
-rw-r----- 1 mysql mysql 306M Apr 23 13:18 /var/lib/mysql/binlog.000016Come si può vedere, siamo interessati all'ultimo file binlog.
example@sqldat.com:~# mysqlbinlog --start-datetime='2018-04-23 13:00:00' --verbose /var/lib/mysql/binlog.000016 > sql.outUna volta fatto, diamo un'occhiata al contenuto di questo file. Cercheremo 'drop schema' in vim. Ecco una parte rilevante del file:
# at 320358785
#180423 13:18:58 server id 1 end_log_pos 320358850 CRC32 0x0893ac86 GTID last_committed=307804 sequence_number=307805 rbr_only=no
SET @@SESSION.GTID_NEXT= '52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415'/*!*/;
# at 320358850
#180423 13:18:58 server id 1 end_log_pos 320358946 CRC32 0x487ab38e Query thread_id=55 exec_time=1 error_code=0
SET TIMESTAMP=1524489538/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
drop schema sbtest
/*!*/;Come possiamo vedere, vogliamo ripristinare fino alla posizione 320358785. Possiamo passare questi dati all'interfaccia utente di ClusterControl:
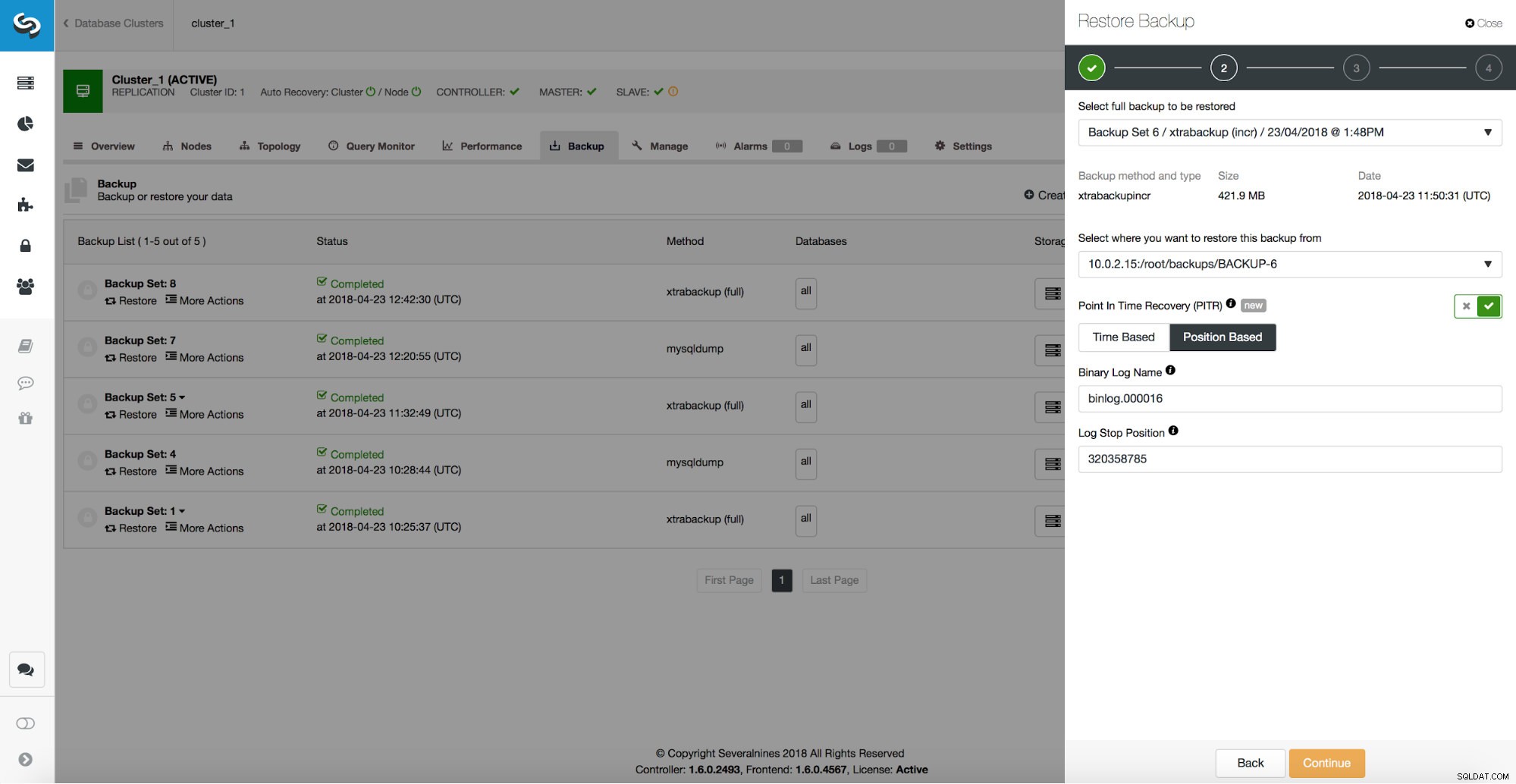
Schiavo ritardato
Se abbiamo uno slave ritardato e quell'host è sufficiente per gestire tutto il traffico, possiamo usarlo e promuoverlo a master. Per prima cosa, però, dobbiamo assicurarci che abbia raggiunto il vecchio master fino al punto della perdita di dati. Useremo alcune CLI qui per farlo accadere. Innanzitutto, dobbiamo capire in quale posizione si è verificata la perdita di dati. Quindi fermeremo lo slave e lo faremo correre fino all'evento di perdita di dati. Abbiamo mostrato come ottenere la posizione corretta nella sezione precedente, esaminando i log binari. Possiamo usare quella posizione (binlog.000016, posizione 320358785) o, se utilizziamo uno slave multithread, dovremmo usare il GTID dell'evento di perdita di dati (52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415) e riprodurre le query fino a quel GTID.
Per prima cosa, fermiamo lo slave e disabilitiamo il ritardo:
mysql> STOP SLAVE;
Query OK, 0 rows affected (0.01 sec)
mysql> CHANGE MASTER TO MASTER_DELAY = 0;
Query OK, 0 rows affected (0.02 sec)Quindi possiamo avviarlo fino a una determinata posizione del log binario.
mysql> START SLAVE UNTIL MASTER_LOG_FILE='binlog.000016', MASTER_LOG_POS=320358785;
Query OK, 0 rows affected (0.01 sec)Se desideriamo utilizzare GTID, il comando avrà un aspetto diverso:
mysql> START SLAVE UNTIL SQL_BEFORE_GTIDS = ‘52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415’;
Query OK, 0 rows affected (0.01 sec)Una volta interrotta la replica (ovvero tutti gli eventi richiesti sono stati eseguiti), è necessario verificare che l'host contenga i dati mancanti. In tal caso, puoi promuoverlo a master e quindi ricostruire altri host utilizzando il nuovo master come origine dei dati.
Questa non è sempre l'opzione migliore. Tutto dipende da quanto è in ritardo il tuo slave:se è in ritardo di un paio d'ore, potrebbe non avere senso aspettare che recuperi il ritardo, soprattutto se il traffico di scrittura è intenso nel tuo ambiente. In tal caso, è molto probabilmente più veloce ricostruire gli host utilizzando il backup fisico. D'altra parte, se hai un volume di traffico piuttosto piccolo, questo potrebbe essere un bel modo per risolvere rapidamente il problema, promuovere un nuovo master e continuare a servire il traffico, mentre il resto dei nodi viene ricostruito in background .
Perdita parziale di dati - Backup fisico
In caso di perdita parziale dei dati, i backup fisici possono essere inefficienti ma, poiché sono il tipo più comune di backup, è molto importante sapere come utilizzarli per il ripristino parziale. Il primo passo sarà sempre ripristinare un backup fino a un punto nel tempo prima dell'evento di perdita di dati. È anche molto importante ripristinarlo su un host separato. ClusterControl utilizza xtrabackup per i backup fisici, quindi mostreremo come usarlo. Supponiamo di aver eseguito la seguente query errata:
DELETE FROM sbtest1 WHERE id < 23146;
Volevamo eliminare solo una singola riga ('=' nella clausola WHERE), invece ne abbiamo cancellate un po' (
Ora, diamo un'occhiata al file di output e vediamo cosa possiamo trovare lì. Stiamo usando la replica basata su righe, quindi non vedremo l'SQL esatto che è stato eseguito. Invece (finché useremo --verbose flag su mysqlbinlog) vedremo eventi come di seguito:
Come si può vedere, MySQL identifica le righe da eliminare utilizzando una condizione WHERE molto precisa. Segni misteriosi nel commento leggibile dall'uomo, "@1", "@2", significano "prima colonna", "seconda colonna". Sappiamo che la prima colonna è "id", che è qualcosa che ci interessa. Dobbiamo trovare un grande evento DELETE su una tabella "sbtest1". I commenti che seguiranno dovrebbero menzionare id di 1, quindi id di '2', quindi '3' e così via - tutto fino a id di '23145'. Tutto dovrebbe essere eseguito in un'unica transazione (un singolo evento in un registro binario). Dopo aver analizzato l'output utilizzando "less", abbiamo trovato:
L'evento, a cui sono allegati quei commenti, è iniziato alle:
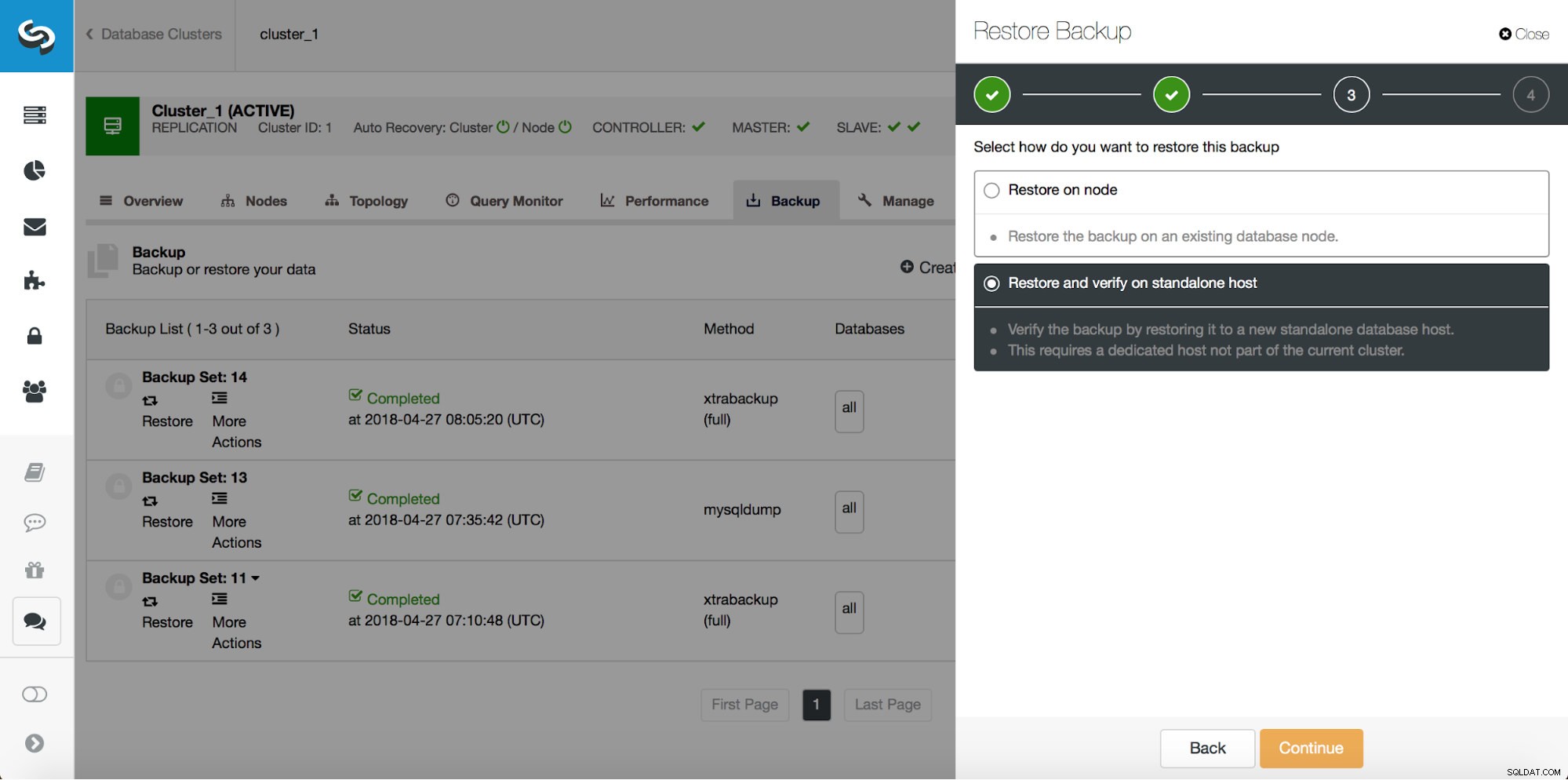
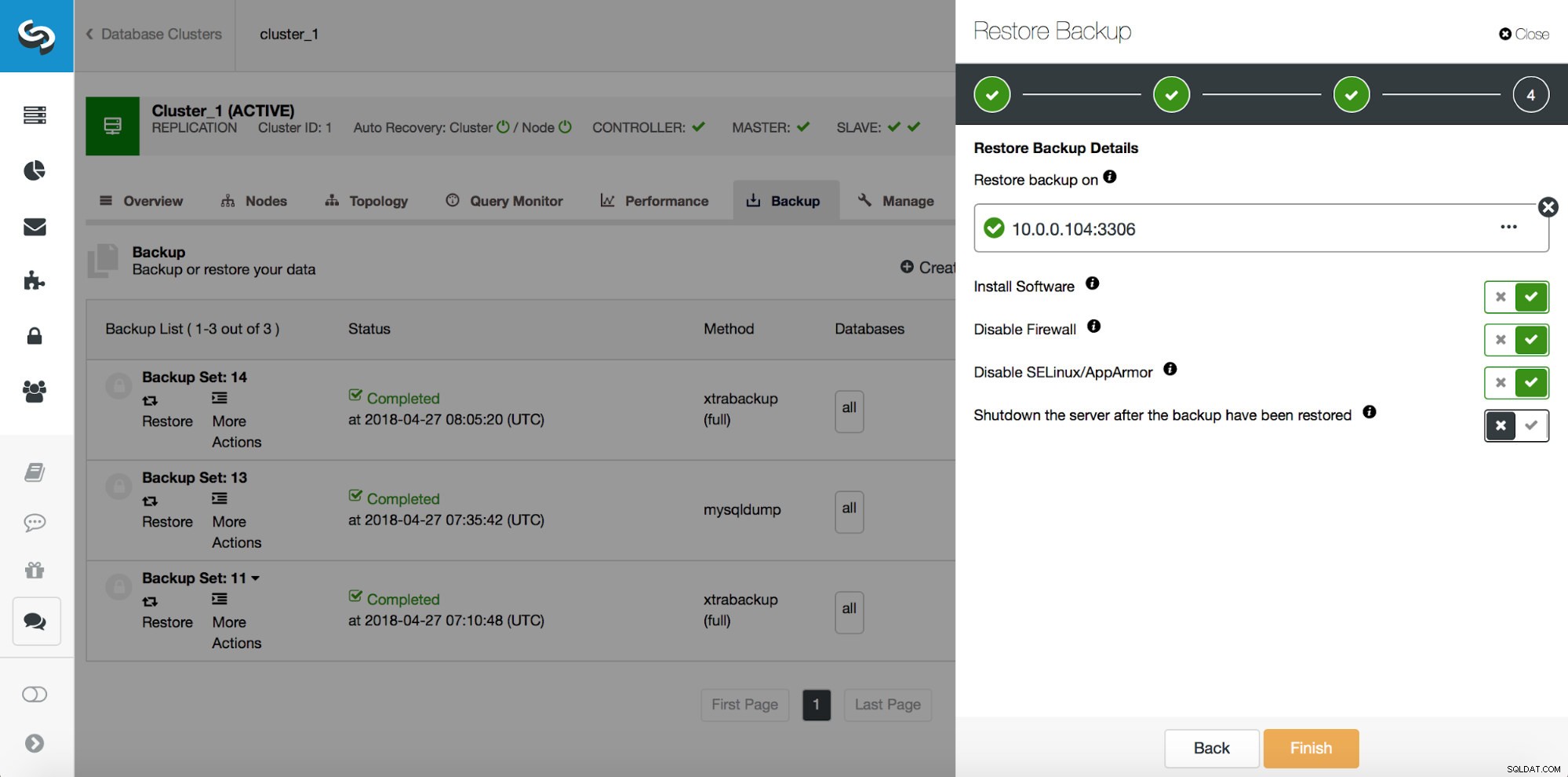
Quindi, vogliamo ripristinare il backup fino al commit precedente nella posizione 29600687. Facciamolo ora. Useremo un server esterno per questo. Ripristineremo il backup fino a quella posizione e manterremo il server di ripristino attivo e funzionante in modo da poter poi estrarre i dati mancanti.
Una volta completato il ripristino, assicuriamoci che i nostri dati siano stati recuperati:
Sembra buono. Ora possiamo estrarre questi dati in un file che caricheremo nuovamente sul master.
Qualcosa non va - questo perché il server è configurato per poter scrivere file solo in una posizione particolare - è tutta una questione di sicurezza, non vogliamo che gli utenti salvino i contenuti dove vogliono. Controlliamo dove possiamo salvare il nostro file:
Ok, proviamo ancora una volta:
Ora sembra molto meglio. Copiamo i dati nel master:
Ora è il momento di caricare le righe mancanti sul master e verificare se è riuscito:
Questo è tutto, abbiamo ripristinato i nostri dati mancanti.
Nella sezione precedente, abbiamo ripristinato i dati persi utilizzando un backup fisico e un server esterno. E se avessimo creato un backup logico? Diamo un'occhiata. Per prima cosa, verifichiamo di avere un backup logico:
Sì, è lì. Ora è il momento di decomprimerlo.
Quando lo guardi, vedrai che i dati sono archiviati nel formato INSERT multivalore. Ad esempio:
Tutto ciò che dobbiamo fare ora è individuare dove si trova la nostra tabella e quindi dove sono archiviate le righe che ci interessano. Innanzitutto, conoscendo i modelli di mysqldump (elimina tabella, creane una nuova, disabilita indici, inserisci dati) scopriamo quale riga contiene l'istruzione CREATE TABLE per la tabella 'sbtest1':
Ora, usando un metodo per tentativi ed errori, dobbiamo capire dove cercare le nostre righe. Ti mostreremo il comando finale che abbiamo escogitato. L'intero trucco è provare a stampare diversi intervalli di righe usando sed e quindi controllare se l'ultima riga contiene righe vicine, ma successive a quelle che stiamo cercando. Nel comando seguente cerchiamo le righe comprese tra 971 (CREATE TABLE) e 993. Chiediamo anche a sed di uscire una volta raggiunta la riga 994 poiché il resto del file non ci interessa:
L'output è simile al seguente:
Ciò significa che il nostro intervallo di righe (fino a righe con ID 23145) è vicino. Successivamente, si tratta di pulire manualmente il file. Vogliamo che inizi con la prima riga che dobbiamo ripristinare:
E finisci con l'ultima riga da ripristinare:
Abbiamo dovuto tagliare alcuni dei dati non necessari (è un inserimento multilinea) ma dopo tutto questo abbiamo un file che possiamo caricare di nuovo sul master.
Infine, ultimo controllo:
Tutto bene, i dati sono stati ripristinati.
In questo caso, non seguiremo l'intero processo. Abbiamo già descritto come identificare la posizione di un evento di perdita di dati nei log binari. Abbiamo anche descritto come arrestare uno slave ritardato e riavviare la replica, fino a un punto prima dell'evento di perdita di dati. Abbiamo anche spiegato come usare SELECT INTO OUTFILE e LOAD DATA INFILE per esportare i dati dal server esterno e caricarli sul master. Questo è tutto ciò di cui hai bisogno. Finché i dati sono ancora sullo slave ritardato, è necessario interromperlo. Quindi è necessario individuare la posizione prima dell'evento di perdita di dati, avviare lo slave fino a quel punto e, una volta fatto, utilizzare lo slave ritardato per estrarre i dati che sono stati eliminati, copiare il file su master e caricarlo per ripristinare i dati .
Ripristinare i dati persi non è divertente, ma se segui i passaggi che abbiamo seguito in questo blog, avrai buone possibilità di recuperare ciò che hai perso.mysqlbinlog --verbose /var/lib/mysql/binlog.000003 > bin.out### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=999296
### @2=1009782
### @3='96260841950-70557543083-97211136584-70982238821-52320653831-03705501677-77169427072-31113899105-45148058587-70555151875'
### @4='84527471555-75554439500-82168020167-12926542460-82869925404'### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=1
### @2=1006036
### @3='123'
### @4='43683718329-48150560094-43449649167-51455516141-06448225399'
### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=2
### @2=1008980
### @3='123'
### @4='05603373460-16140454933-50476449060-04937808333-32421752305'#180427 8:09:21 server id 1 end_log_pos 29600687 CRC32 0x8cfdd6ae Xid = 307686
COMMIT/*!*/;
# at 29600687
#180427 8:09:21 server id 1 end_log_pos 29600752 CRC32 0xb5aa18ba GTID last_committed=42844 sequence_number=42845 rbr_only=yes
/*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/;
SET @@SESSION.GTID_NEXT= '0c695e13-4931-11e8-9f2f-080027e8bf1b:55893'/*!*/;
# at 29600752
#180427 8:09:21 server id 1 end_log_pos 29600826 CRC32 0xc7b71da5 Query thread_id=44 exec_time=0 error_code=0
SET TIMESTAMP=1524816561/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
BEGIN
/*!*/;
# at 29600826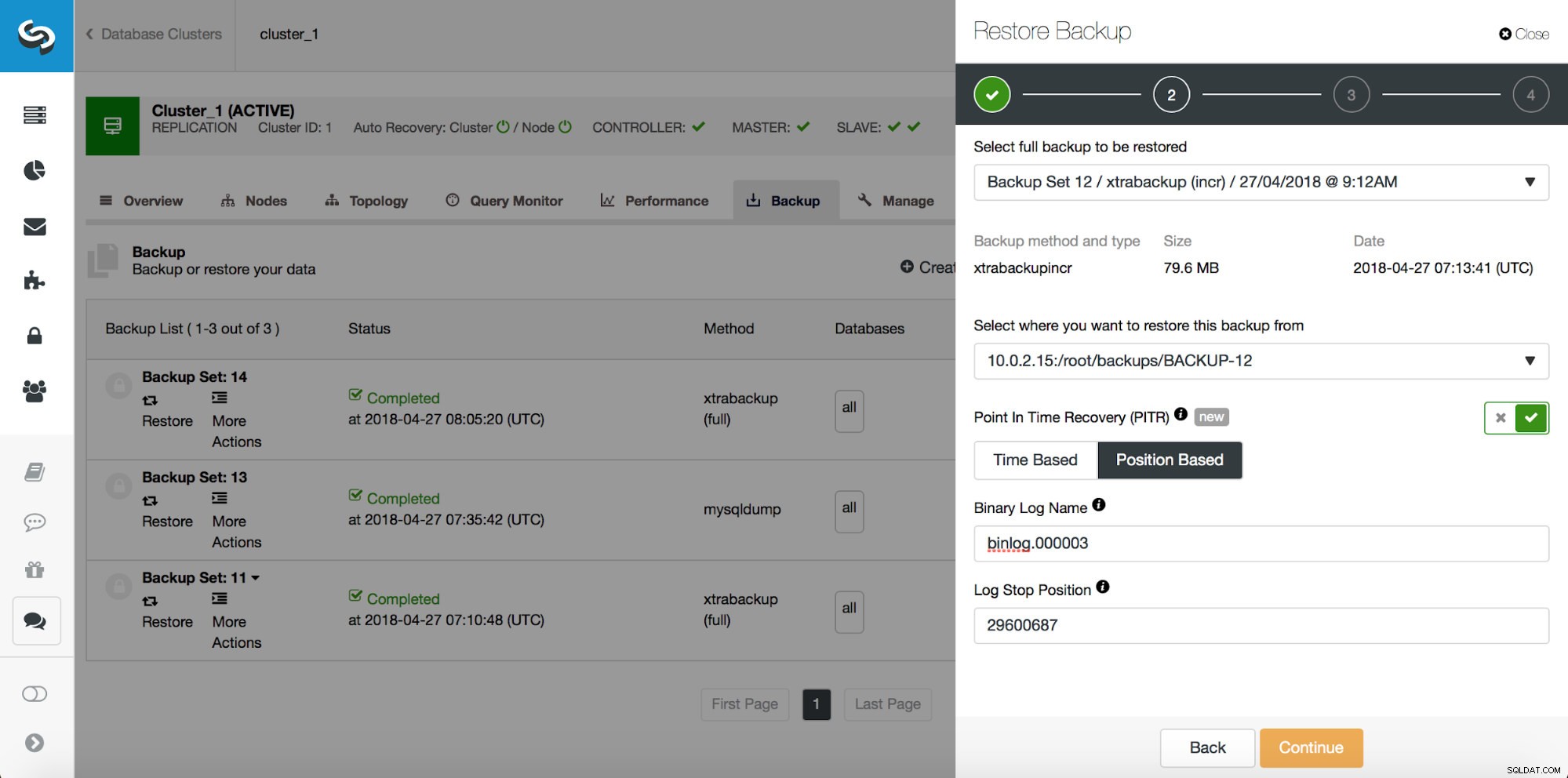
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.03 sec)mysql> SELECT * FROM sbtest.sbtest1 WHERE id < 23146 INTO OUTFILE 'missing.sql';
ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statementmysql> SHOW VARIABLES LIKE "secure_file_priv";
+------------------+-----------------------+
| Variable_name | Value |
+------------------+-----------------------+
| secure_file_priv | /var/lib/mysql-files/ |
+------------------+-----------------------+
1 row in set (0.13 sec)mysql> SELECT * FROM sbtest.sbtest1 WHERE id < 23146 INTO OUTFILE '/var/lib/mysql-files/missing.sql';
Query OK, 23145 rows affected (0.05 sec)example@sqldat.com:~# scp /var/lib/mysql-files/missing.sql 10.0.0.101:/var/lib/mysql-files/
missing.sql 100% 1744KB 1.7MB/s 00:00mysql> LOAD DATA INFILE '/var/lib/mysql-files/missing.sql' INTO TABLE sbtest.sbtest1;
Query OK, 23145 rows affected (2.22 sec)
Records: 23145 Deleted: 0 Skipped: 0 Warnings: 0
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.00 sec)Perdita parziale di dati - Backup logico
example@sqldat.com:~# ls -alh /root/backups/BACKUP-13/
total 5.8G
drwx------ 2 root root 4.0K Apr 27 07:35 .
drwxr-x--- 5 root root 4.0K Apr 27 07:14 ..
-rw-r--r-- 1 root root 2.4K Apr 27 07:35 cmon_backup.metadata
-rw------- 1 root root 5.8G Apr 27 07:35 mysqldump_2018-04-27_071434_complete.sql.gzexample@sqldat.com:~# mkdir /root/restore
example@sqldat.com:~# zcat /root/backups/BACKUP-13/mysqldump_2018-04-27_071434_complete.sql.gz > /root/restore/backup.sqlINSERT INTO `sbtest1` VALUES (1,1006036,'18034632456-32298647298-82351096178-60420120042-90070228681-93395382793-96740777141-18710455882-88896678134-41810932745','43683718329-48150560094-43449649167-51455516141-06448225399'),(2,1008980,'69708345057-48265944193-91002879830-11554672482-35576538285-03657113365-90301319612-18462263634-56608104414-27254248188','05603373460-16140454933-50476449060-04937808333-32421752305')example@sqldat.com:~/restore# grep -n "CREATE TABLE \`sbtest1\`" backup.sql > out
example@sqldat.com:~/restore# cat out
971:CREATE TABLE `sbtest1` (example@sqldat.com:~/restore# sed -n '971,993p; 994q' backup.sql > 1.sql
example@sqldat.com:~/restore# tail -n 1 1.sql | lessINSERT INTO `sbtest1` VALUES (31351,1007187,'23938390896-69688180281-37975364313-05234865797-89299459691-74476188805-03642252162-40036598389-45190639324-97494758464','60596247401-06173974673-08009930825-94560626453-54686757363'),INSERT INTO `sbtest1` VALUES (1,1006036,'18034632456-32298647298-82351096178-60420120042-90070228681-93395382793-96740777141-18710455882-88896678134-41810932745','43683718329-48150560094-43449649167-51455516141-06448225399')(23145,1001595,'37250617862-83193638873-99290491872-89366212365-12327992016-32030298805-08821519929-92162259650-88126148247-75122945670','60801103752-29862888956-47063830789-71811451101-27773551230');example@sqldat.com:~/restore# cat 1.sql | mysql -usbtest -psbtest -h10.0.0.101 sbtest
mysql: [Warning] Using a password on the command line interface can be insecure.mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.00 sec)Perdita parziale di dati, slave ritardato
Conclusione