I backup sono fondamentali quando si tratta di sicurezza dei dati. Sono la soluzione definitiva per il ripristino di emergenza:non hai nodi di database raggiungibili e il tuo data center potrebbe letteralmente andare in fumo, ma finché hai un backup dei tuoi dati, puoi comunque riprenderti da tale situazione.
In genere, utilizzerai i backup per eseguire il ripristino da diversi tipi di casi:
- DROP TABLE accidentale o DELETE senza una clausola WHERE o con una clausola WHERE non sufficientemente specifica.
- un aggiornamento del database che non riesce e danneggia i dati
- errore/corruzione del supporto di archiviazione
Il ripristino dal backup non è sufficiente? Cosa deve essere puntuale? Dobbiamo tenere a mente che un backup è un'istantanea dei dati acquisiti in un determinato momento. Se si esegue un backup all'1:00 e una tabella è stata rimossa accidentalmente alle 11:00, è possibile ripristinare i dati fino all'1:00, ma per quanto riguarda le modifiche avvenute tra l'1:00 e le 11:00? Tali modifiche andrebbero perse a meno che tu non possa riprodurre le modifiche avvenute nel mezzo. Fortunatamente, MySQL ha un tale meccanismo per memorizzare le modifiche:i log binari. Potresti sapere che quei log vengono utilizzati per la replica:MySQL li usa per archiviare tutte le modifiche avvenute sul master e uno slave li usa per riprodurre tali modifiche e applicarle al suo set di dati. Poiché i binlog memorizzano tutte le modifiche, puoi anche usarle per riprodurre il traffico. In questo post del blog, daremo un'occhiata a come ClusterControl può aiutarti a eseguire il Point-In-Time Recovery (PITR).
Creazione di backup compatibili con il ripristino temporizzato
Prima di tutto, parliamo dei prerequisiti. Un host da cui esegui i backup deve avere i log binari abilitati. Senza di loro, PITR non è possibile. Secondo requisito:un host da cui si eseguono i backup deve disporre di tutti i registri binari necessari per eseguire il ripristino a un determinato momento. Se utilizzi una rotazione dei log binari troppo aggressiva, questo potrebbe diventare un problema.
Vediamo quindi come utilizzare questa funzionalità in ClusterControl. Prima di tutto, devi fare un backup compatibile con PITR. Tale backup deve essere completo, completo e coerente. Per xtrabackup, purché contenga un set di dati completo (non hai incluso solo un sottoinsieme di schemi), sarà compatibile con PITR.
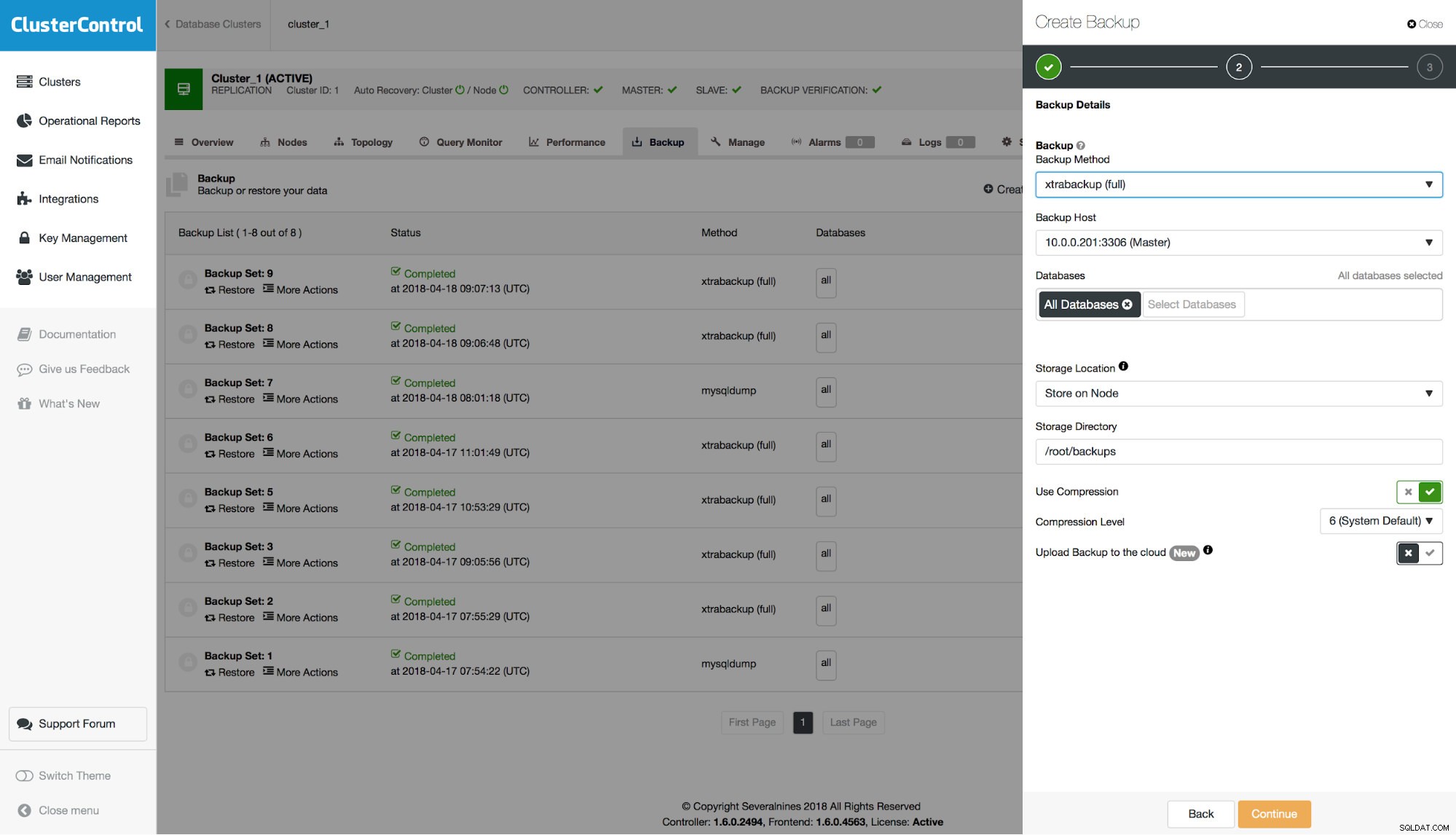
Per mysqldump, c'è un'opzione per renderlo compatibile con PITR. Quando abiliti questa opzione, tutte le opzioni necessarie verranno configurate (ad esempio, non sarai in grado di selezionare schemi separati da includere nel dump) e il backup verrà contrassegnato come disponibile per il ripristino temporizzato.
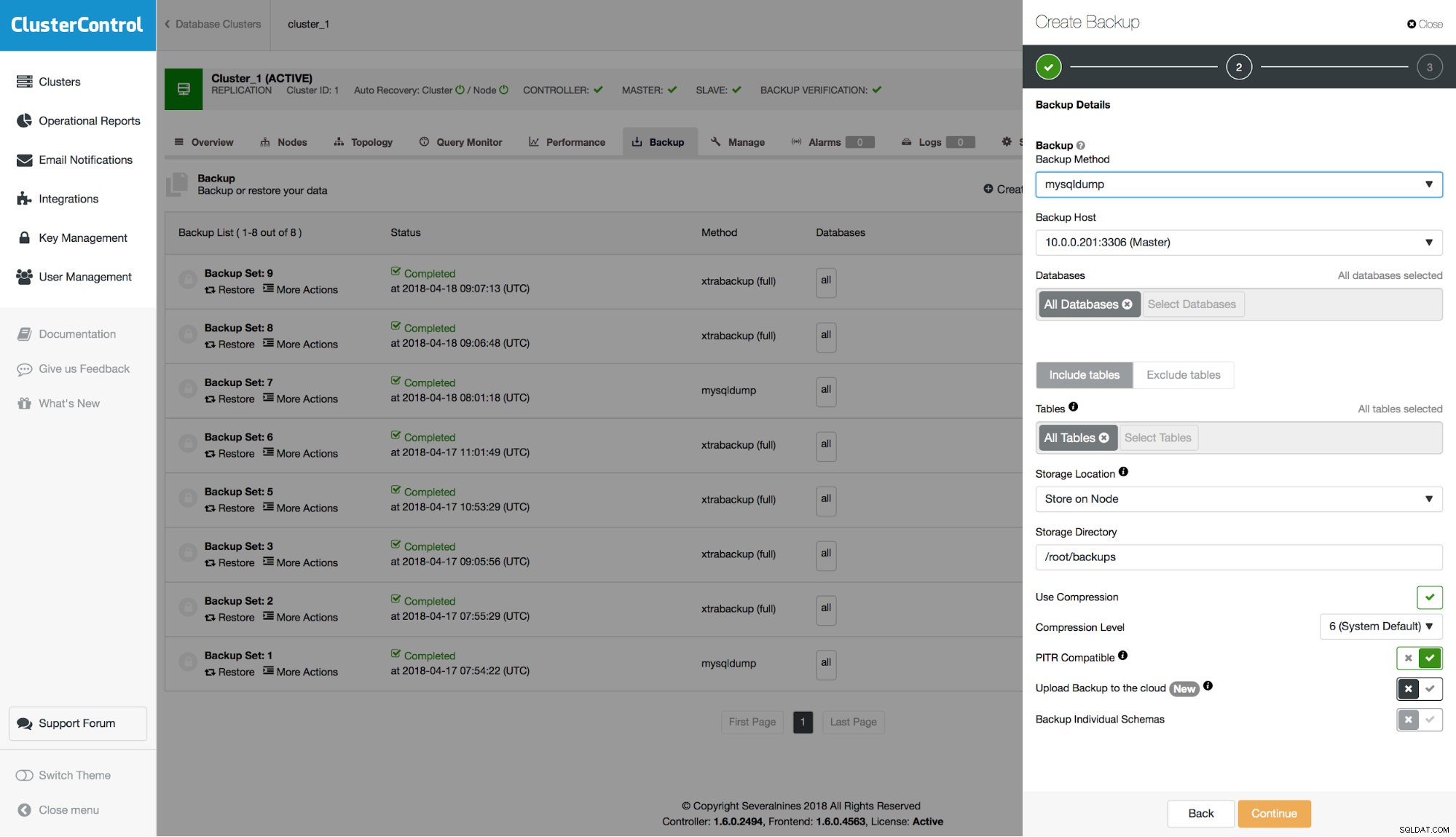
Recupero point-in-time da un backup
Innanzitutto, devi scegliere un backup da ripristinare.
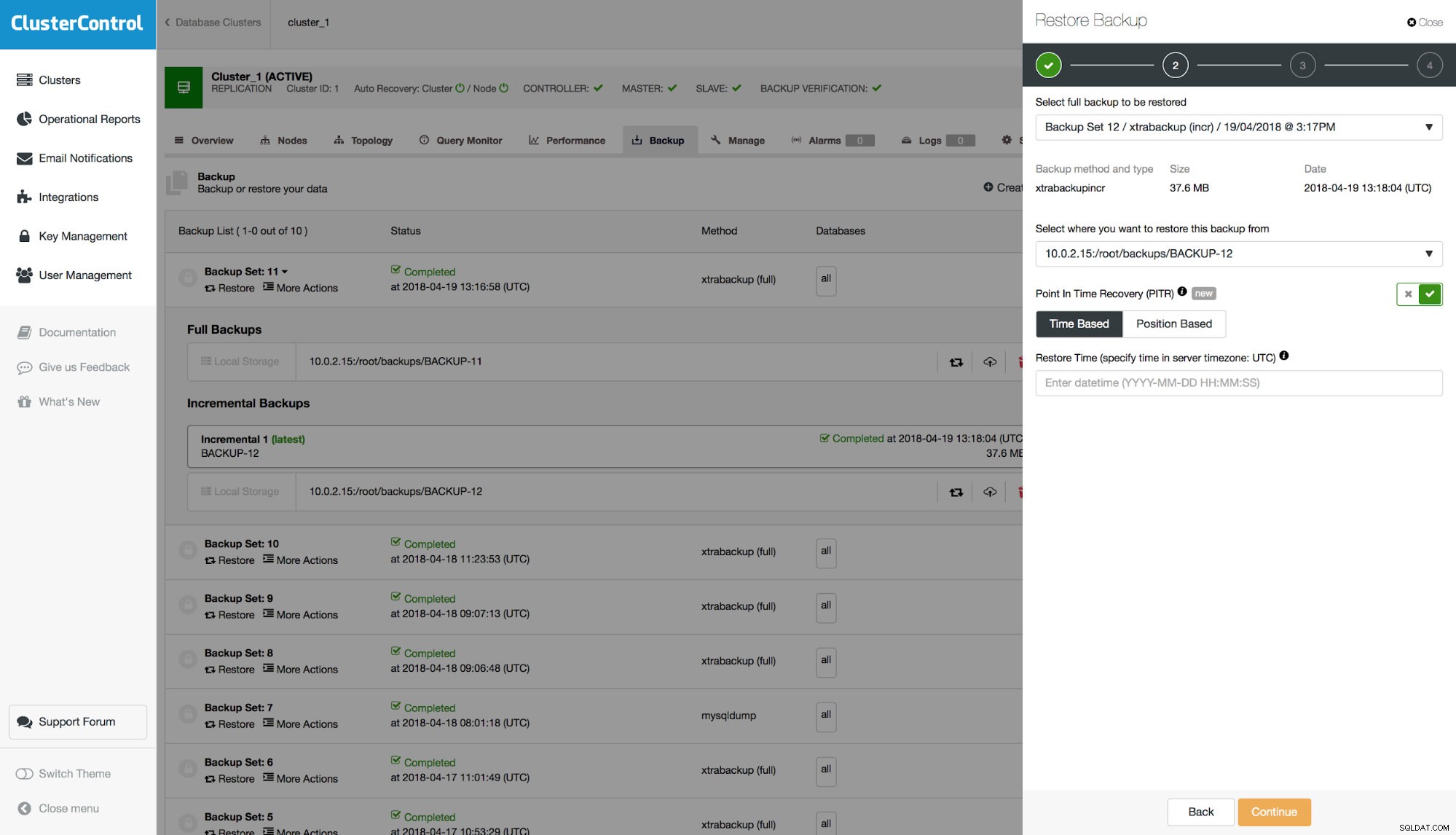
Se il backup è compatibile con PITR, verrà presentata un'opzione per eseguire un ripristino point-in-time. Avrai due opzioni per questo:"In base al tempo" e "In base alla posizione". Discutiamo della differenza tra queste due opzioni.
PITR "basato sul tempo"
Con questa opzione puoi passare una data e un'ora, fino alla quale il backup deve essere ripristinato. Può essere definito entro una seconda risoluzione. Non garantisce che tutti i dati vengano ripristinati perché, anche se si è molto precisi nella definizione dell'ora, nel corso di un secondo potrebbero essere registrati più eventi nel log binario. Diciamo che sai che la perdita di dati è avvenuta il 18 aprile, alle 10:00:01. Passi la seguente data e ora al modulo:"2018-04-18 10:00:00". Tieni presente che dovresti utilizzare un orario basato sulle impostazioni del fuso orario sul server del database su cui è stato creato il backup.
Può ancora accadere che la perdita di dati non sia stata la prima che si è verificata alle 10:00:01, quindi alcuni eventi andranno persi nel processo. Diamo un'occhiata a cosa significa.
Durante un secondo, più eventi possono essere registrati nei binlog. Consideriamo questo caso:
10:00:00 - eventi A,B,C,D,E,F
10:00:01 - eventi V,W,X,Y,Z
dove X è l'evento di perdita di dati. Con una granularità di un secondo, puoi ripristinare fino a tutto ciò che è accaduto alle 10:00:00 (quindi fino a F) o fino a 10:00:01 (fino a Z). L'ultimo caso non è di alcuna utilità poiché X verrebbe rieseguito. Nel primo caso, ci mancano V e W.
Ecco perché il ripristino basato sulla posizione è più preciso. Puoi dire "Voglio ripristinare fino a W".
Il ripristino basato sul tempo è il più preciso che puoi ottenere senza dover accedere ai registri binari e definire la posizione esatta in cui desideri ripristinare. Questo ci porta al secondo metodo per fare PITR.
PITR "basato sulla posizione"
Qui è richiesta una certa esperienza con gli strumenti da riga di comando per MySQL, in particolare l'utilità mysqlbinlog. D'altra parte, avrai il miglior controllo su come verrà effettuato il recupero.
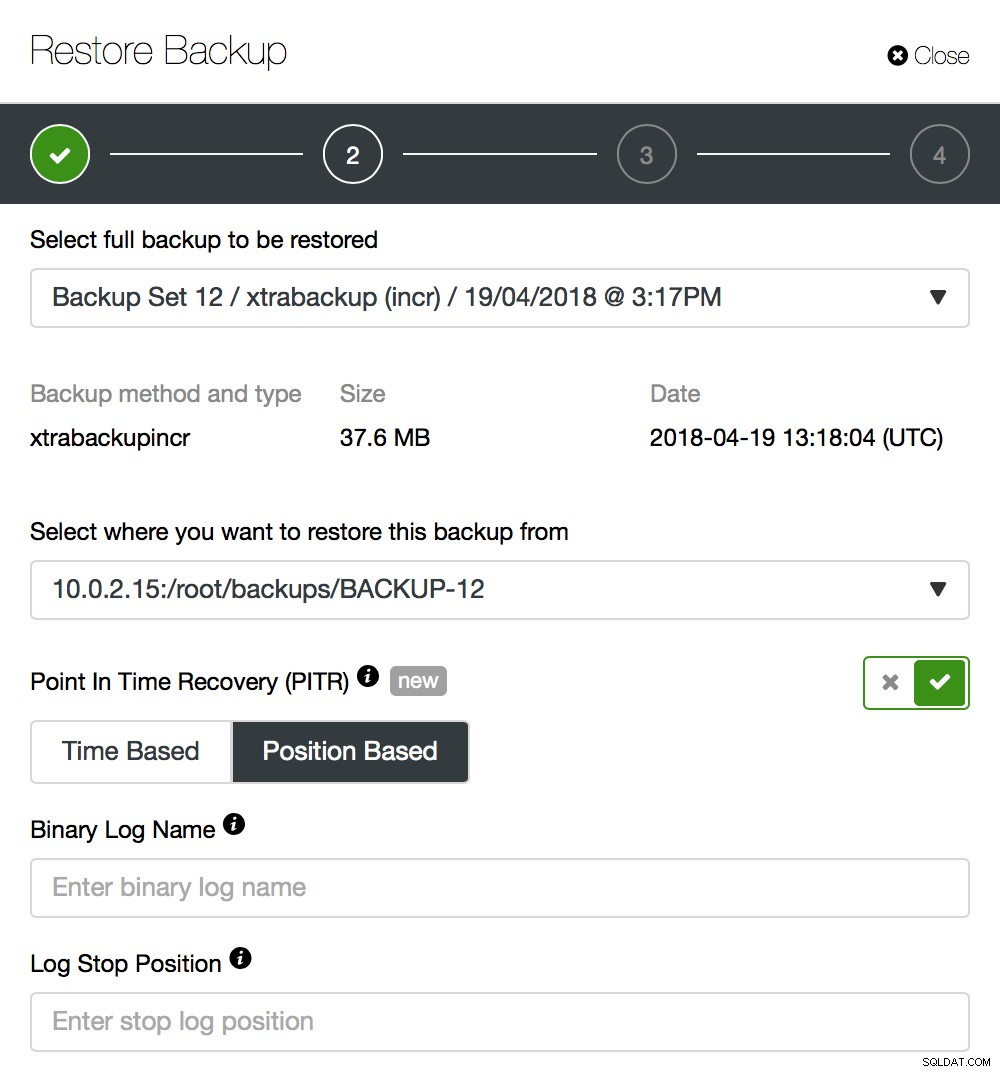
Esaminiamo un semplice esempio. Come puoi vedere nello screenshot sopra, dovrai passare un nome di registro binario e una posizione del registro binario fino a quel punto il backup dovrebbe essere ripristinato. Nella maggior parte dei casi, questa dovrebbe essere l'ultima posizione prima dell'evento di perdita di dati.
Qualcuno ha eseguito un comando SQL che ha provocato una grave perdita di dati:
mysql> DROP TABLE sbtest1;
Query OK, 0 rows affected (0.02 sec)La nostra applicazione ha subito iniziato a lamentarsi:
sysbench 1.1.0-ecf1191 (using bundled LuaJIT 2.1.0-beta3)
Running the test with following options:
Number of threads: 2
Report intermediate results every 1 second(s)
Initializing random number generator from current time
Initializing worker threads...
Threads started!
FATAL: mysql_drv_query() returned error 1146 (Table 'sbtest.sbtest1' doesn't exist) for query 'DELETE FROM sbtest1 WHERE id=5038'
FATAL: `thread_run' function failed: /usr/local/share/sysbench/oltp_common.lua:490: SQL error, errno = 1146, state = '42S02': Table 'sbtest.sbtest1' doesn't existAbbiamo un backup ma vogliamo ripristinare tutti i dati fino a quel momento fatale. Prima di tutto, assumiamo che l'applicazione non funzioni, quindi possiamo scartare tutte le scritture avvenute dopo la DROP TABLE come non importanti. Se la tua applicazione funziona in una certa misura, dovresti unire le modifiche rimanenti in seguito. Ok, esaminiamo i log binari per trovare la posizione dell'istruzione DROP TABLE. Poiché vogliamo evitare di analizzare tutti i log binari, scopriamo qual era la posizione coperta dal nostro ultimo backup. Puoi verificarlo esaminando i registri per l'ultimo set di backup e cercare una riga simile a questa:
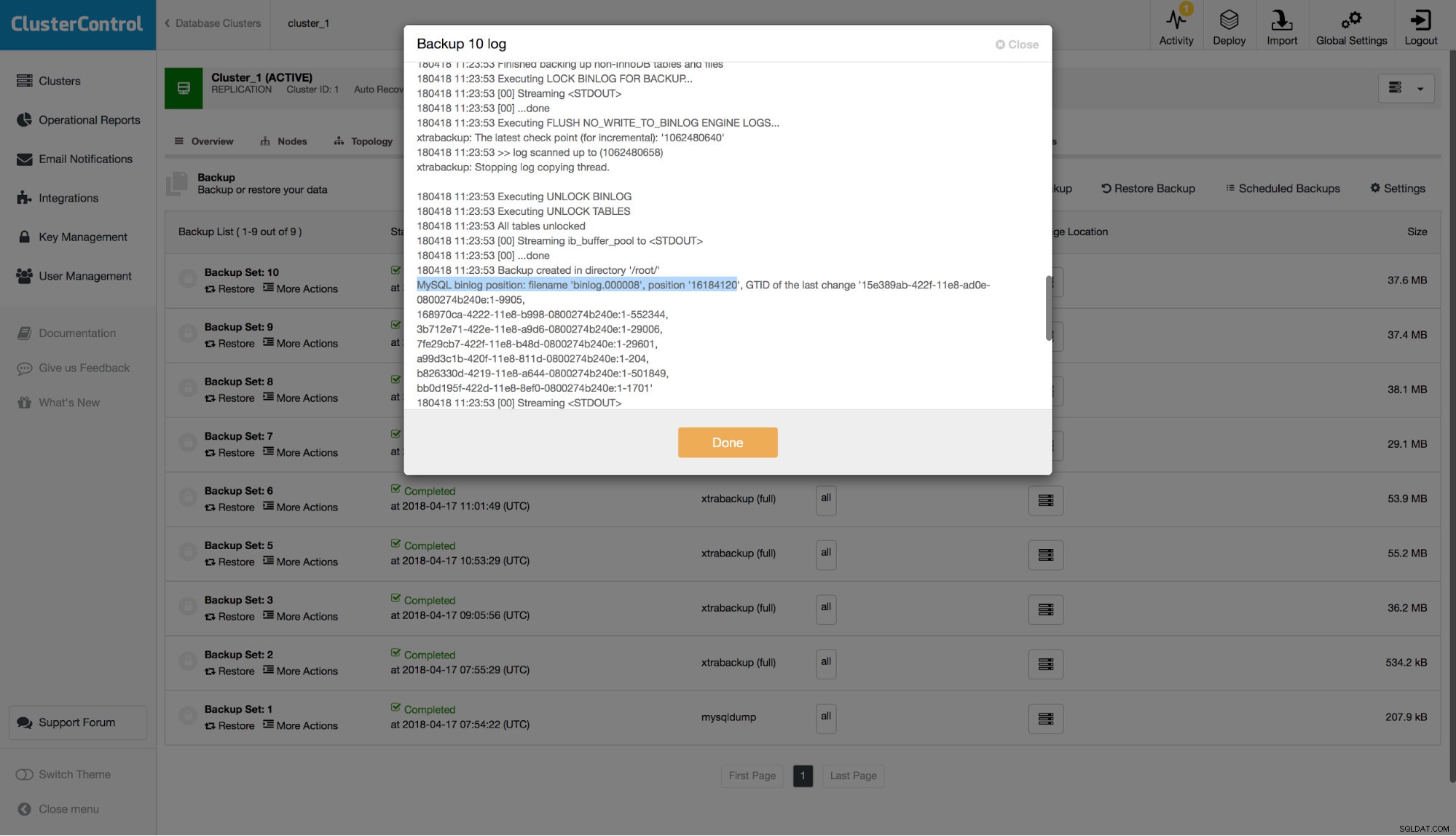
Quindi, stiamo parlando del nome del file "binlog.000008" e della posizione "16184120". Usiamo questo come punto di partenza. Controlliamo quali file di log binari abbiamo:
example@sqldat.com:~# ls -alh /var/lib/mysql/binlog.*
-rw-r----- 1 mysql mysql 58M Apr 17 08:31 /var/lib/mysql/binlog.000001
-rw-r----- 1 mysql mysql 116M Apr 17 08:59 /var/lib/mysql/binlog.000002
-rw-r----- 1 mysql mysql 379M Apr 17 09:30 /var/lib/mysql/binlog.000003
-rw-r----- 1 mysql mysql 344M Apr 17 10:54 /var/lib/mysql/binlog.000004
-rw-r----- 1 mysql mysql 892K Apr 17 10:56 /var/lib/mysql/binlog.000005
-rw-r----- 1 mysql mysql 74M Apr 17 11:03 /var/lib/mysql/binlog.000006
-rw-r----- 1 mysql mysql 5.2M Apr 17 11:06 /var/lib/mysql/binlog.000007
-rw-r----- 1 mysql mysql 21M Apr 18 11:35 /var/lib/mysql/binlog.000008
-rw-r----- 1 mysql mysql 59K Apr 18 11:35 /var/lib/mysql/binlog.000009
-rw-r----- 1 mysql mysql 144 Apr 18 11:35 /var/lib/mysql/binlog.indexQuindi, oltre a 'binlog.000008' abbiamo anche 'binlog.000009' da esaminare. Eseguiamo il comando che convertirà i log binari in formato SQL partendo dalla posizione che abbiamo trovato nel log di backup:
example@sqldat.com:~# mysqlbinlog --start-position='16184120' --verbose /var/lib/mysql/binlog.000008 /var/lib/mysql/binlog.000009 > binlog.outPer decodificare gli eventi basati su riga è necessario il nodo '--verbose'. Questo non è necessariamente richiesto per il DROP TABLE che stiamo cercando, ma per altri tipi di eventi potrebbe essere necessario.
Cerchiamo nel nostro output la query DROP TABLE:
example@sqldat.com:~# grep -B 7 -A 1 "DROP TABLE" binlog.out
# at 20885489
#180418 11:24:32 server id 1 end_log_pos 20885554 CRC32 0xb89f2e66 GTID last_committed=38168 sequence_number=38170 rbr_only=no
SET @@SESSION.GTID_NEXT= '7fe29cb7-422f-11e8-b48d-0800274b240e:38170'/*!*/;
# at 20885554
#180418 11:24:32 server id 1 end_log_pos 20885678 CRC32 0xb38a427b Query thread_id=54 exec_time=0 error_code=0
use `sbtest`/*!*/;
SET TIMESTAMP=1524050672/*!*/;
DROP TABLE `sbtest1` /* generated by server */
/*!*/;In questo esempio possiamo vedere due eventi. Innanzitutto, nella posizione di 20885489, imposta la variabile GTID_NEXT.
# at 20885489
#180418 11:24:32 server id 1 end_log_pos 20885554 CRC32 0xb89f2e66 GTID last_committed=38168 sequence_number=38170 rbr_only=no
SET @@SESSION.GTID_NEXT= '7fe29cb7-422f-11e8-b48d-0800274b240e:38170'/*!*/;In secondo luogo, nella posizione di 20885554 c'è il nostro evento DROP TABLE. Ciò porta alla conclusione che dovremmo eseguire il PITR fino alla posizione di 20885489. L'unica domanda a cui rispondere è di quale log binario stiamo parlando. Possiamo verificarlo cercando le voci di rotazione del binlog:
example@sqldat.com:~# grep "Rotate to binlog" binlog.out
#180418 11:35:46 server id 1 end_log_pos 21013114 CRC32 0x2772cc18 Rotate to binlog.000009 pos: 4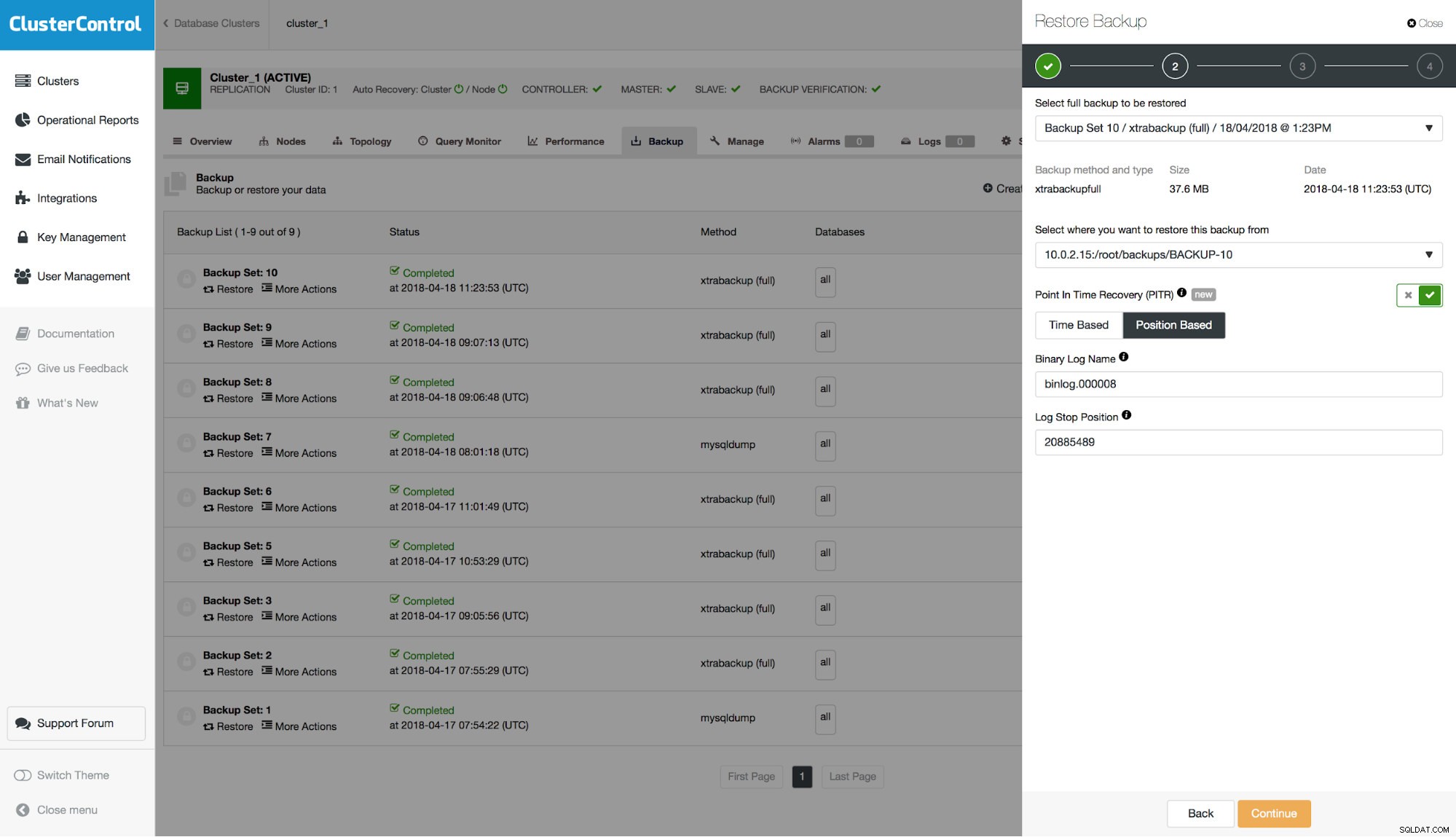
Come si può vedere chiaramente confrontando le date, la rotazione in binlog.000009 è avvenuta più tardi, quindi vogliamo passare binlog.000008 come file binlog nel modulo.
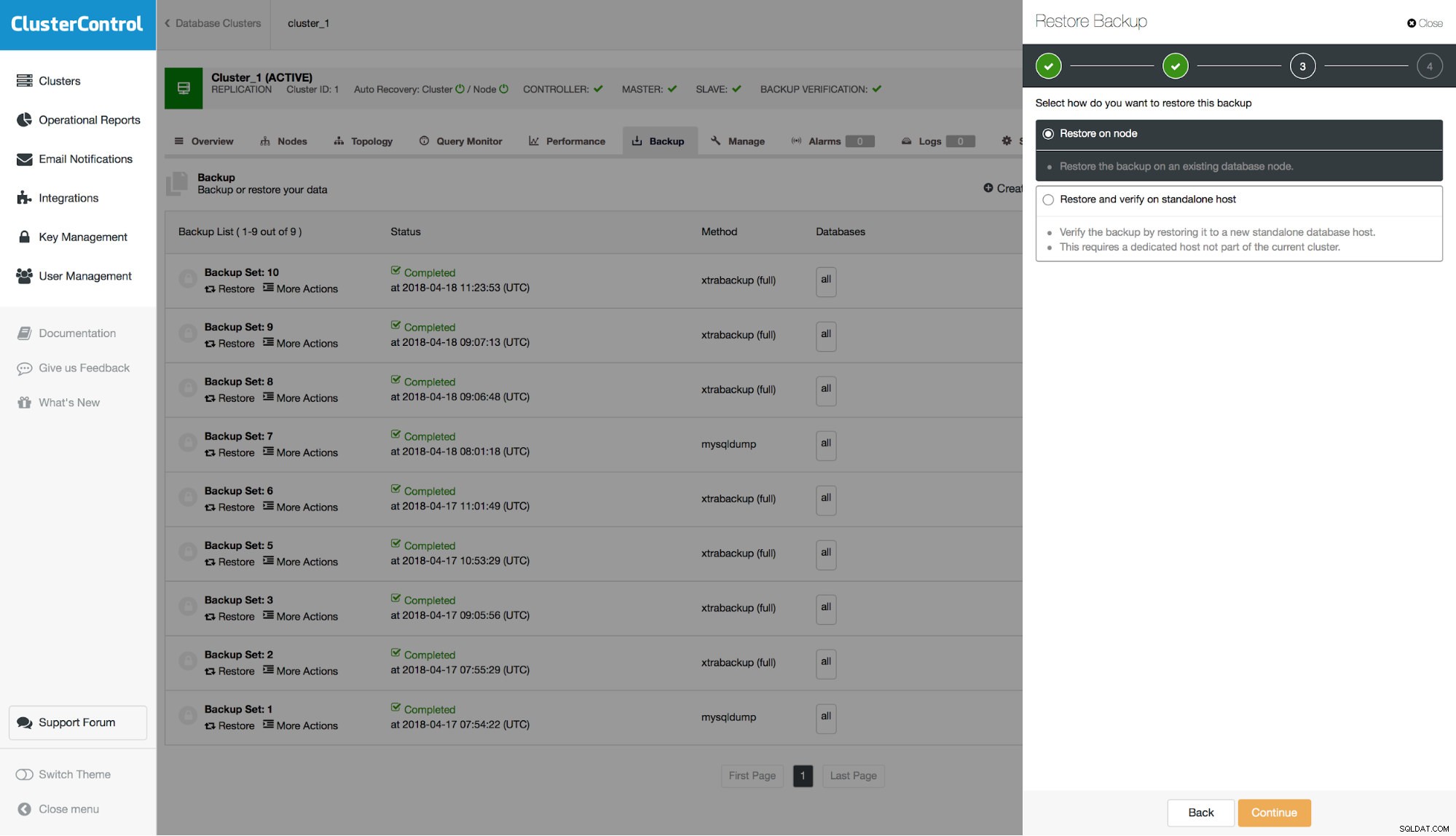
Successivamente, dobbiamo decidere se ripristinare il backup sul cluster o se vogliamo utilizzare un server esterno per ripristinarlo. Questa seconda opzione potrebbe essere utile se desideri ripristinare solo un sottoinsieme di dati. Puoi ripristinare il backup fisico completo su un host separato e quindi utilizzare mysqldump per scaricare i dati mancanti e caricarli sul server di produzione.
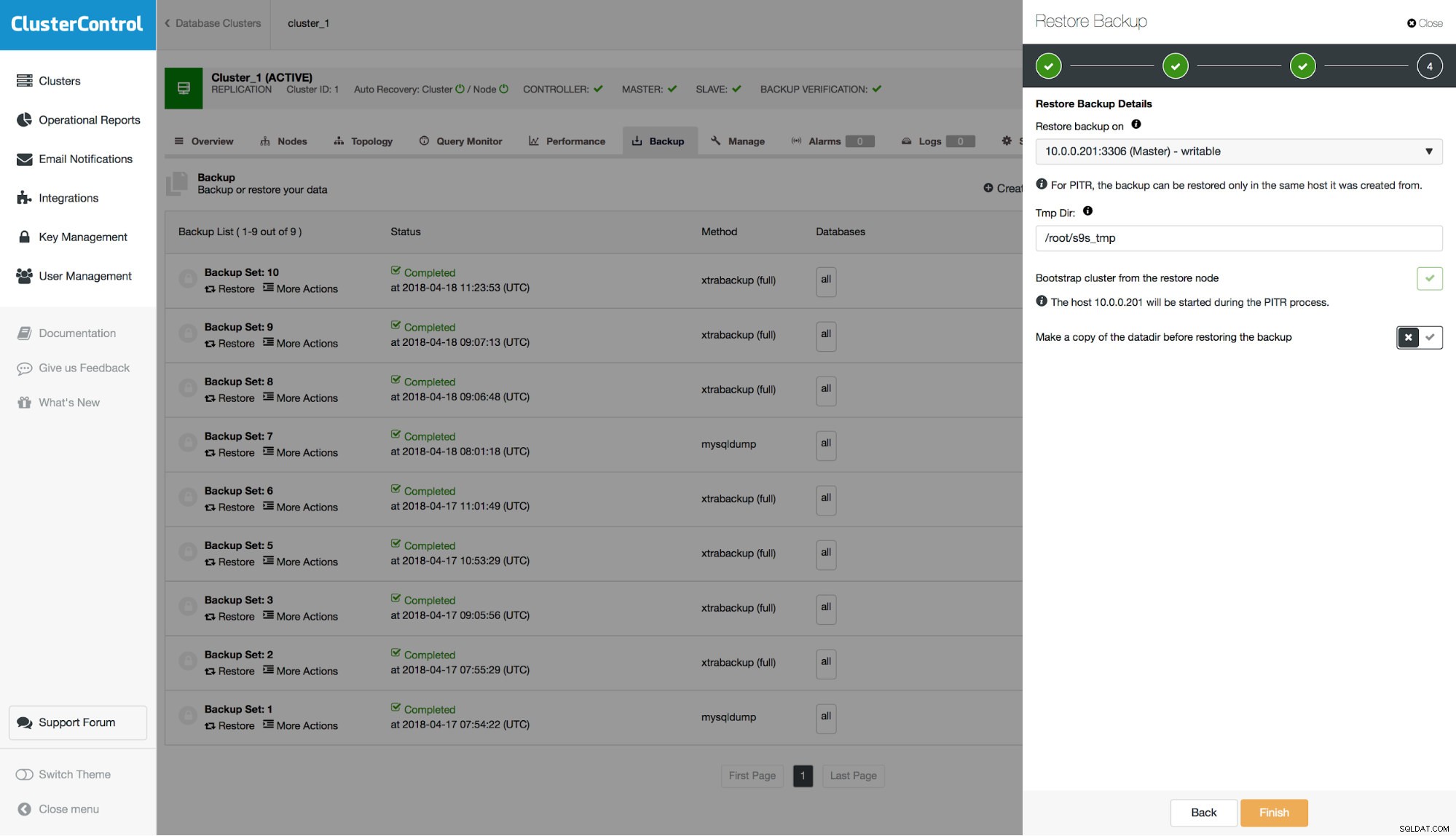
Tieni presente che quando ripristini il backup sul tuo cluster, dovrai ricostruire nodi diversi da quello che hai ripristinato. Nello scenario master - slave in genere si desidera ripristinare il backup sul master e quindi ricostruire gli slave da esso.
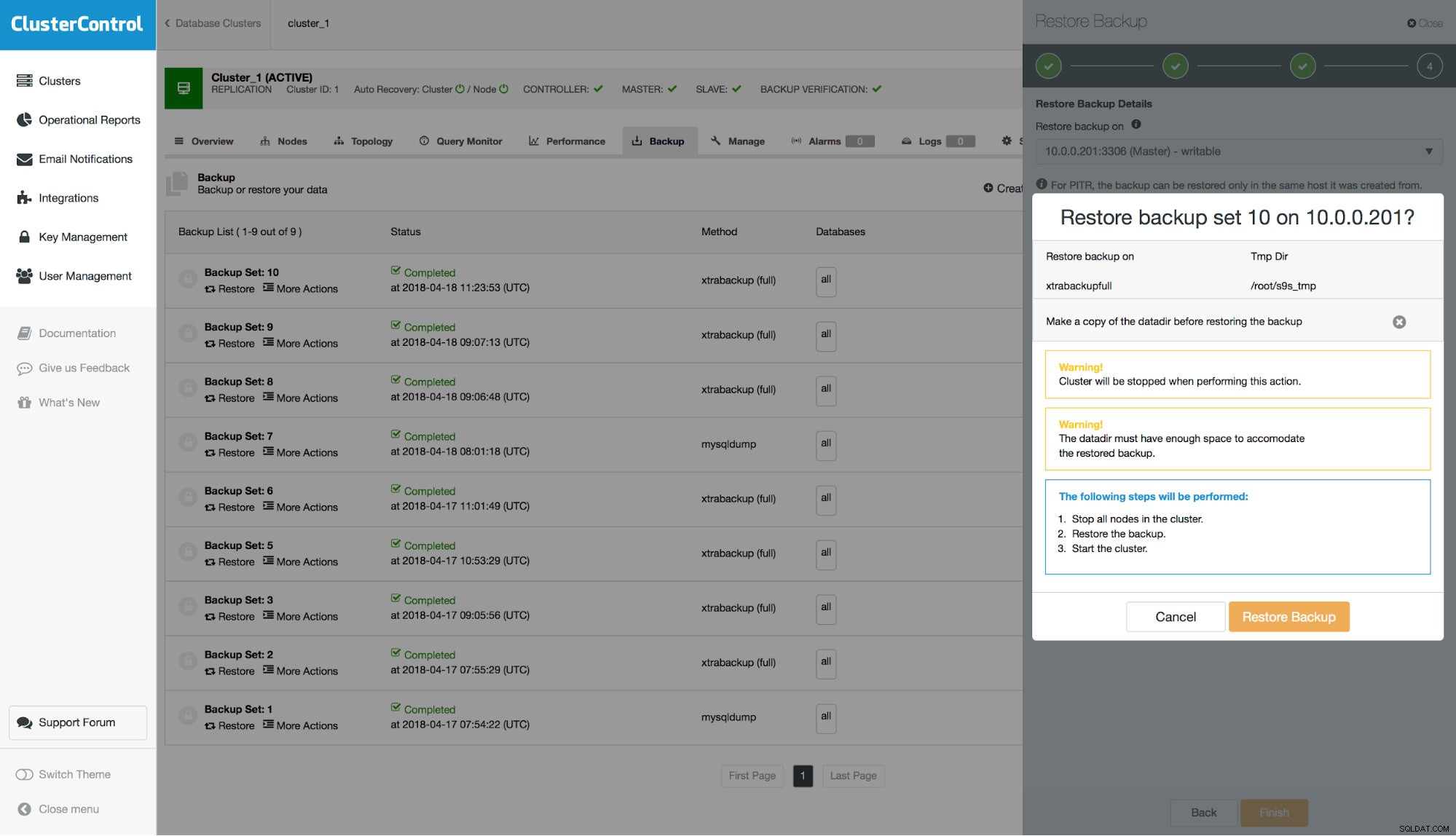
Come ultimo passaggio, vedrai un riepilogo delle azioni che ClusterControl eseguirà.
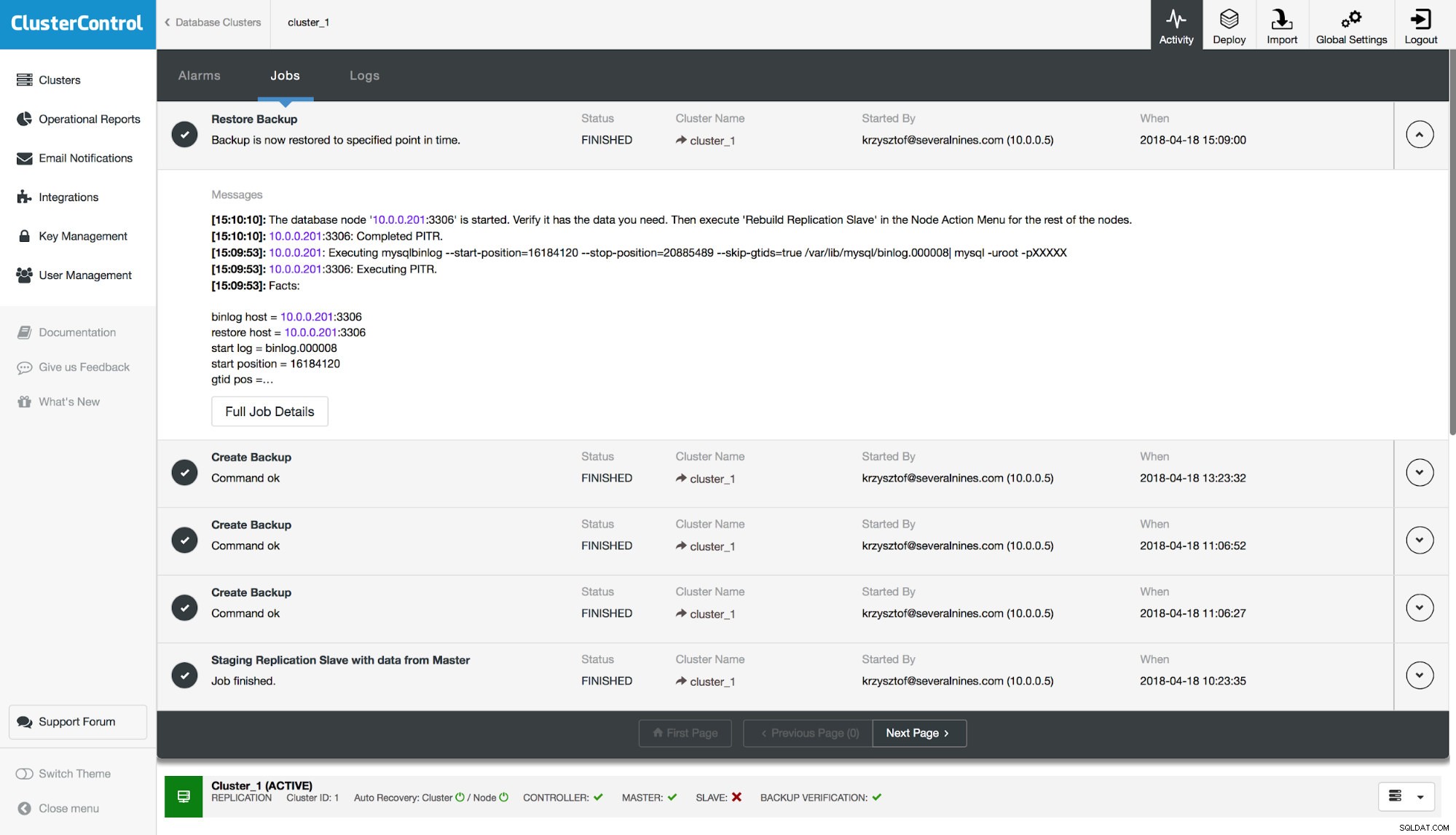
Infine, dopo il ripristino del backup, verificheremo se la tabella mancante è stata ripristinata o meno:
mysql> show tables from sbtest like 'sbtest1'\G
*************************** 1. row ***************************
Tables_in_sbtest (sbtest1): sbtest1
1 row in set (0.00 sec)Sembra tutto ok, siamo riusciti a ripristinare i dati mancanti.
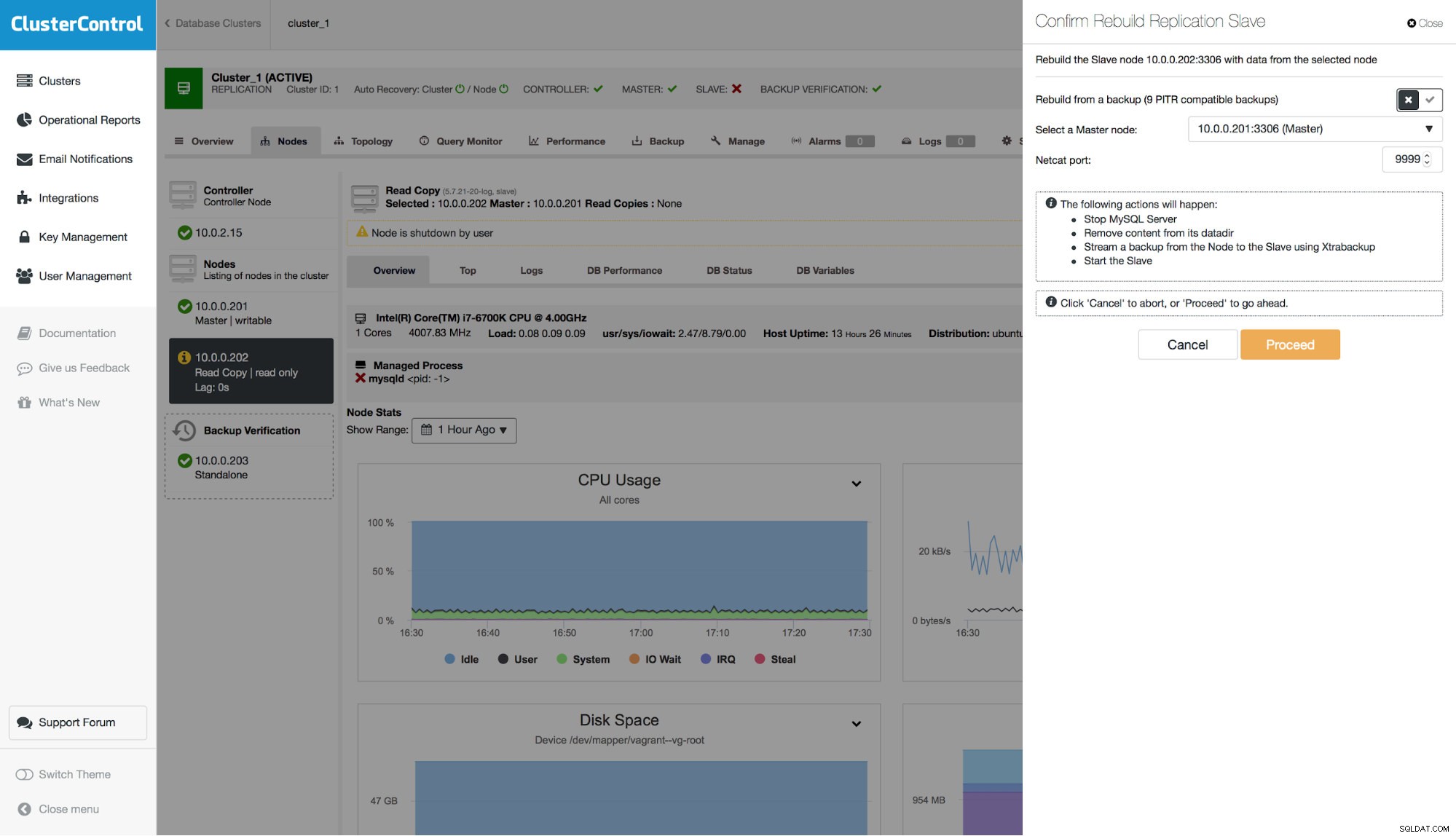
L'ultimo passo che dobbiamo compiere è ricostruire il nostro schiavo. Tieni presente che esiste un'opzione per utilizzare un backup PITR. Nell'esempio qui, ciò non è possibile in quanto lo slave replicherebbe l'evento DROP TABLE e finirebbe per non essere coerente con il master.