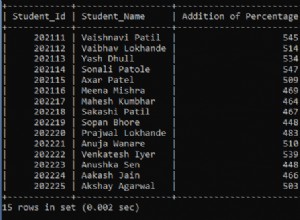
Archiviare ~3,5 TB di dati e inserire circa 1K/sec 24x7, e anche eseguire query a una velocità non specificata, è possibile con SQL Server, ma ci sono più domande:
- quale requisito di disponibilità hai per questo? Tempo di attività del 99,999% o è sufficiente il 95%?
- quale requisito di affidabilità hai? La mancanza di un inserto ti costa $ 1 milione?
- quale requisito di recuperabilità hai? Se perdi un giorno di dati, importa?
- quale requisito di coerenza hai? È necessario garantire che una scrittura sia visibile alla lettura successiva?
Se hai bisogno di tutti questi requisiti che ho evidenziato, il carico che proponi costerà milioni di hardware e licenze su un sistema relazionale, qualsiasi sistema, indipendentemente dagli espedienti che provi (sharding, partizionamento ecc.). Un sistema nosql, per loro stessa definizione, non soddisferebbe tutti questi requisiti.
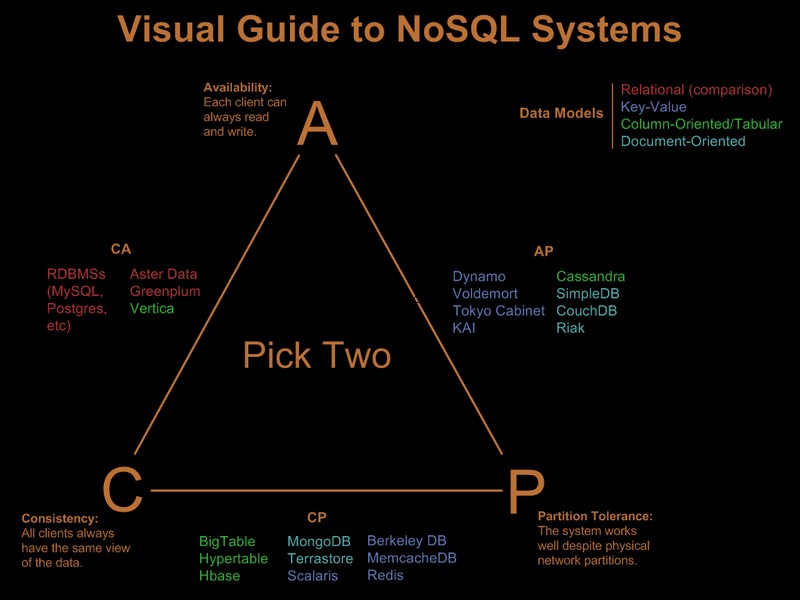
Quindi ovviamente hai già allentato alcuni di questi requisiti. C'è una bella guida visiva che confronta le offerte nosql basate sul paradigma "scegli 2 su 3" in Visual Guide to NoSQL Systems:
Dopo l'aggiornamento del commento OP
Con SQL Server questo sarebbe un'implementazione semplice:
- una chiave cluster (GUID, ora) di una singola tabella. Sì, verrà frammentato, ma la frammentazione influisce sui read-ahead e i read-ahead sono necessari solo per scansioni di intervalli significativi. Poiché esegui query solo per GUID e intervallo di date specifici, la frammentazione non avrà molta importanza. Sì, è una chiave ampia, quindi le pagine non a fogli avranno una scarsa densità di chiavi. Sì, porterà a un fattore di riempimento scadente. E sì, possono verificarsi divisioni di pagina. Nonostante questi problemi, dati i requisiti, è ancora la migliore scelta di chiavi cluster.
- partizionare la tabella in base al tempo in modo da poter implementare la cancellazione efficiente dei record scaduti, tramite una finestra scorrevole automatica. Aumenta questo con una ricostruzione della partizione dell'indice online dell'ultimo mese per eliminare il fattore di riempimento scadente e la frammentazione introdotti dal clustering GUID.
- abilita la compressione della pagina. Poiché i gruppi di chiavi raggruppati in base al GUID prima, tutti i record di un GUID saranno uno accanto all'altro, offrendo alla compressione della pagina una buona possibilità di distribuire la compressione del dizionario.
- avrai bisogno di un percorso IO veloce per il file di registro. Sei interessato a un throughput elevato, non a una bassa latenza per un registro che tenga il passo con 1.000 inserimenti/sec, quindi lo stripping è d'obbligo.
Il partizionamento e la compressione delle pagine richiedono ciascuno un SQL Server Enterprise Edition, non funzioneranno su Standard Edition ed entrambi sono molto importanti per soddisfare i requisiti.
Come nota a margine, se i record provengono da una farm di server Web front-end, inserirei Express su ciascun server Web e invece di INSERT sul back-end, SEND le informazioni al back-end, utilizzando una connessione/transazione locale sull'Express collocato insieme al server web. Questo dà una storia di disponibilità molto migliore alla soluzione.
Quindi è così che lo farei in SQL Server. La buona notizia è che i problemi che dovrai affrontare sono ben compresi e le soluzioni sono note. ciò non significa necessariamente che sia migliore di quello che potresti ottenere con Cassandra, BigTable o Dynamo. Lascerò che qualcuno più esperto in cose non sql-ish argomenta il loro caso.
Nota che non ho mai menzionato il modello di programmazione, il supporto .Net e simili. Onestamente penso che siano irrilevanti nelle grandi distribuzioni. Fanno un'enorme differenza nel processo di sviluppo, ma una volta implementati non importa quanto sia stato veloce lo sviluppo, se l'overhead ORM uccide le prestazioni :)