TimescaleDB è un database open source inventato per rendere SQL scalabile per dati di serie temporali. È un sistema di database relativamente nuovo. TimescaleDB è stato introdotto sul mercato due anni fa e ha raggiunto la versione 1.0 a settembre 2018. Tuttavia, è progettato su un sistema RDBMS maturo.
TimescaleDB è incluso in un pacchetto come estensione PostgreSQL. Tutto il codice è concesso in licenza in base alla licenza open source Apache-2, ad eccezione di alcuni codici sorgente relativi alle funzionalità aziendali di serie temporali concesse in licenza con la licenza Timescale (TSL).
In quanto database di serie temporali, fornisce il partizionamento automatico tra data e valori chiave. Il supporto SQL nativo di TimescaleDB lo rende una buona opzione per coloro che intendono archiviare dati di serie temporali e hanno già una solida conoscenza del linguaggio SQL.
Se stai cercando un database di serie temporali in grado di utilizzare Rich SQL, HA, una solida soluzione di backup, la replica e altre funzionalità aziendali, questo blog potrebbe metterti sulla strada giusta.
Quando utilizzare TimescaleDB
Prima di iniziare con le funzionalità di TimescaleDB, vediamo dove può adattarsi. TimescaleDB è stato progettato per offrire il meglio sia relazionale che NoSQL, con particolare attenzione alle serie temporali. Ma cosa sono i dati delle serie temporali?
I dati delle serie temporali sono al centro dell'Internet delle cose, dei sistemi di monitoraggio e di molte altre soluzioni incentrate sui dati che cambiano frequentemente. Come suggerisce il nome "serie temporali", stiamo parlando di dati che cambiano nel tempo. Le possibilità per questo tipo di DBMS sono infinite. Puoi usarlo in vari casi d'uso IoT industriali nel settore manifatturiero, minerario, petrolifero e del gas, vendita al dettaglio, assistenza sanitaria, monitoraggio delle operazioni di sviluppo o informazioni finanziarie. Può anche adattarsi perfettamente alle pipeline di machine learning o come fonte per operazioni e intelligence aziendali.
Non c'è dubbio che la domanda di IoT e soluzioni simili crescerà. Detto questo, possiamo anche aspettarci la necessità di analizzare ed elaborare i dati in molti modi diversi. I dati delle serie temporali in genere vengono solo aggiunti:è abbastanza improbabile che vengano aggiornati i vecchi dati. In genere non elimini righe particolari, d'altra parte, potresti volere una sorta di aggregazione dei dati nel tempo. Non vogliamo solo memorizzare come i nostri dati cambiano nel tempo, ma anche analizzarli e imparare da essi.
Il problema con i nuovi tipi di sistemi di database è che di solito utilizzano il proprio linguaggio di query. Ci vuole tempo perché gli utenti imparino una nuova lingua. La più grande differenza tra TimescaleDB e altri database di serie temporali popolari è il supporto per SQL. TimescaleDB supporta l'intera gamma di funzionalità SQL, inclusi aggregati basati sul tempo, join, sottoquery, funzioni di finestra e indici secondari. Inoltre, se la tua applicazione sta già utilizzando PostgreSQL, non sono necessarie modifiche al codice client.
Nozioni di base sull'architettura
TimescaleDB è implementato come estensione su PostgreSQL, il che significa che un database con scala temporale viene eseguito all'interno di un'istanza PostgreSQL complessiva. Il modello di estensione consente al database di sfruttare molti degli attributi di PostgreSQL come affidabilità, sicurezza e connettività a un'ampia gamma di strumenti di terze parti. Allo stesso tempo, TimescaleDB sfrutta l'alto grado di personalizzazione disponibile per le estensioni aggiungendo hook in profondità nel pianificatore di query, nel modello di dati e nel motore di esecuzione di PostgreSQL.
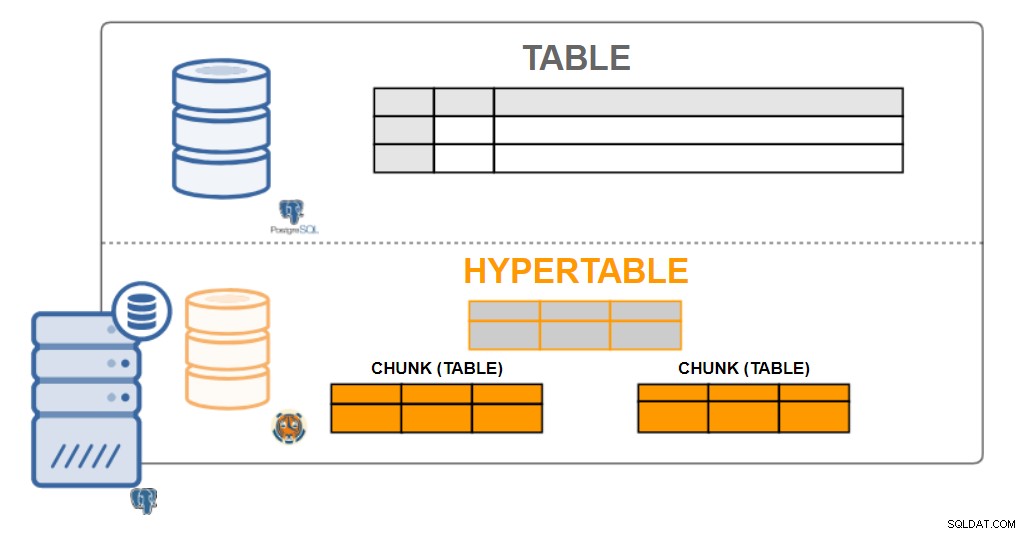 Architettura TimescaleDB
Architettura TimescaleDB Ipertabili
Dal punto di vista dell'utente, i dati di TimescaleDB sembrano tabelle singolari, chiamate hypertables. Le ipertabelle sono un concetto o una vista implicita di molte singole tabelle che contengono i dati chiamati blocchi. I dati della tabella iper possono essere una o due dimensioni. Può essere aggregato in base a un intervallo di tempo ea un valore (opzionale) di "chiave di partizione".
Praticamente tutte le interazioni dell'utente con TimescaleDB sono con hypertables. Creare tabelle, indici, modificare tabelle, selezionare dati, inserire dati... dovrebbero essere tutti eseguiti sull'ipertabella.
TimescaleDB esegue questo partizionamento esteso sia su distribuzioni a nodo singolo che su distribuzioni in cluster (in fase di sviluppo). Sebbene il partizionamento sia tradizionalmente utilizzato solo per la scalabilità orizzontale su più macchine, ci consente anche di scalare fino a velocità di scrittura elevate (e query parallelizzate migliorate) anche su macchine singole.
Supporto dati relazionali
Come database relazionale, ha il pieno supporto per SQL. TimescaleDB supporta modelli di dati flessibili che possono essere ottimizzati per diversi casi d'uso. Ciò rende Timescale leggermente diverso dalla maggior parte degli altri database di serie temporali. Il DBMS è ottimizzato per l'acquisizione rapida e le query complesse, basato su PostgreSQL e, quando necessario, abbiamo accesso a una solida elaborazione di serie temporali.
Installazione
TimescaleDB in modo simile a PostgreSQL supporta molti modi diversi di installazione, inclusa l'installazione su Ubuntu, Debian, RHEL/Centos, Windows o piattaforme cloud.
Uno dei modi più convenienti per giocare con TimescaleDB è un'immagine Docker.
Il comando seguente estrarrà un'immagine Docker da Docker Hub se non è già stata installata e quindi eseguirà.
docker run -d --name timescaledb -p 5432:5432 -e POSTGRES_PASSWORD=severalnines timescale/timescaledbPrimo utilizzo
Poiché la nostra istanza è attiva e funzionante, è ora di creare il nostro primo database timescaledb. Come puoi vedere di seguito, ci connettiamo tramite la console PostgreSQL standard, quindi se disponi di strumenti client PostgreSQL (ad es. psql) installati localmente, puoi utilizzarli per accedere all'istanza della finestra mobile TimescaleDB.
psql -U postgres -h localhost
CREATE DATABASE severalnines;
\c severalnines
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;Operazioni quotidiane
Dal punto di vista sia dell'uso che della gestione, TimescaleDB ha l'aspetto e la sensazione di PostgreSQL e può essere gestito e interrogato come tale.
I principali punti elenco per le operazioni quotidiane sono:
- Coesiste con altri TimescaleDB e database PostgreSQL su un server PostgreSQL.
- Utilizza SQL come linguaggio di interfaccia.
- Utilizza connettori PostgreSQL comuni per strumenti di terze parti per backup, console ecc.
Impostazioni TimescaleDB
Le impostazioni predefinite di PostgreSQL sono in genere troppo conservative per i server moderni e TimescaleDB. Dovresti assicurarti che le tue impostazioni postgresql.conf siano ottimizzate, usando timescaledb-tune o facendolo manualmente.
$ timescaledb-tuneLo script ti chiederà di confermare le modifiche. Queste modifiche vengono quindi scritte nel tuo postgresql.conf e avranno effetto al riavvio.
Ora, diamo un'occhiata ad alcune operazioni di base del tutorial TimescaleDB che possono darti un'idea di come lavorare con il nuovo sistema di database.
Per creare una hypertable, inizi con una normale tabella SQL e poi la converti in una hypertable tramite la funzione create_hypertable.
-- Create extension timescaledb
CREATE EXTENSION timescaledb;
Create a regular table
CREATE TABLE conditions (
time TIMESTAMPTZ NOT NULL,
location TEXT NOT NULL,
temperature DOUBLE PRECISION NULL,
humidity DOUBLE PRECISION NULL
);Convertirlo in hypertable è semplice come:
SELECT create_hypertable('conditions', 'time');L'inserimento dei dati nell'hypertable avviene tramite i normali comandi SQL:
INSERT INTO conditions(time, location, temperature, humidity)
VALUES (NOW(), 'office', 70.0, 50.0);La selezione dei dati è un vecchio buon SQL.
SELECT * FROM conditions ORDER BY time DESC LIMIT 10;Come possiamo vedere di seguito, possiamo eseguire un gruppo per, un ordine per e funzioni. Inoltre, TimescaleDB include funzioni per l'analisi di serie temporali che non sono presenti in vanilla PostgreSQL.
SELECT time_bucket('15 minutes', time) AS fifteen_min,
location, COUNT(*),
MAX(temperature) AS max_temp,
MAX(humidity) AS max_hum
FROM conditions
WHERE time > NOW() - interval '3 hours'
GROUP BY fifteen_min, location
ORDER BY fifteen_min DESC, max_temp DESC;