Nel caso non l'avessi visto, abbiamo appena rilasciato ClusterControl 1.7.5 con importanti miglioramenti e nuove utili funzionalità. Alcune delle funzionalità includono Cluster Wide Maintenance, supporto per la versione CentOS 8 e Debian 10, supporto per PostgreSQL 12, supporto per MongoDB 4.2 e Percona MongoDB v4.0, nonché il nuovo MySQL Freeze Frame.
Aspetta, ma cos'è un fermo immagine MySQL? È qualcosa di nuovo per MySQL?
Beh, non è qualcosa di nuovo all'interno del kernel MySQL stesso. È una nuova funzionalità aggiunta a ClusterControl 1.7.5 specifica per i database MySQL. Il MySQL Freeze Frame in ClusterControl 1.7.5 tratterà le seguenti cose:
- Istantanea dello stato di MySQL prima dell'errore del cluster.
- Istantanea dell'elenco dei processi MySQL prima dell'errore del cluster (disponibile a breve).
- Ispeziona gli incidenti del cluster nei rapporti operativi o dallo strumento a riga di comando s9s.
Questi sono preziosi insiemi di informazioni che possono aiutare a tracciare i bug e correggere i cluster MySQL/MariaDB quando le cose vanno male. In futuro, stiamo pianificando di includere anche le istantanee dei valori di stato di SHOW ENGINE InnoDB. Quindi, resta sintonizzato sulle nostre versioni future.
Nota che questa funzione è ancora in stato beta, prevediamo di raccogliere più set di dati mentre lavoriamo con i nostri utenti. In questo blog, ti mostreremo come sfruttare questa funzionalità, soprattutto quando hai bisogno di ulteriori informazioni durante la diagnosi del tuo cluster MySQL/MariaDB.
ClusterControl sulla gestione degli errori del cluster
Per gli errori del cluster, ClusterControl non fa nulla a meno che il ripristino automatico (cluster/nodo) non sia abilitato come di seguito:

Una volta abilitato, ClusterControl proverà a recuperare un nodo o ripristinare il cluster tramite visualizzare l'intera topologia del cluster.
Per MySQL, ad esempio in una replica master-slave, deve avere almeno un master attivo in un dato momento, indipendentemente dal numero di slave disponibili. ClusterControl tenta di correggere la topologia almeno una volta per i cluster di replica, ma fornisce più tentativi per la replica multi-master come NDB Cluster e Galera Cluster. Il ripristino del nodo tenta di ripristinare un nodo del database in errore, ad es. quando il processo è stato interrotto (arresto anomalo) o il processo ha subito un OOM (memoria insufficiente). ClusterControl si collegherà al nodo tramite SSH e proverà a far apparire MySQL. In precedenza abbiamo scritto sul blog come ClusterControl esegue il ripristino automatico del database e il failover, quindi visita questo articolo per saperne di più sullo schema per il ripristino automatico di ClusterControl.
Nella versione precedente di ClusterControl <1.7.5, quei tentativi di ripristino attivavano degli allarmi. Ma una cosa che i nostri clienti hanno perso era un rapporto sull'incidente più completo con informazioni sullo stato appena prima dell'errore del cluster. Fino a quando non ci siamo resi conto di questa carenza e abbiamo aggiunto questa funzionalità in ClusterControl 1.7.5. L'abbiamo chiamato "MySQL Freeze Frame". Il MySQL Freeze Frame, al momento della stesura di questo documento, offre un breve riepilogo degli incidenti che hanno portato a modifiche dello stato del cluster appena prima dell'arresto anomalo. Soprattutto, include alla fine del report l'elenco degli host e le loro variabili e valori MySQL Global Status.
In che modo MySQL Freeze Frame differisce dal ripristino automatico?
Il MySQL Freeze Frame non fa parte del ripristino automatico di ClusterControl. Indipendentemente dal fatto che il ripristino automatico sia disabilitato o abilitato, MySQL Freeze Frame farà sempre il suo lavoro fintanto che viene rilevato un errore del cluster o del nodo.
Come funziona MySQL Freeze Frame?
In ClusterControl, ci sono alcuni stati che classifichiamo come diversi tipi di stato del cluster. MySQL Freeze Frame genererà un rapporto sull'incidente quando vengono attivati questi due stati:
- CLUSTER_DEGRADED
- CLUSTER_FAILURE
In ClusterControl, un CLUSTER_DEGRADED è quando puoi scrivere su un cluster, ma uno o più nodi sono inattivi. Quando ciò accade, ClusterControl genererà il rapporto sull'incidente.
Per CLUSTER_FAILURE, sebbene la sua nomenclatura si spieghi da sola, è lo stato in cui il tuo cluster non riesce e non è più in grado di elaborare letture o scritture. Allora quello è uno stato CLUSTER_FAILURE. Indipendentemente dal fatto che un processo di ripristino automatico stia tentando di risolvere il problema o che sia disabilitato, ClusterControl genererà il rapporto dell'incidente.
Come si attiva MySQL Freeze Frame?
Il MySQL Freeze Frame di ClusterControl è abilitato per impostazione predefinita e genera un rapporto di incidente solo quando vengono attivati o rilevati gli stati CLUSTER_DEGRADED o CLUSTER_FAILURE. Quindi non c'è bisogno da parte dell'utente di impostare alcuna impostazione di configurazione di ClusterControl, ClusterControl lo farà automaticamente per te.
Individuazione del rapporto sull'incidente del fermo immagine di MySQL
Al momento della stesura di questo articolo, ci sono 4 modi per individuare il rapporto dell'incidente. Questi possono essere trovati eseguendo le seguenti sezioni di seguito.
Utilizzo della scheda Rapporti operativi
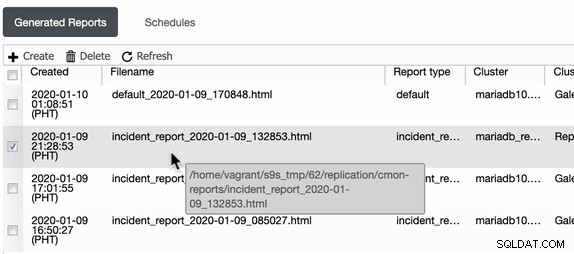
I report operativi delle versioni precedenti vengono utilizzati solo per creare, pianificare o elencare i report operativi che sono stati generati dagli utenti. Dalla versione 1.7.5, abbiamo incluso il rapporto sull'incidente generato dalla nostra funzione MySQL Freeze Frame. Vedi l'esempio seguente:
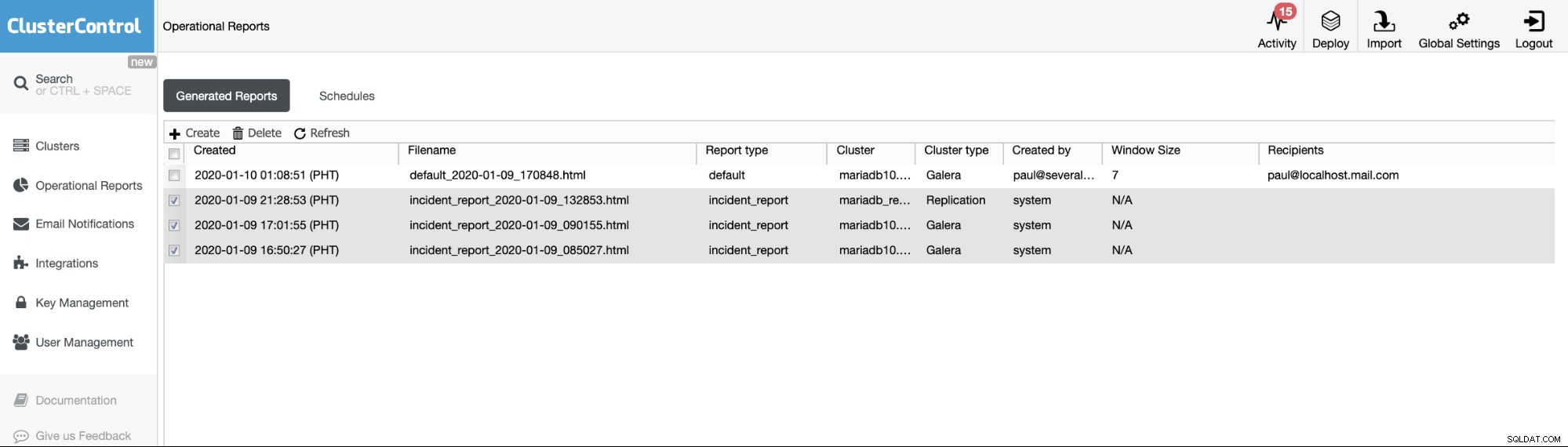
Gli elementi selezionati o gli elementi con Tipo di rapporto ==report_incidente sono l'incidente report generati dalla funzione MySQL Freeze Frame in ClusterControl.
Utilizzo dei rapporti di errore
Selezionando il cluster e generando un report di errore, ovvero seguendo questo processo:
Utilizzo della riga di comando CLI di s9s
In un rapporto di incidente generato, include istruzioni o suggerimenti su come utilizzarlo con il comando CLI di s9s. Di seguito è riportato ciò che viene mostrato nel rapporto sull'incidente:
Suggerimento! L'utilizzo dello strumento CLI di s9s ti consente di raccogliere facilmente i dati in questo rapporto, ad esempio:
s9s report --list --long
s9s report --cat --report-id=NQuindi, se desideri individuare e generare un rapporto di errore, puoi utilizzare questo approccio:
[example@sqldat.com ~]$ s9s report --list --long --cluster-id=60
ID CID TYPE CREATED TITLE
19 60 incident_report 16:50:27 Incident Report - Cluster Failed
20 60 incident_report 17:01:55 Incident ReportSe voglio eseguire il grep delle variabili wsrep_* su un host specifico, posso fare quanto segue:
[example@sqldat.com ~]$ s9s report --cat --report-id=20 --cluster-id=60|sed -n '/WSREP.*/p'|sed 's/ */ /g'|grep '192.168.10.80'|uniq -d
| WSREP_APPLIER_THREAD_COUNT | 4 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_CONF_ID | 18446744073709551615 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_SIZE | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_DELAYED | 27ac86a9-3254-11ea-b104-bb705eb13dde:tcp://192.168.10.100:4567:1,9234d567-3253-11ea-92d3-b643c178d325:tcp://192.168.10.90:4567:1,9234d567-3253-11ea-92d4-b643c178d325:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25e-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25f-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b260-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b261-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b262-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b263-cfcbda888ea9:tcp://192.168.10.90:4567:1,b0b7cb15-3241-11ea-bdbc-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbd-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbe-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbf-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdc0-1a21deddc100:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b321-9a836d562a47:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b322-9a836d562a47:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ab-e298880f3348:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ac-e298880f3348:tcp://192.168.10.100:4567:1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_GCOMM_UUID | 781facbc-3241-11ea-8a22-d74e5dcf7e08 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LAST_COMMITTED | 443 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_CACHED_DOWNTO | 98 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_RECV_QUEUE_MAX | 2 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROTOCOL_VERSION | 10 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROVIDER_VERSION | 26.4.3(r4535) | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED | 112 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED_BYTES | 14413 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED_BYTES | 40592 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_DATA_BYTES | 31734 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS_BYTES | 2752 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_ROLLBACKER_THREAD_COUNT | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_THREAD_COUNT | 5 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_REPL_LATENCY | 4.508e-06/4.508e-06/4.508e-06/0/1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |Individuazione manuale tramite il percorso del file di sistema
ClusterControl genera questi rapporti sugli incidenti nell'host in cui viene eseguito ClusterControl. ClusterControl crea una directory in /home/
Ci sono pericoli o avvertenze quando si utilizza MySQL Freeze Frame?
ClusterControl non cambia né modifica nulla nei tuoi nodi o cluster MySQL. MySQL Freeze Frame leggerà semplicemente SHOW GLOBAL STATUS (a partire da questo momento) a intervalli specifici per salvare i record poiché non possiamo prevedere lo stato di un nodo o cluster MySQL quando può andare in crash o quando può avere problemi hardware o disco. Non è possibile prevederlo, quindi salviamo i valori e quindi possiamo generare un rapporto di incidente nel caso in cui un particolare nodo si interrompa. In tal caso, il pericolo di avere questo è quasi nullo. Può teoricamente aggiungere una serie di richieste client ai server nel caso in cui alcuni blocchi siano mantenuti all'interno di MySQL, ma non l'abbiamo ancora notato. La serie di test non lo mostra, quindi saremmo lieti se tu potessi lasciare conoscerci o presentare un ticket di supporto in caso di problemi.
Ci sono alcune situazioni in cui un rapporto di incidente potrebbe non essere in grado di raccogliere variabili di stato globali se un problema di rete era il problema prima che ClusterControl bloccasse un frame specifico per raccogliere i dati. Questo è del tutto ragionevole perché non c'è modo in cui ClusterControl possa raccogliere dati per ulteriori diagnosi poiché in primo luogo non c'è connessione al nodo.
Infine, potresti chiederti perché non tutte le variabili sono mostrate nella sezione GLOBAL STATUS? Nel frattempo, impostiamo un filtro in cui i valori vuoti o 0 sono esclusi nel rapporto dell'incidente. Il motivo è che vogliamo risparmiare spazio su disco. Una volta che questi rapporti sugli incidenti non sono più necessari, puoi eliminarli tramite la scheda Rapporti operativi.
Test della funzione di fermo immagine di MySQL
Crediamo che tu sia impaziente di provare questo e vedere come funziona. Ma per favore, assicurati di non eseguirlo o testarlo in un ambiente live o di produzione. Tratteremo 2 fasi dello scenario in MySQL/MariaDB, una per la configurazione master-slave e una per la configurazione di tipo Galera.
Scenario di test di configurazione master-slave
In una configurazione master-slave, è facile e semplice da provare.
Fase uno
Assicurati di aver disabilitato le modalità di ripristino automatico (Cluster e Node), come di seguito:

quindi non proverà o tenterà di correggere lo scenario di test.
Fase due
Vai al tuo nodo Master e prova a impostare in sola lettura:
example@sqldat.com[mysql]> set @@global.read_only=1;
Query OK, 0 rows affected (0.000 sec)Fase tre
Questa volta è stato lanciato un allarme e quindi è stato generato un rapporto sull'incidente. Guarda di seguito come appare il mio cluster:

e l'allarme è stato attivato:

e il rapporto sull'incidente è stato generato:

Scenario di test per l'installazione del cluster Galera
Per la configurazione basata su Galera, dobbiamo assicurarci che il cluster non sia più disponibile, ovvero un errore a livello di cluster. A differenza del test Master-Slave, puoi abilitare il ripristino automatico poiché giocheremo con le interfacce di rete.
Nota:per questa configurazione, assicurati di avere più interfacce se stai testando i nodi in un'istanza remota poiché non puoi portare l'interfaccia in alto quando si scende dall'interfaccia a cui sei connesso.
Fase uno
Crea un cluster Galera a 3 nodi (ad esempio usando vagrant)
Fase due
Emetti il comando (proprio come di seguito) per simulare un problema di rete e farlo su tutti i nodi
[example@sqldat.com ~]# ifdown eth1
Device 'eth1' successfully disconnected.Fase tre
Ora, ha rimosso il mio cluster e ha questo stato:

ha lanciato un allarme,

e genera un rapporto sull'incidente:

Per un esempio di rapporto sull'incidente, puoi utilizzare questo file non elaborato e salvarlo come html.
È abbastanza semplice provare, ma ancora una volta, esegui questa operazione solo in un ambiente non live e non di produzione.
Conclusione
MySQL Freeze Frame in ClusterControl può essere utile durante la diagnosi degli arresti anomali. Durante la risoluzione dei problemi, sono necessarie molte informazioni per determinare la causa ed è esattamente ciò che fornisce MySQL Freeze Frame.