Il Service Pack 2 per SQL Server 2014 è stato rilasciato il mese scorso (leggi le note sulla versione qui) e include una nuova istruzione DBCC:DBCC CLONEDATABASE . Sono stato piuttosto entusiasta di vedere questo comando introdotto, in quanto fornisce un comando molto semplice modo per copiare uno schema di database, incluse le statistiche , che può essere utilizzato per testare le prestazioni delle query senza richiedere tutto lo spazio necessario per i dati nel database. Ho finalmente trovato del tempo per testare DBCC CLONEDATABASE e capire i limiti, e devo dire che è stato piuttosto divertente.
Nozioni di base
Ho iniziato creando un clone del database AdventureWorks2014 ed eseguendo una query sul database di origine e quindi sul database clone:
DBCC CLONEDATABASE (N'AdventureWorks2014', N'AdventureWorks2014_CLONE'); GO SET STATISTICS IO ON; GO SET STATISTICS TIME ON; GO SET STATISTICS XML ON; GO USE [AdventureWorks2014]; GO SELECT * FROM [Sales].[SalesOrderHeader] [h] JOIN [Sales].[SalesOrderDetail] [d] ON [h].[SalesOrderID] = [d].[SalesOrderID] ORDER BY [SalesOrderDetailID]; GO USE [AdventureWorks2014_CLONE]; GO SELECT * FROM [Sales].[SalesOrderHeader] [h] JOIN [Sales].[SalesOrderDetail] [d] ON [h].[SalesOrderID] = [d].[SalesOrderID] ORDER BY [SalesOrderDetailID]; GO SET STATISTICS IO OFF; GO SET STATISTICS TIME OFF; GO SET STATISTICS XML OFF; GO
Se osservo l'output di I/O e TIME, posso vedere che la query sul database di origine ha richiesto più tempo e ha generato molto più I/O, entrambi previsti poiché il database clone non contiene dati:
/* database FONTE */
Tempi di esecuzione di SQL Server:
Tempo CPU =0 ms, tempo trascorso =0 ms.
Tempo di analisi e compilazione di SQL Server:
Tempo CPU =0 ms, tempo trascorso =4 ms.
(121317 righe interessate)
Tabella 'SalesOrderHeader'. Conteggio scansioni 0, letture logiche 371567, letture fisiche 0, letture read-ahead 0, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
Tavolo 'Tavolo da lavoro'. Conteggio scansioni 0, letture logiche 0, letture fisiche 0, letture read-ahead 0, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
Tabella 'Dettagli ordini di vendita'. Conteggio scansioni 5, letture logiche 1361, letture fisiche 0, letture read-ahead 0, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
Tavolo 'Tavolo da lavoro'. Conteggio scansioni 0, letture logiche 0, letture fisiche 0, letture read-ahead 0, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
(1 riga/i interessata/e)
Tempi di esecuzione di SQL Server:
Tempo CPU =686 ms, tempo trascorso =2548 ms.
/* CLONE database */
Tempi di esecuzione di SQL Server:
Tempo CPU =0 ms, tempo trascorso =0 ms.
Tempo di analisi e compilazione di SQL Server:
Tempo CPU =12 ms, tempo trascorso =12 ms.
(0 righe interessate)
Tavolo 'Tavolo da lavoro'. Conteggio scansioni 0, letture logiche 0, letture fisiche 0, letture read-ahead 0, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
Tabella 'SalesOrderHeader'. Conteggio scansioni 0, letture logiche 0, letture fisiche 0, letture read-ahead 0, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
Tabella 'Dettagli ordini di vendita'. Conteggio scansioni 5, letture logiche 0, letture fisiche 0, letture read-ahead 0, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
(1 riga/i interessata/e)
Tempi di esecuzione di SQL Server:
Tempo CPU =0 ms, tempo trascorso =83 ms.
Se guardo i piani di esecuzione, sono gli stessi per entrambi i database ad eccezione dei valori effettivi (la quantità di dati effettivamente spostati attraverso il piano):
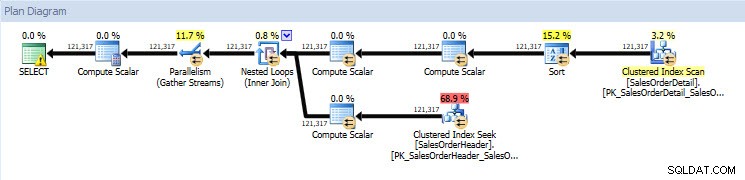 Piano di query per il database AdventureWorks2014
Piano di query per il database AdventureWorks2014
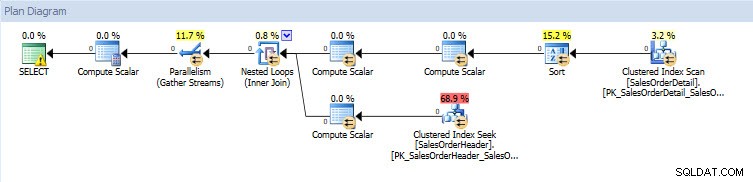 Piano di query per il database AdventureWorks2014_CLONE
Piano di query per il database AdventureWorks2014_CLONE
Qui è dove il valore di DBCC CLONEDATABASE è evidente:posso ottenere una copia vuota di un database a chiunque (assistenza prodotti Microsoft, il mio collega DBA, ecc.) e fargli ricreare e analizzare un problema, e non hanno bisogno potenzialmente di centinaia di GB di spazio su disco per farlo esso. Il post del martedì T-SQL di luglio di Melissa contiene informazioni dettagliate su ciò che accade durante il processo di clonazione, quindi ti consiglio di leggerlo per ulteriori informazioni.
È così?
Ma... posso fare di più con DBCC CLONEDATABASE ? Voglio dire, è fantastico, ma penso che ci siano molte altre cose che posso fare con una copia vuota del database. Se leggi la documentazione per DBCC CLONEDATABASE , vedrai questa riga:
Il mio primo pensiero è stato:"ottimizzatore di query - ehm... posso usarlo come opzione per testare aggiornamenti ?"
Bene, il database clonato è di sola lettura, ma ho pensato di provare comunque a cambiare alcune opzioni. Ad esempio, se potessi modificare la modalità di compatibilità, sarebbe davvero interessante, poiché potrei testare le modifiche CE in SQL Server 2014 e SQL Server 2016.
USE [master]; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET COMPATIBILITY_LEVEL = 110;
Ricevo un errore:
Msg 3906, livello 16, stato 1Impossibile aggiornare il database "AdventureWorks2014_CLONE" perché il database è di sola lettura.
Msg 5069, livello 16, stato 1
Istruzione ALTER DATABASE non riuscita.
Hm. Posso cambiare il modello di recupero?
ALTER DATABASE [AdventureWorks2014_CLONE] SET RECOVERY SIMPLE WITH NO_WAIT;
Io posso. Non sembra giusto. Bene, è di sola lettura, posso cambiarlo?
ALTER DATABASE [AdventureWorks2014_CLONE] SET READ_WRITE WITH NO_WAIT;
SÌ! Prima che ti ecciti troppo, lasciami lasciare questa nota dalla documentazione proprio qui:
Nota Il database appena generato generato da DBCC CLONEDATABASE non è supportato per l'uso come database di produzione ed è destinato principalmente a scopi diagnostici e di risoluzione dei problemi. Si consiglia di scollegare il database clonato dopo la creazione del database.Ripeterò questa riga della documentazione, la metterò in grassetto e la metterò in rosso come un'espressione amichevole ma estremamente importante promemoria:
Il database appena generato generato da DBCC CLONEDATABASE non è supportato per essere utilizzato come database di produzione ed è destinato principalmente a scopi diagnostici e di risoluzione dei problemi.Bene, per me va bene, sicuramente non l'avrei usato per la produzione, ma ora posso usarlo per i test! ORA posso cambiare la modalità di compatibilità e ORA posso eseguirne il backup e ripristinarlo su un'altra istanza per il test!
USE [master]; GO BACKUP DATABASE [AdventureWorks2014_CLONE] TO DISK = N'C:\Backups\AdventureWorks2014_CLONE.bak' WITH INIT, NOFORMAT, STATS = 10, NAME = N'AW2014_CLONE_full'; GO /* restore on SQL Server 2016 */ RESTORE DATABASE [AdventureWorks2014_CLONE] FROM DISK = N'C:\Backups\AdventureWorks2014_CLONE.bak' WITH MOVE N'AdventureWorks2014_Data' TO N'C:\Databases\AdventureWorks2014_Data_2684624044.mdf', MOVE N'AdventureWorks2014_Log' TO N'C:\Databases\AdventureWorks2014_Log_3195542593.ldf', NOUNLOAD, REPLACE, STATS = 5; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET COMPATIBILITY_LEVEL = 130; GO
QUESTO È GRANDE.
Nel mio ultimo post ho parlato di trace flag 2389 e di test con il nuovo Cardinality Estimator perché, amici, avete necessità da testare con il nuovo CE prima dell'aggiornamento. Se non esegui il test e se modifichi la modalità di compatibilità su 120 (SQL Server 2014) o 130 (SQL Server 2016) come parte dell'aggiornamento, corri il rischio di lavorare in modalità antincendio se ti imbatti in regressioni con la nuova CE. Ora potresti stare bene e le prestazioni potrebbero essere ancora migliori dopo l'aggiornamento. Ma... non vorresti esserne certo?
Molto spesso quando menziono i test prima di un aggiornamento, mi viene detto che non esiste un ambiente in cui eseguire i test. So che alcuni di voi hanno un ambiente di test. Alcuni di voi hanno Test, Dev, QA, UAT e chissà cos'altro. Sei fortunato.
Per quelli di voi che affermano di non avere alcun ambiente di test in cui testare, vi do DBCC CLONEDATABASE . Con questo comando, non hai scuse per non eseguire le query eseguite più di frequente e quelle più pesanti contro un clone del tuo database. Anche se non hai un ambiente di test, hai la tua macchina. Eseguire il backup del database clone dalla produzione, eliminare il clone, ripristinare il backup nell'istanza locale e quindi eseguire il test. Il database clone occupa pochissimo spazio su disco e non incorrerai in memoria o conflitto di I/O poiché non ci sono dati. Tu farai essere in grado di convalidare i piani di query dal clone rispetto a quelli dal database di produzione. Inoltre, se esegui il ripristino su SQL Server 2016, puoi incorporare Query Store nei test! Abilita Query Store, esegui i test nella modalità di compatibilità originale, quindi aggiorna la modalità di compatibilità ed esegui nuovamente il test. Puoi utilizzare Query Store per confrontare le query fianco a fianco! (Puoi dire che sto ballando sulla mia sedia in questo momento?)
Considerazioni
Ancora una volta, questo non dovrebbe essere qualcosa che useresti in produzione, e so che non lo faresti, ma vale la pena ripeterlo perché nel suo stato attuale, DBCC CLONEDATABASE non è completamente completo . Ciò è indicato nell'articolo della Knowledge Base sotto gli oggetti supportati; oggetti come tabelle ottimizzate per la memoria e tabelle di file non vengono copiati, il testo completo non è supportato, ecc.
Ora, il database dei cloni non è privo di inconvenienti. Se esegui inavvertitamente una ricostruzione dell'indice o un aggiornamento delle statistiche in quel database, hai appena cancellato i dati del test. Perderai le statistiche originali, che probabilmente è ciò che volevi davvero in primo luogo. Ad esempio, se controllo le statistiche per l'indice cluster su SalesOrderHeader in questo momento, ottengo questo:
USE [AdventureWorks2014_CLONE]; GO DBCC SHOW_STATISTICS (N'Sales.SalesOrderHeader',PK_SalesOrderHeader_SalesOrderID);
 Statistiche originali per SalesOrderHeader
Statistiche originali per SalesOrderHeader
Ora, se aggiorno le statistiche su quella tabella, ottengo questo:
UPDATE STATISTICS [Sales].[SalesOrderHeader] WITH FULLSCAN; GO DBCC SHOW_STATISTICS (N'Sales.SalesOrderHeader',PK_SalesOrderHeader_SalesOrderID);
 Statistiche aggiornate (vuote) per SalesOrderHeader
Statistiche aggiornate (vuote) per SalesOrderHeader
Come ulteriore sicurezza, è probabilmente una buona idea disabilitare gli aggiornamenti automatici delle statistiche:
USE [master]; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET AUTO_UPDATE_STATISTICS OFF WITH NO_WAIT;
Se ti capita di aggiornare le statistiche involontariamente, eseguendo DBCC CLONEDATABASE e passare attraverso il processo di backup e ripristino non è così difficile e lo avrai automatizzato in pochissimo tempo.
È possibile aggiungere dati al database. Questo potrebbe essere utile se vuoi sperimentare le statistiche (ad es. frequenze di campionamento diverse, statistiche filtrate) e hai spazio di archiviazione sufficiente per contenere una copia dei dati della tabella.
Senza dati nel database, ovviamente non otterrai dati di I/O e durata rappresentativi in modo affidabile. Va bene. Se hai bisogno di dati sul vero utilizzo delle risorse, allora hai bisogno di una copia del tuo database con tutti i dati al suo interno. DBCC CLONEDATABASE riguarda davvero il test delle prestazioni delle query; questo è tutto. Non sostituisce in alcun modo i tradizionali test di aggiornamento, ma è una nuova opzione per convalidare il modo in cui SQL Server ottimizza una query con versioni e modalità di compatibilità diverse. Buon test!



