[ Parte 1 | Parte 2 | Parte 3 | Parte 4]
Nella parte 3 di questa serie, ho mostrato due soluzioni alternative per evitare di ampliare un IDENTITY colonna:una che ti fa semplicemente guadagnare tempo e un'altra che abbandona IDENTITY del tutto. Il primo ti impedisce di avere a che fare con dipendenze esterne come chiavi esterne, ma il secondo non risolve questo problema. In questo post, volevo descrivere in dettaglio l'approccio che adotterei se avessi assolutamente bisogno di passare a bigint , necessario per ridurre al minimo i tempi di inattività e aveva tutto il tempo per la pianificazione.
A causa di tutti i potenziali bloccanti e della necessità di interruzioni minime, l'approccio potrebbe essere visto come un po' complesso e lo diventa solo se vengono utilizzate funzionalità esotiche aggiuntive (ad esempio, partizionamento, OLTP in memoria o replica) .
Ad un livello molto alto, l'approccio consiste nel creare un set di tabelle shadow, in cui tutti gli inserti vengono indirizzati a una nuova copia della tabella (con il tipo di dati più grande) e l'esistenza dei due set di tabelle è altrettanto trasparente possibile all'applicazione e ai suoi utenti.
A un livello più granulare, l'insieme dei passaggi sarebbe il seguente:
- Crea copie shadow delle tabelle, con i tipi di dati corretti.
- Modificare le procedure memorizzate (o il codice ad hoc) per utilizzare bigint per i parametri. (Ciò potrebbe richiedere modifiche oltre l'elenco dei parametri, come variabili locali, tabelle temporanee, ecc., ma non è il caso qui.)
- Rinomina le vecchie tabelle e crea viste con quei nomi che uniscono la vecchia e la nuova tabella.
- Quelle viste avranno invece dei trigger per indirizzare correttamente le operazioni DML alle tabelle appropriate, in modo che i dati possano ancora essere modificati durante la migrazione.
- Ciò richiede anche che SCHEMABINDING venga eliminato da tutte le viste indicizzate, che le viste esistenti abbiano unioni tra tabelle nuove e vecchie e che le procedure che si basano su SCOPE_IDENTITY() vengano modificate.
- Migra i vecchi dati alle nuove tabelle in blocchi.
- Pulizia, composto da:
- Eliminazione delle visualizzazioni temporanee (che rilascerà i trigger INSTEAD OF).
- Rinominare le nuove tabelle con i nomi originali.
- Correzione delle procedure memorizzate per ripristinare SCOPE_IDENTITY().
- Eliminando i vecchi tavoli ormai vuoti.
- Riportare SCHEMABINDING nelle viste indicizzate e ricreare gli indici cluster.
Probabilmente puoi evitare gran parte delle visualizzazioni e dei trigger se riesci a controllare tutto l'accesso ai dati tramite le procedure archiviate, ma poiché questo scenario è raro (e impossibile da considerare attendibile al 100%), mostrerò il percorso più difficile.
Schema iniziale
Nel tentativo di mantenere questo approccio il più semplice possibile, pur continuando ad affrontare molti dei blocchi che ho menzionato in precedenza nella serie, supponiamo di avere questo schema:
CREATE TABLE dbo.Employees
(
EmployeeID int IDENTITY(1,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName ON dbo.Employees(Name);
GO
CREATE VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO
CREATE TABLE dbo.EmployeeFile
(
EmployeeID int NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees(EmployeeID),
Notes nvarchar(max) NULL
);
GO Quindi una semplice tabella del personale, con una colonna IDENTITY in cluster, un indice non in cluster, una colonna calcolata basata sulla colonna IDENTITY, una vista indicizzata e una tabella HR/dirt separata che ha una chiave esterna alla tabella del personale (I non sto necessariamente incoraggiando quel design, lo sto solo usando per questo esempio). Queste sono tutte cose che rendono questo problema più complicato di quanto sarebbe se avessimo un tavolo autonomo e indipendente.
Con quello schema in atto, probabilmente abbiamo alcune stored procedure che fanno cose come CRUD. Questi sono più per motivi di documentazione che altro; Apporterò modifiche allo schema sottostante in modo tale che la modifica di queste procedure dovrebbe essere minima. Questo per simulare il fatto che la modifica dell'SQL ad hoc dalle tue applicazioni potrebbe non essere possibile e potrebbe non essere necessaria (a patto che tu non stia utilizzando un ORM in grado di rilevare tabelle e viste).
CREATE PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(),@Notes);
END
GO
CREATE PROCEDURE dbo.Employee_Update
@EmployeeID int,
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Get
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Delete
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO Ora aggiungiamo 5 righe di dati alle tabelle originali:
EXEC dbo.Employee_Add @Name = N'Employee1', @Notes = 'Employee #1 is the best'; EXEC dbo.Employee_Add @Name = N'Employee2', @Notes = 'Fewer people like Employee #2'; EXEC dbo.Employee_Add @Name = N'Employee3', @Notes = 'Jury on Employee #3 is out'; EXEC dbo.Employee_Add @Name = N'Employee4', @Notes = '#4 is moving on'; EXEC dbo.Employee_Add @Name = N'Employee5', @Notes = 'I like #5';
Fase 1:nuove tabelle
Qui creeremo una nuova coppia di tabelle, rispecchiando gli originali ad eccezione del tipo di dati delle colonne EmployeeID, il seme iniziale per la colonna IDENTITY e un suffisso temporaneo sui nomi:
CREATE TABLE dbo.Employees_New
(
EmployeeID bigint IDENTITY(2147483648,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName_New ON dbo.Employees_New(Name);
GO
CREATE TABLE dbo.EmployeeFile_New
(
EmployeeID bigint NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees_New(EmployeeID),
Notes nvarchar(max) NULL
); Fase 2:correggi i parametri della procedura
Le procedure qui (e potenzialmente il tuo codice ad hoc, a meno che non stia già utilizzando il tipo intero più grande) richiederanno una modifica molto minore in modo che in futuro possano accettare valori EmployeeID oltre i limiti superiori di un intero. Mentre potresti sostenere che se hai intenzione di alterare queste procedure, potresti semplicemente indicarle ai nuovi tavoli, sto cercando di sostenere che puoi raggiungere l'obiettivo finale con *minima* intrusione nell'esistente, permanente codice.
ALTER PROCEDURE dbo.Employee_Update
@EmployeeID bigint, -- only change
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Get
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Delete
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO Fase 3:visualizzazioni e attivatori
Sfortunatamente, questo non può *tutto* essere fatto in silenzio. Possiamo eseguire la maggior parte delle operazioni in parallelo e senza influire sull'utilizzo simultaneo, ma a causa di SCHEMABINDING, la vista indicizzata deve essere modificata e l'indice successivamente ricreato.
Questo è vero per qualsiasi altro oggetto che utilizza SCHEMABINDING e fa riferimento a una delle nostre tabelle. Consiglio di cambiarla in una vista non indicizzata all'inizio dell'operazione e di ricostruire l'indice solo una volta dopo che tutti i dati sono stati migrati, piuttosto che più volte nel processo (poiché le tabelle verranno rinominate più volte). In effetti, quello che farò è cambiare la visualizzazione per unire le nuove e vecchie versioni della tabella Impiegati per la durata del processo.
Un'altra cosa che dobbiamo fare è modificare la procedura memorizzata Employee_Add per utilizzare @@IDENTITY invece di SCOPE_IDENTITY(), temporaneamente. Questo perché il trigger INSTEAD OF che gestirà i nuovi aggiornamenti a "Employees" non avrà visibilità del valore SCOPE_IDENTITY(). Questo, ovviamente, presuppone che le tabelle non abbiano trigger after che influenzeranno @@IDENTITY. Si spera che tu possa modificare queste query all'interno di una stored procedure (dove potresti semplicemente puntare INSERT alla nuova tabella), o il codice della tua applicazione non deve fare affidamento su SCOPE_IDENTITY() in primo luogo.
Lo faremo in SERIALIZABLE in modo che nessuna transazione tenti di intrufolarsi mentre gli oggetti sono in flusso. Questo è un insieme di operazioni principalmente basate sui metadati, quindi dovrebbe essere rapido.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
GO
-- first, remove schemabinding from the view so we can change the base table
ALTER VIEW dbo.LunchGroupCount
--WITH SCHEMABINDING -- this will silently drop the index
-- and will temp. affect performance
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- rename the tables
EXEC sys.sp_rename N'dbo.Employees', N'Employees_Old', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile', N'EmployeeFile_Old', N'OBJECT';
GO
-- the view above will be broken for about a millisecond
-- until the following union view is created:
CREATE VIEW dbo.Employees
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Name, LunchGroup
FROM dbo.Employees_Old
UNION ALL
SELECT EmployeeID, Name, LunchGroup
FROM dbo.Employees_New;
GO
-- now the view will work again (but it will be slower)
CREATE VIEW dbo.EmployeeFile
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Notes
FROM dbo.EmployeeFile_Old
UNION ALL
SELECT EmployeeID, Notes
FROM dbo.EmployeeFile_New;
GO
CREATE TRIGGER dbo.Employees_InsteadOfInsert
ON dbo.Employees
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
-- just needs to insert the row(s) into the new copy of the table
INSERT dbo.Employees_New(Name) SELECT Name FROM inserted;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfUpdate
ON dbo.Employees
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- need to cover multi-row updates, and the possibility
-- that any row may have been migrated already
UPDATE o SET Name = i.Name
FROM dbo.Employees_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Name = i.Name
FROM dbo.Employees_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfDelete
ON dbo.Employees
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- a row may have been migrated already, maybe not
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.Employees_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfInsert
ON dbo.EmployeeFile
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT EmployeeID, Notes FROM inserted;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfUpdate
ON dbo.EmployeeFile
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE o SET Notes = i.Notes
FROM dbo.EmployeeFile_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Notes = i.Notes
FROM dbo.EmployeeFile_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfDelete
ON dbo.EmployeeFile
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.EmployeeFile_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
-- the insert stored procedure also has to be updated, temporarily
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(@@IDENTITY, @Notes);
-------^^^^^^^^^^------ change here
END
GO
COMMIT TRANSACTION; Passaggio 4:migra i vecchi dati nella nuova tabella
Migreremo i dati in blocchi per ridurre al minimo l'impatto sia sulla concorrenza che sul registro delle transazioni, prendendo in prestito la tecnica di base da un mio vecchio post, "Rompi grandi operazioni di eliminazione in blocchi". Eseguiremo questi batch anche in SERIALIZABLE, il che significa che dovrai prestare attenzione alle dimensioni del batch e ho omesso la gestione degli errori per brevità.
CREATE TABLE #batches(EmployeeID int);
DECLARE @BatchSize int = 1; -- for this demo only
-- your optimal batch size will hopefully be larger
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
WHILE 1 = 1
BEGIN
INSERT #batches(EmployeeID)
SELECT TOP (@BatchSize) EmployeeID
FROM dbo.Employees_Old
WHERE EmployeeID NOT IN (SELECT EmployeeID FROM dbo.Employees_New)
ORDER BY EmployeeID;
IF @@ROWCOUNT = 0
BREAK;
BEGIN TRANSACTION;
SET IDENTITY_INSERT dbo.Employees_New ON;
INSERT dbo.Employees_New(EmployeeID, Name)
SELECT o.EmployeeID, o.Name
FROM #batches AS b
INNER JOIN dbo.Employees_Old AS o
ON b.EmployeeID = o.EmployeeID;
SET IDENTITY_INSERT dbo.Employees_New OFF;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT o.EmployeeID, o.Notes
FROM #batches AS b
INNER JOIN dbo.EmployeeFile_Old AS o
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
COMMIT TRANSACTION;
TRUNCATE TABLE #batches;
-- monitor progress
SELECT total = (SELECT COUNT(*) FROM dbo.Employees),
original = (SELECT COUNT(*) FROM dbo.Employees_Old),
new = (SELECT COUNT(*) FROM dbo.Employees_New);
-- checkpoint / backup log etc.
END
DROP TABLE #batches; Risultati:
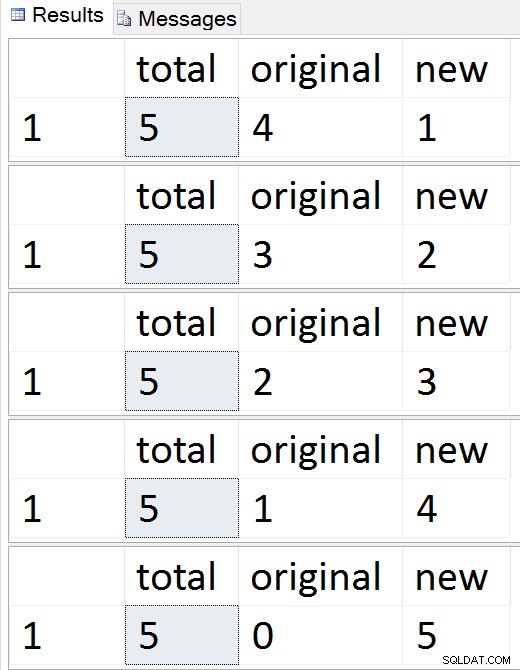 Guarda la migrazione delle righe una per una
Guarda la migrazione delle righe una per una
In qualsiasi momento durante quella sequenza, puoi testare inserimenti, aggiornamenti ed eliminazioni e dovrebbero essere gestiti in modo appropriato. Una volta completata la migrazione, puoi passare al resto del processo.
Fase 5:ripulisci
È necessaria una serie di passaggi per ripulire gli oggetti che sono stati creati temporaneamente e per ripristinare Employees / EmployeeFile come cittadini di prima classe. Molti di questi comandi sono semplicemente operazioni sui metadati:ad eccezione della creazione dell'indice cluster nella vista indicizzata, dovrebbero essere tutti istantanei.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
-- drop views and restore name of new tables
DROP VIEW dbo.EmployeeFile; --v
DROP VIEW dbo.Employees; -- this will drop the instead of triggers
EXEC sys.sp_rename N'dbo.Employees_New', N'Employees', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile_New', N'EmployeeFile', N'OBJECT';
GO
-- put schemabinding back on the view, and remove the union
ALTER VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- change the procedure back to SCOPE_IDENTITY()
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(), @Notes);
END
GO
COMMIT TRANSACTION;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- drop the old (now empty) tables
-- and create the index on the view
-- outside the transaction
DROP TABLE dbo.EmployeeFile_Old;
DROP TABLE dbo.Employees_Old;
GO
-- only portion that is absolutely not online
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO A questo punto, tutto dovrebbe tornare al normale funzionamento, anche se potresti voler considerare le attività di manutenzione tipiche a seguito di importanti modifiche allo schema, come l'aggiornamento delle statistiche, la ricostruzione degli indici o l'eliminazione dei piani dalla cache.
Conclusione
Questa è una soluzione piuttosto complessa a quello che dovrebbe essere un problema semplice. Spero che a un certo punto SQL Server renda possibile eseguire operazioni come aggiungere/rimuovere la proprietà IDENTITY, ricostruire gli indici con nuovi tipi di dati di destinazione e modificare le colonne su entrambi i lati di una relazione senza sacrificare la relazione. Nel frattempo, sarei interessato a sapere se questa soluzione ti aiuta o se hai un approccio diverso.
Un grande ringraziamento a James Lupolt (@jlupoltsql) per aver aiutato la sanità mentale a controllare il mio approccio e averlo messo alla prova definitiva su uno dei suoi tavoli reali. (È andata bene. Grazie James!)
—
[ Parte 1 | Parte 2 | Parte 3 | Parte 4]