Di recente, il mio amico Erland Sommarskog mi ha presentato una nuova sfida per le isole. Si basa su una domanda da un forum di database pubblico. La sfida in sé non è complicata da gestire quando si utilizzano tecniche ben note, che utilizzano principalmente funzioni di finestra. Tuttavia, queste tecniche richiedono un ordinamento esplicito nonostante la presenza di un indice di supporto. Ciò influisce sulla scalabilità e sui tempi di risposta delle soluzioni. Appassionato di sfide, ho deciso di trovare una soluzione per ridurre al minimo il numero di operatori di ordinamento espliciti nel piano o, meglio ancora, eliminare del tutto la necessità di tali operatori. E ho trovato una soluzione del genere.
Inizierò presentando una forma generalizzata della sfida. Mostrerò quindi due soluzioni basate su tecniche note, seguite dalla nuova soluzione. Infine, confronterò le prestazioni delle diverse soluzioni.
Ti consiglio di provare a trovare una soluzione prima di implementare la mia.
La sfida
Presenterò una forma generalizzata della sfida delle isole originali di Erland.
Utilizzare il codice seguente per creare una tabella denominata T1 e popolarla con un piccolo set di dati di esempio:
SET NOCOUNT ON;
USE tempdb;
DROP TABLE IF EXISTS dbo.T1
CREATE TABLE dbo.T1
(
grp VARCHAR(10) NOT NULL,
ord INT NOT NULL,
val VARCHAR(10) NOT NULL,
CONSTRAINT PK_T1 PRIMARY KEY(grp, ord)
);
GO
INSERT INTO dbo.T1(grp, ord, val) VALUES
('Group A', 1002, 'Y'),
('Group A', 1003, 'Y'),
('Group A', 1005, 'Y'),
('Group A', 1007, 'N'),
('Group A', 1011, 'N'),
('Group A', 1013, 'N'),
('Group A', 1017, 'Y'),
('Group A', 1019, 'Y'),
('Group A', 1023, 'N'),
('Group A', 1029, 'N'),
('Group B', 1001, 'X'),
('Group B', 1002, 'X'),
('Group B', 1003, 'Z'),
('Group B', 1005, 'Z'),
('Group B', 1008, 'Z'),
('Group B', 1013, 'Z'),
('Group B', 1021, 'Y'),
('Group B', 1034, 'Y'); La sfida è la seguente:
Presupponendo il partizionamento in base alla colonna grp e l'ordinamento in base alla colonna ord, calcola i numeri di riga sequenziali che iniziano con 1 all'interno di ogni gruppo di righe consecutivo con lo stesso valore nella colonna val. Di seguito è riportato il risultato desiderato per il dato piccolo insieme di dati campione:
grp ord val seqno -------- ----- ---- ------ Group A 1002 Y 1 Group A 1003 Y 2 Group A 1005 Y 3 Group A 1007 N 1 Group A 1011 N 2 Group A 1013 N 3 Group A 1017 Y 1 Group A 1019 Y 2 Group A 1023 N 1 Group A 1029 N 2 Group B 1001 X 1 Group B 1002 X 2 Group B 1003 Z 1 Group B 1005 Z 2 Group B 1008 Z 3 Group B 1013 Z 4 Group B 1021 Y 1 Group B 1034 Y 2
Si noti la definizione del vincolo della chiave primaria in base alla chiave composita (grp, ord), che risulta in un indice cluster basato sulla stessa chiave. Questo indice può potenzialmente supportare le funzioni della finestra partizionate da grp e ordinate per ord.
Per testare le prestazioni della tua soluzione, dovrai popolare la tabella con volumi maggiori di dati campione. Utilizzare il codice seguente per creare la funzione di supporto GetNums:
CREATE FUNCTION dbo.GetNums(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Utilizza il codice seguente per popolare T1, dopo aver modificato i parametri che rappresentano il numero di gruppi, il numero di righe per gruppo e il numero di valori distinti come desideri:
DECLARE
@numgroups AS INT = 1000,
@rowspergroup AS INT = 10000, -- test with 1000 to 10000 here
@uniquevalues AS INT = 5;
ALTER TABLE dbo.T1 DROP CONSTRAINT PK_T1;
TRUNCATE TABLE dbo.T1;
INSERT INTO dbo.T1 WITH(TABLOCK) (grp, ord, val)
SELECT
CAST(G.n AS VARCHAR(10)) AS grp,
CAST(R.n AS INT) AS ord,
CAST(ABS(CHECKSUM(NEWID())) % @uniquevalues + 1 AS VARCHAR(10)) AS val
FROM dbo.GetNums(1, @numgroups) AS G
CROSS JOIN dbo.GetNums(1, @rowspergroup) AS R;
ALTER TABLE dbo.T1 ADD CONSTRAINT PK_T1 PRIMARY KEY CLUSTERED(grp, ord);
Nei miei test delle prestazioni, ho popolato la tabella con 1.000 gruppi, tra 1.000 e 10.000 righe per gruppo (quindi da 1 M a 10 M di righe) e 5 valori distinti. Ho usato un SELECT INTO per scrivere il risultato in una tabella temporanea.
La mia macchina di prova ha quattro CPU logiche, che eseguono SQL Server 2019 Enterprise.
Presumo che tu stia utilizzando un ambiente progettato per supportare la modalità batch nell'archivio righe sia direttamente, ad esempio, utilizzando SQL Server 2019 Enterprise Edition come la mia, sia indirettamente, creando un indice columnstore fittizio sulla tabella.
Ricorda, punti extra se riesci a trovare una soluzione efficiente senza uno smistamento esplicito nel piano. Buona fortuna!
È necessario un operatore di ordinamento nell'ottimizzazione delle funzioni della finestra?
Prima di trattare le soluzioni, un po' di background sull'ottimizzazione, in modo che ciò che vedrai nei piani di query in seguito avrà più senso.
Le tecniche più comuni per risolvere i compiti delle isole come la nostra implicano l'uso di una combinazione di funzioni di finestra di aggregazione e/o classifica. SQL ServerSQL Server può elaborare tali funzioni della finestra utilizzando una serie di operatori in modalità riga precedenti (segmento, progetto sequenza, segmento, spool di finestra, aggregazione di flusso) o l'operatore di aggregazione finestra in modalità batch più recente e generalmente più efficiente.
In entrambi i casi, gli operatori che gestiscono il calcolo della funzione finestra devono acquisire i dati ordinati dagli elementi di partizionamento e ordinamento della finestra. Se non si dispone di un indice di supporto, naturalmente SQL Server dovrà introdurre un operatore di ordinamento nel piano. Ad esempio, se nella tua soluzione sono presenti più funzioni della finestra con più di una combinazione univoca di partizionamento e ordinamento, è necessario disporre di un ordinamento esplicito nel piano. Ma cosa succede se hai solo una combinazione univoca di partizionamento e ordinamento e un indice di supporto?
Il metodo della modalità riga precedente può fare affidamento su dati preordinati acquisiti da un indice senza la necessità di un operatore di ordinamento esplicito sia in modalità seriale che parallela. L'operatore in modalità batch più recente elimina gran parte delle inefficienze dell'ottimizzazione della modalità riga precedente e presenta i vantaggi intrinseci dell'elaborazione in modalità batch. Tuttavia, la sua attuale implementazione parallela richiede un operatore di ordinamento parallelo intermedio in modalità batch anche quando è presente un indice di supporto. Solo la sua implementazione seriale può fare affidamento sull'ordine dell'indice senza un operatore di ordinamento. Questo è tutto da dire quando l'ottimizzatore deve scegliere una strategia per gestire la funzione della tua finestra, supponendo che tu abbia un indice di supporto, sarà generalmente una delle seguenti quattro opzioni:
- Modalità riga, seriale, nessun ordinamento
- Modalità riga, parallela, nessun ordinamento
- Modalità batch, seriale, nessun ordinamento
- Modalità batch, parallela, ordinamento
Verrà scelto quello che risulta nel costo del piano più basso, presupponendo ovviamente che i prerequisiti per il parallelismo e la modalità batch siano soddisfatti quando si considerano quelli. Normalmente, affinché l'ottimizzatore giustifichi un piano parallelo, i vantaggi del parallelismo devono superare il lavoro aggiuntivo come la sincronizzazione dei thread. Con l'opzione 4 di cui sopra, i vantaggi del parallelismo devono superare il solito lavoro extra associato al parallelismo, oltre all'ordinamento extra.
Durante la sperimentazione di diverse soluzioni alla nostra sfida, ho avuto casi in cui l'ottimizzatore ha scelto l'opzione 2 sopra. Lo ha scelto nonostante il metodo della modalità riga comporti alcune inefficienze perché i vantaggi del parallelismo e dell'assenza di smistamento hanno comportato un piano con un costo inferiore rispetto alle alternative. In alcuni di questi casi, forzare un piano seriale con un suggerimento ha portato all'opzione 3 sopra e a prestazioni migliori.
Con questo background in mente, diamo un'occhiata alle soluzioni. Inizierò con due soluzioni che si basano su tecniche note per le attività delle isole che non possono sfuggire all'ordinamento esplicito nel piano.
Soluzione basata su tecnica nota 1
Di seguito la prima soluzione alla nostra sfida, che si basa su una tecnica nota da tempo:
WITH C AS
(
SELECT *,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY ord) -
ROW_NUMBER() OVER(PARTITION BY grp, val ORDER BY ord) AS island
FROM dbo.T1
)
SELECT grp, ord, val,
ROW_NUMBER() OVER(PARTITION BY grp, val, island ORDER BY ord) AS seqno
FROM C; La chiamerò Soluzione nota 1.
Il CTE chiamato C si basa su una query che calcola due numeri di riga. Il primo (lo chiamerò rn1) è partizionato da grp e ordinato da ord. Il secondo (lo chiamerò rn2) è partizionato da grp e val e ordinato da ord. Poiché rn1 ha spazi tra diversi gruppi dello stesso val e rn2 no, la differenza tra rn1 e rn2 (colonna chiamata isola) è un valore costante univoco per tutte le righe con gli stessi valori grp e val. Di seguito è riportato il risultato della query interna, inclusi i risultati dei calcoli dei numeri su due righe, che non vengono restituiti come colonne separate:
grp ord val rn1 rn2 island -------- ----- ---- ---- ---- ------- Group A 1002 Y 1 1 0 Group A 1003 Y 2 2 0 Group A 1005 Y 3 3 0 Group A 1007 N 4 1 3 Group A 1011 N 5 2 3 Group A 1013 N 6 3 3 Group A 1017 Y 7 4 3 Group A 1019 Y 8 5 3 Group A 1023 N 9 4 5 Group A 1029 N 10 5 5 Group B 1001 X 1 1 0 Group B 1002 X 2 2 0 Group B 1003 Z 3 1 2 Group B 1005 Z 4 2 2 Group B 1008 Z 5 3 2 Group B 1013 Z 6 4 2 Group B 1021 Y 7 1 6 Group B 1034 Y 8 2 6
Ciò che resta da fare alla query esterna è calcolare la colonna dei risultati seqno utilizzando la funzione ROW_NUMBER, partizionata per grp, val e island e ordinata per ord, generando il risultato desiderato.
Nota che puoi ottenere lo stesso valore dell'isola per valori val diversi all'interno della stessa partizione, come nell'output sopra. Questo è il motivo per cui è importante utilizzare grp, val e island come elementi di partizione della finestra e non solo grp e island.
Allo stesso modo, se hai a che fare con un'attività isole che richiede di raggruppare i dati per isola e calcolare gli aggregati di gruppo, raggrupperesti le righe per grp, val e island. Ma questo non è il caso della nostra sfida. Qui ti è stato assegnato il compito di calcolare solo i numeri di riga in modo indipendente per ogni isola.
La figura 1 ha il piano predefinito che ho ottenuto per questa soluzione sul mio computer dopo aver popolato la tabella con 10 milioni di righe.
 Figura 1:Piano parallelo per la soluzione nota 1
Figura 1:Piano parallelo per la soluzione nota 1
Il calcolo di rn1 può fare affidamento sull'ordine dell'indice. Quindi, l'ottimizzatore ha scelto la strategia no sort + modalità riga parallela per questo (i primi operatori di Segmento e Sequence Project nel piano). Poiché i calcoli di rn2 e seqno utilizzano le proprie combinazioni uniche di elementi di partizionamento e ordinamento, l'ordinamento esplicito è inevitabile per quelli indipendentemente dalla strategia utilizzata. Pertanto, l'ottimizzatore ha scelto la strategia di ordinamento + modalità batch parallela per entrambi. Questo piano prevede due operatori di ordinamento espliciti.
Nel mio test delle prestazioni, questa soluzione ha impiegato 3,68 secondi per completare 1 milione di righe e 43,1 secondi contro 10 milioni di righe.
Come detto ho testato tutte le soluzioni anche forzando un piano seriale (con un suggerimento MAXDOP 1). Il piano seriale per questa soluzione è mostrato nella Figura 1.
 Figura 2:piano seriale per la soluzione nota 1
Figura 2:piano seriale per la soluzione nota 1
Come previsto, questa volta anche il calcolo di rn1 utilizza la strategia della modalità batch senza un precedente operatore di ordinamento, ma il piano ha ancora due operatori di ordinamento per i successivi calcoli del numero di riga. Il piano seriale ha funzionato peggio di quello parallelo sulla mia macchina con tutte le dimensioni di input che ho testato, impiegando 4,54 secondi per essere completato con 1 milione di righe e 61,5 secondi con 10 milioni di righe.
Soluzione basata su tecnica nota 2
La seconda soluzione che presenterò si basa su una tecnica brillante per il rilevamento delle isole che ho imparato da Paul White alcuni anni fa. Di seguito è riportato il codice della soluzione completo basato su questa tecnica:
WITH C1 AS
(
SELECT *,
CASE
WHEN val = LAG(val) OVER(PARTITION BY grp ORDER BY ord) THEN 0
ELSE 1
END AS isstart
FROM dbo.T1
),
C2 AS
(
SELECT *,
SUM(isstart) OVER(PARTITION BY grp ORDER BY ord ROWS UNBOUNDED PRECEDING) AS island
FROM C1
)
SELECT grp, ord, val,
ROW_NUMBER() OVER(PARTITION BY grp, island ORDER BY ord) AS seqno
FROM C2; Farò riferimento a questa soluzione come Soluzione nota 2.
La query che definisce i calcoli CTE C1 utilizza un'espressione CASE e la funzione della finestra LAG (partizionata da grp e ordinata da ord) per calcolare una colonna di risultati chiamata isstart. Questa colonna ha il valore 0 quando il valore val corrente è lo stesso del precedente e 1 altrimenti. In altre parole, è 1 quando la riga è la prima in un'isola e 0 altrimenti.
Di seguito è riportato l'output della query che definisce C1:
grp ord val isstart -------- ----- ---- -------- Group A 1002 Y 1 Group A 1003 Y 0 Group A 1005 Y 0 Group A 1007 N 1 Group A 1011 N 0 Group A 1013 N 0 Group A 1017 Y 1 Group A 1019 Y 0 Group A 1023 N 1 Group A 1029 N 0 Group B 1001 X 1 Group B 1002 X 0 Group B 1003 Z 1 Group B 1005 Z 0 Group B 1008 Z 0 Group B 1013 Z 0 Group B 1021 Y 1 Group B 1034 Y 0
La magia per quanto riguarda il rilevamento dell'isola avviene nel CTE C2. La query che lo definisce calcola un identificatore di isola utilizzando la funzione della finestra SUM (anch'essa partizionata da grp e ordinata da ord) applicata alla colonna isstart. La colonna dei risultati con l'identificatore dell'isola è denominata isola. All'interno di ogni partizione, ottieni 1 per la prima isola, 2 per la seconda isola e così via. Pertanto, la combinazione delle colonne grp e island è un identificatore dell'isola, che puoi utilizzare nelle attività delle isole che implicano il raggruppamento per isola quando pertinente.
Di seguito è riportato l'output della query che definisce C2:
grp ord val isstart island -------- ----- ---- -------- ------- Group A 1002 Y 1 1 Group A 1003 Y 0 1 Group A 1005 Y 0 1 Group A 1007 N 1 2 Group A 1011 N 0 2 Group A 1013 N 0 2 Group A 1017 Y 1 3 Group A 1019 Y 0 3 Group A 1023 N 1 4 Group A 1029 N 0 4 Group B 1001 X 1 1 Group B 1002 X 0 1 Group B 1003 Z 1 2 Group B 1005 Z 0 2 Group B 1008 Z 0 2 Group B 1013 Z 0 2 Group B 1021 Y 1 3 Group B 1034 Y 0 3
Infine, la query esterna calcola la colonna del risultato desiderato seqno con una funzione ROW_NUMBER, partizionata per grp e island e ordinata per ord. Si noti che questa combinazione di partizionamento e ordinamento degli elementi è diversa da quella utilizzata dalle precedenti funzioni della finestra. Mentre il calcolo delle prime due funzioni della finestra può potenzialmente basarsi sull'ordine dell'indice, l'ultima no.
La figura 3 ha il piano predefinito che ho ottenuto per questa soluzione.
 Figura 3:Piano parallelo per la soluzione nota 2
Figura 3:Piano parallelo per la soluzione nota 2
Come puoi vedere nel piano, il calcolo delle prime due funzioni della finestra utilizza la strategia in modalità no sort + riga parallela e il calcolo dell'ultima utilizza la strategia in modalità sort + batch parallela.
I tempi di esecuzione che ho ottenuto per questa soluzione variavano da 2,57 secondi contro 1 milione di righe a 46,2 secondi contro 10 milioni di righe.
Quando ho forzato l'elaborazione seriale, ho ottenuto il piano mostrato nella Figura 4.
 Figura 4:piano seriale per la soluzione nota 2
Figura 4:piano seriale per la soluzione nota 2
Come previsto, questa volta tutti i calcoli delle funzioni della finestra si basano sulla strategia della modalità batch. I primi due senza ordinamento precedente e l'ultimo con. Sia il piano parallelo che quello seriale prevedevano un operatore di ordinamento esplicito. Il piano seriale ha funzionato meglio del piano parallelo sulla mia macchina con le dimensioni di input che ho testato. I tempi di esecuzione che ho ottenuto per il piano seriale forzato variavano da 1,75 secondi contro 1 milione di righe a 21,7 secondi contro 10 milioni di righe.
Soluzione basata su una nuova tecnica
Quando Erland ha introdotto questa sfida in un forum privato, le persone erano scettiche sulla possibilità di risolverla con una query che era stata ottimizzata con un piano senza ordinamento esplicito. Questo è tutto ciò che avevo bisogno di sentire per motivarmi. Quindi, ecco cosa mi è venuto in mente:
WITH C1 AS
(
SELECT *,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY ord) AS rn,
LAG(val) OVER(PARTITION BY grp ORDER BY ord) AS prev
FROM dbo.T1
),
C2 AS
(
SELECT *,
MAX(CASE WHEN val = prev THEN NULL ELSE rn END)
OVER(PARTITION BY grp ORDER BY ord ROWS UNBOUNDED PRECEDING) AS firstrn
FROM C1
)
SELECT grp, ord, val, rn - firstrn + 1 AS seqno
FROM C2; La soluzione utilizza tre funzioni della finestra:LAG, ROW_NUMBER e MAX. La cosa importante qui è che tutti e tre sono basati sul partizionamento grp e sull'ordinamento degli ordini, che è allineato con l'ordine delle chiavi dell'indice di supporto.
La query che definisce il CTE C1 utilizza la funzione ROW_NUMBER per calcolare i numeri di riga (colonna rn) e la funzione LAG per restituire il valore val precedente (colonna precedente).
Ecco l'output della query che definisce C1:
grp ord val rn prev -------- ----- ---- --- ----- Group A 1002 Y 1 NULL Group A 1003 Y 2 Y Group A 1005 Y 3 Y Group A 1007 N 4 Y Group A 1011 N 5 N Group A 1013 N 6 N Group A 1017 Y 7 N Group A 1019 Y 8 Y Group A 1023 N 9 Y Group A 1029 N 10 N Group B 1001 X 1 NULL Group B 1002 X 2 X Group B 1003 Z 3 X Group B 1005 Z 4 Z Group B 1008 Z 5 Z Group B 1013 Z 6 Z Group B 1021 Y 7 Z Group B 1034 Y 8 Y
Nota quando val e prev sono gli stessi, non è la prima riga dell'isola, altrimenti lo è.
Sulla base di questa logica, la query che definisce il CTE C2 utilizza un'espressione CASE che restituisce rn quando la riga è la prima in un'isola e NULL in caso contrario. Il codice applica quindi la funzione della finestra MAX al risultato dell'espressione CASE, restituendo il primo rn dell'isola (prima colonna).
Ecco l'output della query che definisce C2, incluso l'output dell'espressione CASE:
grp ord val rn prev CASE firstrn -------- ----- ---- --- ----- ----- -------- Group A 1002 Y 1 NULL 1 1 Group A 1003 Y 2 Y NULL 1 Group A 1005 Y 3 Y NULL 1 Group A 1007 N 4 Y 4 4 Group A 1011 N 5 N NULL 4 Group A 1013 N 6 N NULL 4 Group A 1017 Y 7 N 7 7 Group A 1019 Y 8 Y NULL 7 Group A 1023 N 9 Y 9 9 Group A 1029 N 10 N NULL 9 Group B 1001 X 1 NULL 1 1 Group B 1002 X 2 X NULL 1 Group B 1003 Z 3 X 3 3 Group B 1005 Z 4 Z NULL 3 Group B 1008 Z 5 Z NULL 3 Group B 1013 Z 6 Z NULL 3 Group B 1021 Y 7 Z 7 7 Group B 1034 Y 8 Y NULL 7
Ciò che resta per la query esterna è calcolare la colonna del risultato desiderato seqno come rn meno firstrn più 1.
La figura 5 ha il piano parallelo predefinito che ho ottenuto per questa soluzione durante il test utilizzando un'istruzione SELECT INTO, scrivendo il risultato in una tabella temporanea.
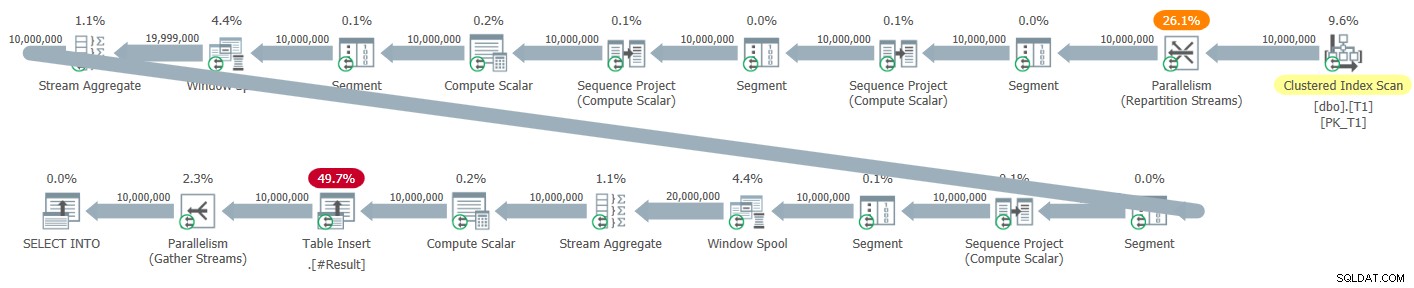 Figura 5:Piano parallelo per una nuova soluzione
Figura 5:Piano parallelo per una nuova soluzione
Non sono presenti operatori di ordinamento espliciti in questo piano. Tuttavia, tutte e tre le funzioni della finestra vengono calcolate utilizzando la strategia no sort + modalità riga parallela, quindi ci mancano i vantaggi dell'elaborazione batch. I tempi di esecuzione che ho ottenuto per questa soluzione con il piano parallelo variavano da 2,47 secondi contro 1 milione di righe e 41,4 contro 10 milioni di righe.
Qui, c'è un'alta probabilità che un piano seriale con elaborazione batch funzioni significativamente meglio, specialmente quando la macchina non ha molte CPU. Ricordiamo che sto testando le mie soluzioni su una macchina con 4 CPU logiche. La figura 6 mostra il piano che ho ottenuto per questa soluzione quando si forza l'elaborazione seriale.
 Figura 6:piano seriale per una nuova soluzione
Figura 6:piano seriale per una nuova soluzione
Tutte e tre le funzioni della finestra utilizzano la strategia no sort + modalità batch seriale. E i risultati sono piuttosto impressionanti. I tempi di esecuzione di questa soluzione variavano da 0,5 secondi contro 1 milione di righe e 5,49 secondi contro 10 milioni di righe. Un altro aspetto curioso di questa soluzione è che quando viene testata come una normale istruzione SELECT (con risultati eliminati) anziché un'istruzione SELECT INTO, SQL Server ha scelto il piano seriale per impostazione predefinita. Con le altre due soluzioni, ho ottenuto un piano parallelo di default sia con SELECT che con SELECT INTO.
Consulta la sezione successiva per i risultati completi del test delle prestazioni.
Confronto delle prestazioni
Ecco il codice che ho usato per testare le tre soluzioni, ovviamente decommentando il suggerimento MAXDOP 1 per testare i piani seriali:
-- Test Known Solution 1
DROP TABLE IF EXISTS #Result;
WITH C AS
(
SELECT *,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY ord) -
ROW_NUMBER() OVER(PARTITION BY grp, val ORDER BY ord) AS island
FROM dbo.T1
)
SELECT grp, ord, val,
ROW_NUMBER() OVER(PARTITION BY grp, val, island ORDER BY ord) AS seqno
INTO #Result
FROM C
/* OPTION(MAXDOP 1) */; -- uncomment for serial test
GO
-- Test Known Solution 2
DROP TABLE IF EXISTS #Result;
WITH C1 AS
(
SELECT *,
CASE
WHEN val = LAG(val) OVER(PARTITION BY grp ORDER BY ord) THEN 0
ELSE 1
END AS isstart
FROM dbo.T1
),
C2 AS
(
SELECT *,
SUM(isstart) OVER(PARTITION BY grp ORDER BY ord ROWS UNBOUNDED PRECEDING) AS island
FROM C1
)
SELECT grp, ord, val,
ROW_NUMBER() OVER(PARTITION BY grp, island ORDER BY ord) AS seqno
INTO #Result
FROM C2
/* OPTION(MAXDOP 1) */;
GO
-- Test New Solution
DROP TABLE IF EXISTS #Result;
WITH C1 AS
(
SELECT *,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY ord) AS rn,
LAG(val) OVER(PARTITION BY grp ORDER BY ord) AS prev
FROM dbo.T1
),
C2 AS
(
SELECT *,
MAX(CASE WHEN val = prev THEN NULL ELSE rn END)
OVER(PARTITION BY grp ORDER BY ord ROWS UNBOUNDED PRECEDING) AS firstrn
FROM C1
)
SELECT grp, ord, val, rn - firstrn + 1 AS seqno
INTO #Result
FROM C2
/* OPTION(MAXDOP 1) */; La Figura 7 mostra i tempi di esecuzione dei piani paralleli e seriali per tutte le soluzioni rispetto a dimensioni di input diverse.
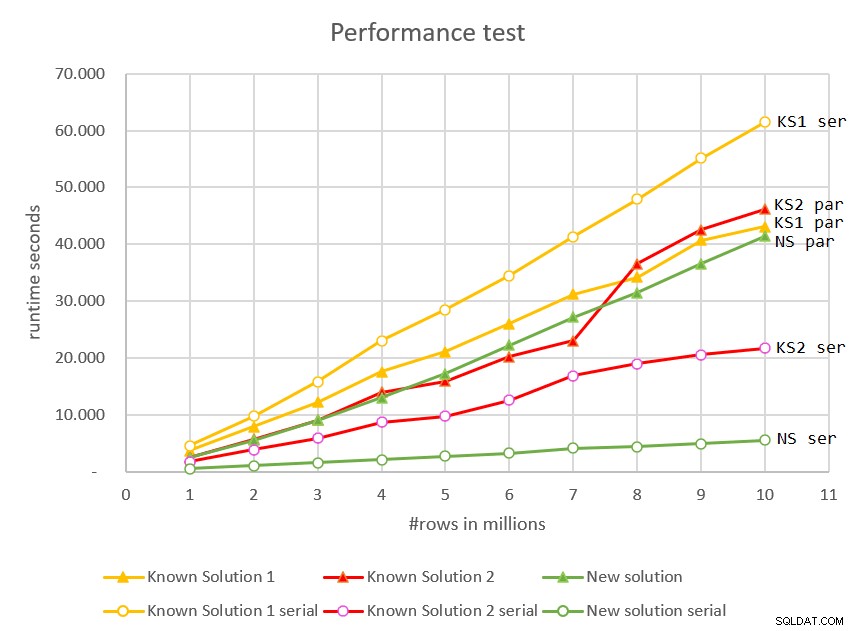 Figura 7:confronto delle prestazioni
Figura 7:confronto delle prestazioni
La nuova soluzione, che utilizza la modalità seriale, è la chiara vincitrice. Ha grandi prestazioni, ridimensionamento lineare e tempo di risposta immediato.
Conclusione
I compiti delle isole sono abbastanza comuni nella vita reale. Molti di loro coinvolgono sia l'identificazione delle isole che il raggruppamento dei dati per isola. La sfida delle isole di Erland, che era al centro di questo articolo, è un po' più singolare perché non prevede il raggruppamento ma invece la sequenza delle righe di ciascuna isola con i numeri di riga.
Ho presentato due soluzioni basate su tecniche note per identificare le isole. Il problema con entrambi è che si traducono in piani che coinvolgono l'ordinamento esplicito, che influisce negativamente sulle prestazioni, sulla scalabilità e sui tempi di risposta delle soluzioni. Ho anche presentato una nuova tecnica che ha portato a un piano senza alcun ordinamento. Il piano seriale per questa soluzione, che utilizza una strategia no sort + modalità batch seriale, offre prestazioni eccellenti, ridimensionamento lineare e tempi di risposta immediati. È un peccato, almeno per ora, non possiamo avere una strategia no sort + modalità batch parallela per la gestione delle funzioni della finestra.