Questo articolo è la quarta puntata di una serie su bug, insidie e best practice di T-SQL. In precedenza mi occupavo di determinismo, subquery e join. Il focus dell'articolo di questo mese sono bug, insidie e best practice relative alle funzioni della finestra. Grazie Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man e Paul White per aver offerto le tue idee!
Nei miei esempi userò un database di esempio chiamato TSQLV5. Puoi trovare lo script che crea e popola questo database qui e il suo diagramma ER qui.
Esistono due insidie comuni che coinvolgono le funzioni della finestra, entrambe il risultato di impostazioni predefinite implicite controintuitive imposte dallo standard SQL. Una trappola ha a che fare con i calcoli dei totali parziali in cui si ottiene una cornice della finestra con l'opzione RANGE implicita. Un'altra trappola è in qualche modo correlata, ma ha conseguenze più gravi, coinvolgendo una definizione di frame implicita per le funzioni FIRST_VALUE e LAST_VALUE.
Finestra con opzione RANGE implicita
La nostra prima trappola riguarda il calcolo dei totali parziali utilizzando una funzione di aggregazione della finestra, in cui si specifica esplicitamente la clausola dell'ordine della finestra, ma non si specifica esplicitamente l'unità del frame della finestra (ROWS o RANGE) e la relativa estensione del frame della finestra, ad es. ROWS PRECEDENTE SENZA LIMITI. Il default implicito è controintuitivo e le sue conseguenze potrebbero essere sorprendenti e dolorose.
Per dimostrare questa trappola, userò una tabella chiamata Transazioni che contiene due milioni di transazioni di conto bancario con crediti (valori positivi) e debiti (valori negativi). Eseguire il codice seguente per creare la tabella Transazioni e popolarla con dati di esempio:
SET NOCOUNT ON;
USE TSQLV5; -- https://tsql.solidq.com/SampleDatabases/TSQLV5.zip
DROP TABLE IF EXISTS dbo.Transactions;
CREATE TABLE dbo.Transactions
(
actid INT NOT NULL,
tranid INT NOT NULL,
val MONEY NOT NULL,
CONSTRAINT PK_Transactions PRIMARY KEY(actid, tranid) -- creates POC index
);
DECLARE
@num_partitions AS INT = 100,
@rows_per_partition AS INT = 20000;
INSERT INTO dbo.Transactions WITH (TABLOCK) (actid, tranid, val)
SELECT NP.n, RPP.n,
(ABS(CHECKSUM(NEWID())%2)*2-1) * (1 + ABS(CHECKSUM(NEWID())%5))
FROM dbo.GetNums(1, @num_partitions) AS NP
CROSS JOIN dbo.GetNums(1, @rows_per_partition) AS RPP; La nostra trappola ha sia un lato logico con un potenziale bug logico, sia un lato prestazionale con una penalizzazione delle prestazioni. La penalizzazione delle prestazioni è rilevante solo quando la funzione finestra è ottimizzata con operatori di elaborazione in modalità riga. SQL Server 2016 introduce l'operatore Window Aggregate in modalità batch, che rimuove la parte di penalizzazione delle prestazioni della trappola, ma prima di SQL Server 2019 questo operatore viene utilizzato solo se è presente un indice columnstore nei dati. SQL Server 2019 introduce la modalità batch nel supporto di rowstore, in modo da poter ottenere l'elaborazione in modalità batch anche se non sono presenti indici columnstore sui dati. Per dimostrare la riduzione delle prestazioni con l'elaborazione in modalità riga, se si eseguono gli esempi di codice in questo articolo in SQL Server 2019 o versioni successive o nel database SQL di Azure, usare il codice seguente per impostare il livello di compatibilità del database su 140 in modo da non abilitare ancora la modalità batch nell'archivio riga:
ALTER DATABASE TSQLV5 SET COMPATIBILITY_LEVEL = 140;
Utilizzare il codice seguente per attivare le statistiche relative all'ora e all'I/O nella sessione:
SET STATISTICS TIME, IO ON;
Per evitare di attendere la stampa di due milioni di righe in SSMS, suggerisco di eseguire gli esempi di codice in questa sezione con l'opzione Elimina risultati dopo l'esecuzione attivata (vai su Opzioni query, Risultati, Griglia e seleziona Elimina risultati dopo l'esecuzione).
Prima di arrivare alla trappola, considera la seguente query (chiamala Query 1) che calcola il saldo del conto bancario dopo ogni transazione applicando un totale parziale utilizzando una funzione di aggregazione della finestra con una specifica esplicita del frame:
SELECT actid, tranid, val,
SUM(val) OVER( PARTITION BY actid
ORDER BY tranid
ROWS UNBOUNDED PRECEDING ) AS balance
FROM dbo.Transactions; Il piano per questa query, utilizzando l'elaborazione in modalità riga, è mostrato nella Figura 1.
 Figura 1:piano per la query 1, elaborazione in modalità riga
Figura 1:piano per la query 1, elaborazione in modalità riga
Il piano estrae i dati preordinati dall'indice cluster della tabella. Quindi utilizza gli operatori Segmento e Sequence Project per calcolare i numeri di riga per capire quali righe appartengono al frame della riga corrente. Quindi utilizza gli operatori Segment, Window Spool e Stream Aggregate per calcolare la funzione di aggregazione della finestra. L'operatore Window Spool viene utilizzato per eseguire lo spooling delle righe di frame che devono quindi essere aggregate. Senza alcuna ottimizzazione speciale, il piano avrebbe dovuto scrivere per riga tutte le righe del frame applicabili nello spool e quindi aggregarle. Ciò avrebbe comportato una complessità quadratica o N. La buona notizia è che quando il frame inizia con UNBOUNDED PRECEDING, SQL Server identifica il caso come fast track caso, in cui prende semplicemente il totale parziale della riga precedente e aggiunge il valore della riga corrente per calcolare il totale parziale della riga corrente, con conseguente ridimensionamento lineare. In questa modalità fast track, il piano scrive solo due righe nello spool per riga di input, una con l'aggregato e l'altra con i dettagli.
Il Window Spool può essere implementato fisicamente in due modi. O come uno spool veloce in memoria progettato appositamente per le funzioni della finestra o come uno spool su disco lento, che è essenzialmente una tabella temporanea in tempdb. Se il numero di righe che devono essere scritte nello spool per riga sottostante potrebbe superare 10.000 oppure, se SQL Server non è in grado di prevedere il numero, utilizzerà lo spool su disco più lento. Nel nostro piano di query, abbiamo esattamente due righe scritte nello spool per riga sottostante, quindi SQL Server utilizza lo spool in memoria. Sfortunatamente, non c'è modo di dire dal piano che tipo di bobina stai ricevendo. Ci sono due modi per capirlo. Uno consiste nell'usare un evento esteso chiamato window_spool_ondisk_warning. Un'altra opzione è abilitare STATISTICS IO e controllare il numero di letture logiche riportate per una tabella denominata Worktable. Un numero maggiore di zero significa che hai lo spool su disco. Zero significa che hai la bobina in memoria. Ecco le statistiche di I/O per la nostra query:
Letture logiche della tabella "Worktable":0. Letture logiche della tabella "Transazioni":6208.Come puoi vedere, abbiamo usato la bobina in memoria. Questo è generalmente il caso quando si utilizza l'unità telaio della finestra ROWS con UNBOUNDED PRECEDING come primo delimitatore.
Ecco le statistiche temporali per la nostra query:
Tempo CPU:4297 ms, tempo trascorso:4441 ms.Ci sono voluti circa 4,5 secondi per completare questa query sulla mia macchina con risultati scartati.
Ora per la cattura. Se utilizzi l'opzione RANGE invece di ROWS, con gli stessi delimitatori, potrebbe esserci una sottile differenza di significato, ma una grande differenza di prestazioni in modalità riga. La differenza di significato è rilevante solo se non si dispone di un ordinamento totale, cioè se si ordina in base a qualcosa che non è unico. L'opzione ROWS UNBOUNDED PRECEDING si interrompe con la riga corrente, quindi in caso di parità il calcolo non è deterministico. Al contrario, l'opzione RANGE UNBOUNDED PRECEDING guarda avanti rispetto alla riga corrente e include i pareggi se presenti. Utilizza una logica simile all'opzione TOP WITH TIES. Quando hai un ordinamento totale, cioè stai ordinando in base a qualcosa di unico, non ci sono legami da includere, e quindi ROWS e RANGE diventano logicamente equivalenti in questo caso. Il problema è che quando si utilizza RANGE, SQL Server utilizza sempre lo spool su disco nell'elaborazione in modalità riga poiché durante l'elaborazione di una determinata riga non è possibile prevedere quante altre righe verranno incluse. Ciò può comportare una grave penalizzazione delle prestazioni.
Considera la seguente query (chiamala Query 2), che è la stessa della Query 1, utilizzando solo l'opzione RANGE invece di ROWS:
SELECT actid, tranid, val,
SUM(val) OVER( PARTITION BY actid
ORDER BY tranid
RANGE UNBOUNDED PRECEDING ) AS balance
FROM dbo.Transactions; Il piano per questa query è mostrato nella Figura 2.
 Figura 2:piano per la query 2, elaborazione in modalità riga
Figura 2:piano per la query 2, elaborazione in modalità riga
La query 2 è logicamente equivalente alla query 1 perché abbiamo un ordine totale; tuttavia, poiché utilizza RANGE, viene ottimizzato con lo spool su disco. Osserva che nel piano per la query 2 lo spool della finestra ha lo stesso aspetto del piano per la query 1 e i costi stimati sono gli stessi.
Di seguito sono riportate le statistiche relative al tempo e agli I/O per l'esecuzione della Query 2:
Tempo CPU:19515 ms, tempo trascorso:20201 ms.Letture logiche tabella 'Worktable':12044701. Letture logiche tabella 'Transazioni':6208.
Notare il gran numero di letture logiche rispetto a Worktable, a indicare che hai ottenuto lo spool su disco. Il tempo di esecuzione è più di quattro volte più lungo rispetto alla query 1.
Se stai pensando che, in tal caso, eviterai semplicemente di utilizzare l'opzione RANGE, a meno che tu non abbia davvero bisogno di includere le cravatte, è una buona idea. Il problema è che se si utilizza una funzione finestra che supporta un frame (aggregati, FIRST_VALUE, LAST_VALUE) con una clausola esplicita di ordine della finestra, ma senza alcuna menzione dell'unità frame della finestra e della sua estensione associata, si ottiene RANGE UNBOUNDED PRECEDING per impostazione predefinita . Questa impostazione predefinita è dettata dallo standard SQL e lo standard l'ha scelta perché generalmente preferisce opzioni più deterministiche come impostazioni predefinite. La seguente query (chiamatela Query 3) è un esempio che cade in questa trappola:
SELECT actid, tranid, val,
SUM(val) OVER( PARTITION BY actid
ORDER BY tranid ) AS balance
FROM dbo.Transactions; Spesso le persone scrivono in questo modo supponendo che stiano ottenendo ROWS UNBOUNDED PRECEDING per impostazione predefinita, senza rendersi conto che in realtà stanno ottenendo RANGE UNBOUNDED PRECEDING. Il fatto è che poiché la funzione utilizza l'ordine totale, ottieni lo stesso risultato come con ROWS, quindi non puoi dire che c'è un problema dal risultato. Ma i dati sulle prestazioni che otterrai sono quelli della Query 2. Vedo che le persone cadono continuamente in questa trappola.
La procedura migliore per evitare questo problema è nei casi in cui si utilizza una funzione finestra con una cornice, sii esplicito sull'unità cornice della finestra e sulla sua estensione e generalmente si preferisce ROWS. Riserva l'uso di RANGE solo ai casi in cui l'ordine non è univoco e devi includere le cravatte.
Considera la seguente query che illustra un caso in cui esiste una differenza concettuale tra ROWS e RANGE:
SELECT orderdate, orderid, val,
SUM(val) OVER( ORDER BY orderdate ROWS UNBOUNDED PRECEDING ) AS sumrows,
SUM(val) OVER( ORDER BY orderdate RANGE UNBOUNDED PRECEDING ) AS sumrange
FROM Sales.OrderValues
ORDER BY orderdate; Questa query genera il seguente output:
orderdate orderid val sumrows sumrange ---------- -------- -------- -------- --------- 2017-07-04 10248 440.00 440.00 440.00 2017-07-05 10249 1863.40 2303.40 2303.40 2017-07-08 10250 1552.60 3856.00 4510.06 2017-07-08 10251 654.06 4510.06 4510.06 2017-07-09 10252 3597.90 8107.96 8107.96 ...
Osservare la differenza nei risultati per le righe in cui la stessa data dell'ordine appare più di una volta, come nel caso dell'8 luglio 2017. Si noti come l'opzione ROWS non includa i pareggi e quindi non sia deterministica, e come lo fa l'opzione RANGE include legami, e quindi è sempre deterministico.
È discutibile però se in pratica hai casi in cui ordini per qualcosa che non è unico e hai davvero bisogno dell'inclusione di legami per rendere deterministico il calcolo. Ciò che è probabilmente molto più comune nella pratica è fare una di queste due cose. Uno è rompere i legami aggiungendo qualcosa all'ordine della finestra per renderlo unico e in questo modo ottenere un calcolo deterministico, in questo modo:
SELECT orderdate, orderid, val,
SUM(val) OVER( ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING ) AS runningsum
FROM Sales.OrderValues
ORDER BY orderdate; Questa query genera il seguente output:
orderdate orderid val runningsum ---------- -------- --------- ----------- 2017-07-04 10248 440.00 440.00 2017-07-05 10249 1863.40 2303.40 2017-07-08 10250 1552.60 3856.00 2017-07-08 10251 654.06 4510.06 2017-07-09 10252 3597.90 8107.96 ...
Un'altra opzione è applicare il raggruppamento preliminare, nel nostro caso, per data dell'ordine, in questo modo:
SELECT orderdate, SUM(val) AS daytotal,
SUM(SUM(val)) OVER( ORDER BY orderdate ROWS UNBOUNDED PRECEDING ) AS runningsum
FROM Sales.OrderValues
GROUP BY orderdate
ORDER BY orderdate; Questa query genera il seguente output in cui ogni data dell'ordine viene visualizzata una sola volta:
orderdate daytotal runningsum ---------- --------- ----------- 2017-07-04 440.00 440.00 2017-07-05 1863.40 2303.40 2017-07-08 2206.66 4510.06 2017-07-09 3597.90 8107.96 ...
In ogni caso, assicurati di ricordare le best practice qui!
La buona notizia è che se si esegue SQL Server 2016 o versioni successive e nei dati è presente un indice columnstore (anche se si tratta di un falso indice columnstore filtrato) o se si esegue SQL Server 2019 o versioni successive oppure nel database SQL di Azure, indipendentemente dalla presenza di indici columnstore, tutte e tre le query sopra menzionate vengono ottimizzate con l'operatore Window Aggregate in modalità batch. Con questo operatore, molte delle inefficienze di elaborazione in modalità riga vengono eliminate. Questo operatore non utilizza affatto uno spool, quindi non ci sono problemi di spool in memoria e su disco. Utilizza un'elaborazione più sofisticata in cui può applicare più passaggi paralleli sulla finestra di righe in memoria sia per ROWS che per RANGE.
Per dimostrare l'utilizzo dell'ottimizzazione in modalità batch, assicurati che il livello di compatibilità del database sia impostato su 150 o superiore:
ALTER DATABASE TSQLV5 SET COMPATIBILITY_LEVEL = 150;
Esegui di nuovo la query 1:
SELECT actid, tranid, val,
SUM(val) OVER( PARTITION BY actid
ORDER BY tranid
ROWS UNBOUNDED PRECEDING ) AS balance
FROM dbo.Transactions; Il piano per questa query è mostrato nella Figura 3.
 Figura 3:piano per la query 1, elaborazione in modalità batch
Figura 3:piano per la query 1, elaborazione in modalità batch
Ecco le statistiche sul rendimento che ho ottenuto per questa query:
Tempo CPU:937 ms, tempo trascorso:983 ms.Letture logiche della tabella 'Transazioni':6208.
Il tempo di esecuzione è sceso a 1 secondo!
Esegui nuovamente la query 2 con l'opzione RANGE esplicita:
SELECT actid, tranid, val,
SUM(val) OVER( PARTITION BY actid
ORDER BY tranid
RANGE UNBOUNDED PRECEDING ) AS balance
FROM dbo.Transactions; Il piano per questa query è mostrato nella Figura 4.
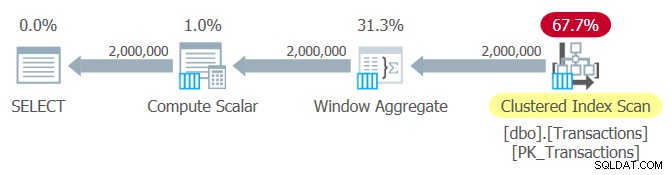 Figura 2:piano per la query 2, elaborazione in modalità batch
Figura 2:piano per la query 2, elaborazione in modalità batch
Ecco le statistiche sul rendimento che ho ottenuto per questa query:
Tempo CPU:969 ms, tempo trascorso:1048 ms.Letture logiche della tabella 'Transazioni':6208.
Le prestazioni sono le stesse della Query 1.
Esegui nuovamente la query 3, con l'opzione RANGE implicita:
SELECT actid, tranid, val,
SUM(val) OVER( PARTITION BY actid
ORDER BY tranid ) AS balance
FROM dbo.Transactions; Il piano e i numeri delle prestazioni sono ovviamente gli stessi della Query 2.
Al termine, esegui il codice seguente per disattivare le statistiche sul rendimento:
SET STATISTICS TIME, IO OFF;
Inoltre, non dimenticare di disattivare l'opzione Elimina risultati dopo l'esecuzione in SSMS.
Frame implicito con FIRST_VALUE e LAST_VALUE
Le funzioni FIRST_VALUE e LAST_VALUE sono funzioni della finestra di offset che restituiscono un'espressione rispettivamente dalla prima o dall'ultima riga nella cornice della finestra. La parte difficile di loro è che spesso quando le persone li usano per la prima volta, non si rendono conto che supportano un frame, piuttosto pensano che si applichino all'intera partizione.
Considera il seguente tentativo di restituire le informazioni sull'ordine, oltre ai valori del primo e dell'ultimo ordine del cliente:
SELECT custid, orderdate, orderid, val,
FIRST_VALUE(val) OVER( PARTITION BY custid
ORDER BY orderdate, orderid ) AS firstval,
LAST_VALUE(val) OVER( PARTITION BY custid
ORDER BY orderdate, orderid ) AS lastval
FROM Sales.OrderValues
ORDER BY custid, orderdate, orderid; Se ritieni erroneamente che queste funzioni operino sull'intera partizione della finestra, come crede molte persone che usano queste funzioni per la prima volta, ti aspetti naturalmente che FIRST_VALUE restituisca il valore dell'ordine del primo ordine del cliente e LAST_VALUE restituisca il valore dell'ultimo ordine del cliente. In pratica, però, queste funzioni supportano un frame. Come promemoria, con le funzioni che supportano un frame, quando si specifica la clausola dell'ordine della finestra ma non l'unità del frame della finestra e la sua estensione associata, si ottiene RANGE UNBOUNDED PRECEDING per impostazione predefinita. Con la funzione FIRST_VALUE, otterrai il risultato atteso, ma se la tua query viene ottimizzata con gli operatori in modalità riga, pagherai la penalità dell'utilizzo dello spool su disco. Con la funzione LAST_VALUE è anche peggio. Non solo pagherai la penalità dello spool su disco, ma invece di ottenere il valore dall'ultima riga nella partizione, otterrai il valore dalla riga corrente!
Ecco l'output della query precedente:
custid orderdate orderid val firstval lastval ------- ---------- -------- ---------- ---------- ---------- 1 2018-08-25 10643 814.50 814.50 814.50 1 2018-10-03 10692 878.00 814.50 878.00 1 2018-10-13 10702 330.00 814.50 330.00 1 2019-01-15 10835 845.80 814.50 845.80 1 2019-03-16 10952 471.20 814.50 471.20 1 2019-04-09 11011 933.50 814.50 933.50 2 2017-09-18 10308 88.80 88.80 88.80 2 2018-08-08 10625 479.75 88.80 479.75 2 2018-11-28 10759 320.00 88.80 320.00 2 2019-03-04 10926 514.40 88.80 514.40 3 2017-11-27 10365 403.20 403.20 403.20 3 2018-04-15 10507 749.06 403.20 749.06 3 2018-05-13 10535 1940.85 403.20 1940.85 3 2018-06-19 10573 2082.00 403.20 2082.00 3 2018-09-22 10677 813.37 403.20 813.37 3 2018-09-25 10682 375.50 403.20 375.50 3 2019-01-28 10856 660.00 403.20 660.00 ...
Spesso, quando le persone vedono tale output per la prima volta, pensano che SQL Server abbia un bug. Ma ovviamente non è così; è semplicemente l'impostazione predefinita dello standard SQL. C'è un bug nella query. Rendendosi conto che è coinvolto un frame, vuoi essere esplicito sulla specifica del frame e utilizzare il frame minimo che cattura la riga che stai cercando. Inoltre, assicurati di utilizzare l'unità ROWS. Quindi, per ottenere la prima riga nella partizione, utilizzare la funzione FIRST_VALUE con il frame ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW. Per ottenere l'ultima riga nella partizione, utilizzare la funzione LAST_VALUE con il frame ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING.
Ecco la nostra query rivista con il bug corretto:
SELECT custid, orderdate, orderid, val,
FIRST_VALUE(val) OVER( PARTITION BY custid
ORDER BY orderdate, orderid
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW ) AS firstval,
LAST_VALUE(val) OVER( PARTITION BY custid
ORDER BY orderdate, orderid
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING ) AS lastval
FROM Sales.OrderValues
ORDER BY custid, orderdate, orderid; Questa volta ottieni il risultato corretto:
custid orderdate orderid val firstval lastval ------- ---------- -------- ---------- ---------- ---------- 1 2018-08-25 10643 814.50 814.50 933.50 1 2018-10-03 10692 878.00 814.50 933.50 1 2018-10-13 10702 330.00 814.50 933.50 1 2019-01-15 10835 845.80 814.50 933.50 1 2019-03-16 10952 471.20 814.50 933.50 1 2019-04-09 11011 933.50 814.50 933.50 2 2017-09-18 10308 88.80 88.80 514.40 2 2018-08-08 10625 479.75 88.80 514.40 2 2018-11-28 10759 320.00 88.80 514.40 2 2019-03-04 10926 514.40 88.80 514.40 3 2017-11-27 10365 403.20 403.20 660.00 3 2018-04-15 10507 749.06 403.20 660.00 3 2018-05-13 10535 1940.85 403.20 660.00 3 2018-06-19 10573 2082.00 403.20 660.00 3 2018-09-22 10677 813.37 403.20 660.00 3 2018-09-25 10682 375.50 403.20 660.00 3 2019-01-28 10856 660.00 403.20 660.00 ...
Viene da chiedersi quale sia stata la motivazione per cui lo standard ha persino supportato un telaio con queste funzioni. Se ci pensi, li utilizzerai principalmente per ottenere qualcosa dalla prima o dall'ultima riga nella partizione. Se hai bisogno del valore da, diciamo, due righe prima di quella corrente, invece di usare FIRST_VALUE con un frame che inizia con 2 PRECEDING, non è molto più semplice usare LAG con un offset esplicito di 2, in questo modo:
SELECT custid, orderdate, orderid, val,
LAG(val, 2) OVER( PARTITION BY custid
ORDER BY orderdate, orderid ) AS prevtwoval
FROM Sales.OrderValues
ORDER BY custid, orderdate, orderid; Questa query genera il seguente output:
custid orderdate orderid val prevtwoval ------- ---------- -------- ---------- ----------- 1 2018-08-25 10643 814.50 NULL 1 2018-10-03 10692 878.00 NULL 1 2018-10-13 10702 330.00 814.50 1 2019-01-15 10835 845.80 878.00 1 2019-03-16 10952 471.20 330.00 1 2019-04-09 11011 933.50 845.80 2 2017-09-18 10308 88.80 NULL 2 2018-08-08 10625 479.75 NULL 2 2018-11-28 10759 320.00 88.80 2 2019-03-04 10926 514.40 479.75 3 2017-11-27 10365 403.20 NULL 3 2018-04-15 10507 749.06 NULL 3 2018-05-13 10535 1940.85 403.20 3 2018-06-19 10573 2082.00 749.06 3 2018-09-22 10677 813.37 1940.85 3 2018-09-25 10682 375.50 2082.00 3 2019-01-28 10856 660.00 813.37 ...
Apparentemente, c'è una differenza semantica tra l'uso sopra della funzione LAG e FIRST_VALUE con un frame che inizia con 2 PRECEDING. Con il primo, se una riga non esiste nell'offset desiderato, ottieni un NULL per impostazione predefinita. Con quest'ultimo si ottiene comunque il valore dalla prima riga presente, ovvero il valore dalla prima riga nella partizione. Considera la seguente query:
SELECT custid, orderdate, orderid, val,
FIRST_VALUE(val) OVER( PARTITION BY custid
ORDER BY orderdate, orderid
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW ) AS prevtwoval
FROM Sales.OrderValues
ORDER BY custid, orderdate, orderid; Questa query genera il seguente output:
custid orderdate orderid val prevtwoval ------- ---------- -------- ---------- ----------- 1 2018-08-25 10643 814.50 814.50 1 2018-10-03 10692 878.00 814.50 1 2018-10-13 10702 330.00 814.50 1 2019-01-15 10835 845.80 878.00 1 2019-03-16 10952 471.20 330.00 1 2019-04-09 11011 933.50 845.80 2 2017-09-18 10308 88.80 88.80 2 2018-08-08 10625 479.75 88.80 2 2018-11-28 10759 320.00 88.80 2 2019-03-04 10926 514.40 479.75 3 2017-11-27 10365 403.20 403.20 3 2018-04-15 10507 749.06 403.20 3 2018-05-13 10535 1940.85 403.20 3 2018-06-19 10573 2082.00 749.06 3 2018-09-22 10677 813.37 1940.85 3 2018-09-25 10682 375.50 2082.00 3 2019-01-28 10856 660.00 813.37 ...
Osservare che questa volta non ci sono NULL nell'output. Quindi c'è un certo valore nel supportare un frame con FIRST_VALUE e LAST_VALUE. Assicurati solo di ricordare la migliore pratica per essere sempre esplicito sulla specifica del frame con queste funzioni e utilizzare l'opzione ROWS con il frame minimo che contiene la riga che stai cercando.
Conclusione
Questo articolo si è concentrato su bug, insidie e best practice relative alle funzioni della finestra. Ricorda che entrambe le funzioni di aggregazione della finestra e le funzioni di offset della finestra FIRST_VALUE e LAST_VALUE supportano un frame e che se specifichi la clausola dell'ordine della finestra ma non specifichi l'unità del frame della finestra e la sua estensione associata, ottieni RANGE UNBOUNDED PRECEDING di predefinito. Ciò comporta una riduzione delle prestazioni quando la query viene ottimizzata con gli operatori in modalità riga. Con la funzione LAST_VALUE si ottengono i valori dalla riga corrente anziché dall'ultima riga nella partizione. Ricorda di essere esplicito sul frame e di preferire generalmente l'opzione RIGHE a RANGE. È fantastico vedere i miglioramenti delle prestazioni con l'operatore Window Aggregate in modalità batch. Quando è applicabile, almeno la trappola delle prestazioni viene eliminata.