Uno sviluppatore Oracle che usa spesso le espressioni regolari nel codice prima o poi può affrontare un fenomeno davvero mistico. Ricerche a lungo termine per la radice del problema possono portare a perdita di peso, appetito e provocare vari tipi di disturbi psicosomatici:tutto questo può essere prevenuto con l'aiuto della funzione regexp_replace. Può avere fino a 6 argomenti:
REGEXP_REPLACE (
- stringa_sorgente,
- modello,
- sostituendo_stringa,
- la posizione iniziale della ricerca di corrispondenza con un modello (predefinito 1),
- una posizione di occorrenza del modello in una stringa di origine (per impostazione predefinita 0 è uguale a tutte le occorrenze),
- modificatore (finora è un cavallo oscuro)
)
Restituisce la stringa_origine modificata in cui tutte le occorrenze del modello vengono sostituite dal valore passato nel parametro stringa_sostitutiva. Spesso viene utilizzata una versione breve della funzione, in cui vengono specificati i primi 3 argomenti, che è sufficiente per risolvere molti problemi. Farò lo stesso. Supponiamo di dover mascherare tutti i caratteri stringa con asterischi nella stringa "MASK:minuscolo". Per specificare l'intervallo di caratteri minuscoli, il modello "[a-z]" dovrebbe adattarsi.
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual Aspettativa
+------------------+ | RESULT | +------------------+ | MASK: ***** **** | +------------------+
Realtà
+------------------+ | RESULT | +------------------+ | *A**: ***** **** | +------------------+
Se questo evento non è stato riprodotto nel tuo database, sei fortunato finora. Ma più spesso inizi a scavare nel codice, a convertire stringhe da un insieme di caratteri a un altro e alla fine arriva la disperazione.
Definizione di un problema
Si pone la domanda:cosa c'è di così speciale nella lettera "A" da non essere stata sostituita perché anche il resto dei caratteri maiuscoli non doveva essere sostituito. Forse ci sono altre lettere corrette tranne questa. È necessario guardare l'intero alfabeto dei caratteri maiuscoli.
select regexp_replace('ABCDEFJHIGKLMNOPQRSTUVWXYZ', '[a-z]', '*') as alphabet from dual
+----------------------------+
| ALPHABET |
+----------------------------+
| A************************* |
+----------------------------+ Tuttavia
Se il sesto argomento della funzione non è specificato in modo esplicito, ad esempio, 'i' è senza distinzione tra maiuscole e minuscole o 'c' è con distinzione tra maiuscole e minuscole quando si confronta una stringa di origine con un modello, il l'espressione regolare utilizza il parametro NLS_SORT della sessione/database per impostazione predefinita. Ad esempio:
select value from sys.nls_session_parameters where parameter = 'NLS_SORT' +---------+ | VALUE | +---------+ | ENGLISH | +---------+
Questo parametro specifica il metodo di ordinamento in ORDER BY. Se parliamo di ordinamento di singoli caratteri semplici, allora un certo numero binario (codice NLSSORT) corrisponde a ciascuno di essi e l'ordinamento avviene effettivamente in base al valore di questi numeri.
Per illustrare questo, prendiamo i primi e gli ultimi caratteri dell'alfabeto, sia minuscoli che maiuscoli, e mettiamoli in una tabella non ordinata condizionatamente e chiamiamola ABC. Quindi, ordiniamo questo set in base al campo SYMBOL e visualizziamo il suo codice NLSSORT nel formato HEX accanto a ciascun simbolo.
with ABC as (
select column_value as symbol
from table(sys.odcivarchar2list('A','B','C','X','Y','Z','a','b','c','x','y','z'))
)
select symbol,
nlssort(symbol) nls_code_hex
from ABC
order by symbol
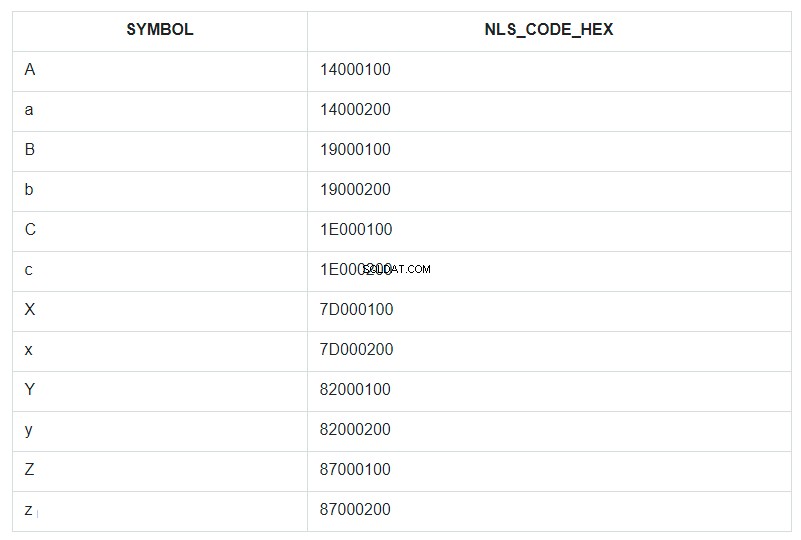
Nella query è specificato ORDER BY per il campo SYMBOL, ma in realtà nel database l'ordinamento è andato in base ai valori del campo NLS_CODE_HEX.
Ora, torna all'intervallo dal modello e guarda la tabella:qual è la verticale tra il simbolo 'a' (codice 14000200) e 'z' (codice 87000200)? Tutto tranne la "A" maiuscola. Questo è tutto ciò che è stato sostituito da un asterisco. E il codice 14000100 della lettera "A" non è compreso nel range di sostituzione da 14000200 a 87000200.
Cura
Specifica esplicitamente il modificatore di distinzione tra maiuscole e minuscole
select regexp_replace('MASK: lower case', '[a-z]', '*', 1, 0, 'c') from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+
Alcune fonti affermano che il modificatore 'c' è impostato di default, ma abbiamo appena visto che questo non è del tutto vero. E se qualcuno non l'ha visto, allora il parametro NLS_SORT della sua sessione/database è molto probabilmente impostato su BINARY e l'ordinamento viene eseguito in corrispondenza di codici di caratteri reali. Infatti, se modifichi il parametro di sessione, il problema sarà risolto.
ALTER SESSION SET NLS_SORT=BINARY;
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+ I test sono stati eseguiti in Oracle 12c.
Sentiti libero di lasciare i tuoi commenti e fai attenzione.