Il mese scorso ho pubblicato una sfida per creare un generatore di serie di numeri efficiente. Le risposte sono state travolgenti. C'erano molte idee e suggerimenti brillanti, con molte applicazioni ben oltre questa particolare sfida. Mi ha fatto capire quanto sia bello far parte di una comunità e che si possono ottenere cose straordinarie quando un gruppo di persone intelligenti unisce le forze. Grazie Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason e John Number2 per aver condiviso idee e commenti.
Inizialmente pensavo di scrivere un solo articolo per riassumere le idee presentate dalle persone, ma erano troppe. Quindi dividerò la copertura in diversi articoli. Questo mese mi concentrerò principalmente sui miglioramenti suggeriti da Charlie e Alan Burstein alle due soluzioni originali che ho pubblicato il mese scorso sotto forma di TVF in linea chiamate dbo.GetNumsItzikBatch e dbo.GetNumsItzik. Chiamerò le versioni migliorate rispettivamente dbo.GetNumsAlanCharlieItzikBatch e dbo.GetNumsAlanCharlieItzik.
È così eccitante!
Le soluzioni originali di Itzik
Come rapido promemoria, le funzioni che ho trattato il mese scorso utilizzano un CTE di base che definisce un costruttore di valori di tabella con 16 righe. Le funzioni utilizzano una serie di CTE a cascata, ciascuna delle quali applica un prodotto (cross join) di due istanze del CTE precedente. In questo modo, con cinque CTE oltre quello di base, puoi ottenere un set fino a 4.294.967.296 righe. Un CTE chiamato Nums utilizza la funzione ROW_NUMBER per produrre una serie di numeri che iniziano con 1. Infine, la query esterna calcola i numeri nell'intervallo richiesto tra gli input @low e @high.
La funzione dbo.GetNumsItzikBatch usa un join fittizio a una tabella con un indice columnstore per ottenere l'elaborazione batch. Ecco il codice per creare la tabella fittizia:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Ed ecco il codice che definisce la funzione dbo.GetNumsItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsItzikBatch(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Ho usato il codice seguente per testare la funzione con "Elimina risultati dopo l'esecuzione" abilitato in SSMS:
SELECT n FROM dbo.GetNumsItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Ecco le statistiche sulle prestazioni che ho ottenuto per questa esecuzione:
CPU time = 16985 ms, elapsed time = 18348 ms.
La funzione dbo.GetNumsItzik è simile, solo che non ha un join fittizio e normalmente ottiene l'elaborazione in modalità riga in tutto il piano. Ecco la definizione della funzione:
CREATE OR ALTER FUNCTION dbo.GetNumsItzik(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Ecco il codice che ho usato per testare la funzione:
SELECT n FROM dbo.GetNumsItzik(1, 100000000) OPTION(MAXDOP 1);
Ecco le statistiche sulle prestazioni che ho ottenuto per questa esecuzione:
CPU time = 19969 ms, elapsed time = 21229 ms.
I miglioramenti di Alan Burstein e Charlie
Alan e Charlie hanno suggerito diversi miglioramenti alle mie funzioni, alcuni con implicazioni sulle prestazioni moderate e altri con aspetti più drammatici. Inizierò con le scoperte di Charlie relative alle spese generali di compilazione e alla piegatura costante. Tratterò quindi i suggerimenti di Alan, comprese le sequenze basate su 1 rispetto a quelle basate su @low (condivise anche da Charlie e Jeff Moden), evitando ordinamenti non necessari e calcolando un intervallo di numeri in ordine opposto.
Risultati del tempo di compilazione
Come ha notato Charlie, un generatore di serie numeriche viene spesso utilizzato per generare serie con un numero di righe molto piccolo. In questi casi, il tempo di compilazione del codice può diventare una parte sostanziale del tempo totale di elaborazione della query. Ciò è particolarmente importante quando si utilizzano iTVF, poiché, a differenza delle stored procedure, non è il codice della query parametrizzato a essere ottimizzato, bensì il codice della query dopo l'incorporamento dei parametri. In altre parole, i parametri vengono sostituiti con i valori di input prima dell'ottimizzazione e il codice con le costanti viene ottimizzato. Questo processo può avere implicazioni sia negative che positive. Una delle implicazioni negative è che si ottengono più compilazioni poiché la funzione viene chiamata con valori di input diversi. Per questo motivo, i tempi di compilazione dovrebbero essere assolutamente presi in considerazione, specialmente quando si utilizza la funzione molto frequentemente con intervalli ridotti.
Ecco i tempi di compilazione trovati da Charlie per le varie cardinalità CTE di base:
2: 22ms 4: 9ms 16: 7ms 256: 35ms
È curioso vedere che tra questi, 16 è l'ottimale, e che c'è un salto molto drammatico quando si sale al livello successivo, che è 256. Ricordiamo che le funzioni dbo.GetNumsItzikBacth e dbo.GetNumsItzik usano la cardinalità CTE di base di 16 .
Piegatura costante
Il ripiegamento costante è spesso un'implicazione positiva che nelle giuste condizioni può essere abilitato grazie al processo di incorporamento dei parametri sperimentato da un iTVF. Ad esempio, supponiamo che la tua funzione abbia un'espressione @x + 1, dove @x è un parametro di input della funzione. Invochi la funzione con @x =5 come input. L'espressione incorporata diventa quindi 5 + 1 e, se idonea per la piegatura costante (ne parleremo più a breve), diventa 6. Se questa espressione fa parte di un'espressione più elaborata che coinvolge colonne e viene applicata a molti milioni di righe, questo può comportano risparmi non trascurabili nei cicli della CPU.
La parte difficile è che SQL Server è molto esigente su cosa piegare costantemente e cosa non piegare costantemente. Ad esempio, SQL Server non piega costante col1 + 5 + 1, né piega 5 + col1 + 1. Ma piega 5 + 1 + col1 a 6 + col1. Lo so. Quindi, ad esempio, se la tua funzione ha restituito SELECT @x + col1 + 1 AS mycol1 FROM dbo.T1, potresti abilitare il ripiegamento costante con la seguente piccola alterazione:SELECT @x + 1 + col1 AS mycol1 FROM dbo.T1. Non mi credi? Esamina i piani per le tre query seguenti nel database PerformanceV5 (o query simili con i tuoi dati) e verifica tu stesso:
SELECT orderid + 5 + 1 AS myorderid FROM dbo.orders; SELECT 5 + orderid + 1 AS myorderid FROM dbo.orders; SELECT 5 + 1 + orderid AS myorderid FROM dbo.orders;
Ho ottenuto le seguenti tre espressioni negli operatori Calcola scalare per queste tre query, rispettivamente:
[Expr1003] = Scalar Operator([PerformanceV5].[dbo].[Orders].[orderid]+(5)+(1)) [Expr1003] = Scalar Operator((5)+[PerformanceV5].[dbo].[Orders].[orderid]+(1)) [Expr1003] = Scalar Operator((6)+[PerformanceV5].[dbo].[Orders].[orderid])
Vedi dove sto andando con questo? Nelle mie funzioni ho usato la seguente espressione per definire la colonna dei risultati n:
@low + rownum - 1 AS n
Charlie si è reso conto che con la seguente piccola modifica, può consentire una piegatura costante:
@low - 1 + rownum AS n
Ad esempio, il piano per la query precedente che ho fornito su dbo.GetNumsItzik, con @low =1, aveva originariamente la seguente espressione definita dall'operatore Compute Scalar:
[Expr1154] = Scalar Operator((1)+[Expr1153]-(1))
Dopo aver applicato la modifica minore di cui sopra, l'espressione nel piano diventa:
[Expr1154] = Scalar Operator((0)+[Expr1153])
Fantastico!
Per quanto riguarda le implicazioni sulle prestazioni, ricorda che le statistiche sulle prestazioni che ho ottenuto per la query su dbo.GetNumsItzikBatch prima della modifica erano le seguenti:
CPU time = 16985 ms, elapsed time = 18348 ms.
Ecco i numeri che ho ottenuto dopo la modifica:
CPU time = 16375 ms, elapsed time = 17932 ms.
Ecco i numeri che ho ottenuto per la query contro dbo.GetNumsItzik originariamente:
CPU time = 19969 ms, elapsed time = 21229 ms.
Ed ecco i numeri dopo la modifica:
CPU time = 19266 ms, elapsed time = 20588 ms.
Le prestazioni sono migliorate solo un po' di qualche punto percentuale. Ma aspetta, c'è di più! Se devi elaborare i dati ordinati, le implicazioni sulle prestazioni possono essere molto più drammatiche, come vedremo più avanti nella sezione sull'ordinazione.
Sequenza basata su 1 rispetto a @low-based e numeri di riga opposti
Alan, Charlie e Jeff hanno notato che nella stragrande maggioranza dei casi nella vita reale in cui è necessario un intervallo di numeri, è necessario che inizi con 1 o talvolta 0. È molto meno comune aver bisogno di un punto di partenza diverso. Quindi potrebbe avere più senso fare in modo che la funzione restituisca sempre un intervallo che inizia, ad esempio, con 1 e, quando è necessario un punto di partenza diverso, applicare qualsiasi calcolo esternamente nella query rispetto alla funzione.
Alan in realtà ha avuto un'idea elegante per fare in modo che la TVF inline restituisca sia una colonna che inizia con 1 (semplicemente il risultato diretto della funzione ROW_NUMBER) alias come rn, sia una colonna che inizia con @low alias come n. Poiché la funzione viene incorporata, quando la query esterna interagisce solo con la colonna rn, la colonna n non viene nemmeno valutata e si ottengono vantaggi in termini di prestazioni. Quando è necessario che la sequenza inizi con @low, si interagisce con la colonna n e si paga il costo aggiuntivo applicabile, quindi non è necessario aggiungere calcoli esterni espliciti. Alan ha persino suggerito di aggiungere una colonna chiamata op che calcola i numeri in ordine opposto e interagisce con essa solo quando è necessaria una tale sequenza. La colonna op si basa sul calcolo:@high + 1 – rownum. Questa colonna ha un significato quando devi elaborare le righe in ordine decrescente, come dimostrerò più avanti nella sezione relativa all'ordinamento.
Quindi, applichiamo i miglioramenti di Charlie e Alan alle mie funzioni.
Per la versione in modalità batch, assicurati di creare prima la tabella fittizia con l'indice columnstore, se non è già presente:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Quindi usa la seguente definizione per la funzione dbo.GetNumsAlanCharlieItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Ecco un esempio di utilizzo della funzione:
SELECT * FROM dbo.GetNumsAlanCharlieItzikBatch(-2, 3) AS F ORDER BY rn;
Questo codice genera il seguente output:
rn op n --- --- --- 1 3 -2 2 2 -1 3 1 0 4 0 1 5 -1 2 6 -2 3
Quindi, verifica le prestazioni della funzione con 100 milioni di righe, restituendo prima la colonna n:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Ecco le statistiche sulle prestazioni che ho ottenuto per questa esecuzione:
CPU time = 16375 ms, elapsed time = 17932 ms.
Come puoi vedere, c'è un piccolo miglioramento rispetto a dbo.GetNumsItzikBatch sia nella CPU che nel tempo trascorso grazie al costante piegamento che ha avuto luogo qui.
Testare la funzione, solo che questa volta restituisce la colonna rn:
SELECT rn FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Ecco le statistiche sulle prestazioni che ho ottenuto per questa esecuzione:
CPU time = 15890 ms, elapsed time = 18561 ms.
Tempo CPU ulteriormente ridotto, anche se il tempo trascorso sembra essere leggermente aumentato in questa esecuzione rispetto a quando si interroga la colonna n.
La figura 1 ha i piani per entrambe le query.
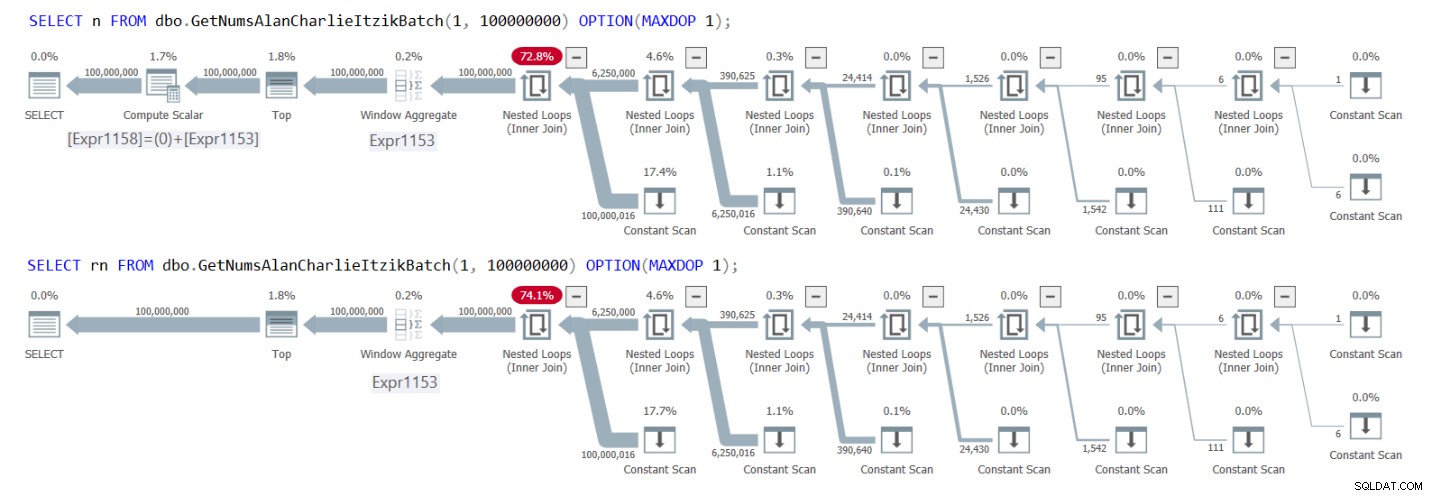 Figura 1:piani per GetNumsAlanCharlieItzikBatch che restituisce n contro rn
Figura 1:piani per GetNumsAlanCharlieItzikBatch che restituisce n contro rn
Puoi vedere chiaramente nei piani che quando si interagisce con la colonna rn, non è necessario l'operatore Calcola scalare aggiuntivo. Nota anche nel primo piano il risultato dell'attività di piegatura costante che ho descritto in precedenza, dove @low – 1 + rownum è stato inserito in 1 – 1 + rownum, e quindi piegato in 0 + rownum.
Ecco la definizione della versione in modalità riga della funzione denominata dbo.GetNumsAlanCharlieItzik:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzik(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum; Utilizzare il codice seguente per testare la funzione, prima interrogando la colonna n:
SELECT n FROM dbo.GetNumsAlanCharlieItzik(1, 100000000) OPTION(MAXDOP 1);
Ecco le statistiche sulle prestazioni che ho ottenuto:
CPU time = 19047 ms, elapsed time = 20121 ms.
Come puoi vedere, è un po' più veloce di dbo.GetNumsItzik.
Quindi, interroga la colonna rn:
SELECT rn FROM dbo.GetNumsAlanCharlieItzik(1, 100000000) OPTION(MAXDOP 1);
I numeri delle prestazioni migliorano ulteriormente sia sulla CPU che sul fronte del tempo trascorso:
CPU time = 17656 ms, elapsed time = 18990 ms.
Considerazioni sull'ordine
I miglioramenti sopra citati sono sicuramente interessanti e l'impatto sulle prestazioni non è trascurabile, ma non molto significativo. Un impatto molto più drammatico e profondo sulle prestazioni può essere osservato quando è necessario elaborare i dati ordinati in base alla colonna dei numeri. Questo potrebbe essere semplice come la necessità di restituire le righe ordinate, ma è altrettanto rilevante per qualsiasi esigenza di elaborazione basata sugli ordini, ad esempio un operatore Stream Aggregate per il raggruppamento e l'aggregazione, un algoritmo Merge Join per l'unione e così via.
Quando si esegue una query dbo.GetNumsItzikBatch o dbo.GetNumsItzik e si ordina per n, l'ottimizzatore non si rende conto che l'espressione di ordinamento sottostante @low + rownum – 1 è preservazione dell'ordine rispetto a rownum. L'implicazione è un po' simile a quella di un'espressione di filtro non SARGable, solo con un'espressione di ordinamento ciò si traduce in un operatore di ordinamento esplicito nel piano. L'ordinamento aggiuntivo influisce sul tempo di risposta. Influisce anche sul ridimensionamento, che in genere diventa n log n anziché n.
Per dimostrarlo, interroga dbo.GetNumsItzikBatch, richiedendo la colonna n, ordinata per n:
SELECT n FROM dbo.GetNumsItzikBatch(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Ho le seguenti statistiche sulle prestazioni:
CPU time = 34125 ms, elapsed time = 39656 ms.
Il tempo di esecuzione è più che raddoppiato rispetto al test senza la clausola ORDER BY.
Testare la funzione dbo.GetNumsItzik in modo simile:
SELECT n FROM dbo.GetNumsItzik(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Ho ottenuto i seguenti numeri per questo test:
CPU time = 52391 ms, elapsed time = 55175 ms.
Anche qui il tempo di esecuzione è più che raddoppiato rispetto al test senza la clausola ORDER BY.
La figura 2 ha i piani per entrambe le query.
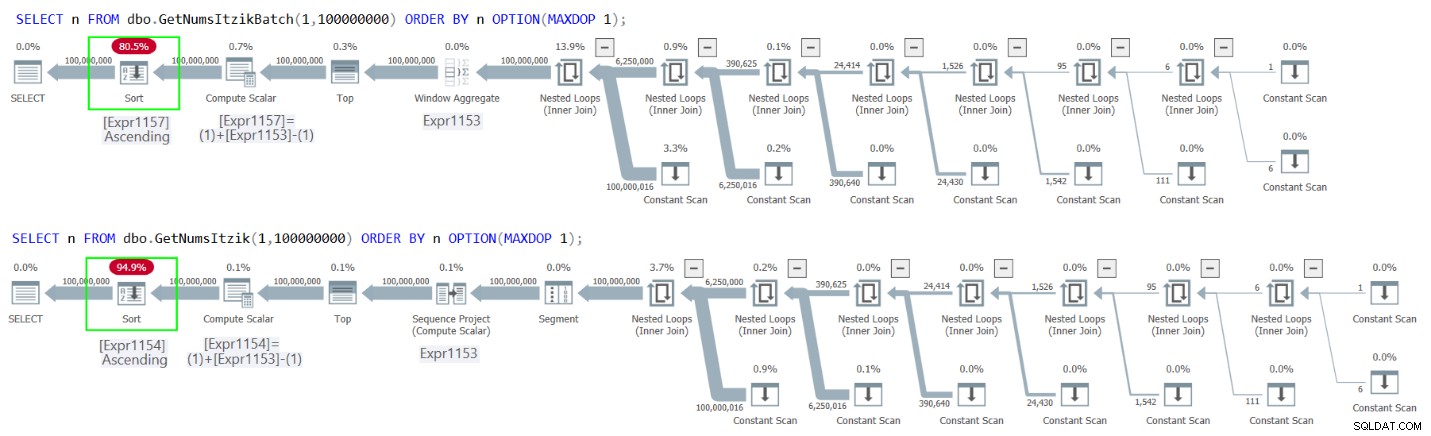 Figura 2:Piani per GetNumsItzikBatch e GetNumsItzik ordinati per n
Figura 2:Piani per GetNumsItzikBatch e GetNumsItzik ordinati per n
In entrambi i casi puoi vedere l'operatore Ordina esplicito nei piani.
Quando si interroga dbo.GetNumsAlanCharlieItzikBatch o dbo.GetNumsAlanCharlieItzik e si ordina per rn, l'ottimizzatore non ha bisogno di aggiungere un operatore di ordinamento al piano. Quindi potresti restituire n, ma ordinare per rn, e in questo modo evitare un ordinamento. Ciò che è un po' scioccante, però, e lo intendo in senso positivo, è che la versione rivista di n che sperimenta un piegamento costante, mantiene l'ordine! È facile per l'ottimizzatore rendersi conto che 0 + rownum è un'espressione di conservazione dell'ordine rispetto a rownum, e quindi evitare un ordinamento.
Provalo. Interroga dbo.GetNumsAlanCharlieItzikBatch, restituendo n e ordinando per n o rn, in questo modo:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n -- same with rn OPTION(MAXDOP 1);
Ho ottenuto i seguenti numeri di prestazioni:
CPU time = 16500 ms, elapsed time = 17684 ms.
Questo è ovviamente grazie al fatto che non c'era bisogno di un operatore di smistamento nel piano.
Esegui un test simile contro dbo.GetNumsAlanCharlieItzik:
SELECT n FROM dbo.GetNumsAlanCharlieItzik(1,100000000) ORDER BY n -- same with rn OPTION(MAXDOP 1);
Ho i seguenti numeri:
CPU time = 19546 ms, elapsed time = 20803 ms.
La figura 3 ha i piani per entrambe le query:
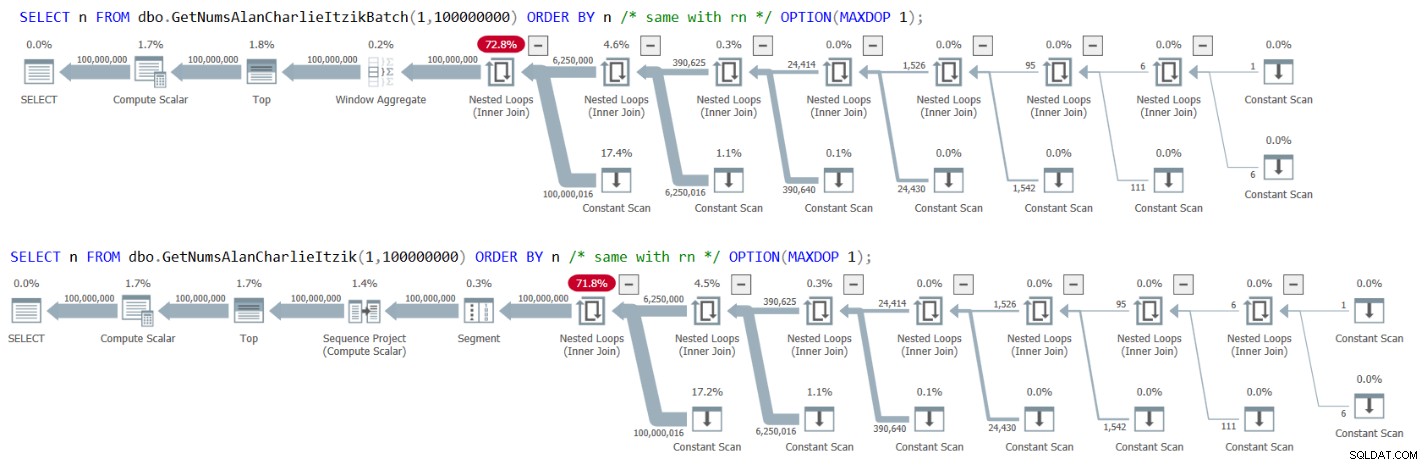
Figura 3:Piani per GetNumsAlanCharlieItzikBatch e GetNumsAlanCharlieItzik ordinando per n o rn
Osserva che non è presente alcun operatore di ordinamento nei piani.
Ti fa venire voglia di cantare...
All you need is constant folding All you need is constant folding All you need is constant folding, constant folding Constant folding is all you need
Grazie Charlie!
Ma cosa succede se devi restituire o elaborare i numeri in ordine decrescente? Il tentativo più ovvio è usare ORDER BY n DESC, o ORDER BY rn DESC, in questo modo:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n DESC OPTION(MAXDOP 1); SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY rn DESC OPTION(MAXDOP 1);
Sfortunatamente, tuttavia, entrambi i casi determinano un ordinamento esplicito nei piani, come mostrato nella Figura 4.
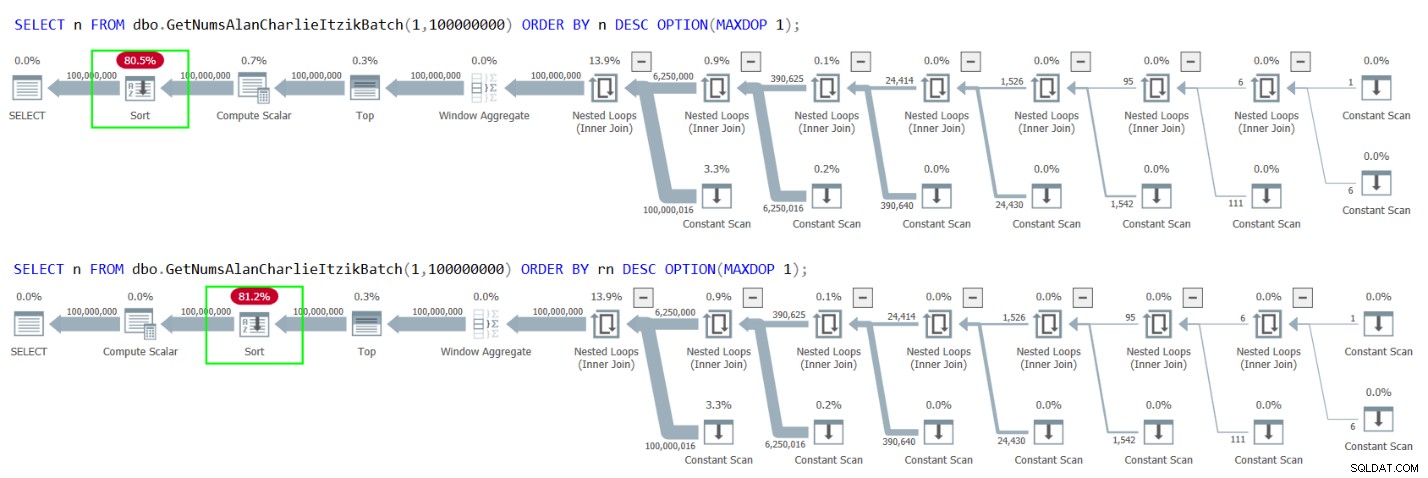 Figura 4:Piani per GetNumsAlanCharlieItzikBatch ordinando per n o rn decrescente
Figura 4:Piani per GetNumsAlanCharlieItzikBatch ordinando per n o rn decrescente
È qui che l'ingegnoso trucco di Alan con la rubrica diventa un vero toccasana. Restituisci la colonna op mentre ordini per n o rn, in questo modo:
SELECT op FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Il piano per questa query è mostrato nella Figura 5.
 Figura 5:piano per GetNumsAlanCharlieItzikBatch che restituisce op e ordina per n o rn crescente
Figura 5:piano per GetNumsAlanCharlieItzikBatch che restituisce op e ordina per n o rn crescente
Ottieni i dati ordinati per n decrescente e non è necessario un ordinamento nel piano.
Grazie Alan!
Riepilogo delle prestazioni
Allora, cosa abbiamo imparato da tutto questo?
I tempi di compilazione possono essere un fattore determinante, soprattutto quando si utilizza frequentemente la funzione con intervalli ridotti. Su una scala logaritmica con base 2, il dolce 16 sembra essere un bel numero magico.
Comprendi le peculiarità della piegatura costante e usale a tuo vantaggio. Quando un iTVF ha espressioni che coinvolgono parametri, costanti e colonne, inserisci i parametri e le costanti nella parte iniziale dell'espressione. Ciò aumenterà la probabilità di piegatura, ridurrà il sovraccarico della CPU e aumenterà la probabilità di conservazione dell'ordine.
Va bene avere più colonne utilizzate per scopi diversi in un iTVF e interrogare quelle pertinenti in ogni caso senza preoccuparsi di pagare quelle che non sono referenziate.
Quando è necessario restituire la sequenza numerica nell'ordine opposto, utilizzare la colonna originale n o rn nella clausola ORDER BY con ordine crescente e restituire la colonna op, che calcola i numeri in ordine inverso.
La figura 6 riassume i numeri delle prestazioni che ho ottenuto nei vari test.
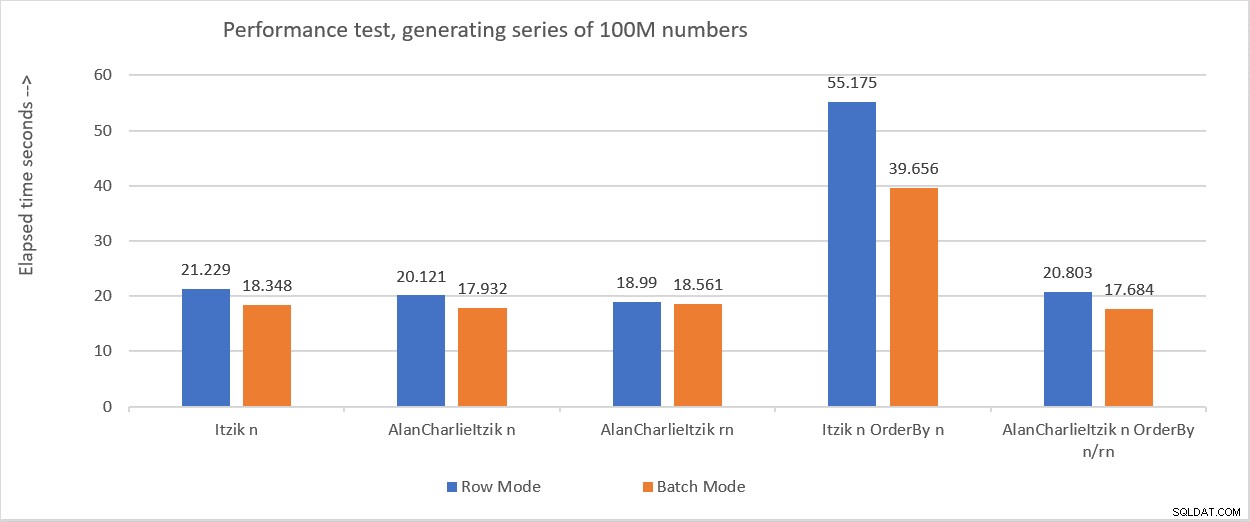 Figura 6:riepilogo delle prestazioni
Figura 6:riepilogo delle prestazioni
Il mese prossimo continuerò a esplorare ulteriori idee, approfondimenti e soluzioni alla sfida del generatore di serie di numeri.



