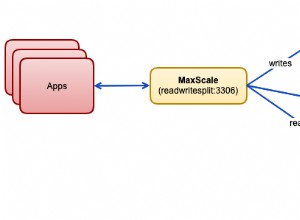
HAProxy e ProxySQL sono entrambi bilanciatori di carico molto popolari nel mondo MySQL, ma c'è una differenza significativa tra i due proxy. Non entreremo nei dettagli qui, puoi leggere di più su HAProxy in HAProxy Tutorial e ProxySQL in ProxySQL Tutorial. La differenza più importante è che ProxySQL è un proxy compatibile con SQL, analizza il traffico e comprende il protocollo MySQL e, in quanto tale, può essere utilizzato per il modellamento del traffico avanzato:puoi bloccare le query, riscriverle, indirizzarle a host particolari, memorizzare nella cache loro e molti altri. HAProxy, d'altra parte, è un proxy di livello 4 molto semplice ma efficiente e tutto ciò che fa è inviare pacchetti al back-end. ProxySQL può essere utilizzato per eseguire una suddivisione in lettura-scrittura:comprende l'SQL e può essere configurato per rilevare se una query è SELECT o meno e instradarla di conseguenza:SELECT a tutti i nodi, altre query solo per il master. Questa funzione non è disponibile in HAProxy, che deve utilizzare due porte separate e due backend separati per master e slave:la suddivisione in lettura/scrittura deve essere eseguita sul lato dell'applicazione.
Perché migrare a ProxySQL?
Sulla base delle differenze che abbiamo spiegato sopra, vorremmo dire che il motivo principale per cui potresti voler passare da HAProxy a ProxySQL è a causa della mancanza della divisione lettura-scrittura in HAProxy. Se utilizzi un cluster di database MySQL e non importa se si tratta di una replica asincrona o di un cluster Galera, probabilmente vorrai essere in grado di dividere le letture dalle scritture. Per la replica MySQL, ovviamente, questo sarebbe l'unico modo per utilizzare il cluster di database poiché le scritture devono sempre essere inviate al master. Pertanto, se non è possibile eseguire la divisione lettura-scrittura, è possibile inviare query solo al master. Per Galera la divisione lettura-scrittura non è un must, ma sicuramente un bene da avere. Certo, puoi configurare tutti i nodi Galera come un unico back-end in HAProxy e inviare traffico a tutti loro in modalità round-robin, ma ciò potrebbe comportare scritture da più nodi in conflitto tra loro, causando deadlock e calo delle prestazioni. Abbiamo anche riscontrato problemi e bug all'interno del cluster Galera, per i quali, fino a quando non sono stati risolti, la soluzione alternativa era indirizzare tutte le scritture su un singolo nodo. Pertanto, la migliore pratica consiste nell'inviare tutte le scritture a un nodo Galera in quanto ciò porta a un comportamento più stabile e prestazioni migliori.
Un altro ottimo motivo per la migrazione a ProxySQL è la necessità di avere un migliore controllo sul traffico. Con HAProxy non puoi fare nulla:invia semplicemente il traffico ai suoi backend. Con ProxySQL puoi modellare il tuo traffico utilizzando regole di query (abbinando il traffico utilizzando espressioni regolari, utente, schema, host di origine e molti altri). Puoi reindirizzare OLAP SELECTs allo slave di analisi (è vero sia per la replica che per Galera). Puoi scaricare il tuo master reindirizzando alcuni dei SELECT su di esso. È possibile implementare un firewall SQL. Puoi aggiungere un ritardo ad alcune query, puoi terminare le query se richiedono più di un tempo predefinito. Puoi riscrivere le query per aggiungere suggerimenti per l'ottimizzazione. Tutto ciò non è possibile con HAProxy.
Come migrare da HAProxy a ProxySQL?
Per prima cosa, consideriamo la seguente topologia...
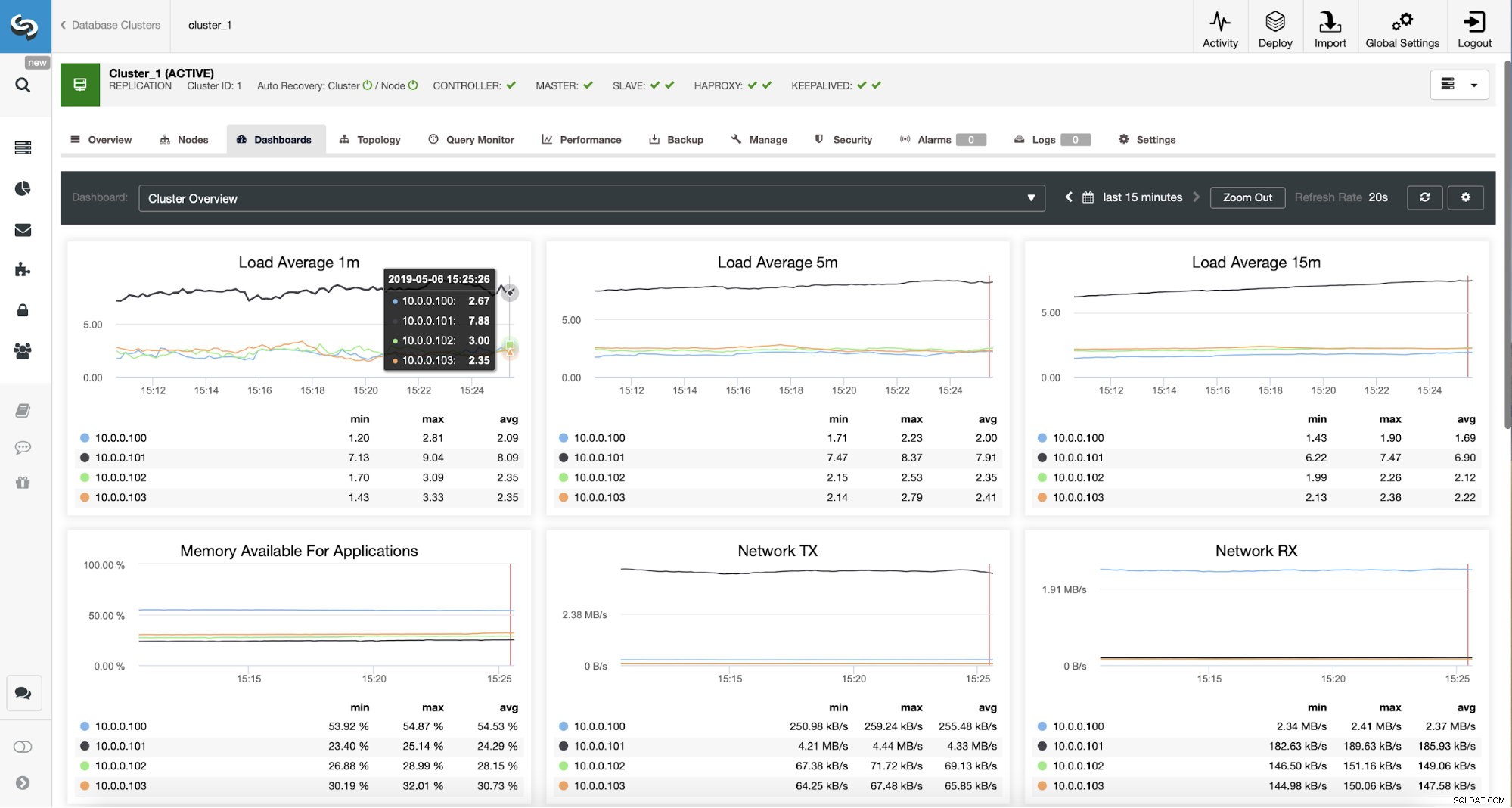
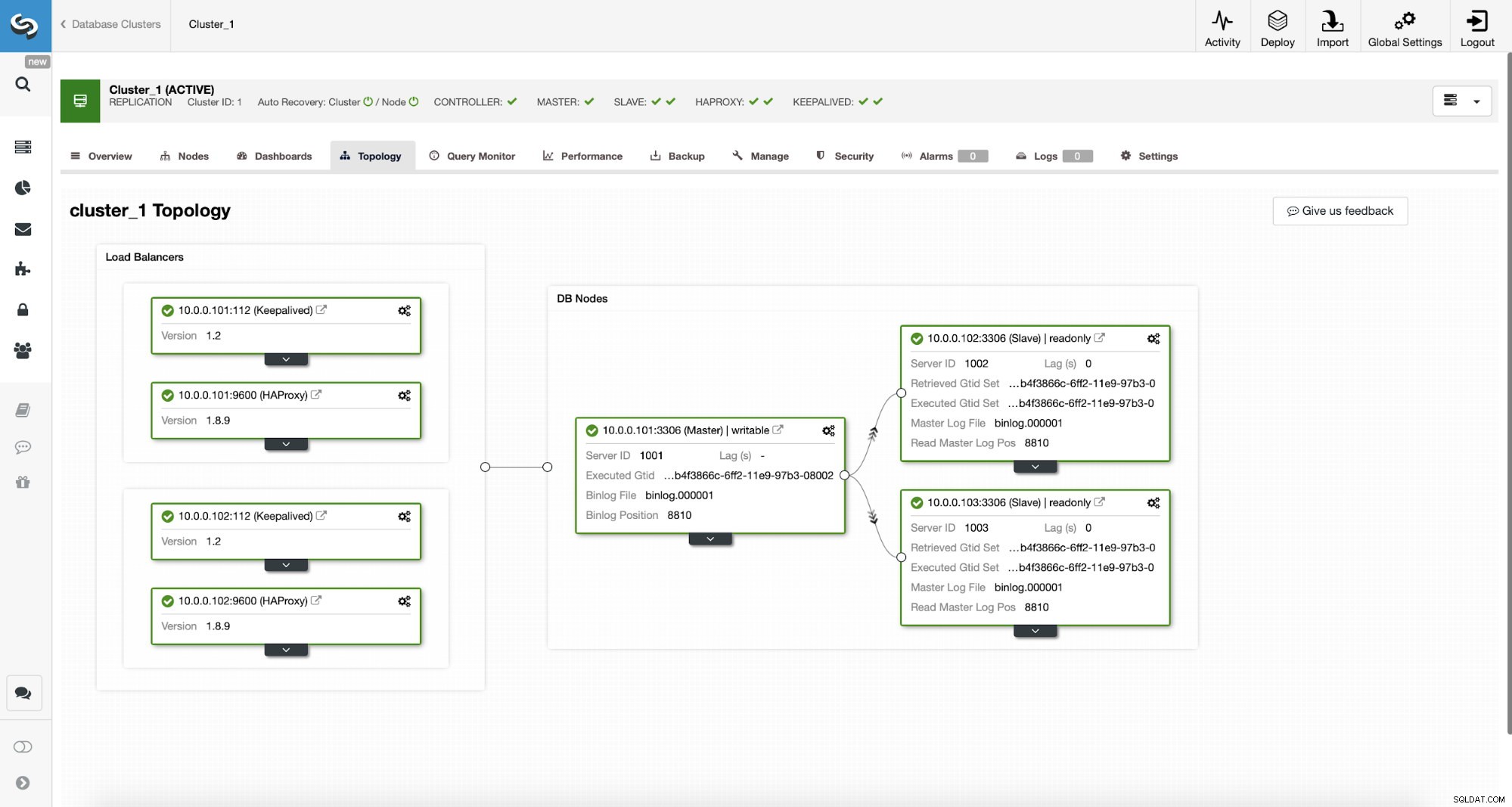 Topologia MySQL di ClusterControl
Topologia MySQL di ClusterControl 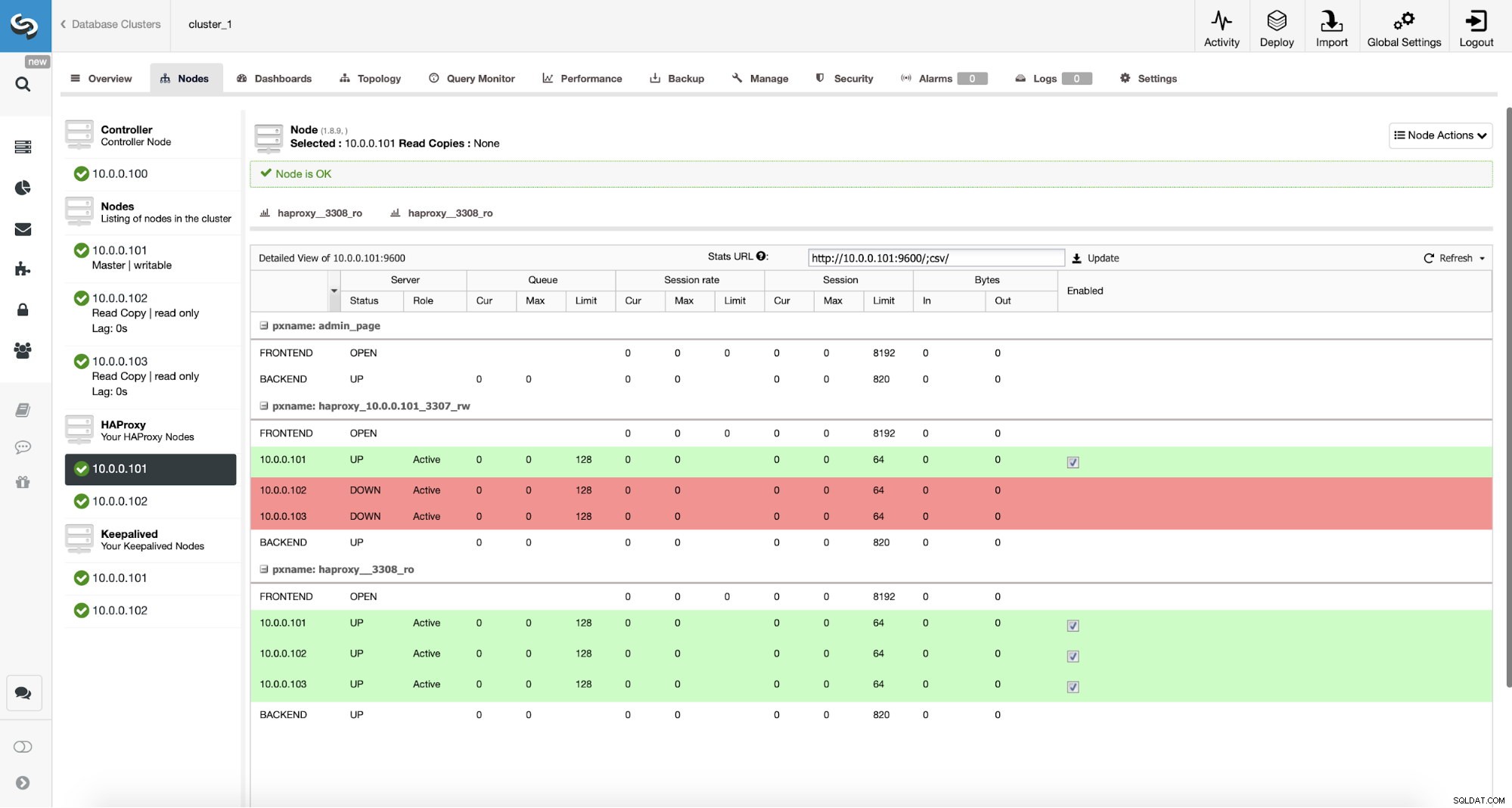 Cluster di replica MySQL in ClusterControl
Cluster di replica MySQL in ClusterControl Abbiamo qui un cluster di replica composto da un master e due slave. Abbiamo due nodi HAProxy distribuiti, ciascuno utilizza due backend:sulla porta 3307 per master (scritture) e 3308 per tutti i nodi (letture). Keepalived viene utilizzato per fornire un IP virtuale su queste due istanze HAProxy:se una di esse si guasta, ne verrà utilizzata un'altra. La nostra applicazione si collega direttamente al VIP, tramite esso a una delle istanze HAProxy. Supponiamo che la nostra applicazione (useremo Sysbench) non possa eseguire la divisione in lettura-scrittura, quindi dobbiamo connetterci al backend "scrittore". Di conseguenza, la maggior parte del carico è sul nostro master (10.0.0.101).
Quali sarebbero i passaggi per migrare a ProxySQL? Pensiamoci un attimo. Innanzitutto, dobbiamo distribuire e configurare ProxySQL. Dovremo aggiungere server a ProxySQL, creare utenti di monitoraggio richiesti e creare regole di query appropriate. Infine, dovremo distribuire Keepalived su ProxySQL, creare un altro IP virtuale e quindi garantire il passaggio più semplice possibile per la nostra applicazione da HAProxy a ProxySQL.
Diamo un'occhiata a come possiamo farlo...
Come installare ProxySQL
Si può installare ProxySQL in molti modi. Puoi utilizzare il repository, sia da ProxySQL stesso (https://repo.proxysql.com) o se ti capita di utilizzare Percona XtraDB Cluster, puoi anche installare ProxySQL dal repository Percona anche se potrebbe richiedere una configurazione aggiuntiva poiché si basa sulla CLI strumenti di amministrazione creati per PXC. Dato che stiamo parlando di replica, il loro utilizzo potrebbe solo rendere le cose più complesse. Infine, puoi anche installare i binari ProxySQL dopo averli scaricati da ProxySQL GitHub. Attualmente ci sono due versioni stabili, 1.4.xe 2.0.x. Ci sono differenze tra ProxySQL 1.4 e ProxySQL 2.0 in termini di funzionalità, per questo blog ci atterremo al ramo 1.4.x, poiché è testato meglio e il set di funzionalità è sufficiente per noi.
Utilizzeremo il repository ProxySQL e implementeremo ProxySQL su due nodi aggiuntivi:10.0.0.103 e 10.0.0.104.
Innanzitutto, installeremo ProxySQL utilizzando il repository ufficiale. Ci assicureremo inoltre che il client MySQL sia installato (lo useremo per configurare ProxySQL). Tieni presente che il processo che stiamo attraversando non è di livello produttivo. Per la produzione vorrai almeno modificare le credenziali predefinite per l'utente amministrativo. Dovrai anche rivedere la configurazione e assicurarti che sia in linea con le tue aspettative e requisiti.
apt-get install -y lsb-release
wget -O - 'https://repo.proxysql.com/ProxySQL/repo_pub_key' | apt-key add -
echo deb https://repo.proxysql.com/ProxySQL/proxysql-1.4.x/$(lsb_release -sc)/ ./ | tee /etc/apt/sources.list.d/proxysql.list
apt-get -y update
apt-get -y install proxysql
service proxysql startOra, quando ProxySQL è stato avviato, utilizzeremo la CLI per configurare ProxySQL.
mysql -uadmin -padmin -P6032 -h127.0.0.1In primo luogo, definiremo i server back-end e gli hostgroup di replica:
mysql> INSERT INTO mysql_servers (hostgroup_id, hostname) VALUES (10, '10.0.0.101'), (20, '10.0.0.102'), (20, '10.0.0.103');
Query OK, 3 rows affected (0.91 sec)mysql> INSERT INTO mysql_replication_hostgroups (writer_hostgroup, reader_hostgroup) VALUES (10, 20);
Query OK, 1 row affected (0.00 sec)Abbiamo tre server, abbiamo anche definito che ProxySQL dovrebbe usare hostgroup 10 per master (nodo con read_only=0) e hostgroup 20 per slave (read_only=1).
Come passaggio successivo, dobbiamo aggiungere un utente di monitoraggio sui nodi MySQL in modo che ProxySQL possa monitorarli. Andremo con le impostazioni predefinite, idealmente cambierai le credenziali in ProxySQL.
mysql> SHOW VARIABLES LIKE 'mysql-monitor_username';
+------------------------+---------+
| Variable_name | Value |
+------------------------+---------+
| mysql-monitor_username | monitor |
+------------------------+---------+
1 row in set (0.00 sec)mysql> SHOW VARIABLES LIKE 'mysql-monitor_password';
+------------------------+---------+
| Variable_name | Value |
+------------------------+---------+
| mysql-monitor_password | monitor |
+------------------------+---------+
1 row in set (0.00 sec)Quindi, dobbiamo creare l'utente "monitor" con la password "monitor". Per fare ciò dovremo eseguire la seguente concessione sul server MySQL principale:
mysql> create user example@sqldat.com'%' identified by 'monitor';
Query OK, 0 rows affected (0.56 sec)Tornando a ProxySQL:dobbiamo configurare gli utenti che la nostra applicazione utilizzerà per accedere a MySQL e alle regole di query, che hanno lo scopo di darci una suddivisione in lettura e scrittura.
mysql> INSERT INTO mysql_users (username, password, default_hostgroup) VALUES ('sbtest', 'sbtest', 10);
Query OK, 1 row affected (0.34 sec)mysql> INSERT INTO mysql_query_rules (rule_id,active,match_digest,destination_hostgroup,apply) VALUES (100, 1, '^SELECT.*FOR UPDATE$',10,1), (200,1,'^SELECT',20,1), (300,1,'.*',10,1);
Query OK, 3 rows affected (0.01 sec)Tieni presente che abbiamo utilizzato la password nel testo normale e faremo affidamento su ProxySQL per l'hashing. Per motivi di sicurezza dovresti passare qui esplicitamente l'hash della password MySQL.
Infine, dobbiamo applicare tutte le modifiche.
mysql> LOAD MYSQL SERVERS TO RUNTIME;
Query OK, 0 rows affected (0.02 sec)mysql> LOAD MYSQL USERS TO RUNTIME;
Query OK, 0 rows affected (0.01 sec)mysql> LOAD MYSQL QUERY RULES TO RUNTIME;
Query OK, 0 rows affected (0.01 sec)mysql> SAVE MYSQL SERVERS TO DISK;
Query OK, 0 rows affected (0.07 sec)mysql> SAVE MYSQL QUERY RULES TO DISK;
Query OK, 0 rows affected (0.02 sec)Vogliamo anche caricare le password con hash dal runtime:le password in testo normale vengono hash quando vengono caricate nella configurazione di runtime, per mantenerle hash su disco dobbiamo caricarle dal runtime e quindi memorizzarle su disco:
mysql> SAVE MYSQL USERS FROM RUNTIME;
Query OK, 0 rows affected (0.00 sec)mysql> SAVE MYSQL USERS TO DISK;
Query OK, 0 rows affected (0.02 sec)Questo è tutto quando si tratta di ProxySQL. Prima di eseguire ulteriori passaggi, dovresti verificare se puoi connetterti ai proxy dai tuoi server delle applicazioni.
example@sqldat.com:~# mysql -h 10.0.0.103 -usbtest -psbtest -P6033 -e "SELECT * FROM sbtest.sbtest4 LIMIT 1\G"
mysql: [Warning] Using a password on the command line interface can be insecure.
*************************** 1. row ***************************
id: 1
k: 50147
c: 68487932199-96439406143-93774651418-41631865787-96406072701-20604855487-25459966574-28203206787-41238978918-19503783441
pad: 22195207048-70116052123-74140395089-76317954521-98694025897Nel nostro caso, sembra tutto a posto. Ora è il momento di installare Keepalived.
Installazione conservata
L'installazione è abbastanza semplice (almeno su Ubuntu 16.04, che abbiamo usato):
apt install keepalivedQuindi devi creare file di configurazione per entrambi i server:
Nodo keepalived principale:
vrrp_script chk_haproxy {
script "killall -0 haproxy" # verify the pid existance
interval 2 # check every 2 seconds
weight 2 # add 2 points of prio if OK
}
vrrp_instance VI_HAPROXY {
interface eth1 # interface to monitor
state MASTER
virtual_router_id 52 # Assign one ID for this route
priority 101
unicast_src_ip 10.0.0.103
unicast_peer {
10.0.0.104
}
virtual_ipaddress {
10.0.0.112 # the virtual IP
}
track_script {
chk_haproxy
}
# notify /usr/local/bin/notify_keepalived.sh
}Backup del nodo keepalive:
vrrp_script chk_haproxy {
script "killall -0 haproxy" # verify the pid existance
interval 2 # check every 2 seconds
weight 2 # add 2 points of prio if OK
}
vrrp_instance VI_HAPROXY {
interface eth1 # interface to monitor
state MASTER
virtual_router_id 52 # Assign one ID for this route
priority 100
unicast_src_ip 10.0.0.103
unicast_peer {
10.0.0.104
}
virtual_ipaddress {
10.0.0.112 # the virtual IP
}
track_script {
chk_haproxy
}
# notify /usr/local/bin/notify_keepalived.shEcco fatto, puoi iniziare a mantenere vivo su entrambi i nodi:
service keepalived startDovresti vedere le informazioni nei registri che uno dei nodi è entrato nello stato MASTER e che VIP è stato attivato su quel nodo.
May 7 09:52:11 vagrant systemd[1]: Starting Keepalive Daemon (LVS and VRRP)...
May 7 09:52:11 vagrant Keepalived[26686]: Starting Keepalived v1.2.24 (08/06,2018)
May 7 09:52:11 vagrant Keepalived[26686]: Opening file '/etc/keepalived/keepalived.conf'.
May 7 09:52:11 vagrant Keepalived[26696]: Starting Healthcheck child process, pid=26697
May 7 09:52:11 vagrant Keepalived[26696]: Starting VRRP child process, pid=26698
May 7 09:52:11 vagrant Keepalived_healthcheckers[26697]: Initializing ipvs
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Registering Kernel netlink reflector
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Registering Kernel netlink command channel
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Registering gratuitous ARP shared channel
May 7 09:52:11 vagrant systemd[1]: Started Keepalive Daemon (LVS and VRRP).
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Unable to load ipset library
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Unable to initialise ipsets
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Opening file '/etc/keepalived/keepalived.conf'.
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Using LinkWatch kernel netlink reflector...
May 7 09:52:11 vagrant Keepalived_healthcheckers[26697]: Registering Kernel netlink reflector
May 7 09:52:11 vagrant Keepalived_healthcheckers[26697]: Registering Kernel netlink command channel
May 7 09:52:11 vagrant Keepalived_healthcheckers[26697]: Opening file '/etc/keepalived/keepalived.conf'.
May 7 09:52:11 vagrant Keepalived_healthcheckers[26697]: Using LinkWatch kernel netlink reflector...
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: pid 26701 exited with status 256
May 7 09:52:12 vagrant Keepalived_vrrp[26698]: VRRP_Instance(VI_HAPROXY) Transition to MASTER STATE
May 7 09:52:13 vagrant Keepalived_vrrp[26698]: pid 26763 exited with status 256
May 7 09:52:13 vagrant Keepalived_vrrp[26698]: VRRP_Instance(VI_HAPROXY) Entering MASTER STATE
May 7 09:52:15 vagrant Keepalived_vrrp[26698]: pid 26806 exited with status 256example@sqldat.com:~# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 08:00:27:ee:87:c4 brd ff:ff:ff:ff:ff:ff
inet 10.0.2.15/24 brd 10.0.2.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::a00:27ff:feee:87c4/64 scope link
valid_lft forever preferred_lft forever
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 08:00:27:fc:ac:21 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.103/24 brd 10.0.0.255 scope global eth1
valid_lft forever preferred_lft forever
inet 10.0.0.112/32 scope global eth1
valid_lft forever preferred_lft forever
inet6 fe80::a00:27ff:fefc:ac21/64 scope link
valid_lft forever preferred_lft foreverCome puoi vedere, sul nodo 10.0.0.103 è stato sollevato un VIP (10.0.0.112). Possiamo ora concludere spostando il traffico dalla vecchia configurazione a quella nuova.
Passaggio del traffico a una configurazione ProxySQL
Esistono molti metodi su come farlo, dipende principalmente dal tuo ambiente particolare. Se ti capita di utilizzare il DNS per mantenere un dominio che punta al tuo VIP HAProxy, puoi semplicemente apportare una modifica lì e, gradualmente, nel tempo tutte le connessioni punteranno al nuovo VIP. Puoi anche apportare una modifica alla tua applicazione, soprattutto se i dettagli della connessione sono hardcoded:una volta implementata la modifica, i nodi inizieranno a connettersi alla nuova configurazione. Non importa come lo fai, sarebbe fantastico testare la nuova configurazione prima di effettuare un passaggio globale. L'hai sicuramente testato sul tuo ambiente di staging, ma non è una cattiva idea scegliere una manciata di server di app e reindirizzarli al nuovo proxy, monitorando come appaiono in termini di prestazioni. Di seguito è riportato un semplice esempio di utilizzo di iptables, che può essere utile per i test.
Sugli host ProxySQL, reindirizza il traffico dall'host 10.0.0.11 e dalla porta 3307 all'host 10.0.0.112 e dalla porta 6033:
iptables -t nat -A OUTPUT -p tcp -d 10.0.0.111 --dport 3307 -j DNAT --to-destination 10.0.0.112:6033A seconda dell'applicazione, potrebbe essere necessario riavviare il server Web o altri servizi (se l'app crea un pool costante di connessioni al database) o semplicemente attendere l'apertura di nuove connessioni su ProxySQL. Puoi verificare che ProxySQL stia ricevendo il traffico:
mysql> show processlist;
+-----------+--------+--------+-----------+---------+---------+-----------------------------------------------------------------------------+
| SessionID | user | db | hostgroup | command | time_ms | info |
+-----------+--------+--------+-----------+---------+---------+-----------------------------------------------------------------------------+
| 12 | sbtest | sbtest | 20 | Sleep | 0 | |
| 13 | sbtest | sbtest | 10 | Query | 0 | DELETE FROM sbtest23 WHERE id=49957 |
| 14 | sbtest | sbtest | 10 | Query | 59 | DELETE FROM sbtest11 WHERE id=50185 |
| 15 | sbtest | sbtest | 20 | Query | 59 | SELECT c FROM sbtest8 WHERE id=46054 |
| 16 | sbtest | sbtest | 20 | Query | 0 | SELECT DISTINCT c FROM sbtest27 WHERE id BETWEEN 50115 AND 50214 ORDER BY c |
| 17 | sbtest | sbtest | 10 | Query | 0 | DELETE FROM sbtest32 WHERE id=50084 |
| 18 | sbtest | sbtest | 10 | Query | 26 | DELETE FROM sbtest28 WHERE id=34611 |
| 19 | sbtest | sbtest | 10 | Query | 16 | DELETE FROM sbtest4 WHERE id=50151 |
+-----------+--------+--------+-----------+---------+---------+-----------------------------------------------------------------------------+Ecco fatto, abbiamo spostato il traffico da HAProxy nella configurazione di ProxySQL. Ci sono voluti alcuni passaggi ma è sicuramente fattibile con piccolissime interruzioni al servizio.
Come migrare da HAProxy a ProxySQL utilizzando ClusterControl?
Nella sezione precedente abbiamo spiegato come distribuire manualmente la configurazione di ProxySQL e quindi migrare in essa. In questa sezione vorremmo spiegare come raggiungere lo stesso obiettivo utilizzando ClusterControl. La configurazione iniziale è esattamente la stessa, quindi dobbiamo procedere con la distribuzione di ProxySQL.
Distribuzione di ProxySQL utilizzando ClusterControl
La distribuzione di ProxySQL in ClusterControl è solo questione di una manciata di clic.
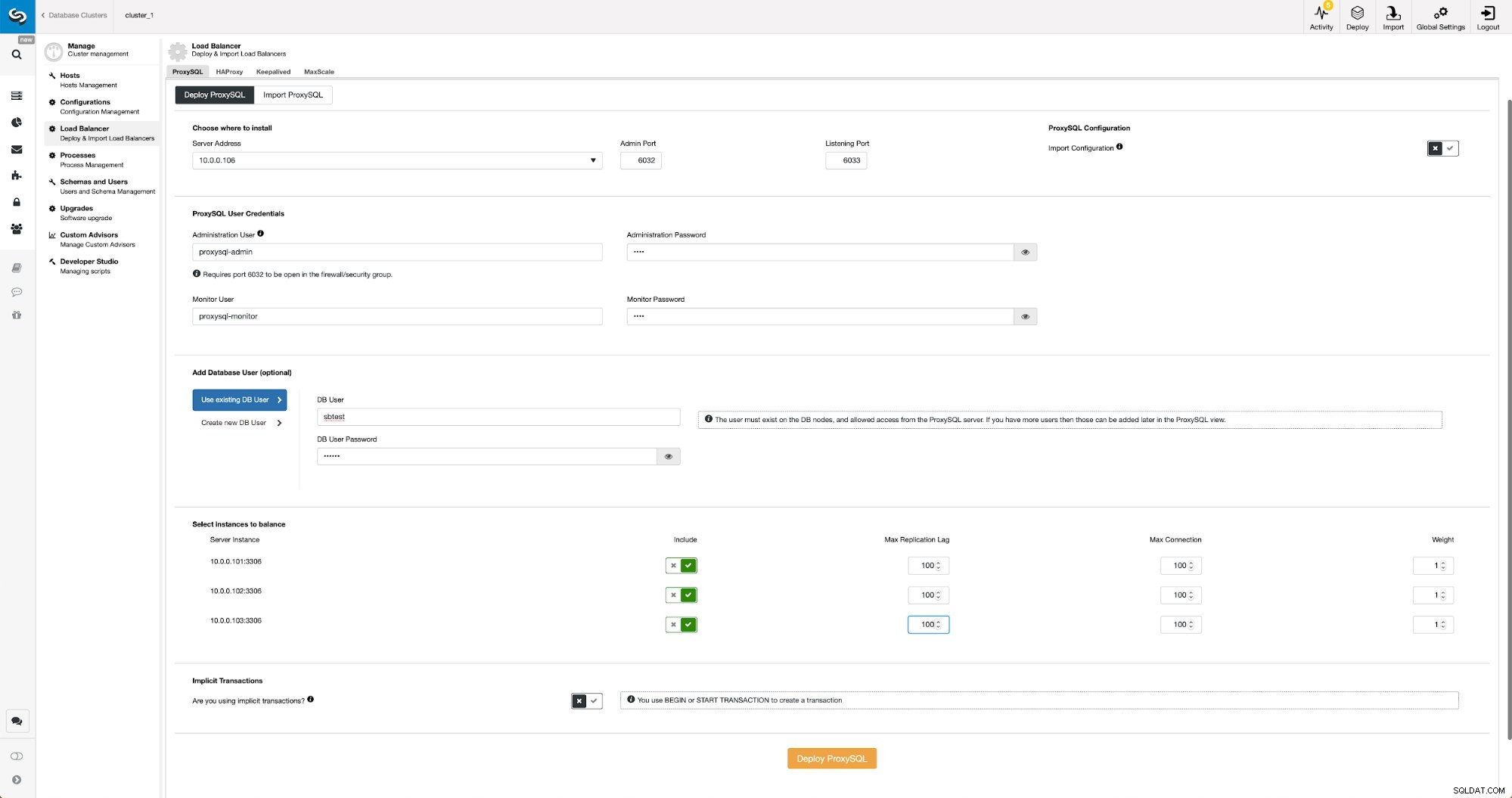 Distribuisci ProxySQL in ClusterControl
Distribuisci ProxySQL in ClusterControl Abbiamo dovuto scegliere l'IP o il nome host di un nodo, passare le credenziali per l'utente amministrativo CLI e l'utente di monitoraggio MySQL. Abbiamo deciso di utilizzare MySQL esistente e abbiamo passato i dettagli di accesso per l'utente 'sbtest'@'%' che utilizziamo nell'applicazione. Abbiamo scelto quali nodi vogliamo utilizzare nel bilanciamento del carico, abbiamo anche aumentato il ritardo massimo di replica (se tale soglia viene superata, ProxySQL non invierà il traffico a quello slave) da 10 secondi predefiniti a 100 poiché stiamo già soffrendo della replica ritardo. Dopo poco i nodi ProxySQL verranno aggiunti al cluster.
Distribuzione di Keepalived per ProxySQL utilizzando ClusterControl
Una volta aggiunti i nodi ProxySQL, è il momento di distribuire Keepalived.
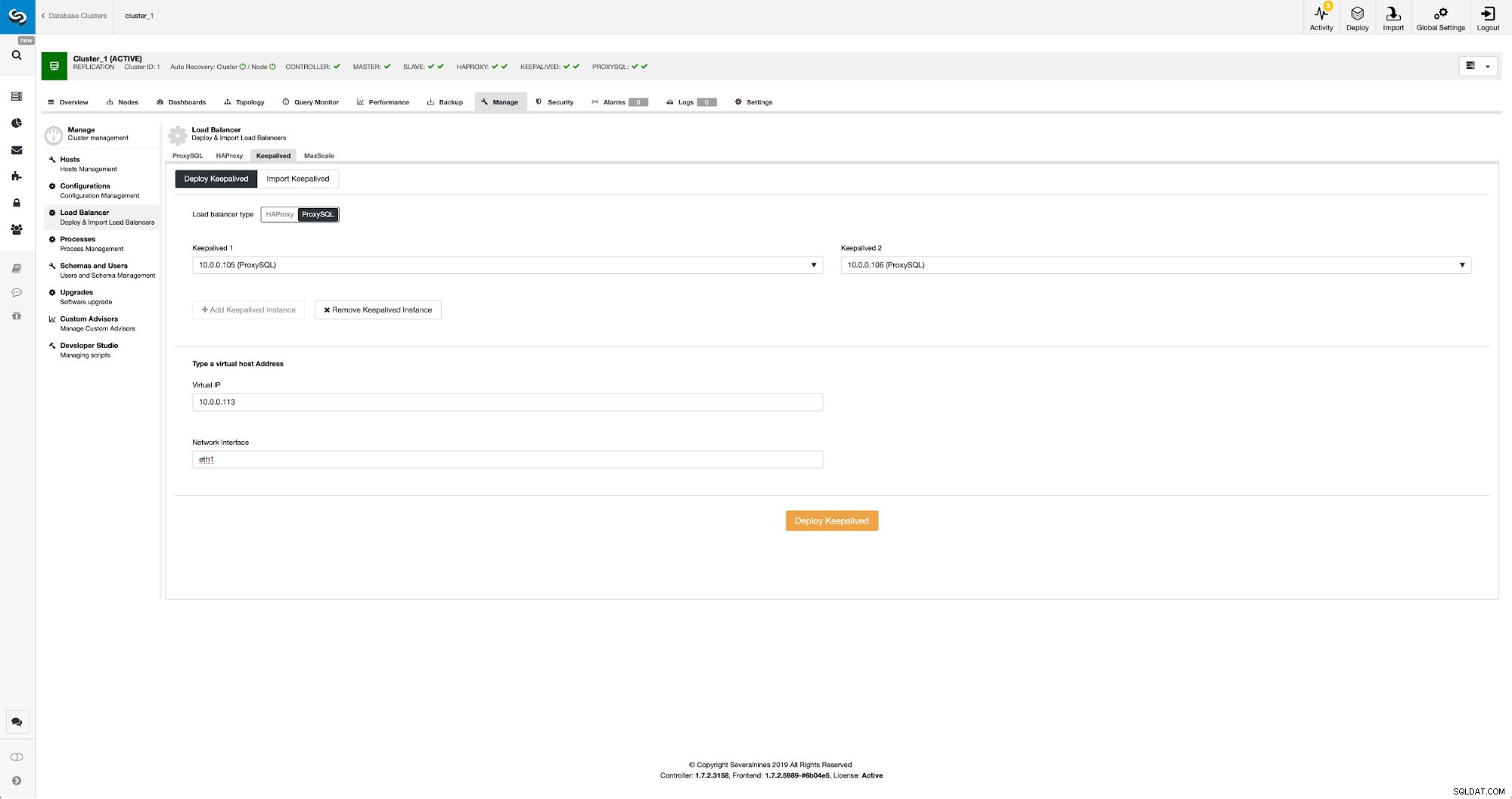 Keepalived con ProxySQL in ClusterControl
Keepalived con ProxySQL in ClusterControl Tutto quello che dovevamo fare era scegliere su quali nodi ProxySQL vogliamo che Keepalived venga distribuito, IP virtuale e interfaccia a cui sarà associato VIP. Quando la distribuzione sarà completata, passeremo il traffico alla nuova configurazione utilizzando uno dei metodi menzionati nella sezione "Passaggio del traffico alla configurazione ProxySQL" sopra.
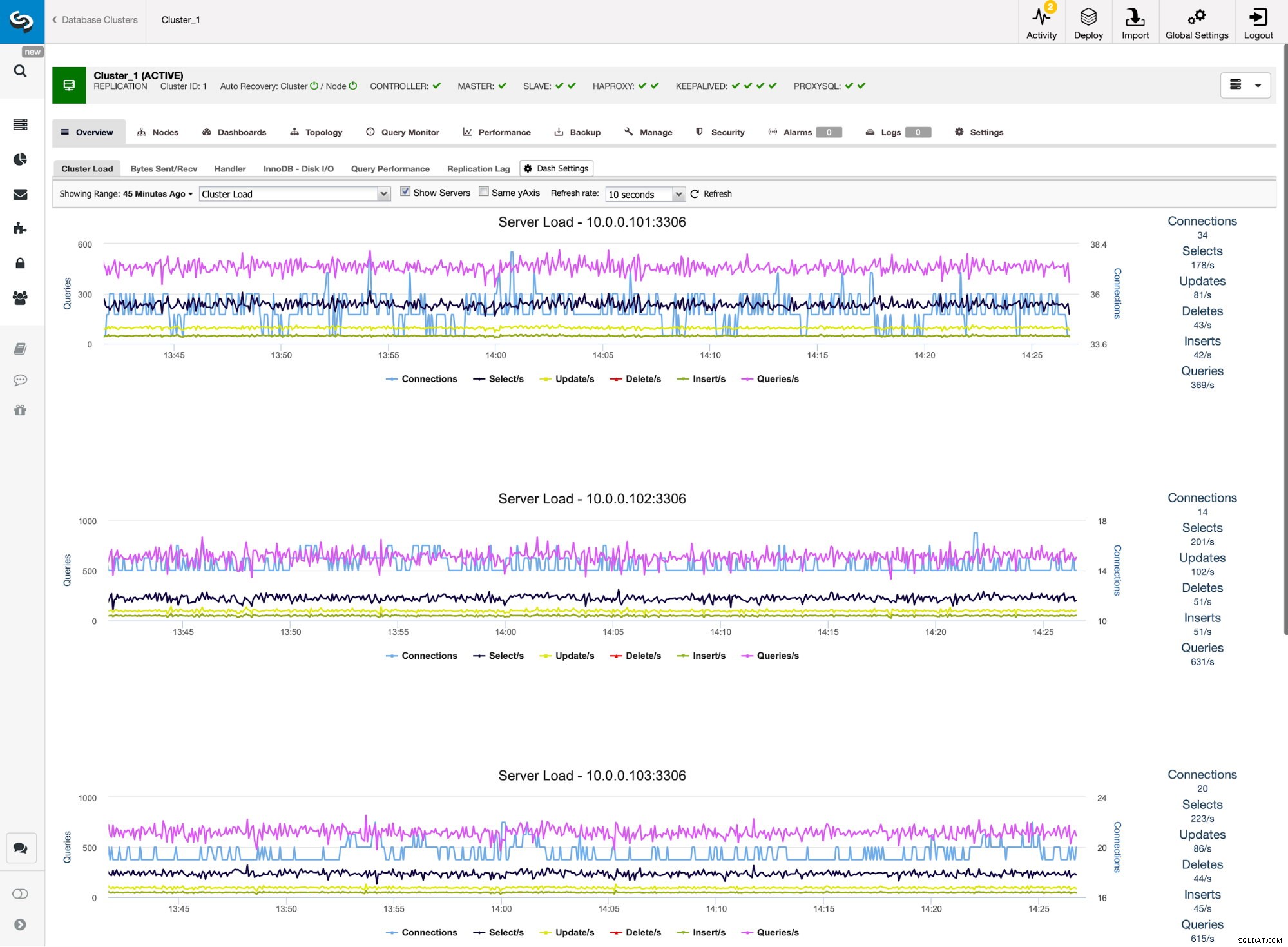
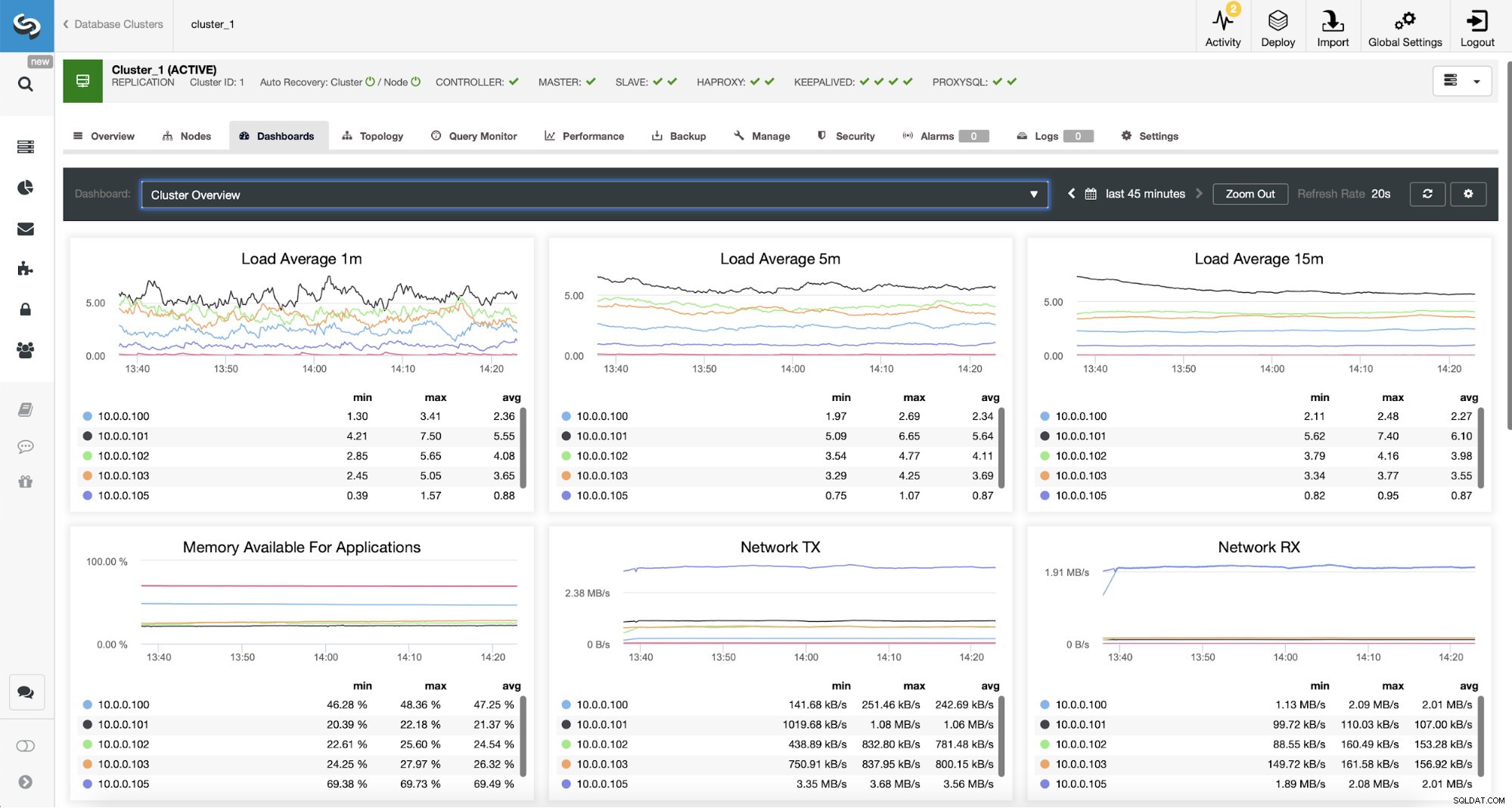 Monitoraggio del traffico ProxySQL in ClusterControl
Monitoraggio del traffico ProxySQL in ClusterControl Possiamo verificare che il traffico sia passato a ProxySQL osservando il grafico del carico:come puoi vedere, il carico è molto più distribuito tra i nodi del cluster. Puoi anche vederlo nel grafico sottostante, che mostra la distribuzione delle query nel cluster.
 Dashboard ProxySQL in ClusterControl
Dashboard ProxySQL in ClusterControl Infine, il dashboard ProxySQL mostra anche che il traffico è distribuito su tutti i nodi del cluster:
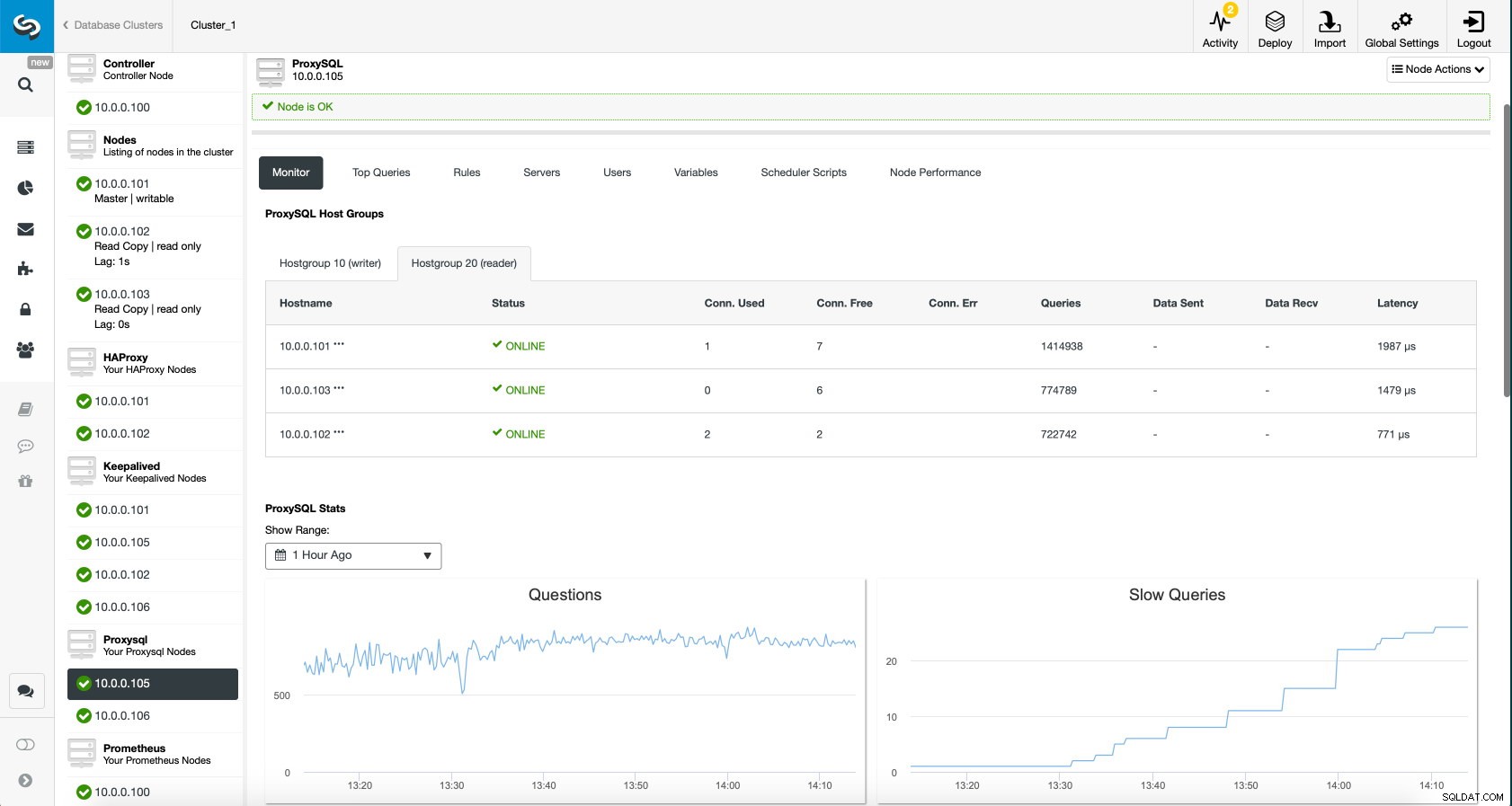 Dashboard ProxySQL in ClusterControl
Dashboard ProxySQL in ClusterControl Ci auguriamo che tu possa trarre vantaggio da questo post sul blog, come puoi vedere, con ClusterControl l'implementazione della nuova architettura richiede solo un momento e richiede solo una manciata di clic per far funzionare le cose. Facci sapere la tua esperienza in tali migrazioni.