|

Le applicazioni basate sui dati coprono un'ampia gamma di complessità, dai semplici microservizi ai sistemi basati su eventi in tempo reale con un carico significativo. Tuttavia, come dimostrerà qualsiasi team di sviluppo e/o DevOps incaricato di migliorare le prestazioni, rendere veloci le app basate sui dati a livello globale è "non banale".
Le moderne architetture applicative come JAMstack impongono la separazione dei problemi spostando i dati e i requisiti di persistenza nell'API. La separazione netta del contenuto statico, della logica aziendale e della persistenza dei dati consente di ridimensionare e gestire ciascuno in modo indipendente.
Molte aziende si concentrano anche sul disaccoppiamento delle loro applicazioni monolitiche per utilizzare i microservizi e spesso vengono implementate all'interno di ambienti serverless. Questo passaggio a un maggiore disaccoppiamento per un migliore isolamento ambientale può anche fornire una migliore agilità regionale per quanto riguarda dove viene implementata la logica aziendale e come viene ridimensionata. Le applicazioni possono ora essere distribuite a livello globale in un'unica azione CI/CD.
Il livello dati presenta tuttavia una maggiore complessità. Esistono sfide pratiche come la coerenza transazionale, l'elevata disponibilità e le prestazioni delle query sotto carico. Esistono vincoli come l'adesione alle PII e ai requisiti di conformità. E ci sono limiti insormontabili come quelli che le leggi della fisica impongono alla latenza.
Memorizzazione nella cache dell'applicazione
Molti team di sviluppo cercano di utilizzare la memorizzazione nella cache per risolvere questi problemi a livello di applicazione, supportati da livelli di persistenza come Redis o sistemi interni. Il concetto è semplice:archiviare i dati richiesti dal cliente per un periodo di tempo e se lo vediamo di nuovo, lo abbiamo pronto per soddisfare la richiesta successiva senza ricorrere al database di origine. La progettazione di una buona strategia di memorizzazione nella cache comporta una serie di sfide:quali dati memorizzare nella cache, come memorizzarli nella cache e quando. E forse ancora più importante, cosa, come e quando rimuovere i dati dalla cache. La strategia di memorizzazione nella cache deve essere ben definita, compresa e utilizzata per ogni nuovo set di funzionalità aggiunto all'applicazione, tra sviluppatori e team potenzialmente dipartimentali. Il tempo e la complessità di sviluppo sono il costo.
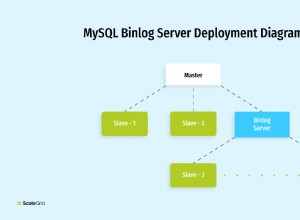
Repliche di lettura del database
In alternativa, molte aziende risolvono problemi di latenza e scalabilità con repliche di lettura del database. Le repliche di lettura sono istanze di sola lettura del database primario e vengono mantenute automaticamente sincronizzate (in modo asincrono) man mano che vengono apportati aggiornamenti al database primario. La progettazione di una solida strategia di lettura e replica è un compito arduo, pieno dei suoi costi e complessità sottili e non così sottili.
Gran parte di quella complessità può essere domata con ScaleGrid. Le repliche di lettura completamente gestite possono essere distribuite con un semplice clic da ScaleGrid (con supporto HA) in tutti i principali cloud e regioni, con il vantaggio principale che i dati vengono mantenuti automaticamente sincronizzati con il database primario.
Tuttavia, le repliche di lettura non possono sfuggire alla necessità di eseguire più server di database, forse molti più, e il relativo costo.
Un approccio diverso:PolyScale.ai Edge Cache
PolyScale è una cache edge del database che adotta un approccio diverso. La cache di PolyScale offre due vantaggi principali:latenza delle query migliorata e carico di lavoro del database ridotto. Analizziamolo un po':
Latenza regionale è risolto in modo molto simile a una CDN; PolyScale fornisce una rete perimetrale globale di punti di presenza (PoP) e archivia le risposte alle query del database vicino al client di origine, velocizzando notevolmente le risposte.
Leggi il rendimento delle query è notevolmente migliorato poiché PolyScale servirà qualsiasi richiesta di database memorizzata nella cache in <10 ms, indipendentemente dalla complessità della query. Inoltre, dato che le richieste di lettura vengono servite da PolyScale, questo carico non influisce mai sul database di origine.
Implementazione
PolyScale può essere implementato senza scrivere codice o distribuire server in pochi minuti. Aggiorna semplicemente la stringa di connessione del client del database (che si tratti di un'applicazione Web, di un microservizio o di uno strumento BI come Tableau) con il nome host di PolyScale. Il traffico del database passerà quindi attraverso la rete perimetrale ed è pronto per la memorizzazione nella cache.
Essendo compatibile con MySQL e Postgres, PolyScale è completamente trasparente per i client di database, quindi non cambia nulla con la tua attuale architettura. Nessuna migrazione, nessuna modifica alla transazionalità e nessuna modifica al tuo attuale linguaggio di query. Plug and play davvero.
Come funziona?
La rete globale di PolyScale esegue il proxy e memorizza nella cache i protocolli wire del database nativi in modo che sia trasparente per qualsiasi client di database. Le query vengono esaminate e lette (SQL SELECT ) può essere memorizzato nella cache geograficamente vicino all'origine richiedente per prestazioni accelerate. Tutto il resto del traffico (INSERT , UPDATE e DELETE ) passa senza problemi al database di origine.
L'IA di PolyScale è sulla buona strada per la piena automazione. Anziché configurare la cache secondo necessità, la piattaforma misurerà il flusso di traffico e regolerà continuamente le proprietà di memorizzazione nella cache per fornire prestazioni ottimali. Puoi leggere ulteriori informazioni sul modello di memorizzazione nella cache AI di PolyScale qui.
Conclusioni
PolyScale.ai fornisce un approccio moderno, plug and play alle prestazioni e al ridimensionamento a livello di dati. La piattaforma PolyScale è sulla strada per l'automazione completa in cui, una volta connessa, gestirà in modo intelligente la memorizzazione nella cache dei dati per prestazioni ottimali.
Dato che PolyScale è compatibile con il database corrente, non sono necessarie modifiche per ridimensionare le letture a livello globale in pochi minuti. Provalo!