Presto è un motore SQL open source distribuito in parallelo per l'elaborazione di big data. È stato sviluppato da zero da Facebook. La prima versione interna è avvenuta nel 2013 ed è stata una soluzione piuttosto rivoluzionaria per i loro problemi con i big data.
Con le centinaia di server geolocalizzati e i petabyte di dati, Facebook ha iniziato a cercare una piattaforma alternativa per i propri cluster Hadoop. Il team dell'infrastruttura desiderava ridurre il tempo necessario per eseguire processi batch di analisi e semplificare lo sviluppo della pipeline utilizzando il linguaggio di programmazione ampiamente noto nell'organizzazione:SQL.
Secondo Presto Foundation, “Facebook utilizza Presto per le query interattive su diversi archivi dati interni, incluso il loro data warehouse da 300 PB. Oltre 1.000 dipendenti di Facebook utilizzano Presto ogni giorno per eseguire più di 30.000 query che in totale scansionano oltre un petabyte ciascuna al giorno".
Sebbene Facebook abbia un ambiente di data warehouse eccezionale, le stesse sfide sono presenti in molte organizzazioni che si occupano di big data.
In questo blog, daremo un'occhiata a come configurare un ambiente presto di base utilizzando un server Docker dal file tar. Come origine dati, ci concentreremo sull'origine dati MySQL, ma potrebbe essere qualsiasi altro popolare RDBMS.
Eseguire Presto in ambiente Big Data
Prima di iniziare, diamo una rapida occhiata ai suoi principi di architettura principali. Presto è un'alternativa agli strumenti che interrogano HDFS utilizzando pipeline di processi MapReduce, come Hive. A differenza di Hive Presto non usa MapReduce. Presto viene eseguito con un motore di esecuzione di query per scopi speciali con operatori di alto livello ed elaborazione in memoria.
A differenza di Hive, Presto può eseguire lo streaming di dati attraverso tutte le fasi contemporaneamente eseguendo blocchi di dati contemporaneamente. È progettato per eseguire query analitiche ad hoc su origini dati eterogenee singole o distribuite. Può raggiungere una piattaforma Hadoop per interrogare database relazionali o altri archivi di dati come file flat.
Presto utilizza ANSI SQL standard, incluse aggregazioni, join o funzioni della finestra analitica. SQL è ben noto e molto più facile da usare rispetto a MapReduce scritto in Java.
Distribuzione di Presto su Docker
La configurazione di base di Presto può essere implementata con un'immagine Docker preconfigurata o un tarball del server Presto.
Il server Docker e i container Presto CLI possono essere facilmente distribuiti con:
docker run -d -p 127.0.0.1:8080:8080 --name presto starburstdata/presto
docker exec -it presto presto-cliÈ possibile scegliere tra due versioni del server Presto. Versione Community e versione Enterprise di Starburst. Poiché lo eseguiremo in un ambiente sandbox non di produzione, in questo articolo utilizzeremo la versione di Apache.
Prerequisiti
Presto è implementato interamente in Java e richiede l'installazione di JVM sul sistema. Funziona sia su OpenJDK che su Oracle Java. La versione minima è Java 8u151 o Java 11.
Per scaricare JAVA JDK visita https://openjdk.java.net/ o https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Puoi controllare la tua versione di Java con
$ java -version
openjdk version "1.8.0_222"
OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_222-b10)
OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.222-b10, mixed mode)Presto Installazione
Per installare Presto scaricheremo il server tar e l'eseguibile Presto CLI jar.
Il tarball conterrà una singola directory di primo livello, presto-server-0.223, che chiameremo directory di installazione.
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.223/presto-server-0.223.tar.gz
$ tar -xzvf presto-server-0.223.tar.gz
$ cd presto-server-0.223/
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.223/presto-cli-0.223-executable.jar
$ mv presto-cli-0.223-executable.jar presto
$ chmod +x prestoInoltre, Presto necessita di una directory di dati per la memorizzazione dei registri, ecc.
Si consiglia di creare una directory di dati al di fuori della directory di installazione.
$ mkdir -p ~/data/presto/Questa posizione è il luogo in cui iniziamo la nostra risoluzione dei problemi.
Configurazione di Presto
Prima di iniziare la nostra prima istanza, dobbiamo creare una serie di file di configurazione. Inizia con la creazione di una directory etc/ all'interno della directory di installazione. Questa posizione conterrà i seguenti file di configurazione:
ecc/
- Proprietà del nodo - configurazione ambientale del nodo
- Configurazione JVM (jvm.config) - Configurazione macchina virtuale Java
- Proprietà di configurazione(config.properties) - configurazione per il server Presto
- Proprietà catalogo - configurazione per connettori (sorgenti dati)
- Proprietà registro - Configurazione logger
Di seguito puoi trovare alcune configurazioni di base per eseguire Presto sandbox. Per maggiori dettagli visita la documentazione.
vi etc/config.properties
Config.properties
coordinator = true
node-scheduler.include-coordinator = true
http-server.http.port = 8080
query.max-memory = 5GB
query.max-memory-per-node = 1GB
discovery-server.enabled = true
discovery.uri = https://localhost:8080
vi etc/jvm.config
-server
-Xmx8G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
vi etc/log.properties
com.facebook.presto = INFOvi etc/node.properties
node.environment = production
node.id = ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir = /Users/bartez/data/prestoLa struttura di base etc/ potrebbe apparire come segue:

Il passaggio successivo consiste nell'impostare il connettore MySQL.
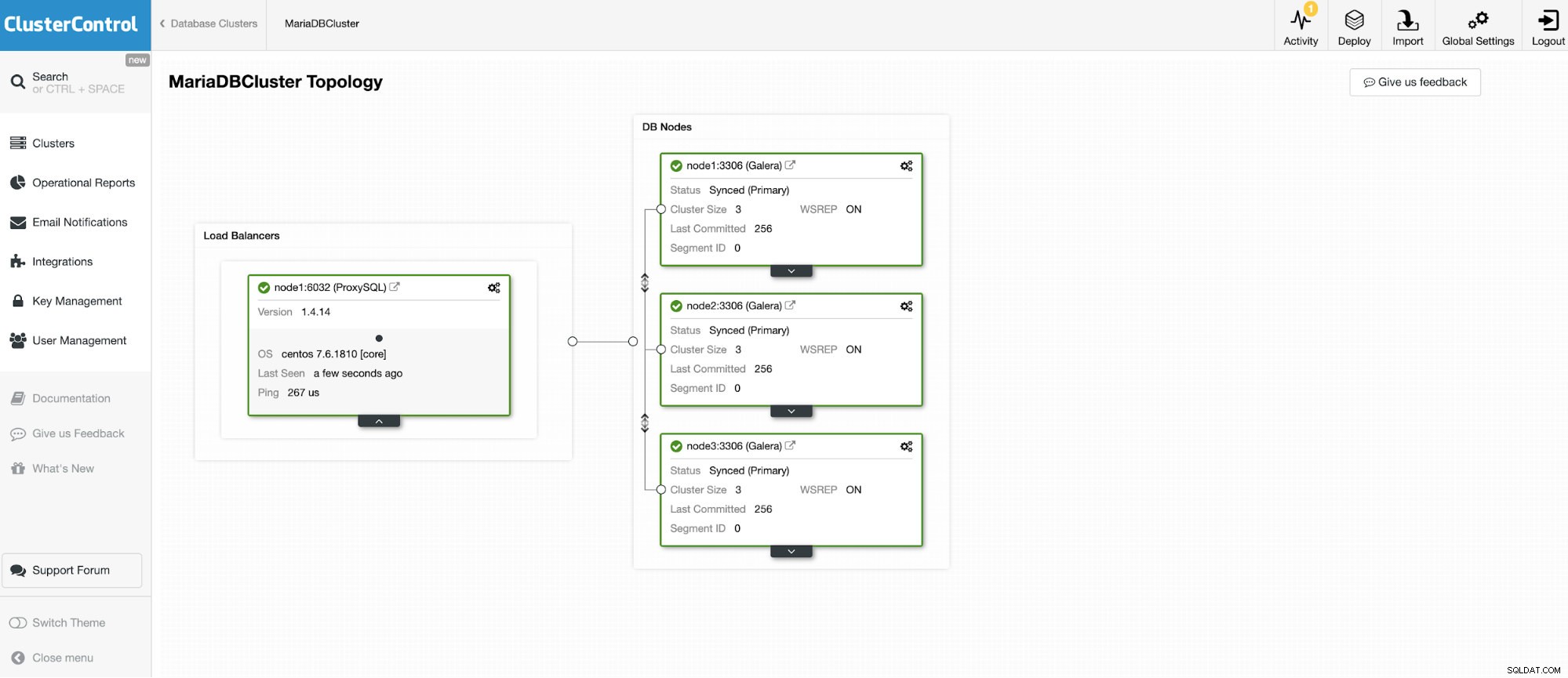
Ci collegheremo a uno dei 3 nodi MariaDB Cluster.
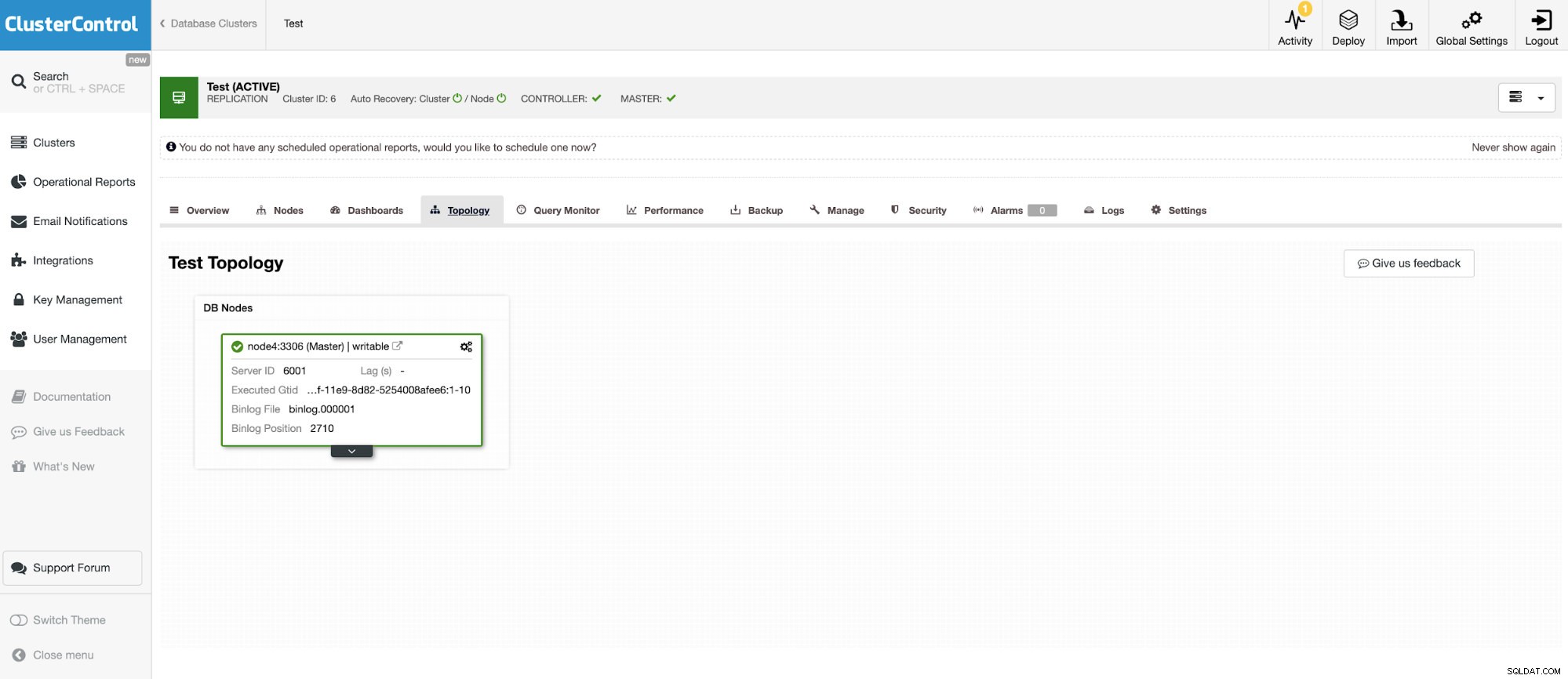
E un'altra istanza standalone che esegue Oracle MySQL 5.7.
Il connettore MySQL consente di eseguire query e creare tabelle in un database MySQL esterno. Questo può essere utilizzato per unire dati tra diversi sistemi come MariaDB e MySQL da Oracle.
Presto utilizza connettori a innesto e la configurazione è molto semplice. Per configurare il connettore MySQL, creare un file delle proprietà del catalogo in etc/catalog denominato, ad esempio, mysql.properties, per montare il connettore MySQL come catalogo mysql. Ciascuno dei file che rappresenta una connessione a un altro server. In questo caso, abbiamo due file:
vi etc/catalog/mysq.properties:
connector.name=mysql
connection-url=jdbc:mysql://node1.net:3306
connection-user=bart
connection-password=secretvi etc/catalog/mysq2.properties
connector.name=mysql
connection-url=jdbc:mysql://node4.net:3306
connection-user=bart2
connection-password=secretPresto in esecuzione
Quando tutto è impostato, è ora di avviare l'istanza Presto. Per iniziare presto, vai alla directory bin sotto l'installazione di preso ed esegui quanto segue:
$ bin/launcher start
Started as 18363Per interrompere l'esecuzione di Presto
$ bin/launcher stopOra, quando il server è attivo e funzionante, possiamo connetterci a Presto con CLI e interrogare il database MySQL.
Per avviare l'esecuzione della console Presto:
./presto --server localhost:8080 --catalog mysql --schema employeesOra possiamo interrogare i nostri database tramite CLI.
presto:mysql> select * from mysql.employees.departments;
dept_no | dept_name
---------+--------------------
d009 | Customer Service
d005 | Development
d002 | Finance
d003 | Human Resources
d001 | Marketing
d004 | Production
d006 | Quality Management
d008 | Research
d007 | Sales
(9 rows)
Query 20190730_232304_00019_uq3iu, FINISHED, 1 node
Splits: 17 total, 17 done (100,00%)
0:00 [9 rows, 0B] [81 rows/s, 0B/s]
Entrambi i database MariaDB cluster e MySQL sono stati alimentati con il database dei dipendenti.
wget https://github.com/datacharmer/test_db/archive/master.zip
mysql -uroot -psecret < employees.sqlLo stato della query è visibile anche nella console Web Presto:https://localhost:8080/ui/#
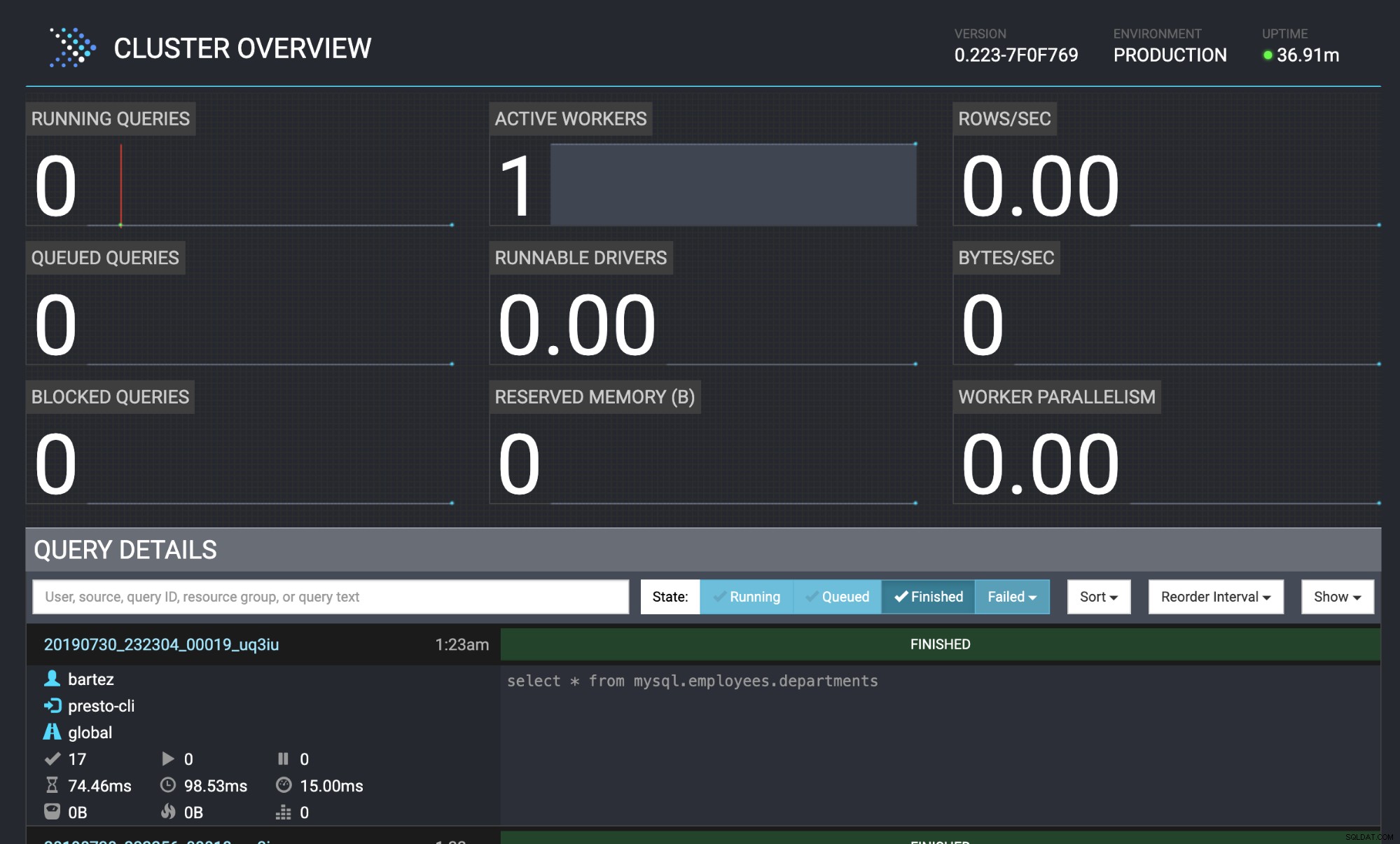 Panoramica del cluster Presto
Panoramica del cluster Presto Conclusione
Molte aziende famose (come Airbnb, Netflix, Twitter) stanno adottando Presto per prestazioni a bassa latenza. È senza dubbio un software molto interessante che potrebbe eliminare la necessità di eseguire pesanti processi di data warehouse ETL. In questo blog abbiamo appena dato una breve occhiata al connettore MySQL, ma puoi usarlo per analizzare i dati da HDFS, Object Store, RDBMS (SQL Server, Oracle, PostgreSQL), Kafka, Cassandra, MongoDB e molti altri.