È presente un bug di regressione in SQL Server 2012 e SQL Server 2014 in cui, se si ricostruisce un indice online in parallelo e si verifica anche un errore irreversibile come un timeout di blocco, è possibile che si verifichi perdita o danneggiamento dei dati . Questo dovrebbe essere uno scenario relativamente raro (Phil Brammer ha una riproduzione semplice in Connect #795134), ma la perdita di dati è una perdita di dati e non sono disposto a scommettere. La correzione è descritta in KB #2969896:FIX:la perdita di dati nell'indice cluster si verifica quando si esegue l'indice di compilazione online in SQL Server 2012.
Non tutti devono preoccuparsi di questo problema. Se non stai eseguendo Enterprise (o una versione equivalente), non puoi eseguire ricostruzioni parallele o online in primo luogo (e probabilmente ci sono alcune persone su Enterprise che non ricostruiscono o non ricostruiscono online). Se hai MAXDOP a livello di istanza impostato su 1, non possono andare in parallelo a meno che non lo si sovrascriva a livello di istruzione. Ma se sei nel 2012 o 2014, stai eseguendo un'edizione adeguata e le tue ricostruzioni online potrebbero andare parallele, sei vulnerabile a questo problema.
Come accennato in precedenza, questo problema potrebbe manifestarsi in SQL Server 2012 RTM, Service Pack 1 e persino Service Pack 2, che è stato rilasciato il 10 giugno. Il bug non è stato corretto fino a molto tempo dopo il blocco del codice SP2, quindi SP2 lo fa non includere questa correzione o nessuna delle correzioni da SP1 CU n. 10 o n. 11. Ho bloggato su questo qui. Il ramo RTM è ufficialmente fuori supporto, quindi non vedrai una correzione lì. Il problema può verificarsi anche in SQL Server 2014.
Sono ora disponibili aggiornamenti cumulativi per SQL Server 2012 Service Pack 1 e 2 e SQL Server 2014. Un rapido riepilogo delle opzioni che consiglio:
Se il tuo ramo / @@VERSION è...
| ...dovresti... | ||||
|---|---|---|---|---|---|
| |||||
| |||||
| Non fare nulla; hai già la correzione. | |||||
| |||||
| Non fare nulla; hai già la correzione. | |||||
| SQL Server 2014 RTM |
| ||||
| Non fare nulla; hai già la correzione. | |||||
| * Se installi l'hotfix SP1 o l'aggiornamento cumulativo n. 11 e quindi installi SP2, annullerai tali modifiche, incluse questa correzione. | |||||
Soluzioni per l'hotfix/CU avverso
Poiché tutte le filiali interessate (eccetto 2012 RTM) hanno un hotfix su richiesta e/o un aggiornamento cumulativo che risolve il problema, la risposta più semplice è semplicemente installare l'aggiornamento pertinente. Tuttavia, potresti trovarti in uno scenario in cui la tua politica aziendale o i cicli di test ti impediscono di distribuire questi aggiornamenti rapidamente, o forse mai. Allora, quali altre opzioni hai?
- Puoi interrompere l'esecuzione delle ricostruzioni fino a quando non sarà disponibile un nuovo service pack per la tua filiale (forse puoi semplicemente continuare con
REORGANIZEper adesso). Sfortunatamente, se fai parte di un'azienda "solo service pack", le tue opzioni sono molto limitate:puoi lottare più duramente per modificare tale criterio, oppure puoi aspettare SQL Server 2012 Service Pack 3 (che potrebbe richiedere molto tempo o potrebbe semplicemente non arrivano mai – vedi la FAQ n. 21 qui) o SQL Server 2014 Service Pack 1 (che probabilmente non vedremo prima dell'arrivo del 2015). - Puoi impostare il
max degree of parallelisma livello di istanza a 1, tuttavia ciò potrebbe avere un effetto negativo sul resto del carico di lavoro:pensa a cose come DBCC multi-thread, query parallele su o tra tabelle partizionate e altre operazioni in cui potresti voler ridurre il parallelismo ma non eliminarlo del tutto. Inoltre, questa impostazione non influirà su una ricostruzione online con, ad esempio, un esplicitoMAXDOP = 8codificato nel comando, in quanto sovrascriveràsp_configureimpostazione.
- Puoi aggiungere il
WITH (MAXDOP = 1)opzione manualmente a tutti i comandi di ricostruzione. (Nota:non è necessario farlo per gli indici XML, poiché intrinsecamente vengono eseguiti a thread singolo, ma lo applicherei semplicemente a tutte le ricostruzioni per coerenza ed evitare qualsiasi logica condizionale non necessaria.)
- Puoi impostare i tuoi lavori di manutenzione dell'indice in modo che vengano eseguiti come un accesso specifico, quindi utilizzare Resource Governor per creare un gruppo di carico di lavoro che limiti il
MAX_DOPdi quell'accesso a 1, indipendentemente da ciò che stanno facendo. Ne ho un esempio nel white paper del 2008 che ho scritto con Boris Baryshnikov, Using the Resource Governor, nella sezione intitolata "Limiting Parallelism for Intensive Background Jobs".
- Se stai utilizzando la soluzione di manutenzione dell'indice di Ola Hallengren, puoi aggiungere il
@MaxDopparametro alle tue chiamate adbo.IndexOptimize:
EXEC dbo.IndexOptimize /* other parameters */ @MaxDop = 1; - Se utilizzi SQL Sentry Fragmentation Manager, puoi dettare il livello di
MAXDOPda utilizzare in Impostazioni - e puoi farlo a livello aziendale, per istanza, per database o anche per singolo indice (in questo caso, probabilmente vorresti impostarlo per istanza, per tutte le istanze senza una correzione disponibile):
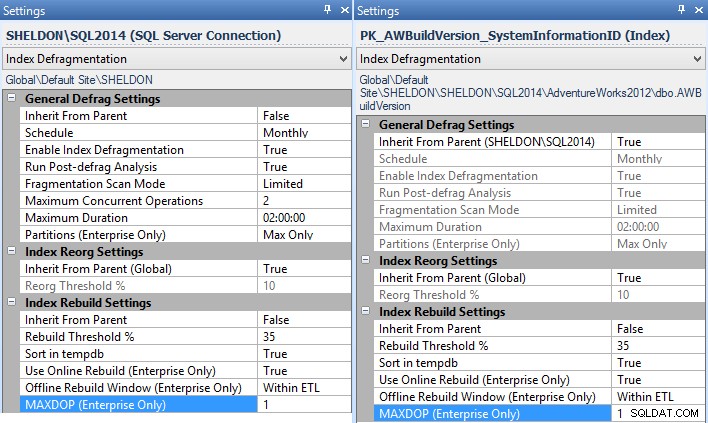
Impostazioni di gestione della frammentazione per l'istanza (a sinistra) e un indice individuale (a destra). - Se stai utilizzando i piani di manutenzione per le ricostruzioni degli indici, dovrai modificarli per utilizzare Esegui attività istruzioni T-SQL e scrivere il tuo
ALTER INDEX ... WITH (ONLINE = ON, MAXDOP = 1);comandi manualmente (quindi potrebbe anche passare a una soluzione automatizzata). Vedi, l'attività di ricostruzione dell'indice non ha una proprietà esposta perMAXDOP, anche se più volte richiesto (l'ultima nel 2012, da Alberto Morillo, e nel lontano 2006, da Linchi Shea). E guarda tutte queste altre utili proprietà che espongono, comeAdvSortInTempdb,ObjectTypeSelectioneTaskAllowesDatbaseSelection[sic!]:
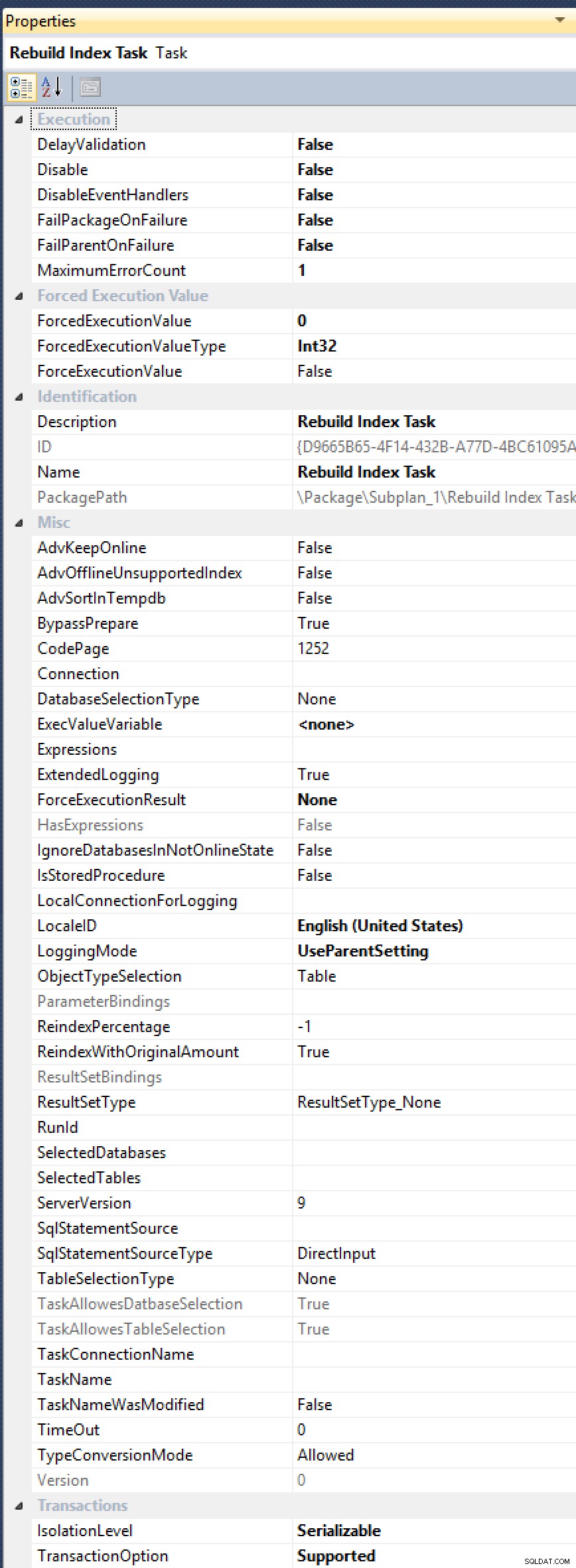
Tutte queste opzioni, ma ancora nessuna cura per MAXDOP.