La durabilità ritardata è una funzionalità recente ma interessante in SQL Server 2014; l'elevato livello dell'elevatore della funzione è, molto semplicemente:
- "Scambia durata con prestazioni."
Prima un po' di sfondo. Per impostazione predefinita, SQL Server utilizza un registro write-ahead (WAL), il che significa che le modifiche vengono scritte nel registro prima che sia consentito il commit. Nei sistemi in cui le scritture dei log delle transazioni diventano il collo di bottiglia e dove esiste una moderata tolleranza alla perdita di dati , ora hai la possibilità di sospendere temporaneamente il requisito per attendere lo svuotamento del registro e la conferma. Questo succede letteralmente per eliminare la D da ACID, almeno per una piccola porzione di dati (ne parleremo più avanti).
In un certo senso fai già questo sacrificio ora. Nella modalità di ripristino completo, c'è sempre un certo rischio di perdita di dati, è solo misurato in termini di tempo piuttosto che di dimensioni. Ad esempio, se esegui il backup del registro delle transazioni ogni cinque minuti, potresti perdere fino a poco meno di 5 minuti di dati se si verificasse qualcosa di catastrofico. Non sto parlando di un semplice failover qui, ma diciamo che il server prende letteralmente fuoco o che qualcuno inciampa nel cavo di alimentazione:il database potrebbe benissimo essere irrecuperabile e potrebbe essere necessario tornare al punto nel tempo dell'ultimo backup del registro . E questo presuppone anche che tu stia testando i tuoi backup ripristinandoli da qualche parte:in caso di un errore critico potresti non avere il punto di ripristino che pensi di avere. Tendiamo a non pensare a questo scenario, ovviamente, perché non ci aspettiamo mai cose cattive™ accada.
Come funziona
La durabilità ritardata consente alle transazioni di scrittura di continuare a essere eseguite come se il registro fosse stato scaricato su disco; in realtà le scritture su disco sono state raggruppate e differite, per essere gestite in background. La transazione è ottimista; presuppone che lo svuotamento del registro sarà accadere. Il sistema utilizza un blocco di log di 60 KB e tenta di svuotare il registro su disco quando questo blocco di 60 KB è pieno (al più tardi - può e spesso accadrà prima). È possibile impostare questa opzione a livello di database, a livello di singola transazione o, nel caso di procedure compilate in modo nativo in OLTP In-Memory, a livello di procedura. L'impostazione del database vince in caso di conflitto; ad esempio, se il database è impostato su disabilitato, il tentativo di eseguire il commit di una transazione utilizzando l'opzione ritardata verrà semplicemente ignorato, senza alcun messaggio di errore. Inoltre, alcune transazioni sono sempre completamente durevoli, indipendentemente dalle impostazioni del database o dalle impostazioni di commit; ad esempio, transazioni di sistema, transazioni tra database e operazioni che coinvolgono FileTable, rilevamento delle modifiche, acquisizione dei dati delle modifiche e replica.
A livello di database, puoi utilizzare:
ALTER DATABASE dbname SET DELAYED_DURABILITY = DISABLED | ALLOWED | FORCED;
Se lo imposti su ALLOWED , ciò significa che qualsiasi singola transazione può utilizzare la Durabilità Ritardata; FORCED significa che tutte le transazioni che possono utilizzare la Durabilità Ritardata lo faranno (le eccezioni di cui sopra sono ancora rilevanti in questo caso). Probabilmente vorrai usare ALLOWED anziché FORCED – ma quest'ultimo può essere utile nel caso di un'applicazione esistente in cui si desidera utilizzare questa opzione in tutto e anche ridurre al minimo la quantità di codice che deve essere toccato. Una cosa importante da notare su ALLOWED è che le transazioni completamente durevoli potrebbero dover attendere più a lungo, poiché forzeranno prima lo svuotamento di tutte le transazioni durevoli ritardate.
A livello di transazione, puoi dire:
COMMIT TRANSACTION WITH (DELAYED_DURABILITY = ON);
E in una procedura OLTP in memoria compilata in modo nativo, puoi aggiungere la seguente opzione a BEGIN ATOMIC blocco:
BEGIN ATOMIC WITH (DELAYED_DURABILITY = ON, ...)
Una domanda comune riguarda ciò che accade con la semantica di blocco e isolamento. Non cambia nulla, davvero. Il blocco e il blocco continuano a verificarsi e le transazioni vengono eseguite allo stesso modo e con le stesse regole. L'unica differenza è che, consentendo l'esecuzione del commit senza attendere che il log venga scaricato sul disco, tutti i blocchi correlati vengono rilasciati molto prima.
Quando dovresti usarlo
Oltre al vantaggio che si ottiene consentendo alle transazioni di procedere senza attendere che avvenga la scrittura del registro, si ottengono anche meno scritture del registro di dimensioni maggiori. Questo può funzionare molto bene se il tuo sistema ha un'alta percentuale di transazioni che sono effettivamente inferiori a 60 KB, e in particolare quando il disco di registro è lento (anche se ho riscontrato vantaggi simili su SSD e HDD tradizionale). Non funziona così bene se le tue transazioni sono, per la maggior parte, superiori a 60 KB, se sono in genere di lunga durata o se hai un throughput elevato e un'elevata concorrenza. Quello che può succedere qui è che puoi riempire l'intero buffer di log prima che il flush finisca, il che significa semplicemente trasferire le tue attese a una risorsa diversa e, in definitiva, non migliorare le prestazioni percepite dagli utenti dell'applicazione.
In altre parole, se il registro delle transazioni non è attualmente un collo di bottiglia, non attivare questa funzione. Come puoi sapere se il tuo registro delle transazioni è attualmente un collo di bottiglia? Il primo indicatore sarebbe WRITELOG alto attende, in particolare se accoppiato con PAGEIOLATCH_** . Paul Randal (@PaulRandal) ha un'ottima serie in quattro parti sull'identificazione dei problemi del registro delle transazioni e sulla configurazione per prestazioni ottimali:
- Ridurre il grasso del registro delle transazioni
- Ridurre più grasso del registro delle transazioni
- Problemi di configurazione del registro delle transazioni
- Monitoraggio del registro delle transazioni
Vedi anche questo post sul blog di Kimberly Tripp (@KimberlyLTripp), 8 passaggi per migliorare il throughput dei log delle transazioni e il post sul blog del team di SQL CAT, Diagnosi dei problemi di prestazioni dei log delle transazioni e dei limiti di Log Manager.
Questa indagine potrebbe portarti alla conclusione che vale la pena esaminare la durabilità ritardata; non può. Testare il tuo carico di lavoro sarà il modo più affidabile per saperlo con certezza. Come molte altre aggiunte nelle versioni recenti di SQL Server (*cough* Hekaton ), questa funzione NON è progettata per migliorare ogni singolo carico di lavoro e, come notato sopra, può effettivamente peggiorare alcuni carichi di lavoro. Leggi questo post del blog di Simon Harvey per alcune altre domande che dovresti porti sul tuo carico di lavoro per determinare se è possibile sacrificare una certa durata per ottenere prestazioni migliori.
Potenziale di perdita di dati
Lo menzionerò più volte e aggiungerò enfasi ogni volta che lo faccio:Devi essere tollerante alla perdita di dati . Con un disco dalle buone prestazioni, il massimo che dovresti aspettarti di perdere in una catastrofe, o anche in un arresto pianificato e regolare, è fino a un blocco completo (60 KB). Tuttavia, nel caso in cui il tuo sottosistema I/O non riesca a tenere il passo, è possibile che tu possa perdere tanto quanto l'intero buffer di registro (~7 MB).
Per chiarire, dalla documentazione (sottolineatura mia):
Per la durabilità ritardata, non c'è differenza tra un arresto imprevisto e un arresto/riavvio previsto di SQL Server . Come gli eventi catastrofici, dovresti pianificare la perdita di dati . In un arresto/riavvio pianificato, alcune transazioni che non sono state scritte su disco potrebbero essere prima salvate su disco, ma non dovresti pianificarlo. Pianifica come se un arresto/riavvio, pianificato o non pianificato, perda i dati come un evento catastrofico.Quindi è molto importante soppesare il rischio di perdita di dati con la necessità di alleviare i problemi di prestazioni del registro delle transazioni. Se gestisci una banca o qualsiasi altra cosa che si occupa di denaro, potrebbe essere molto più sicuro e appropriato per te spostare il tuo registro su un disco più veloce che tirare i dadi usando questa funzione. Se stai cercando di migliorare il tempo di risposta nella tua applicazione Web Gamerz Chat Room, forse il rischio è meno grave.
È possibile controllare questo comportamento in una certa misura per ridurre al minimo il rischio di perdita di dati. Puoi forzare lo scaricamento su disco di tutte le transazioni durevoli ritardate in uno dei due modi seguenti:
- Impegna qualsiasi transazione completamente durevole.
- Chiama
sys.sp_flush_logmanualmente.
Ciò consente di tornare al controllo della perdita di dati in termini di tempo, piuttosto che di dimensioni; potresti programmare il lavaggio ogni 5 secondi, per esempio. Ma vorrai trovare il tuo punto debole qui; risciacquare troppo spesso può compensare il vantaggio di Durabilità ritardata in primo luogo. In ogni caso, dovrai comunque essere tollerante alla perdita di dati , anche se vale solo
Penseresti che CHECKPOINT potrebbe essere d'aiuto in questo caso, ma questa operazione in realtà non garantisce tecnicamente che il registro verrà scaricato su disco.
Interazione con HA/DR
Potresti chiederti come funziona la durata ritardata con le funzionalità HA/DR come il log shipping, la replica e i gruppi di disponibilità. Con la maggior parte di questi funziona invariato. Il log shipping e la replica riprodurranno i record di log che sono stati rafforzati, quindi esiste lo stesso potenziale di perdita di dati lì. Con gli AG in modalità asincrona, non stiamo comunque aspettando il riconoscimento secondario, quindi si comporterà come oggi. Con synchronous, tuttavia, non è possibile eseguire il commit sul primary fino a quando la transazione non viene eseguita e rafforzata nel registro remoto. Anche in questo scenario potremmo avere qualche vantaggio a livello locale non dovendo attendere la scrittura del log locale, dobbiamo comunque attendere l'attività remota. Quindi in quello scenario c'è meno beneficio e potenzialmente nessuno; tranne forse nel raro scenario in cui il disco di registro del primario è molto lento e il disco di registro del secondario è molto veloce. Sospetto che le stesse condizioni valgano per il mirroring sincronizzato/asincrono, ma non otterrai alcun impegno ufficiale da parte mia su come funziona una nuova brillante funzionalità con una deprecata. :-)
Osservazioni sulle prestazioni
Questo non sarebbe un gran post qui se non mostrassi alcune osservazioni sulle prestazioni effettive. Ho impostato 8 database per testare gli effetti di due diversi modelli di carico di lavoro con i seguenti attributi:
- Modello di ripristino:semplice o completo
- Posizione registro:SSD e HDD
- Durata:ritardata o completamente durevole
Sono davvero, davvero, davvero pigro efficiente su questo genere di cose. Poiché voglio evitare di ripetere le stesse operazioni all'interno di ogni database, ho creato temporaneamente la seguente tabella in model :
USE model; GO CREATE TABLE dbo.TheTable ( TheID INT IDENTITY(1,1) PRIMARY KEY, TheDate DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP, RowGuid UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID() );
Quindi ho creato una serie di comandi SQL dinamici per creare questi 8 database, piuttosto che creare i database singolarmente e quindi modificare le impostazioni:
-- C and D are SSD, G is HDD
DECLARE @sql NVARCHAR(MAX) = N'';
;WITH l AS (SELECT l FROM (VALUES('D'),('G')) AS l(l)),
r AS (SELECT r FROM (VALUES('FULL'),('SIMPLE')) AS r(r)),
d AS (SELECT d FROM (VALUES('FORCED'),('DISABLED')) AS d(d)),
x AS (SELECT l.l, r.r, d.d, n = CONVERT(CHAR(1),ROW_NUMBER() OVER
(ORDER BY d.d DESC, l.l)) FROM l CROSS JOIN r CROSS JOIN d)
SELECT @sql += N'
CREATE DATABASE dd' + n + ' ON '
+ '(name = ''dd' + n + '_data'','
+ ' filename = ''C:\SQLData\dd' + n + '.mdf'', size = 1024MB)
LOG ON (name = ''dd' + n + '_log'','
+ ' filename = ''' + l + ':\SQLLog\dd' + n + '.ldf'', size = 1024MB);
ALTER DATABASE dd' + n + ' SET RECOVERY ' + r + ';
ALTER DATABASE dd' + n + ' SET DELAYED_DURABILITY = ' + d + ';'
FROM x ORDER BY d, l;
PRINT @sql;
-- EXEC sp_executesql @sql;
Sentiti libero di eseguire tu stesso questo codice (con il EXEC ancora commentato) per vedere che ciò creerebbe 4 database con durata ritardata OFF (due in ripristino COMPLETO, due in SEMPLICE, uno di ciascuno con accesso su disco lento e uno di ciascuno con accesso su SSD). Ripeti questo schema per 4 database con Durabilità ritardata FORZATA:l'ho fatto per semplificare il codice nel test, piuttosto che per riflettere ciò che farei nella vita reale (dove probabilmente vorrei trattare alcune transazioni come critiche e altre come, beh, meno che critico).
Per il controllo di integrità, ho eseguito la seguente query per assicurarmi che i database avessero la giusta matrice di attributi:
SELECT d.name, d.recovery_model_desc, d.delayed_durability_desc, log_disk = CASE WHEN mf.physical_name LIKE N'D%' THEN 'SSD' else 'HDD' END FROM sys.databases AS d INNER JOIN sys.master_files AS mf ON d.database_id = mf.database_id WHERE d.name LIKE N'dd[1-8]' AND mf.[type] = 1; -- log
Risultati:
| nome | modello_di_recupero | durata_ritardata | log_disk |
|---|---|---|---|
| dd1 | COMPLETO | FORZATO | SSD |
| dd2 | SEMPLICE | FORZATO | SSD |
| dd3 | COMPLETO | FORZATO | HDD |
| dd4 | SEMPLICE | FORZATO | HDD |
| dd5 | COMPLETO | DISABILITATO | SSD |
| dd6 | SEMPLICE | DISABILITATO | SSD |
| dd7 | COMPLETO | DISABILITATO | HDD |
| dd8 | SEMPLICE | DISABILITATO | HDD |
Configurazione pertinente degli 8 database di test
Ho anche eseguito il test in modo pulito più volte per garantire che un file di dati da 1 GB e un file di registro da 1 GB fossero sufficienti per eseguire l'intero set di carichi di lavoro senza introdurre eventi di crescita automatica nell'equazione. Come best practice, faccio regolarmente il possibile per garantire che i sistemi dei clienti dispongano di spazio allocato sufficiente (e avvisi adeguati integrati) in modo tale che nessun evento di crescita si verifichi mai in un momento imprevisto. So che nel mondo reale questo non accade sempre, ma è l'ideale.
Ho impostato il sistema per essere monitorato con SQL Sentry:questo mi avrebbe consentito di mostrare facilmente la maggior parte delle metriche delle prestazioni che volevo evidenziare. Ma ho anche creato una tabella temporanea per memorizzare le metriche batch, inclusa la durata e un output molto specifico da sys.dm_io_virtual_file_stats:
SELECT test = 1, cycle = 1, start_time = GETDATE(), *
INTO #Metrics
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2) WHERE 1 = 0; Ciò mi consentirebbe di registrare l'ora di inizio e di fine di ogni singolo batch e di misurare i delta nel DMV tra l'ora di inizio e l'ora di fine (affidabile solo in questo caso perché so di essere l'unico utente del sistema).
Tante piccole transazioni
Il primo test che volevo eseguire riguardava molte piccole transazioni. Per ogni database, volevo ottenere 500.000 lotti separati di un singolo inserto ciascuno:
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
Ricorda, cerco di essere pigro efficiente su questo genere di cose. Quindi, per generare il codice per tutti gli 8 database, ho eseguito questo:
;WITH x AS
(
SELECT TOP (8) number FROM master..spt_values
WHERE type = N'P' ORDER BY number
)
SELECT CONVERT(NVARCHAR(MAX), N'') + N'
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x;
Ho eseguito questo test e poi ho esaminato #Metrics tabella con la seguente query:
SELECT
[database] = db_name(m1.database_id),
num_writes = m2.num_of_writes - m1.num_of_writes,
write_bytes = m2.num_of_bytes_written - m1.num_of_bytes_written,
bytes_per_write = (m2.num_of_bytes_written - m1.num_of_bytes_written)*1.0
/(m2.num_of_writes - m1.num_of_writes),
io_stall_ms = m2.io_stall_write_ms - m1.io_stall_write_ms,
m1.start_time,
end_time = m2.start_time,
duration = DATEDIFF(SECOND, m1.start_time, m2.start_time)
FROM #Metrics AS m1
INNER JOIN #Metrics AS m2
ON m1.database_id = m2.database_id
WHERE m1.cycle = 1 AND m2.cycle = 2
AND m1.test = 1 AND m2.test = 1; Ciò ha prodotto i seguenti risultati (e ho confermato attraverso più test che i risultati erano coerenti):
| database | scrive | byte | byte/scrittura | io_stall_ms | ora_di_inizio | end_time | durata (secondi) |
|---|---|---|---|---|---|---|---|
| dd1 | 8.068 | 261.894.656 | 32.460,91 | 6.232 | 26-04-2014 17:20:00 | 26-04-2014 17:21:08 | 68 |
| dd2 | 8.072 | 261.682.688 | 32.418,56 | 2.740 | 26-04-2014 17:21:08 | 26-04-2014 17:22:16 | 68 |
| dd3 | 8.246 | 262.254.592 | 31.803,85 | 3.996 | 26-04-2014 17:22:16 | 26-04-2014 17:23:24 | 68 |
| dd4 | 8.055 | 261.688.320 | 32.487,68 | 4.231 | 26-04-2014 17:23:24 | 26-04-2014 17:24:32 | 68 |
| dd5 | 500.012 | 526.448.640 | 1.052,87 | 35.593 | 26-04-2014 17:24:32 | 26-04-2014 17:26:32 | 120 |
| dd6 | 500.014 | 525.870.080 | 1.051,71 | 35.435 | 26-04-2014 17:26:32 | 26-04-2014 17:28:31 | 119 |
| dd7 | 500.015 | 526.120.448 | 1.052,20 | 50.857 | 26-04-2014 17:28:31 | 26-04-2014 17:30:45 | 134 |
| dd8 | 500.017 | 525.886.976 | 1.051,73 | 49.680 | 133 |
Piccole transazioni:durata e risultati da sys.dm_io_virtual_file_stats
Sicuramente alcune osservazioni interessanti qui:
- Il numero di singole operazioni di scrittura era molto piccolo per i database Delayed Durability (~60 volte per quelli tradizionali).
- Il numero totale di byte scritti è stato dimezzato utilizzando la durata ritardata (presumo perché tutte le scritture nel caso tradizionale contenevano molto spazio sprecato).
- Il numero di byte per scrittura era molto più alto per la durata ritardata. Ciò non è stato eccessivamente sorprendente, dal momento che l'intero scopo della funzione è raggruppare le scritture in batch più grandi.
- La durata totale degli stalli di I/O era volatile, ma all'incirca un ordine di grandezza inferiore per la Durabilità ritardata. Gli stalli in transazioni completamente durevoli erano molto più sensibili al tipo di disco.
- Se qualcosa non ti ha convinto finora, la colonna della durata è molto eloquente. I lotti completamente durevoli che richiedono due minuti o più vengono tagliati quasi a metà.
Le colonne dell'ora di inizio/fine mi hanno permesso di concentrarmi sulla dashboard di Performance Advisor per il periodo preciso in cui si stavano verificando queste transazioni, dove possiamo disegnare molti indicatori visivi aggiuntivi:
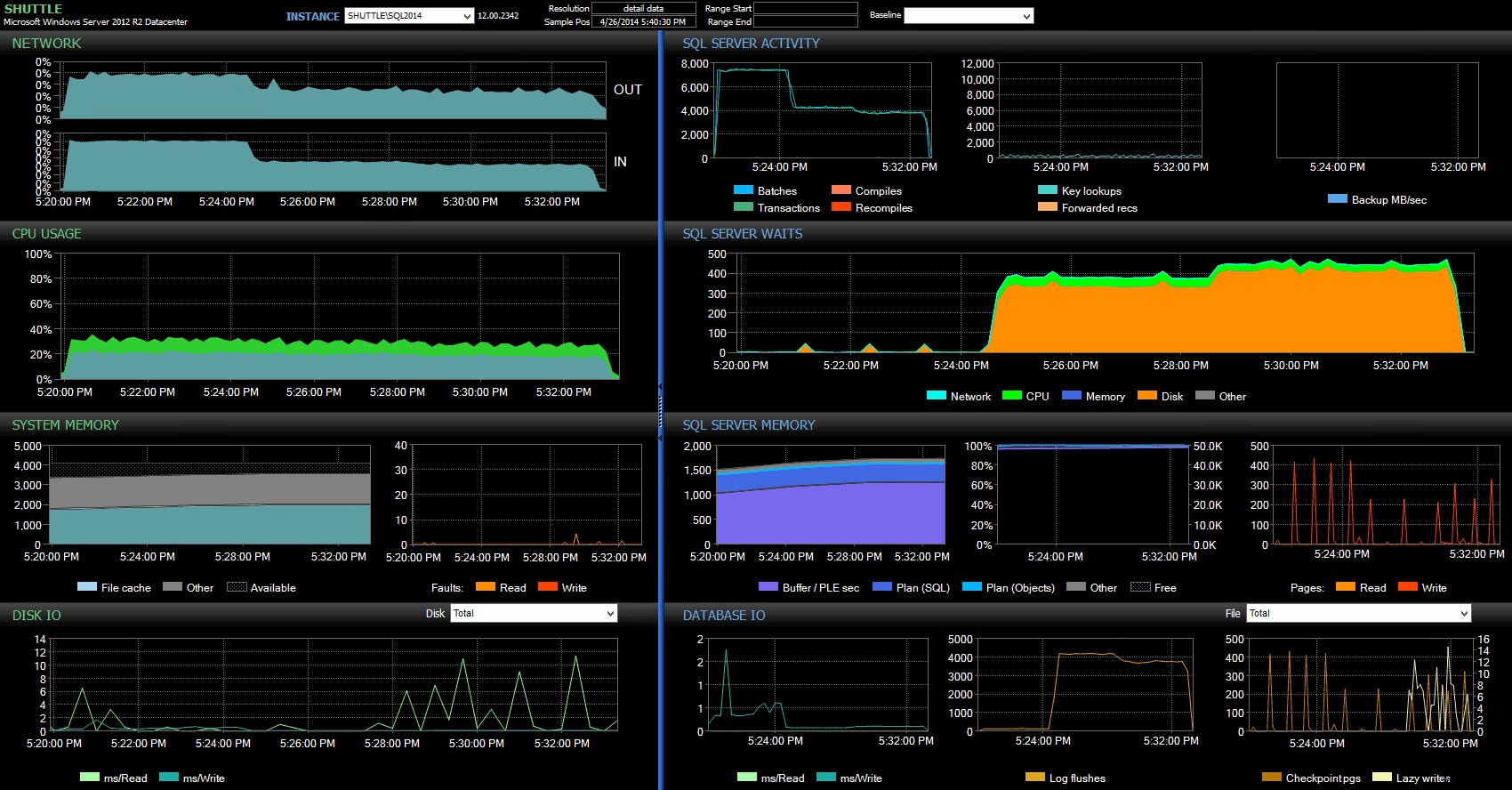
Dashboard di SQL Sentry:fai clic per ingrandire
Ulteriori osservazioni qui:
- Su diversi grafici, puoi vedere chiaramente quando è subentrata la parte di durata non ritardata del batch (~17:24:32).
- Non vi è alcun impatto osservabile sulla CPU o sulla memoria quando si utilizza la Durabilità ritardata.
- Puoi notare un enorme impatto su batch/transazioni al secondo nel primo grafico in Attività di SQL Server.
- Le attese di SQL Server sono alle stelle quando sono iniziate le transazioni completamente durevoli. Questi erano costituiti quasi esclusivamente da
WRITELOGattende, con un piccolo numero diPAGEIOLOATCH_EXePAGEIOLATCH_UPaspetta una buona misura. - Il numero totale di scaricamenti del registro durante le operazioni di Durabilità ritardata è stato piuttosto ridotto (basso 100 s/sec), mentre questo è balzato a oltre 4.000/sec per il comportamento tradizionale (e leggermente inferiore per la durata dell'HDD del test).
Meno, maggiori transazioni
Per il test successivo, volevo vedere cosa sarebbe successo se avessimo eseguito meno operazioni, ma mi sono assicurato che ogni istruzione influisse su una quantità maggiore di dati. Volevo che questo batch venisse eseguito su ogni database:
CREATE TABLE dbo.Rnd
(
batch TINYINT,
TheID INT
);
INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID();
GO
INSERT #Metrics SELECT 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate)
FROM dbo.TheTable AS t
INNER JOIN dbo.Rnd AS r
ON t.TheID = r.TheID
WHERE r.batch = 1;
GO 10000
UPDATE t SET RowGuid = NEWID()
FROM dbo.TheTable AS t
INNER JOIN dbo.Rnd AS r
ON t.TheID = r.TheID
WHERE r.batch = 2;
GO 10000
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.Rnd WHERE batch = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.Rnd WHERE batch = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.Rnd WHERE batch = 3);
GO
INSERT #Metrics SELECT 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2); Quindi ancora una volta ho usato il metodo pigro per produrre 8 copie di questo script, una per database:
;WITH x AS (SELECT TOP (8) number FROM master..spt_values WHERE type = N'P' ORDER BY number)
SELECT N'
USE dd' + RTRIM(Number+1) + ';
GO
CREATE TABLE dbo.Rnd
(
batch TINYINT,
TheID INT
);
INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID();
GO
INSERT #Metrics SELECT 2, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + ''', 2);
GO
UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate)
FROM dbo.TheTable AS t
INNER JOIN dbo.rnd AS r
ON t.TheID = r.TheID
WHERE r.cycle = 1;
GO 10000
UPDATE t SET RowGuid = NEWID()
FROM dbo.TheTable AS t
INNER JOIN dbo.rnd AS r
ON t.TheID = r.TheID
WHERE r.cycle = 2;
GO 10000
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.rnd WHERE cycle = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.rnd WHERE cycle = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.rnd WHERE cycle = 3);
GO
INSERT #Metrics SELECT 2, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x;
Ho eseguito questo batch, quindi ho modificato la query su #Metrics sopra per guardare il secondo test invece del primo. I risultati:
| database | scrive | byte | byte/scrittura | io_stall_ms | ora_di_inizio | end_time | durata (secondi) |
|---|---|---|---|---|---|---|---|
| dd1 | 20.970 | 1.271.911.936 | 60.653,88 | 12.577 | 26-04-2014 17:41:21 | 26-04-2014 17:43:46 | 145 |
| dd2 | 20.997 | 1.272.145.408 | 60.587,00 | 14.698 | 26-04-2014 17:43:46 | 26-04-2014 17:46:11 | 145 |
| dd3 | 20.973 | 1.272.982.016 | 60.696,22 | 12.085 | 26-04-2014 17:46:11 | 26-04-2014 17:48:33 | 142 |
| dd4 | 20.958 | 1.272.064.512 | 60.695,89 | 11.795 | 143 | ||
| dd5 | 30.138 | 1.282.231.808 | 42.545,35 | 7.402 | 26-04-2014 17:50:56 | 26-04-2014 17:53:23 | 147 |
| dd6 | 30.138 | 1.282.260.992 | 42.546,31 | 7.806 | 26-04-2014 17:53:23 | 26-04-2014 17:55:53 | 150 |
| dd7 | 30.129 | 1.281.575.424 | 42.536,27 | 9.888 | 26-04-2014 17:55:53 | 26-04-2014 17:58:25 | 152 |
| dd8 | 30.130 | 1.281.449.472 | 42.530,68 | 11.452 | 26-04-2014 17:58:25 | 26-04-2014 18:00:55 | 150 |
Transazioni più grandi:durata e risultati da sys.dm_io_virtual_file_stats
Questa volta, l'impatto della Durabilità Ritardata è molto meno evidente. Vediamo un numero leggermente inferiore di operazioni di scrittura, con un numero leggermente maggiore di byte per scrittura, con i byte totali scritti quasi identici. In questo caso vediamo effettivamente che gli stalli di I/O sono più alti per la durata ritardata, e questo probabilmente spiega il fatto che anche le durate erano quasi identiche.
Dalla dashboard di Performance Advisor, abbiamo alcune somiglianze con il test precedente e anche alcune nette differenze:
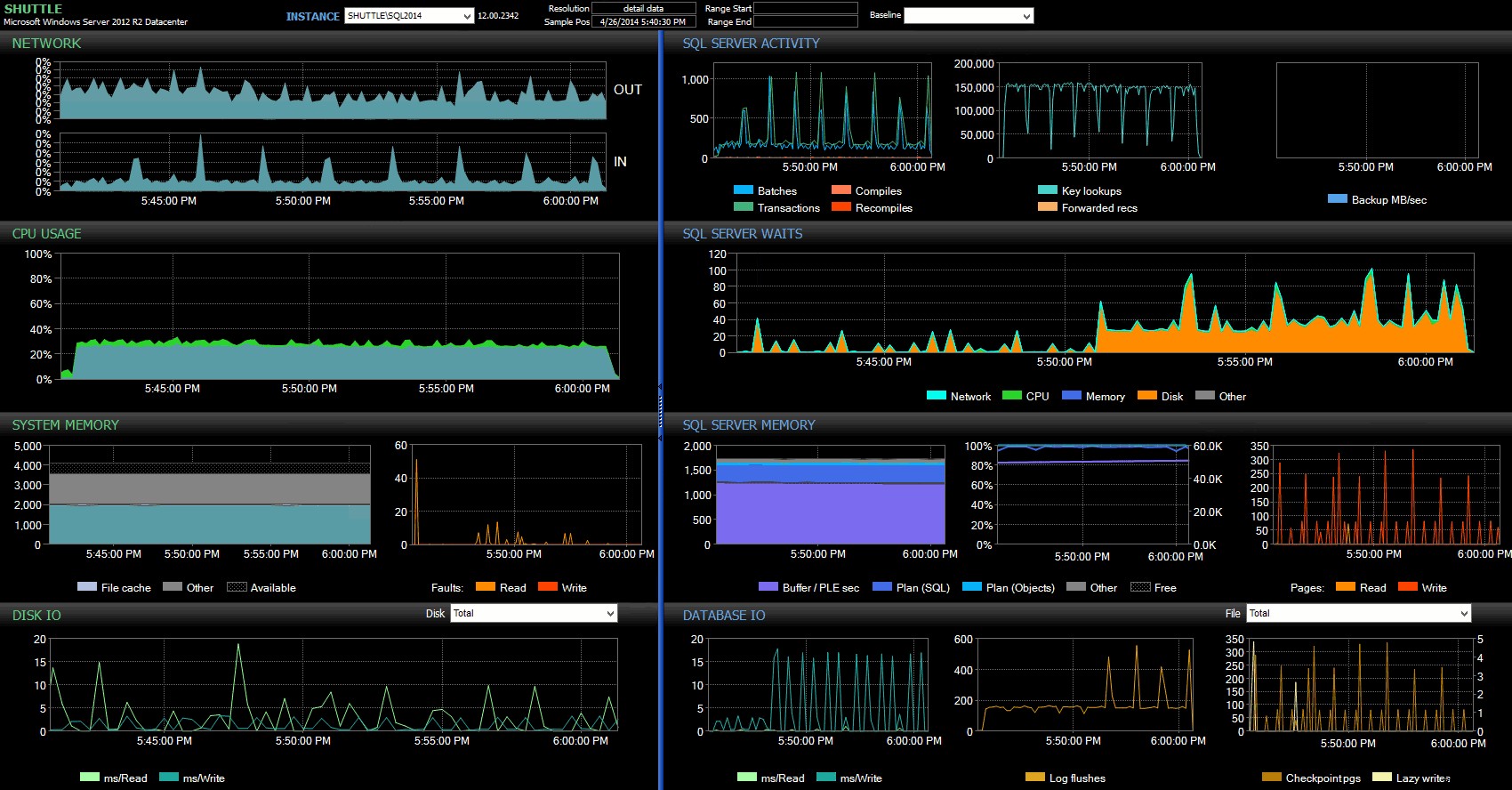
Dashboard di SQL Sentry:fai clic per ingrandire
Una delle grandi differenze da sottolineare qui è che il delta nelle statistiche di attesa non è così pronunciato come nel test precedente:c'è ancora una frequenza molto più alta di WRITELOG attende i batch completamente durevoli, ma per nulla vicino ai livelli visti con le transazioni più piccole. Un'altra cosa che puoi notare immediatamente è che l'impatto precedentemente osservato su batch e transazioni al secondo non è più presente. E infine, mentre ci sono più scaricamenti di log con transazioni completamente durevoli rispetto a quando sono ritardate, questa disparità è molto meno pronunciata rispetto alle transazioni più piccole.
Conclusione
Dovrebbe essere chiaro che ci sono alcuni tipi di carico di lavoro che possono trarre grandi vantaggi dalla durabilità ritardata, a condizione, ovviamente, che si abbia una tolleranza per la perdita di dati . Questa funzionalità non è limitata a OLTP in memoria, è disponibile in tutte le edizioni di SQL Server 2014 e può essere implementata con modifiche al codice minime o nulle. Può sicuramente essere una tecnica potente se il tuo carico di lavoro può supportarla. Ma ancora una volta, dovrai testare il tuo carico di lavoro per essere sicuro che trarrà vantaggio da questa funzionalità e valutare anche se ciò aumenta la tua esposizione al rischio di perdita di dati.
Per inciso, questa può sembrare alla folla di SQL Server come una nuova idea fresca, ma in verità Oracle l'ha introdotta come "Commit asincrono" nel 2006 (vedi COMMIT WRITE ... NOWAIT come documentato qui e bloggato nel 2007). E l'idea stessa esiste da quasi 3 decenni; vedere la breve cronaca della sua storia di Hal Berenson.
La prossima volta
Un'idea su cui mi sono battuto è cercare di migliorare le prestazioni di tempdb forzando la Durabilità Ritardata lì. Una proprietà speciale di tempdb ciò lo rende un candidato così allettante è che è transitorio per natura, qualsiasi cosa in tempdb è progettato, in modo esplicito, per essere lanciato sulla scia di un'ampia varietà di eventi di sistema. Lo sto dicendo ora senza avere alcuna idea se esiste una forma del carico di lavoro in cui funzionerà bene; ma ho intenzione di provarlo e, se trovo qualcosa di interessante, puoi star certo che lo posterò qui.



