Benjamin Nevarez è un consulente indipendente con sede a Los Angeles, California, specializzato nell'ottimizzazione e nell'ottimizzazione delle query di SQL Server. È autore di "SQL Server 2014 Query Tuning &Optimization" e "Inside the SQL Server Query Optimizer" e coautore di "SQL Server 2012 Internals". Con oltre 20 anni di esperienza nei database relazionali, Benjamin è stato anche relatore in molte conferenze su SQL Server, tra cui il PASS Summit, SQL Server Connections e SQLBits. Il blog di Benjamin può essere trovato su https://www.benjaminnevarez.com e può anche essere raggiunto via e-mail all'indirizzo admin di benjaminnevarez dot com e su Twitter all'indirizzo @BenjaminNevarez.
Sebbene la maggior parte delle informazioni, dei blog e della documentazione su SQL Server 2014 si sia concentrata su Hekaton e altre nuove funzionalità, non sono stati forniti molti dettagli sul nuovo stimatore di cardinalità. Attualmente BOL ne parla solo indirettamente nella sezione Novità (Motore di database), affermando che SQL Server 2014 "include miglioramenti sostanziali al componente che crea e ottimizza i piani di query" e ALTER DATABASE istruzione mostra come abilitare o disabilitare il suo comportamento. Fortunatamente possiamo ottenere alcune informazioni aggiuntive leggendo il documento di ricerca Testing Cardinality Estimation Models in SQL Server di Campbell Fraser et al. Sebbene l'obiettivo del documento sia il processo di garanzia della qualità del nuovo modello di stima, offre anche un'introduzione di base al nuovo stimatore di cardinalità e la motivazione della sua riprogettazione.
Allora, cos'è uno stimatore di cardinalità? Uno stimatore di cardinalità è il componente del Query Processor il cui compito è stimare il numero di righe restituite dalle operazioni relazionali in una query. Queste informazioni, insieme ad altri dati, vengono utilizzate da Query Optimizer per selezionare un piano di esecuzione efficiente. La stima della cardinalità è intrinsecamente inesatta, in quanto è un modello matematico che si basa su informazioni statistiche. Si basa inoltre su diversi presupposti che, sebbene non documentati, sono stati conosciuti nel corso degli anni, alcuni dei quali includono i presupposti di uniformità, indipendenza, contenimento e inclusione. Segue una breve descrizione di queste ipotesi.
- Uniformità . Utilizzato quando la distribuzione di un attributo è sconosciuta, ad esempio all'interno delle righe dell'intervallo in un passaggio dell'istogramma o quando un istogramma non è disponibile.
- Indipendenza . Utilizzato quando gli attributi in una relazione sono indipendenti, a meno che non sia nota una correlazione tra loro.
- Contenimento . Utilizzato quando due attributi possono essere uguali, si presume che siano gli stessi.
- Inclusione . Usato quando si confronta un attributo con una costante, si presume che ci sia sempre una corrispondenza.
È interessante notare che di recente ho parlato di alcuni dei limiti di questi presupposti nel mio ultimo discorso al PASS Summit, chiamato Defeating the Limitations of the Query Optimizer. Eppure sono stato sorpreso di leggere nell'articolo che gli autori ammettono che, secondo la loro esperienza pratica, queste ipotesi sono "spesso errate".
L'attuale stimatore di cardinalità è stato scritto insieme all'intero Query Processor per SQL Server 7.0, che è stato rilasciato nel dicembre del 1998. Ovviamente questo componente ha subito molteplici modifiche nel corso di diversi anni e più versioni di SQL Server, incluse correzioni, aggiustamenti ed estensioni a adattarsi alla stima della cardinalità per le nuove funzionalità di T-SQL. Quindi potresti pensare, perché sostituire un componente che è stato utilizzato con successo per circa 15 anni?
Perché un nuovo stimatore di cardinalità
Il documento spiega alcuni dei motivi della riprogettazione tra cui:
- Per adattare lo stimatore di cardinalità ai nuovi modelli di carico di lavoro.
- Le modifiche apportate allo stimatore di cardinalità nel corso degli anni hanno reso difficile il "debug, la previsione e la comprensione" del componente.
- Cercare di migliorare il modello attuale è stato difficile utilizzando l'architettura attuale, quindi è stato creato un nuovo design, incentrato sulla separazione dei compiti di (a) decidere come calcolare una stima particolare e (b) eseguire effettivamente il calcolo .
Non sono sicuro se Microsoft pubblicherà ulteriori dettagli sul nuovo stimatore di cardinalità. Dopotutto, non sono mai stati pubblicati così tanti dettagli sul vecchio stimatore di cardinalità in 15 anni; ad esempio, come viene calcolata una stima della cardinalità specifica. D'altra parte, ci sono nuovi eventi estesi che possiamo utilizzare per risolvere i problemi con la stima della cardinalità o semplicemente per esplorare come funziona. Questi eventi includono query_optimizer_estimate_cardinality , inaccurate_cardinality_estimate , query_optimizer_force_both_cardinality_estimation_behaviors e query_rpc_set_cardinality .
Pianificare le regressioni
Una delle principali preoccupazioni che viene in mente con un cambiamento così grande all'interno di Query Optimizer sono le regressioni del piano. La paura delle regressioni del piano è stata considerata il più grande ostacolo ai miglioramenti di Query Optimizer. Le regressioni sono problemi introdotti dopo l'applicazione di una correzione a Query Optimizer e talvolta indicati come i classici "due errori fanno una cosa giusta". Questo può accadere quando due stime sbagliate, ad esempio una che sopravvaluta un valore e la seconda che lo sottovaluta, si annullano a vicenda, fortunatamente dando una buona stima. La correzione di uno solo di questi valori ora può portare a una stima errata che può influire negativamente sulla scelta della selezione del piano, causando una regressione.
Per evitare regressioni correlate al nuovo stimatore di cardinalità, SQL Server offre un modo per abilitarlo o disabilitarlo, poiché dipende dal livello di compatibilità del database. Questo può essere modificato utilizzando il ALTER DATABASE dichiarazione, come indicato in precedenza. L'impostazione di un database al livello di compatibilità 120 utilizzerà il nuovo stimatore di cardinalità, mentre un livello di compatibilità inferiore a 120 utilizzerà il vecchio stimatore di cardinalità. Inoltre, una volta che si utilizza uno specifico stimatore di cardinalità, sono disponibili due flag di traccia che è possibile utilizzare per passare all'altro. Anche se al momento non vedo i flag di traccia documentati da nessuna parte, sono menzionati come parte della descrizione del query_optimizer_force_both_cardinality_estimation_behaviors evento esteso. Il flag di traccia 2312 può essere utilizzato per abilitare il nuovo stimatore di cardinalità, mentre il flag di traccia 9481 può essere utilizzato per disabilitarlo. Puoi persino utilizzare i flag di traccia per una query specifica utilizzando QUERYTRACEON suggerimento (sebbene non sia ancora documentato se anche questo sarà supportato).
Esempi
Infine, il documento menziona anche alcuni scenari testati come la chiave primaria sovrappopolata, il join semplice o il problema della chiave ascendente. Mostra anche come gli autori hanno sperimentato scenari multipli (o variazioni del modello) e in alcuni casi hanno "rilassato" alcune delle ipotesi fatte dallo stimatore di cardinalità, ad esempio, nel caso dell'ipotesi di indipendenza, passando dalla completa indipendenza alla completa correlazione e qualcosa nel mezzo fino a quando non sono stati trovati buoni risultati.
Sebbene non vengano forniti dettagli sul documento, decido di iniziare a testare alcuni di questi scenari per cercare di capire come funziona il nuovo stimatore di cardinalità. Per ora ti mostrerò un esempio usando il presupposto dell'indipendenza e le chiavi ascendenti. Ho anche testato l'ipotesi di uniformità, ma finora non sono riuscito a trovare alcuna differenza nella stima.
Cominciamo con l'esempio dell'ipotesi di indipendenza. Per prima cosa vediamo il comportamento attuale. Per questo, assicurati di utilizzare il vecchio stimatore di cardinalità eseguendo la seguente istruzione nel database AdventureWorks2012:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 110;
Quindi esegui:
SELECT * FROM Person.Address WHERE City = 'Burbank';
Otteniamo una stima di 196 record come mostrato di seguito:

In modo simile la seguente affermazione otterrà una stima di 194:
SELECT * FROM Person.Address WHERE PostalCode = '91502';
Se utilizziamo entrambi i predicati abbiamo la seguente query, che avrà un numero stimato di righe di 1,93862 (arrotondato a 2 righe se si utilizza SQL Sentry Plan Explorer):
SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502';
Questo valore viene calcolato assumendo la totale indipendenza di entrambi i predicati, che utilizza la formula (196 * 194) / 19614.0 (dove 19614 è il numero totale di righe nella tabella). Utilizzando una correlazione totale dovrebbe darci una stima di 194, poiché tutti i record con codice postale 91502 appartengono a Burbank. Il nuovo stimatore di cardinalità stima un valore che non presuppone una totale indipendenza o correlazione totale. Passare al nuovo stimatore di cardinalità utilizzando la seguente istruzione:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502';
L'esecuzione della stessa istruzione di nuovo darà una stima di 19,3931 righe, che puoi vedere è un valore tra l'assunzione dell'indipendenza totale e la correlazione totale (arrotondata a 19 righe in Plan Explorer). La formula utilizzata è la selettività del filtro più selettivo * SQRT(selettività del filtro più selettivo successivo) o (194/19614.0) * SQRT(196/19614.0) * 19614 che dà 19.393:

Se hai abilitato il nuovo stimatore di cardinalità a livello di database, vuoi disabilitarlo per una query specifica per evitare una regressione del piano, puoi utilizzare il flag di traccia 9481 come spiegato in precedenza:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502' OPTION (QUERYTRACEON 9481);
Nota:l'hint di query QUERYTRACEON viene utilizzato per applicare un flag di traccia a livello di query e attualmente è supportato solo in un numero limitato di scenari. Per ulteriori informazioni sul suggerimento per la query QUERYTRACEON, puoi consultare https://support.microsoft.com/kb/2801413.
Ora esaminiamo il problema della chiave ascendente, un argomento che ho spiegato più dettagliatamente in questo post. La tradizionale raccomandazione di Microsoft per risolvere questo problema è aggiornare manualmente le statistiche dopo aver caricato i dati, come spiegato qui, che descrive il problema nel modo seguente:
Le statistiche sulle colonne chiave ascendenti o discendenti, come IDENTITY o colonne timestamp in tempo reale, potrebbero richiedere aggiornamenti delle statistiche più frequenti rispetto a Query Optimizer. Le operazioni di inserimento aggiungono nuovi valori alle colonne ascendenti o discendenti. Il numero di righe aggiunte potrebbe essere troppo piccolo per attivare un aggiornamento delle statistiche. Se le statistiche non sono aggiornate e le query vengono selezionate dalle righe aggiunte più di recente, le statistiche correnti non avranno stime di cardinalità per questi nuovi valori. Ciò può comportare stime della cardinalità imprecise e prestazioni delle query lente. Ad esempio, una query che seleziona dalle date dell'ordine cliente più recenti avrà stime di cardinalità imprecise se le statistiche non vengono aggiornate per includere le stime di cardinalità per le date dell'ordine cliente più recenti.
La raccomandazione nel mio articolo era di utilizzare i flag di traccia 2389 e 2390, che sono stati pubblicati per la prima volta da Ian Jose nel suo articolo Ascending Keys and Auto Quick Corrected Statistics. Puoi leggere il mio articolo per una spiegazione e un esempio su come utilizzare questi flag di traccia per evitare questo problema. Questi flag di traccia funzionano ancora su SQL Server 2014 CTP2. Ma ancora meglio, non sono più necessari se stai utilizzando il nuovo stimatore di cardinalità.
Utilizzando lo stesso esempio nel mio post:
CREATE TABLE dbo.SalesOrderHeader (
SalesOrderID int NOT NULL,
RevisionNumber tinyint NOT NULL,
OrderDate datetime NOT NULL,
DueDate datetime NOT NULL,
ShipDate datetime NULL,
Status tinyint NOT NULL,
OnlineOrderFlag dbo.Flag NOT NULL,
SalesOrderNumber nvarchar(25) NOT NULL,
PurchaseOrderNumber dbo.OrderNumber NULL,
AccountNumber dbo.AccountNumber NULL,
CustomerID int NOT NULL,
SalesPersonID int NULL,
TerritoryID int NULL,
BillToAddressID int NOT NULL,
ShipToAddressID int NOT NULL,
ShipMethodID int NOT NULL,
CreditCardID int NULL,
CreditCardApprovalCode varchar(15) NULL,
CurrencyRateID int NULL,
SubTotal money NOT NULL,
TaxAmt money NOT NULL,
Freight money NOT NULL,
TotalDue money NOT NULL,
Comment nvarchar(128) NULL,
rowguid uniqueidentifier NOT NULL,
ModifiedDate datetime NOT NULL
); Inserisci alcuni dati:
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate < '2008-07-20 00:00:00.000'; CREATE INDEX IX_OrderDate ON SalesOrderHeader(OrderDate);
Dato che abbiamo creato un indice, abbiamo solo nuove statistiche. L'esecuzione della seguente query creerà una buona stima di 35 righe:
SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-19 00:00:00.000';
Se inseriamo nuovi dati:
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';
Puoi vedere la stima con il vecchio stimatore di cardinalità come mostrato di seguito:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 110; GO SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';

Poiché il numero ridotto di record inseriti non è stato sufficiente per attivare un aggiornamento automatico dell'oggetto statistiche, l'istogramma corrente non è a conoscenza dei nuovi record aggiunti e Query Optimizer utilizza una stima di 1 riga. Facoltativamente è possibile utilizzare i flag di traccia 2389 e 2390 per ottenere una stima migliore. Ma se provi la stessa query con il nuovo stimatore di cardinalità, ottieni la seguente stima:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';
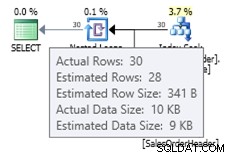
In questo caso otteniamo una stima migliore rispetto al vecchio stimatore di cardinalità (o otteniamo la stessa stima dell'utilizzo dei flag di traccia 2389 o 2390). Il valore stimato di 27,9631 (sempre arrotondato a 28 da Plan Explorer) è calcolato utilizzando le informazioni sulla densità dell'oggetto statistiche moltiplicate per il numero di righe della tabella; ovvero 0,0008992806 * 31095. Il valore della densità può essere ottenuto utilizzando:
DBCC SHOW_STATISTICS('dbo.SalesOrderHeader', 'IX_OrderDate'); Infine, tieni presente che nulla di quanto menzionato in questo articolo è documentato e questo è il comportamento che ho osservato finora in SQL Server 2014 CTP2. Tutto ciò potrebbe cambiare in un CTP successivo o nella versione RTM del prodotto.



