Recovery Time Objective (RTO) è il periodo di tempo entro il quale un servizio deve essere ripristinato per evitare conseguenze inaccettabili. Calcolando il tempo necessario per il ripristino da un errore del database, possiamo sapere quale sia il livello di preparazione richiesto. Se l'RTO è di pochi minuti, è necessario un investimento significativo nel failover. Un RTO di 36 ore richiede un investimento notevolmente inferiore. È qui che entra in gioco l'automazione del failover.
Nei nostri blog precedenti abbiamo discusso del failover per MongoDB, MySQL/MariaDB/Percona, PostgreSQL o TimeScaleDB. Per riassumere, "Failover " è la capacità di un sistema di continuare a funzionare anche se si verifica qualche guasto. Suggerisce che le funzioni del sistema sono assunte dai componenti secondari se i componenti primari si guastano. Il failover è una parte naturale di qualsiasi sistema ad alta disponibilità e in alcuni casi , deve anche essere automatizzato. I failover manuali richiedono troppo tempo, ma ci sono casi in cui l'automazione non funziona bene, ad esempio nel caso di un cervello diviso in cui la replica del database è interrotta e le due "metà" continuano a ricevere aggiornamenti, in modo efficace portando a set di dati divergenti e incoerenze.
In precedenza abbiamo parlato dei principi guida alla base delle procedure di failover automatico di ClusterControl. Laddove possibile, il failover automatizzato fornisce efficienza in quanto consente un rapido ripristino dagli errori. In questo blog, vedremo come ottenere il failover automatico in una configurazione di replica master-slave (o primary-standby) utilizzando ClusterControl.
Requisiti dello stack tecnologico
Uno stack può essere assemblato da componenti software open source e sono disponibili numerose opzioni, alcune più appropriate di altre a seconda delle caratteristiche di failover e anche del livello di esperienza disponibile per la gestione e la manutenzione della soluzione. Anche l'hardware e il networking sono aspetti importanti.
Software
Ci sono molte opzioni disponibili nell'ecosistema open source che puoi usare per implementare il failover. Per MySQL, puoi sfruttare MHA, MMM, Maxscale/MRM, mysqlfailover o Orchestrator. Questo blog precedente confronta MaxScale con MHA e Maxscale/MRM. PostgreSQL ha repmgr, Patroni, PostgreSQL Automatic Failover (PAF), pglookout, pgPool-II o stolon. Queste diverse opzioni di disponibilità elevata sono state trattate in precedenza. MongoDB ha set di repliche con supporto per il failover automatico.
ClusterControl fornisce funzionalità di failover automatico per MySQL, MariaDB, PostgreSQL e MongoDB, di cui parleremo più avanti. Vale la pena notare che ha anche funzionalità per recuperare automaticamente nodi o cluster rotti.
Hardware
Il failover automatico viene in genere eseguito da un server daemon separato, configurato sul proprio hardware, separato dai nodi del database. Sta monitorando lo stato dei database e utilizza le informazioni per prendere decisioni su come reagire in caso di guasto.
I server delle materie prime possono funzionare correttamente, a meno che il server non stia monitorando un numero enorme di istanze. In genere, i controlli di sistema e l'analisi dell'integrità sono leggeri in termini di elaborazione. Tuttavia, se hai un numero elevato di nodi da controllare, CPU e memoria di grandi dimensioni sono un must soprattutto quando i controlli devono essere messi in coda mentre tenta di eseguire il ping e raccogliere informazioni dai server. I nodi monitorati e supervisionati potrebbero bloccarsi a volte a causa di problemi di rete, carico elevato o, nel peggiore dei casi, potrebbero essere inattivi a causa di un guasto hardware o di un danneggiamento dell'host VM. Quindi il server che esegue i controlli di integrità e di sistema dovrà essere in grado di resistere a tali stalli, poiché è probabile che l'elaborazione delle code possa aumentare poiché le risposte a ciascuno dei nodi monitorati possono richiedere del tempo prima che venga verificato che non è più disponibile o si è verificato un timeout stato raggiunto.
Per gli ambienti basati su cloud, sono disponibili servizi che offrono il failover automatico. Ad esempio, Amazon RDS utilizza DRBD per replicare lo storage su un nodo standby. Oppure, se stai archiviando i tuoi volumi in EBS, questi vengono replicati in più zone.
Rete
Il software di failover automatizzato spesso si basa su agenti impostati sui nodi del database. L'agente raccoglie le informazioni localmente dall'istanza del database e le invia al server, quando richiesto.
In termini di requisiti di rete, assicurati di disporre di una buona larghezza di banda e di una connessione di rete stabile. I controlli devono essere eseguiti frequentemente e gli heartbeat mancati a causa di una rete instabile possono portare il software di failover a dedurre (erroneamente) che un nodo è inattivo.
ClusterControl non richiede l'installazione di alcun agente sui nodi del database, poiché eseguirà SSH in ciascun nodo del database a intervalli regolari ed eseguirà una serie di controlli.
Failover automatizzato con ClusterControl
ClusterControl offre la possibilità di eseguire failover manuali e automatizzati. Vediamo come si può fare.
Il failover in ClusterControl può essere configurato per essere automatico o meno. Se preferisci occuparti del failover manualmente, puoi disabilitare il ripristino automatico del cluster. Quando si esegue un failover manuale, è possibile accedere a Cluster → Topologia in ClusterControl. Vedi lo screenshot qui sotto:
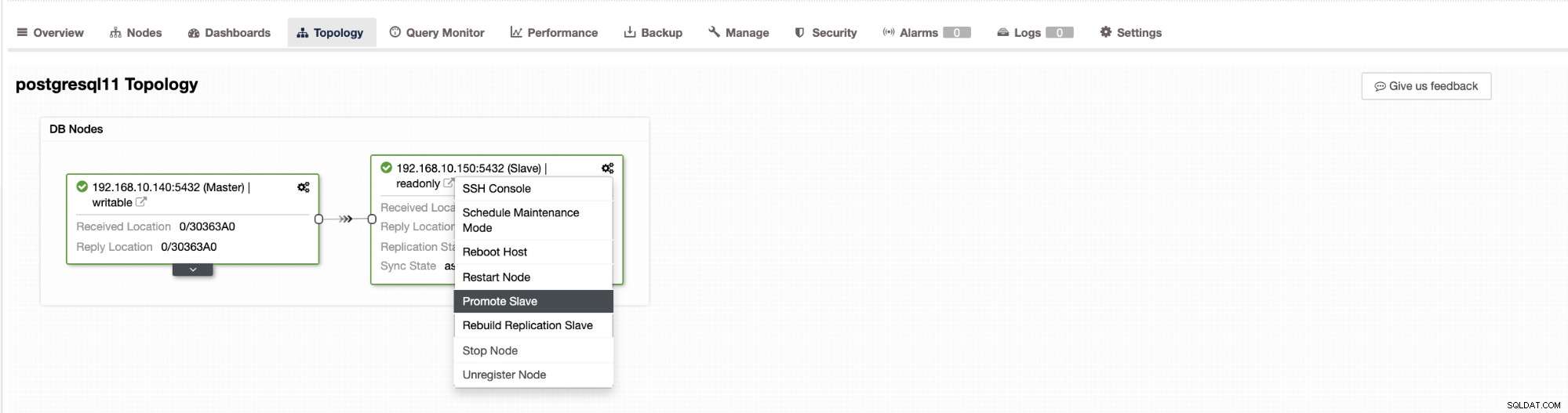
Per impostazione predefinita, il ripristino del cluster è abilitato e viene utilizzato il failover automatico. Dopo aver apportato modifiche nell'interfaccia utente, la configurazione di runtime viene modificata. Se desideri che l'impostazione sopravviva a un riavvio del controller, assicurati di apportare la modifica anche nella configurazione di cmon, ad esempio /etc/cmon.d/cmon_

Nel server MySQL/MariaDB/Percona, ClusterControl avvia il failover automatico quando rileva che non è presente alcun host con sola_lettura bandiera disabilitata. Può succedere perché master (che ha sola_lettura impostato su 0) non è disponibile o può essere attivato da un utente o da qualche software esterno che ha modificato questo flag sul master. Se si apportano modifiche manuali ai nodi del database o si dispone di un software che potrebbe interferire con le impostazioni di sola lettura, è necessario disabilitare il failover automatico. Il failover automatico di ClusterControl viene tentato una sola volta, pertanto un failover non riuscito non sarà seguito nuovamente da un failover successivo, non fino al riavvio di cmon.
Per PostgreSQL, ClusterControl sceglierà lo slave più avanzato, utilizzando a tale scopo pg_current_xlog_location (PostgreSQL 9+) o pg_current_wal_lsn (PostgreSQL 10+) a seconda della versione del nostro database. ClusterControl esegue anche diversi controlli sul processo di failover, al fine di evitare alcuni errori comuni. Un esempio è che se riusciamo a recuperare il nostro vecchio master fallito, "non " essere reintrodotto automaticamente nel cluster, né come master né come slave. Dobbiamo farlo manualmente. Questo eviterà la possibilità di perdita o incoerenza dei dati nel caso in cui il nostro slave (che abbiamo promosso) fosse in ritardo in quel momento dell'errore. Potremmo anche voler analizzare il problema in dettaglio prima di reintrodurlo nella configurazione di replica, quindi vorremmo preservare le informazioni diagnostiche.
Inoltre, se il failover ha esito negativo, non vengono effettuati ulteriori tentativi (questo vale sia per PostgreSQL che per i cluster basati su MySQL), è necessario un intervento manuale per analizzare il problema ed eseguire le azioni corrispondenti. Questo per evitare la situazione in cui ClusterControl, che gestisce il failover automatico, tenta di promuovere lo slave successivo e quello successivo. Potrebbe esserci un problema e non vogliamo peggiorare le cose tentando più failover.
ClusterControl offre l'inserimento in whitelist e blacklist di un insieme di server che si desidera partecipare al failover o escludere come candidati.
Per i cluster di tipo MySQL, ClusterControl crea un elenco di slave che possono essere promossi a master. Nella maggior parte dei casi, conterrà tutti gli slave nella topologia, ma l'utente ha un controllo aggiuntivo su di esso. Ci sono due variabili che puoi impostare nella configurazione di cmon:
replication_failover_whiteliste
replication_failover_blacklistPer la variabile di configurazione replication_failover_whitelist, contiene un elenco di IP o nomi host di slave che dovrebbero essere utilizzati come potenziali candidati master. Se questa variabile è impostata, verranno presi in considerazione solo quegli host. Per la variabile replication_failover_blacklist, contiene un elenco di host che non saranno mai considerati candidati master. È possibile utilizzarlo per elencare gli slave utilizzati per i backup o le query analitiche. Se l'hardware varia tra gli slave, potresti voler mettere qui gli slave che utilizzano hardware più lento.
replication_failover_whitelist ha la precedenza, il che significa che la replication_failover_blacklist viene ignorata se è impostata la replication_failover_whitelist.
Una volta che l'elenco degli slave che possono essere promossi a master è pronto, ClusterControl inizia a confrontare il loro stato, cercando lo slave più aggiornato. Qui, la gestione delle configurazioni basate su MariaDB e MySQL è diversa. Per le configurazioni di MariaDB, ClusterControl seleziona uno slave con il ritardo di replica più basso di tutti gli slave disponibili. Per le configurazioni MySQL, ClusterControl seleziona anche uno schiavo di questo tipo, ma poi verifica la presenza di ulteriori transazioni mancanti che potrebbero essere state eseguite su alcuni degli schiavi rimanenti. Se viene trovata una tale transazione, ClusterControl assolve il candidato master dall'host per recuperare tutte le transazioni mancanti. Puoi saltare questo processo e utilizzare semplicemente lo slave più avanzato impostando la variabile replication_skip_apply_missing_txs nella tua configurazione CMON:
es.
replication_skip_apply_missing_txs=1Consulta la nostra documentazione qui per ulteriori informazioni con le variabili.
L'avvertenza è che devi impostarlo solo se sai cosa stai facendo, poiché potrebbero esserci transazioni errate. Ciò potrebbe causare l'interruzione della replica e l'incoerenza dei dati nel cluster. Se la transazione errata è avvenuta in passato, potrebbe non essere più disponibile nei log binari. In tal caso, la replica si interromperà perché gli slave non saranno in grado di recuperare i dati mancanti. Pertanto, ClusterControl, per impostazione predefinita, controlla eventuali transazioni errate prima di promuovere un candidato master a diventare un master. Se viene rilevato tale problema, l'interruttore principale viene interrotto e ClusterControl consente all'utente di risolvere il problema manualmente.
Se vuoi essere certo al 100% che ClusterControl promuoverà un nuovo master anche se vengono rilevati alcuni problemi, puoi farlo utilizzando la variabile replication_stop_on_error. Vedi sotto:
es.
replication_stop_on_error=0Imposta questa variabile nel tuo file di configurazione cmon. Come accennato in precedenza, potrebbe causare problemi con la replica poiché gli slave potrebbero iniziare a richiedere un evento di registro binario che non è più disponibile. Per gestire questi casi abbiamo aggiunto il supporto sperimentale per la ricostruzione degli schiavi. Se imposti la variabile
replication_auto_rebuild_slave=1nella configurazione di cmon e se il tuo slave è contrassegnato come inattivo con il seguente errore in MySQL:
Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'ClusterControl tenterà di ricostruire lo slave utilizzando i dati del master. Tale impostazione potrebbe non essere sempre appropriata poiché il processo di ricostruzione indurrà un carico maggiore sul master. Potrebbe anche essere che il tuo set di dati sia molto grande e una ricostruzione regolare non sia un'opzione, ecco perché questo comportamento è disabilitato per impostazione predefinita.
Una volta che ci assicuriamo che non esistano transazioni errate e che siamo a posto, c'è ancora un altro problema che dobbiamo gestire in qualche modo:può succedere che tutti gli slave siano in ritardo rispetto al master.
Come probabilmente saprai, la replica in MySQL funziona in un modo piuttosto semplice. Il master memorizza le scritture nei log binari. Il thread I/O dello slave si connette al master ed estrae tutti gli eventi di log binari mancanti. Quindi li memorizza sotto forma di registri di inoltro. Il thread SQL li analizza e applica gli eventi. Lo slave lag è una condizione in cui il thread (o i thread) SQL non è in grado di far fronte al numero di eventi e non è in grado di applicarli non appena vengono estratti dal master dal thread di I/O. Tale situazione può verificarsi indipendentemente dal tipo di replica in uso. Anche se si utilizza la replica semi-sincronizzazione, può solo garantire che tutti gli eventi dal master siano archiviati su uno degli slave nel registro di inoltro. Non dice nulla sull'applicazione di quegli eventi a uno schiavo.
Il problema qui è che, se uno slave viene promosso a master, i log dei relè verranno cancellati. Se uno slave è in ritardo e non ha applicato tutte le transazioni, perderà i dati:gli eventi non ancora applicati dai registri di inoltro andranno persi per sempre.
Non esiste un modo valido per tutti per risolvere questa situazione. ClusterControl offre agli utenti il controllo su come dovrebbe essere fatto, mantenendo le impostazioni predefinite sicure. Viene eseguito nella configurazione cmon utilizzando la seguente impostazione:
replication_failover_wait_to_apply_timeout=-1Per impostazione predefinita, assume un valore di "-1", il che significa che il failover non avverrà immediatamente se un candidato master è in ritardo, quindi è impostato per attendere per sempre a meno che il candidato non abbia recuperato. ClusterControl attenderà indefinitamente che applichi tutte le transazioni mancanti dai suoi registri di inoltro. Questo è sicuro, ma, se per qualche motivo lo slave più aggiornato è in grave ritardo, il completamento del failover potrebbe richiedere ore. Dall'altro lato dello spettro è impostato su "0":significa che il failover si verifica immediatamente, indipendentemente dal fatto che il candidato master sia in ritardo o meno. Puoi anche andare nella via di mezzo e impostarlo su un valore. Questo imposterà un tempo in secondi, ad esempio 30 secondi, quindi imposta la variabile su,
replication_failover_wait_to_apply_timeout=30Quando è impostato su> 0, ClusterControl attende che un candidato master applichi le transazioni mancanti dai suoi registri di inoltro fino a quando il valore non viene raggiunto (che nell'esempio è 30 secondi). Il failover si verifica dopo il tempo definito o quando il candidato principale raggiungerà la replica, a seconda di quale evento si verifica per primo. Questa potrebbe essere una buona scelta se la tua applicazione ha requisiti specifici per quanto riguarda i tempi di inattività e devi eleggere un nuovo master entro un breve lasso di tempo.
Per maggiori dettagli sul funzionamento di ClusterControl con il failover automatico in PostgreSQL e MySQL, consulta i nostri blog precedenti intitolati "Failover for PostgreSQL Replication 101" e "Failover automatico di MySQL Replication - Novità in ClusterControl 1.4".
Conclusione
Il failover automatico è una funzionalità preziosa, soprattutto per le aziende che richiedono operazioni 24 ore su 24, 7 giorni su 7 con tempi di inattività minimi. L'azienda deve definire quanto controllo viene concesso al processo di automazione durante le interruzioni non pianificate. Una soluzione ad alta disponibilità come ClusterControl offre un livello di interazione personalizzabile nell'elaborazione del failover. Per alcune organizzazioni, il failover automatizzato potrebbe non essere un'opzione, anche se l'interazione dell'utente durante il failover può consumare tempo e influire sull'RTO. Il presupposto è che sia troppo rischioso nel caso in cui il failover automatizzato non funzioni correttamente o, peggio ancora, si traduca in dati incasinati e parzialmente mancanti (sebbene si possa sostenere che anche un essere umano può commettere errori disastrosi con conseguenze simili). Coloro che preferiscono mantenere uno stretto controllo sul proprio database possono scegliere di saltare il failover automatico e utilizzare invece un processo manuale. Tale processo richiede più tempo, ma consente a un amministratore esperto di valutare lo stato di un sistema e intraprendere azioni correttive in base a ciò che è accaduto.