La migrazione dal database Oracle all'open source può apportare numerosi vantaggi. Il minor costo di proprietà è allettante e spinge molte aziende a migrare. Allo stesso tempo, DevOps, SysOps o DBA devono mantenere stretti SLA per soddisfare le esigenze aziendali.
Una delle preoccupazioni principali quando si pianifica la migrazione dei dati a un altro database, in particolare l'open source, è come evitare la perdita di dati. Non è troppo inverosimile che qualcuno abbia eliminato accidentalmente parte del database, qualcuno abbia dimenticato di includere una clausola WHERE in una query DELETE o abbia eseguito DROP TABLE accidentalmente. La domanda è come riprendersi da tali situazioni.
Cose del genere possono e accadranno, è inevitabile ma l'impatto può essere disastroso. Come qualcuno ha detto, "È tutto divertimento e giochi finché il backup non fallisce". Il bene più prezioso non può essere compromesso. Punto.
La paura dell'ignoto è naturale se non si ha familiarità con le nuove tecnologie. In effetti, la conoscenza delle soluzioni di database Oracle, l'affidabilità e le straordinarie funzionalità offerte da Oracle Recovery Manager (RMAN) possono scoraggiare te o il tuo team a migrare a un nuovo sistema di database. Ci piace usare le cose che conosciamo, quindi perché migrare quando la nostra soluzione attuale funziona. Chissà quanti progetti sono stati sospesi perché il team o l'individuo non erano convinti della nuova tecnologia?
Backup logici (exp/imp, expdp/impdb)
Secondo la documentazione MySQL, il backup logico è "un backup che riproduce la struttura della tabella e i dati, senza copiare i file di dati effettivi". Questa definizione può essere applicata sia al mondo MySQL che Oracle. Lo stesso vale per "perché" e "quando" utilizzerai il backup logico.
I backup logici sono una buona opzione quando sappiamo quali dati verranno modificati in modo da poter eseguire il backup solo della parte di cui hai bisogno. Semplifica il potenziale ripristino in termini di tempo e complessità. È anche molto utile se dobbiamo spostare una parte di un set di dati di piccole/medie dimensioni e copiarli su un altro sistema (spesso su una versione di database diversa). Oracle utilizza utilità di esportazione come exp ed expdp per leggere i dati del database e quindi esportarli in un file a livello di sistema operativo. È quindi possibile importare nuovamente i dati in un database utilizzando le utility di importazione imp o impdp.
Oracle Export Utilities ci offre molte opzioni per scegliere quali dati devono essere esportati. Sicuramente non troverai lo stesso numero di funzionalità con mysql, ma la maggior parte delle esigenze sono coperte e il resto può essere fatto con script aggiuntivi o strumenti esterni (controlla mydumper).
MySQL viene fornito con un pacchetto di strumenti che offrono funzionalità di base. Sono mysqldump, mysqlpump (la versione moderna di mysqldump che ha il supporto nativo per la parallelizzazione) e il client MySQL che può essere utilizzato per estrarre i dati in un file flat.
Di seguito puoi trovare diversi esempi di come utilizzarli:
Solo struttura del database di backup
mysqldump --no-data -h localhost -u root -ppassword mydatabase > mydatabase_backup.sqlStruttura della tabella di backup
mysqldump --no-data --single- transaction -h localhost -u root -ppassword mydatabase table1 table2 > mydatabase_backup.sqlEseguire il backup di righe specifiche
mysqldump -h localhost --single- transaction -u root -ppassword mydatabase table_name --where="date_created='2019-05-07'" > table_with_specific_rows_dump.sqlImportazione della tabella
mysql -u username -p -D dbname < tableName.sqlIl comando precedente interromperà il caricamento se si verifica un errore.
Se carichi i dati direttamente dal client mysql, gli errori verranno ignorati e il client procederà
mysql> source tableName.sqlPer registrare l'output, devi utilizzare
mysql> tee import_tableName.logPuoi trovare tutti i flag spiegati sotto i link seguenti:
- https://dev.mysql.com/doc/refman/8.0/en/mysqldump.html
- https://dev.mysql.com/doc/refman/8.0/en/mysqlimport.html
- https://dev.mysql.com/doc/refman/8.0/en/mysql.html
Se prevedi di utilizzare il backup logico su diverse versioni del database, assicurati di avere la corretta configurazione delle regole di confronto. La seguente istruzione può essere utilizzata per controllare il set di caratteri e le regole di confronto predefiniti per un determinato database:
USE mydatabase;
SELECT @@character_set_database, @@collation_database;Un altro modo per recuperare la variabile di sistema collation_database consiste nell'usare SHOW VARIABLES.
SHOW VARIABLES LIKE 'collation%';A causa delle limitazioni del dump di MySQL, spesso dobbiamo modificare l'output. Un esempio di tale modifica può essere la necessità di rimuovere alcune righe. Fortunatamente, abbiamo la flessibilità di visualizzare e modificare l'output utilizzando strumenti di testo standard prima del ripristino. Strumenti come awk, grep, sed possono diventare tuoi amici. Di seguito è riportato un semplice esempio di come rimuovere la terza riga dal file dump.
sed -i '1,3d' file.txtLe possibilità sono infinite. Questo è qualcosa che non troveremo con Oracle poiché i dati sono scritti in formato binario.
Ci sono alcune cose che devi considerare quando esegui mysql logico. Uno dei limiti principali è il puro supporto del parallelismo e il blocco degli oggetti.
Considerazioni sul backup logico
Quando viene eseguito tale backup, verranno eseguiti i seguenti passaggi.
- Tabella LOCK TABLE.
- MOSTRA tabella CREA TABELLA.
- SELECT * FROM table INTO OUTFILE file temporaneo.
- Scrivi il contenuto del file temporaneo alla fine del file dump.
- SBLOCCA TABELLE
Per impostazione predefinita mysqldump non include routine ed eventi nel suo output:devi impostare esplicitamente --routines e --events flags.
Un'altra considerazione importante è un motore che usi per archiviare i tuoi dati. Si spera che in questi giorni la maggior parte dei sistemi di produzione utilizzi un motore compatibile con ACID chiamato InnoDB. Il vecchio motore MyISAM doveva bloccare tutte le tabelle per garantire la coerenza. Questo è quando è stato eseguito FLUSH TABELLE CON BLOCCO LETTURA. Sfortunatamente, è l'unico modo per garantire uno snapshot coerente delle tabelle MyISAM mentre il server MySQL è in esecuzione. Ciò renderà il server MySQL di sola lettura finché non verrà eseguito UNLOCK TABLES.
Per le tabelle sul motore di archiviazione InnoDB, si consiglia di utilizzare l'opzione --single-transation. MySQL produce quindi un checkpoint che consente al dump di acquisire tutti i dati prima del checkpoint durante la ricezione delle modifiche in arrivo.
L'opzione --single-transaction di mysqldump non esegue il FLUSH TABELLE CON BLOCCO LETTURA. Fa sì che mysqldump imposti una transazione REPEATABLE READ per tutte le tabelle in fase di dumping.
Un backup di mysqldump è molto più lento di Oracle tools exp, expdp. Mysqldump è uno strumento a thread singolo e questo è il suo svantaggio più significativo:le prestazioni sono ok per i database di piccole dimensioni, ma diventano rapidamente inaccettabili se il set di dati cresce fino a decine di gigabyte.
- INIZIA LA TRANSAZIONE CON UN'ISTANTANEA COERENTE.
- Per ogni schema e tabella di database, un dump esegue questi passaggi:
- MOSTRA tabella CREA TABELLA.
- SELECT * FROM table INTO OUTFILE file temporaneo.
- Scrivi il contenuto del file temporaneo alla fine del file dump.
- IMPEGNA.
Backup fisici (RMAN)
Fortunatamente, la maggior parte dei limiti del backup logico può essere risolta con lo strumento Percona Xtrabackup. Percona XtraBackup è il più popolare software di backup a caldo MySQL/MariaDB open source che esegue backup non bloccanti per i database InnoDB e XtraDB. Rientra nella categoria del backup fisico, che consiste in copie esatte della directory dei dati MySQL e dei file sottostanti.
È la stessa categoria di strumenti come Oracle RMAN. RMAN viene fornito come parte del software del database, XtraBackup deve essere scaricato separatamente. Xtrabackup è disponibile come pacchetto rpm e deb e supporta solo piattaforme Linux. L'installazione è molto semplice:
$ wget https://www.percona.com/downloads/XtraBackup/Percona-XtraBackup-8.0.4/binary/redhat/7/x86_64/percona-XtraBackup-80-8.0.4-1.el7.x86_64.rpm
$ yum localinstall percona-XtraBackup-80-8.0.4-1.el7.x86_64.rpmXtraBackup non blocca il database durante il processo di backup. Per database di grandi dimensioni (oltre 100 GB), fornisce tempi di ripristino molto migliori rispetto a mysqldump. Il processo di ripristino prevede la preparazione dei dati MySQL dai file di backup, prima di sostituirli o cambiarli con la directory dei dati corrente sul nodo di destinazione.
Percona XtraBackup funziona ricordando il numero di sequenza del registro (LSN) all'avvio e quindi copiando i file di dati in un'altra posizione. La copia dei dati richiede del tempo e, se i file cambiano, riflettono lo stato del database in momenti diversi. Allo stesso tempo, XtraBackup esegue un processo in background che tiene d'occhio i file di registro delle transazioni (noti anche come redo log) e copia le modifiche da esso. Questo deve essere fatto continuamente perché i registri delle transazioni sono scritti in modo round-robin e possono essere riutilizzati dopo un po'. XtraBackup necessita dei record del registro delle transazioni per ogni modifica ai file di dati dall'inizio dell'esecuzione.
Quando XtraBackup è installato puoi finalmente eseguire i tuoi primi backup fisici.
xtrabackup --user=root --password=PASSWORD --backup --target-dir=/u01/backups/Un'altra opzione utile che fanno gli amministratori MySQL è lo streaming del backup su un altro server. Tale flusso può essere eseguito con l'uso dello strumento xbstream, come nell'esempio seguente:
Avvia un listener sul server esterno sulla porta preferita (in questo esempio 1984)
nc -l 1984 | pigz -cd - | pv | xbstream -x -C /u01/backupsEsegui il backup e trasferisci su un host esterno
innobackupex --user=root --password=PASSWORD --stream=xbstream /var/tmp | pigz | pv | nc external_host.com 1984Come puoi notare, il processo di ripristino è diviso in due passaggi principali (simile a Oracle). I passaggi vengono ripristinati (copia indietro) e ripristino (applica registro).
XtraBackup --copy-back --target-dir=/var/lib/data
innobackupex --apply-log --use-memory=[values in MB or GB] /var/lib/dataLa differenza è che possiamo eseguire il ripristino solo fino al punto in cui è stato eseguito il backup. Per applicare le modifiche dopo il backup dobbiamo farlo manualmente.
Ripristino temporizzato (ripristino RMAN)
In Oracle, RMAN esegue tutti i passaggi quando eseguiamo il ripristino del database. Può essere eseguito su SCN o sull'ora o in base al set di dati di backup.
RMAN> run
{
allocate channel dev1 type disk;
set until time "to_date('2019-05-07:00:00:00', 'yyyy-mm-dd:hh24:mi:ss')";
restore database;
recover database; }In mysql, abbiamo bisogno di un altro strumento da eseguire per estrarre i dati dai log binari (simili agli archivi di Oracle) mysqlbinlog. mysqlbinlog può leggere i log binari e convertirli in file. Quello che dobbiamo fare è
La procedura di base sarebbe
- Ripristina il backup completo
- Ripristina backup incrementali
- Per identificare l'ora di inizio e di fine del ripristino (che potrebbe essere la fine del backup e il numero di posizione prima della tabella di rilascio).
- Converti i binglog necessari in SQL e applica i file SQL appena creati nella sequenza corretta:assicurati di eseguire un singolo comando mysqlbinlog.
> mysqlbinlog binlog.000001 binlog.000002 | mysql -u root -p
Crittografa i backup (Oracle Wallet)
Percona XtraBackup può essere utilizzato per crittografare o decrittografare backup locali o in streaming con l'opzione xbstream per aggiungere un altro livello di protezione ai backup. Sia l'opzione --encrypt-key che l'opzione --encryptkey-file possono essere utilizzate per specificare la chiave di crittografia. Le chiavi di crittografia possono essere generate con comandi come
$ openssl rand -base64 24
$ bWuYY6FxIPp3Vg5EDWAxoXlmEFqxUqz1Questo valore può quindi essere utilizzato come chiave di crittografia. Esempio del comando innobackupex che utilizza --encrypt-key:
$ innobackupex --encrypt=AES256 --encrypt-key=”bWuYY6FxIPp3Vg5EDWAxoXlmEFqxUqz1” /storage/backups/encryptedPer decrittografare, usa semplicemente l'opzione --decrypt con l'appropriato --encrypt-key:
$ innobackupex --decrypt=AES256 --encrypt-key=”bWuYY6FxIPp3Vg5EDWAxoXlmEFqxUqz1”
/storage/backups/encrypted/2019-05-08_11-10-09/Norme di backup
Non esiste alcuna funzionalità di policy di backup integrata né in MySQL/MariaDB né nello strumento di Percona. Se desideri gestire i tuoi backup logici o fisici MySQL, puoi utilizzare ClusterControl per questo.
ClusterControl è il sistema di gestione di database open source all-inclusive per utenti con ambienti misti. Fornisce funzionalità avanzate di gestione del backup per MySQL o MariaDB.
Con ClusterControl puoi:
- Crea criteri di backup
- Monitoraggio dello stato, delle esecuzioni e dei server dei backup senza backup
- Esegui backup e ripristini (incluso un ripristino temporizzato)
- Controllare la conservazione dei backup
- Salva i backup nell'archivio cloud
- Convalida backup (test completo con ripristino sul server standalone)
- Crittografa i backup
- Comprimi i backup
- E molti altri
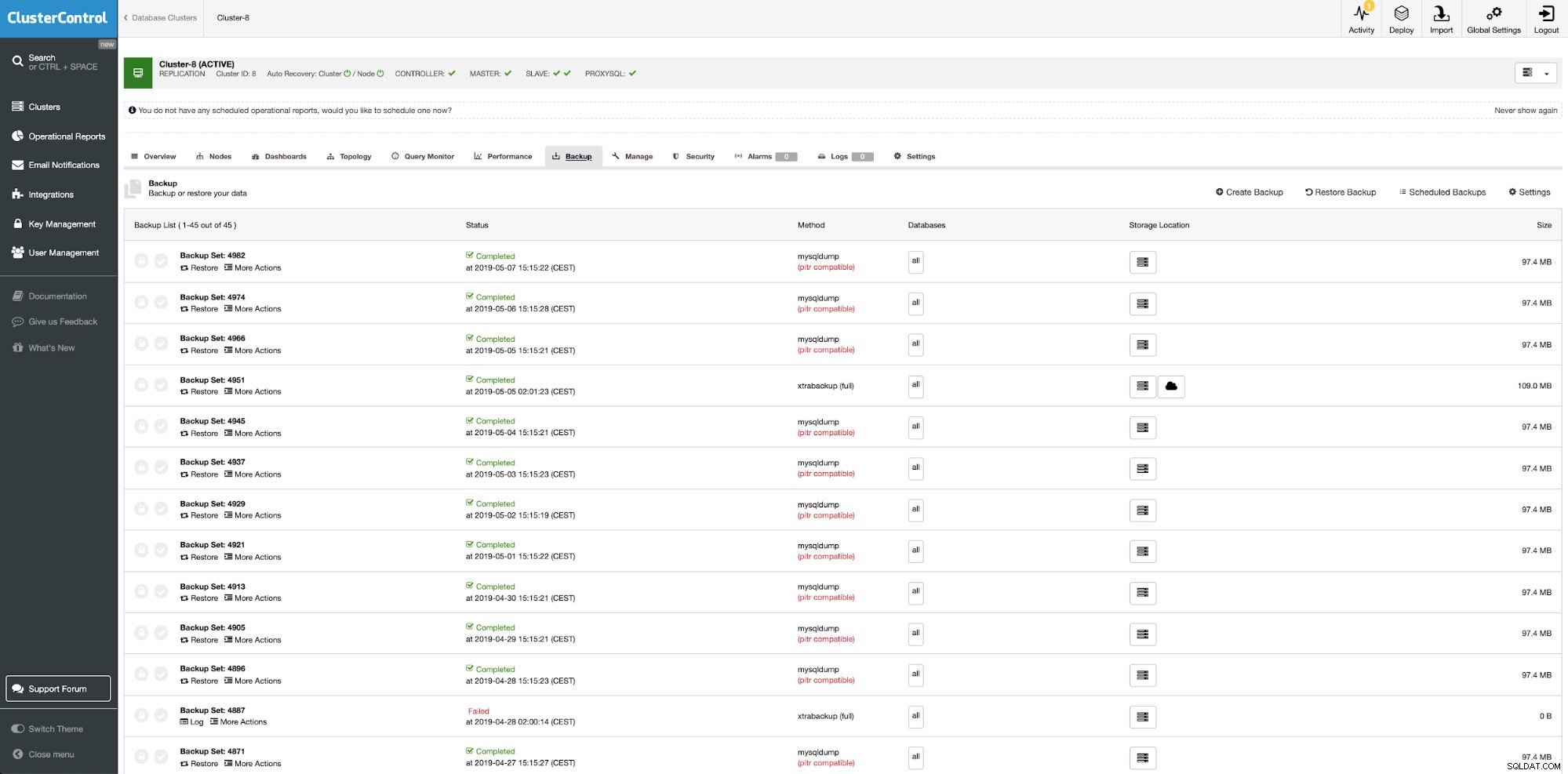 ClusterControl:gestione del backup
ClusterControl:gestione del backup Mantieni i backup nel cloud
Le organizzazioni hanno storicamente implementato soluzioni di backup su nastro come mezzo per proteggere
i dati dagli errori. Tuttavia, l'emergere del cloud computing pubblico ha anche consentito nuovi modelli con un TCO inferiore rispetto a quello tradizionalmente disponibile. Non ha senso per gli affari astrarre il costo di una soluzione di ripristino di emergenza dalla sua progettazione, quindi le organizzazioni devono implementare il giusto livello di protezione al minor costo possibile.
Il cloud ha cambiato il settore del backup dei dati. A causa del suo prezzo accessibile, le piccole imprese hanno una soluzione fuori sede che esegue il backup di tutti i loro dati (e sì, assicurati che siano crittografati). Sia Oracle che MySQL non offrono soluzioni di archiviazione cloud integrate. Invece puoi utilizzare gli strumenti forniti dai fornitori di cloud. Un esempio qui potrebbe essere s3.
aws s3 cp severalnines.sql s3://severalnine-sbucket/mysql_backupsConclusione

Esistono diversi modi per eseguire il backup del database, ma è importante esaminare le esigenze aziendali prima di decidere una strategia di backup. Come puoi vedere, ci sono molte somiglianze tra i backup MySQL e Oracle che si spera possano soddisfare i tuoi SLA.
Assicurati sempre di esercitarti con questi comandi. Non solo quando sei nuovo alla tecnologia, ma ogni volta che il DBMS diventa inutilizzabile, quindi sai cosa fare.
Se desideri saperne di più su MySQL, consulta il nostro whitepaper The DevOps Guide to Database Backups for MySQL e MariaDB.