Una delle caratteristiche interessanti di Galera è il provisioning automatico dei nodi e il controllo dell'appartenenza. Se un nodo non riesce o perde la comunicazione, verrà automaticamente rimosso dal cluster e rimarrà non operativo. Finché la maggior parte dei nodi sta ancora comunicando (Galera chiama questo PC - componente principale), c'è un'alta probabilità che il nodo guasto sia in grado di ricongiungersi, risincronizzare e riprendere automaticamente la replica una volta ripristinata la connettività.
In generale, tutti i nodi Galera sono uguali. Hanno lo stesso set di dati e lo stesso ruolo dei master, in grado di gestire la lettura e la scrittura contemporaneamente, grazie alla comunicazione di gruppo Galera e al plug-in di replica basato sulla certificazione. Pertanto, in realtà non vi è alcun failover dal punto di vista del database a causa di questo equilibrio. Solo dal lato dell'applicazione che richiederebbe il failover, per saltare i nodi non operativi mentre il cluster è partizionato.
In questo post del blog, esamineremo la comprensione di come Galera Cluster esegue il ripristino di nodi e cluster nel caso in cui si verifichi una partizione di rete. Proprio come nota a margine, abbiamo trattato un argomento simile in questo post del blog qualche tempo fa. Codership ha spiegato in dettaglio il concetto di ripristino di Galera nella pagina della documentazione, Node Failure and Recovery.
Errore ed eliminazione del nodo
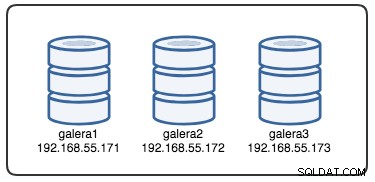
Per comprendere il ripristino, dobbiamo prima capire come Galera rileva il guasto del nodo e il processo di sfratto. Mettiamolo in uno scenario di test controllato in modo da poter comprendere meglio il processo di sfratto. Supponiamo di avere un cluster Galera a tre nodi come illustrato di seguito:
Il seguente comando può essere utilizzato per recuperare le nostre opzioni del provider Galera:
mysql> SHOW VARIABLES LIKE 'wsrep_provider_options'\GÈ un lungo elenco, ma dobbiamo solo concentrarci su alcuni parametri per spiegare il processo:
evs.inactive_check_period = PT0.5S;
evs.inactive_timeout = PT15S;
evs.keepalive_period = PT1S;
evs.suspect_timeout = PT5S;
evs.view_forget_timeout = P1D;
gmcast.peer_timeout = PT3S;Prima di tutto, Galera segue la formattazione ISO 8601 per rappresentare la durata. P1D significa che la durata è di un giorno, mentre PT15S significa che la durata è di 15 secondi (notare l'indicatore dell'ora, T, che precede il valore dell'ora). Ad esempio, se si desidera aumentare evs.view_forget_timeout a 1 giorno e mezzo, si imposterebbe P1DT12H o PT36H.
Considerando che tutti gli host non sono stati configurati con alcuna regola del firewall, utilizziamo il seguente script chiamato block_galera.sh su galera2 per simulare un errore di rete da/verso questo nodo:
#!/bin/bash
# block_galera.sh
# galera2, 192.168.55.172
iptables -I INPUT -m tcp -p tcp --dport 4567 -j REJECT
iptables -I INPUT -m tcp -p tcp --dport 3306 -j REJECT
iptables -I OUTPUT -m tcp -p tcp --dport 4567 -j REJECT
iptables -I OUTPUT -m tcp -p tcp --dport 3306 -j REJECT
# print timestamp
dateEseguendo lo script, otteniamo il seguente output:
$ ./block_galera.sh
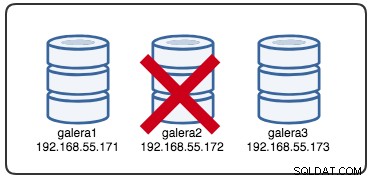
Wed Jul 4 16:46:02 UTC 2018Il timestamp riportato può essere considerato come l'inizio del partizionamento del cluster, dove perdiamo galera2, mentre galera1 e galera3 sono ancora online e accessibili. A questo punto, la nostra architettura Galera Cluster è simile a questa:
Dalla prospettiva del nodo partizionato
Su galera2, vedrai alcune stampe all'interno del registro degli errori di MySQL. Dividiamoli in più parti. Il downtime è iniziato intorno alle 16:46:02 UTC e dopo gmcast.peer_timeout=PT3S , viene visualizzato quanto segue:
2018-07-04 16:46:05 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') connection to peer 8b2041d6 with addr tcp://192.168.55.173:4567 timed out, no messages seen in PT3S
2018-07-04 16:46:05 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.55.173:4567
2018-07-04 16:46:06 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') connection to peer 737422d6 with addr tcp://192.168.55.171:4567 timed out, no messages seen in PT3S
2018-07-04 16:46:06 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 0Quando ha superato evs.suspect_timeout =PT5S , entrambi i nodi galera1 e galera3 sono sospettati di essere morti da galera2:
2018-07-04 16:46:07 140454904243968 [Note] WSREP: evs::proto(62116b35, OPERATIONAL, view_id(REG,62116b35,54)) suspecting node: 8b2041d6
2018-07-04 16:46:07 140454904243968 [Note] WSREP: evs::proto(62116b35, OPERATIONAL, view_id(REG,62116b35,54)) suspected node without join message, declaring inactive
2018-07-04 16:46:07 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 0
2018-07-04 16:46:08 140454904243968 [Note] WSREP: evs::proto(62116b35, GATHER, view_id(REG,62116b35,54)) suspecting node: 737422d6
2018-07-04 16:46:08 140454904243968 [Note] WSREP: evs::proto(62116b35, GATHER, view_id(REG,62116b35,54)) suspected node without join message, declaring inactiveQuindi, Galera rivedrà la visualizzazione del cluster corrente e la posizione di questo nodo:
2018-07-04 16:46:09 140454904243968 [Note] WSREP: view(view_id(NON_PRIM,62116b35,54) memb {
62116b35,0
} joined {
} left {
} partitioned {
737422d6,0
8b2041d6,0
})
2018-07-04 16:46:09 140454904243968 [Note] WSREP: view(view_id(NON_PRIM,62116b35,55) memb {
62116b35,0
} joined {
} left {
} partitioned {
737422d6,0
8b2041d6,0
})Con la nuova visualizzazione cluster, Galera eseguirà il calcolo del quorum per decidere se questo nodo fa parte del componente principale. Se il nuovo componente vede "primary =no", Galera declasserà lo stato del nodo locale da SYNCED a OPEN:
2018-07-04 16:46:09 140454288942848 [Note] WSREP: New COMPONENT: primary = no, bootstrap = no, my_idx = 0, memb_num = 1
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Flow-control interval: [16, 16]
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Trying to continue unpaused monitor
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Received NON-PRIMARY.
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Shifting SYNCED -> OPEN (TO: 2753699)Con l'ultima modifica alla visualizzazione del cluster e allo stato del nodo, Galera restituisce la visualizzazione del cluster post-eliminazione e lo stato globale come di seguito:
2018-07-04 16:46:09 140454222194432 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2753699, view# -1: non-Primary, number of nodes: 1, my index: 0, protocol version 3
2018-07-04 16:46:09 140454222194432 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.Puoi vedere che il seguente stato globale di galera2 è cambiato durante questo periodo:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+
| WSREP_CLUSTER_SIZE | 1 |
| WSREP_CLUSTER_STATUS | non-Primary |
| WSREP_EVS_DELAYED | 737422d6-7db3-11e8-a2a2-bbe98913baf0:tcp://192.168.55.171:4567:1,8b2041d6-7f62-11e8-87d5-12a76678131f:tcp://192.168.55.173:4567:2 |
| WSREP_LOCAL_STATE_COMMENT | Initialized |
| WSREP_READY | OFF |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+A questo punto, il server MySQL/MariaDB su galera2 è ancora accessibile (il database è in ascolto su 3306 e Galera su 4567) ed è possibile interrogare le tabelle di sistema mysql ed elencare i database e le tabelle. Tuttavia, quando salti nelle tabelle non di sistema e fai una semplice query come questa:
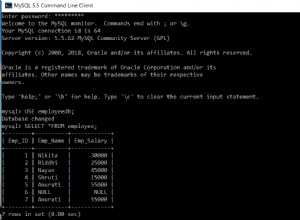
mysql> SELECT * FROM sbtest1;
ERROR 1047 (08S01): WSREP has not yet prepared node for application useRiceverai immediatamente un errore che indica che WSREP è caricato ma non pronto per l'uso da parte di questo nodo, come riportato da wsrep_ready stato. Ciò è dovuto al fatto che il nodo perde la connessione al Componente Primario ed entra nello stato non operativo (lo stato del nodo locale è stato modificato da SYNCED ad OPEN). I dati letti dai nodi in uno stato non operativo sono considerati obsoleti, a meno che non si imposti wsrep_dirty_reads=ON per consentire le letture, sebbene Galera rifiuti comunque qualsiasi comando che modifichi o aggiorni il database.
Infine, Galera continuerà ad ascoltare e a riconnettersi all'infinito con gli altri membri in background:
2018-07-04 16:47:12 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 30
2018-07-04 16:47:13 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 30
2018-07-04 16:48:20 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 60
2018-07-04 16:48:22 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 60Il flusso del processo di sfratto da parte della comunicazione del gruppo Galera per il nodo partizionato durante il problema della rete può essere riassunto come segue:
- Si disconnette dal cluster dopo gmcast.peer_timeout .
- Sospetta altri nodi dopo evs.suspect_timeout .
- Recupera la nuova vista cluster.
- Esegue il calcolo del quorum per determinare lo stato del nodo.
- Declassa il nodo da SYNCED a OPEN.
- Tentativi di riconnettersi al componente principale (altri nodi Galera) in background.
Dalla prospettiva dei componenti primari
Rispettivamente su galera1 e galera3, dopo gmcast.peer_timeout=PT3S , nel log degli errori MySQL viene visualizzato quanto segue:
2018-07-04 16:46:05 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.55.172:4567
2018-07-04 16:46:06 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') reconnecting to 62116b35 (tcp://192.168.55.172:4567), attempt 0Dopo aver superato evs.suspect_timeout =PT5S , galera2 è sospettato di morte da galera3 (e galera1):
2018-07-04 16:46:10 139955510687488 [Note] WSREP: evs::proto(8b2041d6, OPERATIONAL, view_id(REG,62116b35,54)) suspecting node: 62116b35
2018-07-04 16:46:10 139955510687488 [Note] WSREP: evs::proto(8b2041d6, OPERATIONAL, view_id(REG,62116b35,54)) suspected node without join message, declaring inactiveGalera controlla se gli altri nodi rispondono alla comunicazione di gruppo su galera3, scopre che galera1 è in stato primario e stabile:
2018-07-04 16:46:11 139955510687488 [Note] WSREP: declaring 737422d6 at tcp://192.168.55.171:4567 stable
2018-07-04 16:46:11 139955510687488 [Note] WSREP: Node 737422d6 state primGalera rivede la vista cluster di questo nodo (galera3):
2018-07-04 16:46:11 139955510687488 [Note] WSREP: view(view_id(PRIM,737422d6,55) memb {
737422d6,0
8b2041d6,0
} joined {
} left {
} partitioned {
62116b35,0
})
2018-07-04 16:46:11 139955510687488 [Note] WSREP: save pc into diskGalera rimuove quindi il nodo partizionato dal componente primario:
2018-07-04 16:46:11 139955510687488 [Note] WSREP: forgetting 62116b35 (tcp://192.168.55.172:4567)Il nuovo componente primario è ora costituito da due nodi, galera1 e galera3:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 1, memb_num = 2Il componente principale scambierà lo stato tra loro per concordare la nuova visualizzazione del cluster e lo stato globale:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
2018-07-04 16:46:11 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') turning message relay requesting off
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: sent state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: got state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993 from 0 (192.168.55.171)
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: got state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993 from 1 (192.168.55.173)Galera calcola e verifica il quorum dello scambio di stato tra i membri online:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 27,
members = 2/2 (joined/total),
act_id = 2753703,
last_appl. = 2753606,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Flow-control interval: [23, 23]
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Trying to continue unpaused monitorGalera aggiorna la nuova visualizzazione del cluster e lo stato globale dopo lo sfratto di galera2:
2018-07-04 16:46:11 139955214169856 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2753703, view# 28: Primary, number of nodes: 2, my index: 1, protocol version 3
2018-07-04 16:46:11 139955214169856 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2018-07-04 16:46:11 139955214169856 [Note] WSREP: REPL Protocols: 8 (3, 2)
2018-07-04 16:46:11 139955214169856 [Note] WSREP: Assign initial position for certification: 2753703, protocol version: 3
2018-07-04 16:46:11 139956691814144 [Note] WSREP: Service thread queue flushed.
Clean up the partitioned node (galera2) from the active list:
2018-07-04 16:46:14 139955510687488 [Note] WSREP: cleaning up 62116b35 (tcp://192.168.55.172:4567)A questo punto, sia galera1 che galera3 riporteranno uno stato globale simile:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+------------------------------------------------------------------+
| WSREP_CLUSTER_SIZE | 2 |
| WSREP_CLUSTER_STATUS | Primary |
| WSREP_EVS_DELAYED | 1491abd9-7f6d-11e8-8930-e269b03673d8:tcp://192.168.55.172:4567:1 |
| WSREP_LOCAL_STATE_COMMENT | Synced |
| WSREP_READY | ON |
+---------------------------+------------------------------------------------------------------+Elencano il membro problematico in wsrep_evs_delayed stato. Poiché lo stato locale è "Sincronizzato", questi nodi sono operativi ed è possibile reindirizzare le connessioni client da galera2 a uno qualsiasi di essi. Se questo passaggio è scomodo, prendi in considerazione l'utilizzo di un sistema di bilanciamento del carico posizionato davanti al database per semplificare l'endpoint di connessione dai client.
Recupero e unione dei nodi
Un nodo Galera partizionato continuerà a tentare di stabilire una connessione con il componente primario all'infinito. Svuotiamo le regole di iptables su galera2 per consentirgli di connettersi con i nodi rimanenti:
# on galera2
$ iptables -FUna volta che il nodo è in grado di connettersi a uno dei nodi, Galera inizierà a ristabilire automaticamente la comunicazione di gruppo:
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 8b2041d6 tcp://192.168.55.173:4567
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 737422d6 tcp://192.168.55.171:4567
2018-07-09 10:46:34 140075962705664 [Note] WSREP: declaring 737422d6 at tcp://192.168.55.171:4567 stable
2018-07-09 10:46:34 140075962705664 [Note] WSREP: declaring 8b2041d6 at tcp://192.168.55.173:4567 stableIl nodo galera2 si connetterà quindi a uno dei componenti primari (in questo caso è galera1, ID nodo 737422d6) per ottenere la visualizzazione del cluster e lo stato dei nodi correnti:
2018-07-09 10:46:34 140075962705664 [Note] WSREP: Node 737422d6 state prim
2018-07-09 10:46:34 140075962705664 [Note] WSREP: view(view_id(PRIM,1491abd9,142) memb {
1491abd9,0
737422d6,0
8b2041d6,0
} joined {
} left {
} partitioned {
})
2018-07-09 10:46:34 140075962705664 [Note] WSREP: save pc into diskGalera eseguirà quindi lo scambio di stato con il resto dei membri che possono formare la Componente Primaria:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 0, memb_num = 3
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE_EXCHANGE: sent state UUID: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: sent state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 0 (192.168.55.172)
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 1 (192.168.55.171)
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 2 (192.168.55.173)Lo scambio di stato consente a galera2 di calcolare il quorum e produrre il seguente risultato:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 71,
members = 2/3 (joined/total),
act_id = 2836958,
last_appl. = 0,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bcGalera promuoverà quindi lo stato del nodo locale da OPEN a PRIMARY, per avviare e stabilire la connessione del nodo al Componente primario:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Trying to continue unpaused monitor
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Shifting OPEN -> PRIMARY (TO: 2836958)Come riportato dalla riga sopra, Galera calcola il divario su quanto dista il nodo dal cluster. Questo nodo richiede il trasferimento di stato per raggiungere il numero di writeset 2836958 da 2761994:
2018-07-09 10:46:34 140075929970432 [Note] WSREP: State transfer required:
Group state: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
Local state: 55238f52-41ee-11e8-852f-3316bdb654bc:2761994
2018-07-09 10:46:34 140075929970432 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958, view# 72: Primary, number of nodes:
3, my index: 0, protocol version 3
2018-07-09 10:46:34 140075929970432 [Warning] WSREP: Gap in state sequence. Need state transfer.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: REPL Protocols: 8 (3, 2)
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Assign initial position for certification: 2836958, protocol version: 3Galera prepara il listener IST sulla porta 4568 su questo nodo e chiede a qualsiasi nodo sincronizzato nel cluster di diventare un donatore. In questo caso, Galera seleziona automaticamente galera3 (192.168.55.173), oppure potrebbe anche scegliere un donatore dall'elenco in wsrep_sst_donar (se definito) per l'operazione di sincronizzazione:
2018-07-09 10:46:34 140075996276480 [Note] WSREP: Service thread queue flushed.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: IST receiver addr using tcp://192.168.55.172:4568
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Prepared IST receiver, listening at: tcp://192.168.55.172:4568
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Member 0.0 (192.168.55.172) requested state transfer from '*any*'. Selected 2.0 (192.168.55.173)(SYNCED) as donor.Quindi cambierà lo stato del nodo locale da PRIMARY a JOINER. A questo punto, galera2 riceve la richiesta di trasferimento dello stato e inizia a memorizzare nella cache i set di scrittura:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Shifting PRIMARY -> JOINER (TO: 2836958)
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Requesting state transfer: success, donor: 2
2018-07-09 10:46:34 140075929970432 [Note] WSREP: GCache history reset: 55238f52-41ee-11e8-852f-3316bdb654bc:2761994 -> 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
2018-07-09 10:46:34 140075929970432 [Note] WSREP: GCache DEBUG: RingBuffer::seqno_reset(): full resetIl nodo galera2 inizia a ricevere i set di scrittura mancanti dalla gcache del donatore selezionato (galera3):
2018-07-09 10:46:34 140075954312960 [Note] WSREP: 2.0 (192.168.55.173): State transfer to 0.0 (192.168.55.172) complete.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Receiving IST: 74964 writesets, seqnos 2761994-2836958
2018-07-09 10:46:34 140075593627392 [Note] WSREP: Receiving IST... 0.0% ( 0/74964 events) complete.
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Member 2.0 (192.168.55.173) synced with group.
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 737422d6 tcp://192.168.55.171:4567
2018-07-09 10:46:41 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') turning message relay requesting off
2018-07-09 10:46:44 140075593627392 [Note] WSREP: Receiving IST... 36.0% (27008/74964 events) complete.
2018-07-09 10:46:54 140075593627392 [Note] WSREP: Receiving IST... 71.6% (53696/74964 events) complete.
2018-07-09 10:47:02 140075593627392 [Note] WSREP: Receiving IST...100.0% (74964/74964 events) complete.
2018-07-09 10:47:02 140075929970432 [Note] WSREP: IST received: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
2018-07-09 10:47:02 140075954312960 [Note] WSREP: 0.0 (192.168.55.172): State transfer from 2.0 (192.168.55.173) complete.Una volta ricevute e applicate tutte le scritture mancanti, Galera promuoverà galera2 come JOINED fino al seqno 2837012:
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Shifting JOINER -> JOINED (TO: 2837012)
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Member 0.0 (192.168.55.172) synced with group.Il nodo applica tutti i set di scrittura memorizzati nella cache nella sua coda slave e finisce di recuperare il ritardo con il cluster. La sua coda di slave è ora vuota. Galera promuoverà galera2 a SYNCED, indicando che il nodo è ora operativo e pronto a servire i clienti:
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Shifting JOINED -> SYNCED (TO: 2837012)
2018-07-09 10:47:02 140076605892352 [Note] WSREP: Synchronized with group, ready for connectionsA questo punto, tutti i nodi sono tornati operativi. Puoi verificare utilizzando le seguenti istruzioni su galera2:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+----------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+----------------+
| WSREP_CLUSTER_SIZE | 3 |
| WSREP_CLUSTER_STATUS | Primary |
| WSREP_EVS_DELAYED | |
| WSREP_LOCAL_STATE_COMMENT | Synced |
| WSREP_READY | ON |
+---------------------------+----------------+Il wsrep_cluster_size riportato come 3 e lo stato del cluster è Primario, a indicare che galera2 fa parte del componente primario. Il wsrep_evs_delayed è stato anche cancellato e lo stato locale è ora sincronizzato.
Il flusso del processo di ripristino per il nodo partizionato durante il problema della rete può essere riepilogato come segue:
- Ristabilisce la comunicazione di gruppo con altri nodi.
- Recupera la vista del cluster da uno dei componenti primari.
- Esegue lo scambio di stato con il Componente principale e calcola il quorum.
- Cambia lo stato del nodo locale da OPEN a PRIMARY.
- Calcola il divario tra il nodo locale e il cluster.
- Cambia lo stato del nodo locale da PRIMARY a JOINER.
- Prepara il listener/ricevitore IST sulla porta 4568.
- Richiede il trasferimento statale tramite IST e sceglie un donatore.
- Inizia a ricevere e applicare il writeset mancante dalla gcache del donatore scelto.
- Cambia lo stato del nodo locale da JOINER a JOINED.
- Resta al passo con il cluster applicando i set di scrittura memorizzati nella cache nella coda slave.
- Cambia lo stato del nodo locale da JOINED a SYNCED.
Guasto cluster
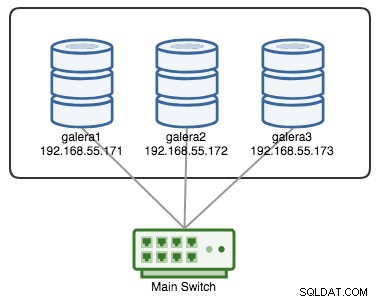
Un Cluster Galera è considerato guasto se non è disponibile alcun componente primario (PC). Considera un cluster Galera a tre nodi simile come illustrato nel diagramma seguente:
Un cluster è considerato operativo se tutti i nodi o la maggior parte dei nodi sono online. Online significa che sono in grado di vedersi attraverso il traffico di replica di Galera o la comunicazione di gruppo. Se nessun traffico entra e esce dal nodo, il cluster invierà un beacon heartbeat affinché il nodo risponda in modo tempestivo. In caso contrario, verrà inserito nell'elenco dei ritardi o dei sospetti in base a come risponde il nodo.
Se un nodo si interrompe, diciamo il nodo C, il cluster rimarrà operativo perché i nodi A e B sono ancora in quorum con 2 voti su 3 per formare un componente primario. Dovresti ottenere il seguente stato del cluster su A e B:
mysql> SHOW STATUS LIKE 'wsrep_cluster_status';
+----------------------+---------+
| Variable_name | Value |
+----------------------+---------+
| wsrep_cluster_status | Primary |
+----------------------+---------+Se diciamo che un interruttore principale è andato kaput, come illustrato nel diagramma seguente:
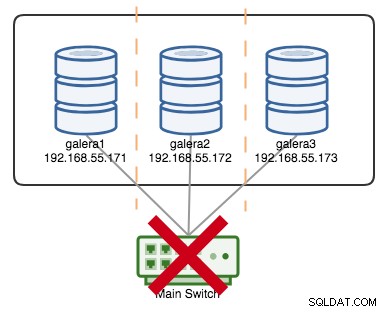
A questo punto, ogni singolo nodo perde la comunicazione tra loro e lo stato del cluster verrà segnalato come non Primario su tutti i nodi (come è successo a galera2 nel caso precedente). Ogni nodo calcolerebbe il quorum e scoprirebbe che è la minoranza (1 voto su 3) perdendo così il quorum, il che significa che non si forma alcun Componente Primario e di conseguenza tutti i nodi si rifiutano di servire qualsiasi dato. Questo è considerato un errore del cluster.
Una volta risolto il problema della rete, Galera ristabilirà automaticamente la comunicazione tra i membri, scambierà gli stati del nodo e determinerà la possibilità di riformare il componente primario confrontando lo stato del nodo, UUID e seqno. Se la probabilità è presente, Galera unirà i componenti primari come mostrato nelle righe seguenti:
2018-06-27 0:16:57 140203784476416 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 2, memb_num = 3
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: sent state msg: 5885911b-795c-11e8-8683-931c85442c7e
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 0 (192.168.55.171)
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 1 (192.168.55.172)
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 2 (192.168.55.173)
2018-06-27 0:16:57 140203784476416 [Warning] WSREP: Quorum: No node with complete state:
Version : 4
Flags : 0x3
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.171'
Incoming addr: '192.168.55.171:3306'
Version : 4
Flags : 0x2
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.172'
Incoming addr: '192.168.55.172:3306'
Version : 4
Flags : 0x2
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.173'
Incoming addr: '192.168.55.173:3306'
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Full re-merge of primary 5224a024-791b-11e8-a0ac-8bc6118b0f96 found: 3 of 3.
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 5,
members = 3/3 (joined/total),
act_id = 112725,
last_appl. = 112722,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Flow-control interval: [28, 28]
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Trying to continue unpaused monitor
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Restored state OPEN -> SYNCED (112725)
2018-06-27 0:16:57 140202564110080 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:112725, view# 6: Primary, number of nodes: 3, my index: 2, protocol version 3A good indicator to know if the re-bootstrapping process is OK is by looking at the following line in the error log:
[Note] WSREP: Synchronized with group, ready for connectionsClusterControl Auto Recovery
ClusterControl comes with node and cluster automatic recovery features, because it oversees and understands the state of all nodes in the cluster. Automatic recovery is by default enabled if the cluster is deployed using ClusterControl. To enable or disable the cluster, simply clicking on the power icon in the summary bar as shown below:

Green icon means automatic recovery is turned on, while red is the opposite. You can monitor the recovery progress from the Activity -> Jobs dialog, like in this case, galera2 was totally inaccessible due to firewall blocking, thus forcing ClusterControl to report the following:
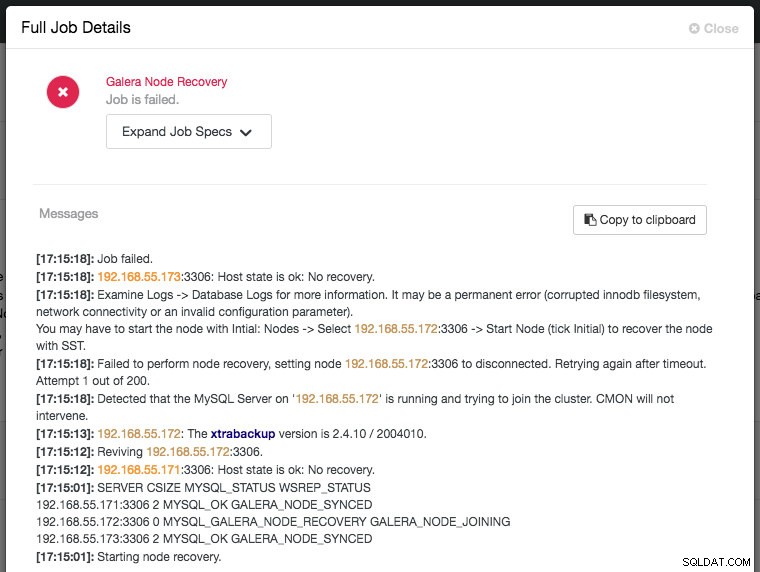
The recovery process will only be commencing after a graceful timeout (30 seconds) to give Galera node a chance to recover itself beforehand. If ClusterControl fails to recover a node or cluster, it will first pull all MySQL error logs from all accessible nodes and will raise the necessary alarms to notify the user via email or by pushing critical events to the third-party integration modules like PagerDuty, VictorOps or Slack. Manual intervention is then required. For Galera Cluster, ClusterControl will keep on trying to recover the failure until you mark the node as under maintenance, or disable the automatic recovery feature.
ClusterControl's automatic recovery is one of most favorite features as voted by our users. It helps you to take the necessary actions quickly, with a complete report on what has been attempted and recommendation steps to troubleshoot further on the issue. For users with support subscriptions, you can look for extra hands by escalating this issue to our technical support team for assistance.
Conclusione
Galera automatic node recovery and membership control are neat features to simplify the cluster management, improve the database reliability and reduce the risk of human error, as commonly haunting other open-source database replication technology like MySQL Replication, Group Replication and PostgreSQL Streaming/Logical Replication.