Questo articolo è la quinta parte di una serie su bug, insidie e best practice di T-SQL. In precedenza mi occupavo di determinismo, subquery, join e windowing. Questo mese mi occupo di pivoting e unpivoting. Grazie Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man e Paul White per aver condiviso i tuoi suggerimenti!
Nei miei esempi, userò un database di esempio chiamato TSQLV5. Puoi trovare lo script che crea e popola questo database qui e il suo diagramma ER qui.
Raggruppamento implicito con PIVOT
Quando le persone desiderano eseguire il pivot dei dati utilizzando T-SQL, utilizzano una soluzione standard con una query raggruppata ed espressioni CASE o l'operatore di tabella PIVOT proprietario. Il vantaggio principale dell'operatore PIVOT è che tende a produrre un codice più breve. Tuttavia, questo operatore presenta alcune carenze, tra cui una trappola di progettazione intrinseca che può causare bug nel codice. Qui descriverò la trappola, il potenziale bug e una best practice che previene il bug. Descriverò anche un suggerimento per migliorare la sintassi dell'operatore PIVOT in modo da evitare il bug.
Quando esegui il pivot dei dati, nella soluzione sono coinvolti tre passaggi, con tre elementi associati:
- Gruppo basato su un elemento di raggruppamento/su righe
- Spread basato su un elemento spread/su colonne
- Aggregare in base a un elemento di aggregazione/dati
Di seguito è riportata la sintassi dell'operatore PIVOT:
SELECTDA PIVOT( ( ) FOR IN( ) ) AS ;
La progettazione dell'operatore PIVOT richiede di specificare in modo esplicito gli elementi di aggregazione e diffusione, ma consente a SQL Server di calcolare in modo implicito l'elemento di raggruppamento mediante eliminazione. Qualunque colonna compaia nella tabella di origine fornita come input per l'operatore PIVOT, diventa implicitamente l'elemento di raggruppamento.
Si supponga ad esempio di voler eseguire una query sulla tabella Sales.Orders nel database di esempio TSQLV5. Vuoi restituire gli ID mittente sulle righe, gli anni di spedizione sulle colonne e il conteggio degli ordini per mittente e anno come aggregato.
Molte persone hanno difficoltà a capire la sintassi dell'operatore PIVOT e questo spesso porta a raggruppare i dati per elementi indesiderati. Ad esempio con il nostro compito, supponiamo che non ti rendi conto che l'elemento di raggruppamento è determinato in modo implicito e ti viene in mente la seguente query:
SELECT shipperid, [2017], [2018], [2019]DA Sales.Orders APPLICA CROSS( VALUES(YEAR(shippeddate)) ) AS D(shippedyear) PIVOT( COUNT(shippeddate) FOR shippingyear IN([2017] , [2018], [2019]) ) ASP;
Nei dati sono presenti solo tre spedizionieri, con ID mittente 1, 2 e 3. Quindi ti aspetti di vedere solo tre righe nel risultato. Tuttavia, l'output effettivo della query mostra molte più righe:
shipperid 2017 2018 2019----------- ----------- ----------- ---------- -3 1 0 01 1 0 02 1 0 01 1 0 02 1 0 02 1 0 02 1 0 03 1 0 02 1 0 03 1 0 0...3 0 1 03 0 1 03 0 1 01 0 1 03 0 1 01 0 1 03 0 1 03 0 1 03 0 1 01 0 1 0...3 0 0 11 0 0 12 0 0 11 0 0 12 0 0 11 0 0 13 0 0 13 0 0 12 0 1 0...(830 righe interessate)
Cosa è successo?
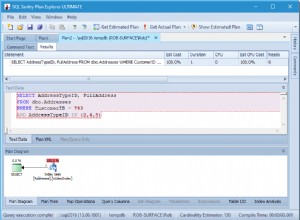
Puoi trovare un indizio che ti aiuterà a capire il bug nel codice osservando il piano di query mostrato nella Figura 1.
 Figura 1:piano per query pivot con raggruppamento implicito
Figura 1:piano per query pivot con raggruppamento implicito
Non lasciare che l'uso dell'operatore CROSS APPLY con la clausola VALUES nella query ti confonda. Questo viene fatto semplicemente per calcolare la colonna del risultato anno di spedizione in base alla colonna data di spedizione di origine ed è gestito dal primo operatore di calcolo scalare nel piano.
La tabella di input per l'operatore PIVOT contiene tutte le colonne della tabella Sales.Orders, più la colonna dei risultati anno spedito. Come accennato, SQL Server determina l'elemento di raggruppamento in modo implicito mediante eliminazione in base a ciò che non è stato specificato come elementi di aggregazione (data di spedizione) e diffusione (anno di spedizione). Forse ti aspettavi intuitivamente che la colonna shipperid fosse la colonna di raggruppamento perché appare nell'elenco SELECT, ma come puoi vedere nel piano, in pratica hai un elenco di colonne molto più lungo, incluso orderid, che è la colonna della chiave primaria in la tabella di origine. Ciò significa che invece di ottenere una riga per mittente, stai ricevendo una riga per ordine. Poiché nell'elenco SELECT hai specificato solo le colonne shipperid, [2017], [2018] e [2019], non vedi il resto, il che si aggiunge alla confusione. Ma il resto ha preso parte al raggruppamento implicito.
Ciò che potrebbe essere fantastico è se la sintassi dell'operatore PIVOT supportasse una clausola in cui è possibile indicare esplicitamente l'elemento raggruppamento/su righe. Qualcosa del genere:
SELECTDA PIVOT( ( ) PER IN( ) SU RIGHE ) AS ;
Sulla base di questa sintassi utilizzeresti il seguente codice per gestire il nostro compito:
SELECT shipperid, [2017], [2018], [2019]DA Sales.Orders APPLICA CROSS( VALUES(YEAR(shippeddate)) ) AS D(shippedyear) PIVOT( COUNT(shippeddate) FOR shippingyear IN([2017] , [2018], [2019]) ON ROWS shipperid ) ASP;
Puoi trovare un elemento di feedback con un suggerimento per migliorare la sintassi dell'operatore PIVOT qui. Per rendere questo miglioramento una modifica univoca, questa clausola può essere resa facoltativa, con l'impostazione predefinita che è il comportamento esistente. Ci sono altri suggerimenti per migliorare la sintassi dell'operatore PIVOT rendendolo più dinamico e supportando più aggregati.
Nel frattempo, c'è una best practice che può aiutarti a evitare il bug. Utilizzare un'espressione di tabella come un CTE o una tabella derivata in cui si proiettano solo i tre elementi che devono essere coinvolti nell'operazione pivot, quindi utilizzare l'espressione di tabella come input per l'operatore PIVOT. In questo modo, controlli completamente l'elemento di raggruppamento. Ecco la sintassi generale che segue questa procedura consigliata:
CONAS( SELECT , , DA )SELECT DA PIVOT( ( ) FOR IN( ) ) AS ;
Applicato al nostro compito, utilizzi il seguente codice:
CON C AS( SELECT shipperid, YEAR(shippeddate) AS shippingyear, shippingdate FROM Sales.Orders)SELECT shipperid, [2017], [2018], [2019]DA C PIVOT( COUNT(shippeddate) FOR shippingyear IN([ 2017], [2018], [2019]) ) ASP;
Questa volta ottieni solo tre righe di risultati come previsto:
shipperid 2017 2018 2019----------- ----------- ----------- ---------- -3 51 125 731 36 130 792 56 143 116
Un'altra opzione consiste nell'utilizzare la vecchia e classica soluzione standard per il pivot utilizzando una query raggruppata e le espressioni CASE, in questo modo:
SELECT shipperid, COUNT(CASE QUANDO speditoanno =2017 THEN 1 END) AS [2017], COUNT(CASE QUANDO speditoanno =2018 THEN 1 END) AS [2018], COUNT(CASE QUANDO speditoanno =2019 THEN 1 END) AS [2019]DA Sales.Ordini APPLICAZIONE INCROCIATA( VALUES(YEAR(shippeddate)) ) COME D(shippedyear)WHOVE la data di spedizione NON È NULLGROUP BY shipperid;
Con questa sintassi tutti e tre i passaggi pivot e i relativi elementi associati devono essere espliciti nel codice. Tuttavia, quando si dispone di un numero elevato di valori di diffusione, questa sintassi tende a essere dettagliata. In questi casi, le persone spesso preferiscono utilizzare l'operatore PIVOT.
Rimozione implicita di NULL con UNPIVOT
L'elemento successivo in questo articolo è più una trappola che un bug. Ha a che fare con l'operatore T-SQL UNPIVOT proprietario, che ti consente di annullare il pivot dei dati da uno stato di colonne a uno stato di righe.
Userò una tabella chiamata CustOrders come dati di esempio. Usa il codice seguente per creare, popolare e interrogare questa tabella per mostrarne il contenuto:
DROP TABLE IF EXISTS dbo.CustOrders;GO WITH C AS( SELECT custid, YEAR(orderdate) AS orderyearyear, val FROM Sales.OrderValues)SELECT custid, [2017], [2018], [2019]INTO dbo.CustOrdersDA C PIVOT( SUM(val) FOR orderyear IN([2017], [2018], [2019]) ) AS P; SELEZIONA * DA dbo.CustOrders;
Questo codice genera il seguente output:
custid 2017 2018 2019------- ---------- ---------- ----------1 NULL 2022.50 2250.502 88.80 799.75 514.403 403.20 5960.78 660.004 1379.00 6406.90 5604.755 4324.40 13849.02 6754.166 NULL 1079.80 2160.007 9986.20 7817.88 730.008 982.00 3026.85 224.009 4074.28 11208.36 6680.6110 1832.80 7630.25 11338.5611 479.40 3179.50 2431.0012 NULL 238.00 1576.8013 100.80 NULL NULL14 1674.22 6516.40 4158.2615 2169.00 1128.00 513.7516 NULL 787.60 931.5017 533.60 420.00 2809.6118 268.80 487.00 860.1019 950.00 4514.35 9296.6920 15568.07 48096.27 41210.65...
Questa tabella contiene i valori totali degli ordini per cliente e anno. I NULL rappresentano i casi in cui un cliente non ha avuto alcuna attività di ordine nell'anno target.
Si supponga di voler annullare il pivot dei dati dalla tabella CustOrders, restituendo una riga per cliente e anno, con una colonna di risultati denominata val che contiene il valore totale dell'ordine per il cliente e l'anno correnti. Qualsiasi attività unpivoting generalmente coinvolge tre elementi:
- I nomi delle colonne di origine esistenti di cui stai annullando il pivot:[2017], [2018], [2019] nel nostro caso
- Un nome che assegni alla colonna di destinazione che conterrà i nomi delle colonne di origine:orderyear nel nostro caso
- Un nome che assegni alla colonna di destinazione che conterrà i valori della colonna di origine:val nel nostro caso
Se decidi di utilizzare l'operatore UNPIVOT per gestire l'attività unpivot, devi prima capire i tre elementi precedenti, quindi utilizzare la seguente sintassi:
SELECT, , DA UNPIVOT( FOR IN( ) ) AS ;
Applicato al nostro compito, utilizzi la seguente query:
SELECT custid, orderyear, valFROM dbo.CustOrders UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) ) AS U;
Questa query genera il seguente output:
ordine custodiaanno val------- ---------- ----------1 2018 2022.501 2019 2250.502 2017 88.802 2018 799.752 2019 514.403 2017 403.203 2018 5960.906 60 2017 1379.004 2018 6406.904 2019 5604.755 2017 4324.405 2018 13849.025 2019 6754.166 2018 1079.806 2019 2160.007 2017 9986.207 2018 7817.887 2019 730.00 ...Osservando i dati di origine e il risultato della query, noti cosa manca?
La progettazione dell'operatore UNPIVOT implica un'eliminazione implicita delle righe dei risultati che hanno un NULL nella colonna dei valori, nel nostro caso val. Osservando il piano di esecuzione per questa query mostrato nella Figura 2, puoi vedere l'operatore Filter che rimuove le righe con NULL nella colonna val (Expr1007 nel piano).
Figura 2:piano per query unpivot con rimozione implicita di NULL
A volte questo comportamento è desiderabile, nel qual caso non è necessario fare nulla di speciale. Il problema è che a volte vuoi mantenere le righe con i NULL. Il trabocchetto è quando vuoi mantenere i NULL e non ti rendi nemmeno conto che l'operatore UNPIVOT è progettato per rimuoverli.
Ciò che potrebbe essere fantastico è se l'operatore UNPIVOT avesse una clausola facoltativa che ti consentisse di specificare se desideri rimuovere o mantenere i NULL, con il primo che è l'impostazione predefinita per la compatibilità con le versioni precedenti. Ecco un esempio di come potrebbe apparire questa sintassi:
SELECT, , DA UNPIVOT( FOR IN( ) [REMOVE NULLS | KEEP NULLS] ) AS ; Se volessi mantenere i NULL, in base a questa sintassi utilizzeresti la seguente query:
SELECT custid, orderyear, valFROM dbo.CustOrders UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) KEEP NULLS ) AS U;Puoi trovare un elemento di feedback con un suggerimento per migliorare la sintassi dell'operatore UNPIVOT in questo modo qui.
Nel frattempo, se vuoi mantenere le righe con i NULL, devi trovare una soluzione alternativa. Se insisti nell'utilizzare l'operatore UNPIVOT, devi applicare due passaggi. Nel primo passaggio si definisce un'espressione di tabella basata su una query che utilizza la funzione ISNULL o COALESCE per sostituire i NULL in tutte le colonne non pivot con un valore che normalmente non può apparire nei dati, ad esempio -1 nel nostro caso. Nel secondo passaggio si utilizza la funzione NULLIF nella query esterna rispetto alla colonna dei valori per sostituire il -1 indietro con un NULL. Ecco il codice completo della soluzione:
CON C AS( SELECT custid, ISNULL([2017], -1.0) AS [2017], ISNULL([2018], -1.0) AS [2018], ISNULL([2019], -1.0) AS [2019 ] FROM dbo.CustOrders)SELECT custid, orderyear, NULLIF(val, -1.0) AS valFROM C UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) ) AS U;Ecco l'output di questa query che mostra che le righe con NULL nella colonna val vengono mantenute:
ordine deposito val. 2019 660.004 2017 1379.004 2018 6406.904 2019 5604.755 2017 4324.405 2018 13849.025 2019 6754.166 2017 null6 2018 1079.806 2019 2160.007 2017 9986.207 7817.887 2019 ...Questo approccio è scomodo, soprattutto quando hai un numero elevato di colonne da annullare.
Una soluzione alternativa utilizza una combinazione dell'operatore APPLY e della clausola VALUES. Costruisci una riga per ogni colonna non pivot, con una colonna che rappresenta la colonna dei nomi di destinazione (orderyear nel nostro caso) e un'altra che rappresenta la colonna dei valori di destinazione (val nel nostro caso). Fornisci l'anno costante per la colonna dei nomi e la colonna di origine correlata pertinente per la colonna dei valori. Ecco il codice completo della soluzione:
SELECT custid, orderyear, valFROM dbo.CustOrders CROSS APPLY ( VALUES(2017, [2017]), (2018, [2018]), (2019, [2019]) ) AS A(orderyear, val);La cosa bella qui è che, a meno che tu non sia interessato alla rimozione delle righe con i NULL nella colonna val, non devi fare nulla di speciale. Non esiste un passaggio implicito qui che rimuove le righe con NULLS. Inoltre, poiché l'alias della colonna val viene creato come parte della clausola FROM, è accessibile alla clausola WHERE. Quindi, se sei interessato alla rimozione dei NULL, puoi essere esplicito al riguardo nella clausola WHERE interagendo direttamente con l'alias della colonna dei valori, in questo modo:
SELECT custid, orderyear, valFROM dbo.CustOrders CROSS APPLY ( VALUES(2017, [2017]), (2018, [2018]), (2019, [2019]) ) AS A(orderyear, val)WHERE val IS NON NULLA;Il punto è che questa sintassi ti dà il controllo se vuoi mantenere o rimuovere i NULL. È più flessibile dell'operatore UNPIVOT in un altro modo, consentendoti di gestire più misure non pivotate come val e qty. Il mio obiettivo in questo articolo era però l'insidia che coinvolge i NULL, quindi non sono entrato in questo aspetto.
Conclusione
La progettazione degli operatori PIVOT e UNPIVOT a volte porta a bug e insidie nel codice. La sintassi dell'operatore PIVOT non consente di indicare esplicitamente l'elemento di raggruppamento. Se non te ne rendi conto, puoi ritrovarti con elementi di raggruppamento indesiderati. Come best practice, si consiglia di utilizzare un'espressione di tabella come input per l'operatore PIVOT, e per questo motivo controllare esplicitamente qual è l'elemento di raggruppamento.
La sintassi dell'operatore UNPIVOT non ti consente di controllare se rimuovere o mantenere le righe con NULL nella colonna dei valori dei risultati. Come soluzione alternativa, puoi utilizzare una soluzione scomoda con le funzioni ISNULL e NULLIF oppure una soluzione basata sull'operatore APPLY e sulla clausola VALUES.
Ho anche menzionato due elementi di feedback con suggerimenti per migliorare gli operatori PIVOT e UNPIVOT con opzioni più esplicite per controllare il comportamento dell'operatore e dei suoi elementi.