Introduzione
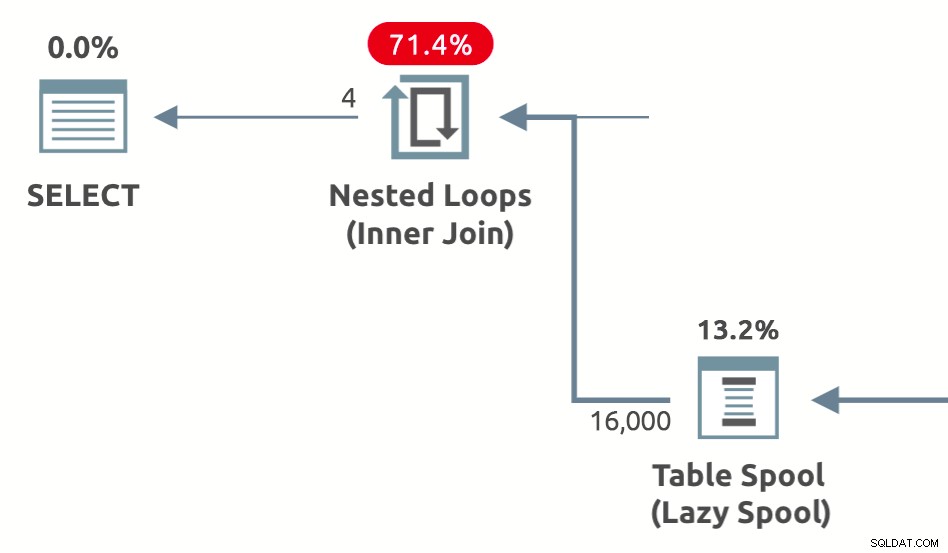
Bobine di prestazioni sono spool pigri aggiunti dall'ottimizzatore per ridurre il costo stimato del lato interno di unisci loop nidificati . Sono disponibili in tre varietà:Lazy Table Spool , Spool indice pigro e Spool conteggio righe pigro . Di seguito è riportato un esempio di forma del piano che mostra uno spool di prestazioni di una tabella pigra:
Le domande a cui ho deciso di rispondere in questo articolo sono perché, come e quando Query Optimizer introduce ogni tipo di spooling delle prestazioni.
Poco prima di iniziare, voglio sottolineare un punto importante:ci sono due tipi distinti di nidificati loop join nei piani di esecuzione. Mi riferirò alla varietà con riferimenti esterni come richiesta e il tipo con un predicato join sull'operatore di join stesso come unione di loop nidificati . Per essere chiari, questa differenza riguarda gli operatori del piano di esecuzione , non la sintassi della query T-SQL. Per maggiori dettagli, vedere il mio articolo collegato.
Spool di prestazioni
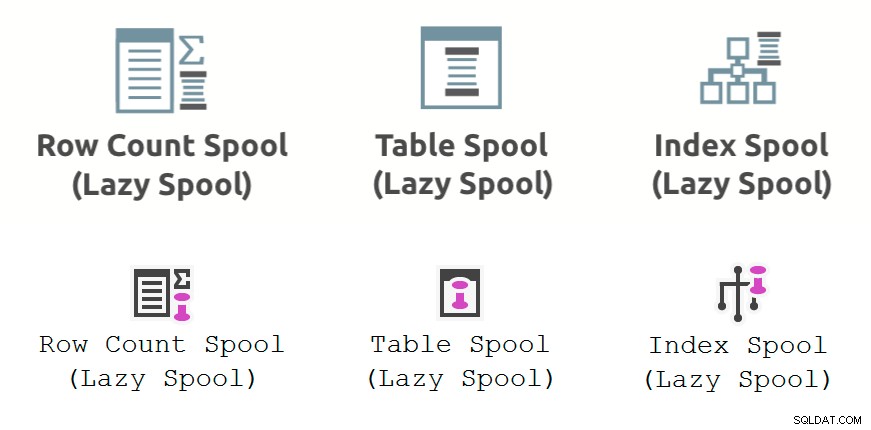
L'immagine sotto mostra la bobina di prestazioni operatori del piano di esecuzione visualizzati in Plan Explorer (riga superiore) e SSMS 18.3 (riga inferiore):
Osservazioni generali
Tutte le bobine di prestazioni sono pigri . Il piano di lavoro della bobina viene gradualmente popolato, una riga alla volta, mentre le righe scorrono attraverso la bobina. (Gli spool desiderosi, al contrario, consumano tutto l'input dal loro operatore figlio prima di restituire qualsiasi riga al loro genitore).
Gli spool delle prestazioni appaiono sempre sul lato interno (l'input inferiore nei piani di esecuzione grafici) di un operatore join o apply di cicli nidificati. L'idea generale è quella di memorizzare nella cache e riprodurre i risultati, salvando, ove possibile, esecuzioni ripetute di operatori interni.
Quando uno spool è in grado di riprodurre i risultati memorizzati nella cache, questo è noto come riavvolgimento . Quando lo spool deve eseguire i suoi operatori figlio per ottenere dati corretti, un rebind si verifica.
Potresti trovare utile pensare a uno spool rebind come un errore di cache e un riavvolgimento come cache hit.
Lazy Table Spool
Questo tipo di bobina di prestazioni può essere utilizzata con entrambi applica e i loop nidificati si uniscono .
Applica
Un rilegatura (cache miss) si verifica ogni volta che un riferimento esterno cambia il valore. Una bobina di una tabella pigra si ricollega troncando il suo tavolo di lavoro e ripopolandolo completamente dai suoi operatori figli.
Un riavvolgi (cache hit) si verifica quando il lato interno viene eseguito con lo stesso valori di riferimento esterni come immediatamente precedente iterazione del ciclo. Un riavvolgimento riproduce i risultati memorizzati nella cache dal piano di lavoro della bobina, risparmiando il costo di rieseguire gli operatori del piano sotto la bobina.
Nota:uno spool lazy table memorizza nella cache solo i risultati per un set di applica riferimento esterno valori alla volta.
Unisciti ai loop nidificati
Lo spool della tabella pigra viene popolato una volta durante la prima iterazione del ciclo. Lo spool riavvolge il suo contenuto per ogni successiva iterazione del join. Con il join di loop nidificato, il lato interno del join è un insieme statico di righe perché il predicato del join si trova sul join stesso. Il set di righe interno statico può quindi essere memorizzato nella cache e riutilizzato più volte tramite lo spool. Un loop nidificato si unisce allo spool delle prestazioni non si ricollega mai.
Spool conteggio righe pigro
Uno spool di conteggio righe è poco più di uno Spool di tabella senza colonne. Memorizza nella cache l'esistenza di una riga, ma non proietta dati di colonna. A parte notare la sua esistenza e menzionare che può essere un'indicazione di un errore nella query di origine, non avrò altro da dire sugli spool di conteggio delle righe.
Da questo momento in poi, ogni volta che vedi "spool di tabella" nel testo, leggilo come "spool di tabella (o conteggio righe)" perché sono così simili.
Spool indice pigro
Lo Spool di indice pigro l'operatore è disponibile solo con applica .
La bobina dell'indice mantiene una tabella di lavoro che non è troncata quando riferimento esterno i valori cambiano. Al contrario, i nuovi dati vengono aggiunti alla cache esistente, indicizzata dai valori di riferimento esterni. Uno spool di indice pigro differisce da uno spool di tabella pigro in quanto può riprodurre i risultati da qualsiasi iterazione del ciclo precedente, non solo quella più recente.
Il passaggio successivo per comprendere quando gli spool delle prestazioni vengono visualizzati nei piani di esecuzione richiede di comprendere un po' come funziona l'ottimizzatore.
Sfondo di Optimizer
Una query di origine viene convertita in una rappresentazione ad albero logico mediante analisi, algebrizzazione, semplificazione e normalizzazione. Quando l'albero risultante non si qualifica per un piano banale, l'ottimizzatore basato sui costi cerca alternative logiche che garantiscano gli stessi risultati, ma a un costo stimato inferiore.
Una volta che l'ottimizzatore ha generato potenziali alternative, le implementa ciascuna utilizzando gli operatori fisici appropriati e calcola i costi stimati. Il piano di esecuzione finale si basa sull'opzione di costo più bassa trovata per ciascun gruppo di operatori. Puoi leggere maggiori dettagli sul processo nella mia serie di approfondimenti su Query Optimizer.
Le condizioni generali necessarie affinché uno spool di prestazioni appaia nel piano finale dell'ottimizzatore sono:
- L'ottimizzatore deve esplorare un'alternativa logica che include uno spool logico in un sostituto generato. Questo è più complesso di quanto sembri, quindi scompatterò i dettagli nella prossima sezione principale.
- Lo spool logico deve essere implementabile come bobina fisica operatore nel motore di esecuzione. Per le versioni moderne di SQL Server, ciò significa essenzialmente che tutte le colonne chiave in uno spool di indice devono essere comparabili tipo, non più di 900 byte* in totale, con 64 colonne chiave o meno.
- Il migliore il piano completo dopo l'ottimizzazione basata sui costi deve includere una delle alternative di spool. In altre parole, qualsiasi scelta basata sui costi tra le opzioni spool e non spool deve risultare a favore dello spool.
* Questo valore è hardcoded in SQL Server e non è stato modificato in seguito all'aumento a 1700 byte per non cluster chiavi di indice da SQL Server 2016 in poi. Questo perché l'indice di spool è un cluster indice, non un indice non cluster.
Regole di Optimizer
Non è possibile specificare uno spool utilizzando T-SQL, quindi ottenerne uno in un piano di esecuzione significa che l'ottimizzatore deve scegliere di aggiungerlo. Come primo passo, ciò significa che l'ottimizzatore deve includere uno spool logico in una delle alternative che sceglie di esplorare.
L'ottimizzatore non applica in modo esaustivo tutte le regole di equivalenza logica che conosce a ogni albero di query. Questo sarebbe uno spreco, dato l'obiettivo dell'ottimizzatore di produrre rapidamente un piano ragionevole. Ci sono molteplici aspetti in questo. In primo luogo, l'ottimizzatore procede per fasi, con regole più economiche e più spesso applicabili provate per prime. Se viene trovato un piano ragionevole in una fase iniziale, o la query non si qualifica per le fasi successive, lo sforzo di ottimizzazione potrebbe terminare anticipatamente con il piano con il costo più basso trovato finora. Questa strategia aiuta a evitare di dedicare più tempo all'ottimizzazione di quanto non venga risparmiato da miglioramenti incrementali dei costi.
Corrispondenza delle regole
Ogni operatore logico nell'albero delle query viene rapidamente verificato per una corrispondenza del modello rispetto alle regole disponibili nella fase di ottimizzazione corrente. Ad esempio, ogni regola corrisponderà solo a un sottoinsieme di operatori logici e potrebbe anche richiedere la presenza di proprietà specifiche, come l'input ordinato garantito. Una regola può corrispondere a una singola operazione logica (un singolo gruppo) oa più gruppi contigui (una sottosezione del piano).
Una volta abbinata, a una regola candidata viene chiesto di generare un valore di promessa . Si tratta di un numero che rappresenta la probabilità che la norma attuale produca un risultato utile, dato il contesto locale. Ad esempio, una regola potrebbe generare un valore di promessa più alto quando la destinazione ha molti duplicati nel suo input, un numero stimato di righe elevato, un input ordinato garantito o qualche altra proprietà desiderabile.
Una volta identificate le regole di esplorazione promettenti, l'ottimizzatore le ordina in ordine di valore promesso e inizia a chiedere loro di generare nuovi sostituti logici. Ogni regola può generare uno o più sostituti che verranno successivamente implementati utilizzando operatori fisici. Come parte di tale processo, viene calcolato un costo stimato.
Il punto di tutto ciò in quanto si applica agli spool delle prestazioni è che la forma e le proprietà del piano logico devono favorire la corrispondenza delle regole compatibili con lo spool e il contesto locale deve produrre un valore di promessa sufficientemente alto che l'ottimizzatore scelga di generare sostituti utilizzando la regola .
Regole di spool
Ci sono un certo numero di regole che esplorano il unimento di loop nidificati logico oppure applica alternative. Alcune di queste regole possono produrre uno o più sostituti con un particolare tipo di bobina di prestazioni. Altre regole che corrispondono ai loop nidificati si uniscono o si applicano non generano mai un'alternativa di spool.
Ad esempio, la regola ApplyToNL implementa un applica logico come un loop fisico si unisce a riferimenti esterni. Questa regola può generare diverse alternative ogni volta che corre. Oltre all'operatore di join fisico, ogni sostituto può contenere uno spool di tabella lazy, uno spool di indice lazy o nessuno spool. I sostituti di spool logici vengono successivamente implementati individualmente e valutati come spool fisici opportunamente tipizzati, da un'altra regola chiamata BuildSpool .
Come secondo esempio, la regola JNtoIdxLookup implementa un join logico come applicazione fisica , con un indice cerca immediatamente sul lato interno. Questa regola mai genera un'alternativa con un componente di spool. JNtoIdxLookup viene valutato in anticipo e restituisce un valore di promessa elevato quando corrisponde, quindi i semplici piani di ricerca dell'indice vengono trovati rapidamente.
Quando l'ottimizzatore trova un'alternativa a basso costo come questa all'inizio, le alternative più complesse possono essere eliminate in modo aggressivo o saltate del tutto. Il ragionamento è che non ha senso perseguire opzioni che difficilmente miglioreranno su un'alternativa a basso costo già trovata. Allo stesso modo, non vale la pena esplorare ulteriormente se l'attuale piano completo più completo ha già un costo totale sufficientemente basso.
Un terzo esempio di regola:la regola JNtoNL è simile a ApplyToNL , ma implementa solo nided loop join fisici , con una bobina da tavolo pigra o nessuna bobina. Questa regola mai genera uno spool indice perché quel tipo di spool richiede un'applicazione.
Generazione di spool e determinazione dei costi
Una regola che è capace di generare uno spool logico non lo farà necessariamente ogni volta che viene richiamato. Sarebbe uno spreco generare alternative logiche che non hanno quasi nessuna possibilità di essere scelte come più economiche. C'è anche un costo per la generazione di nuove alternative, che a loro volta possono produrre ancora più alternative, ognuna delle quali potrebbe richiedere implementazione e costi.
Per gestire ciò, l'ottimizzatore implementa una logica comune per tutte le regole compatibili con lo spool per determinare quali tipi di alternative allo spool generare in base alle condizioni del piano locale.
Unisciti ai loop nidificati
Per un unire i loop nidificati , la possibilità di ottenere una bobina da tavolo pigra incrementi in linea con:
- Il numero stimato di righe sull'input esterno del join.
- Il costo stimato degli operatori del piano interno.
Il costo della bobina viene ripagato dal risparmio ottenuto evitando esecuzioni interne dell'operatore. I risparmi aumentano con più iterazioni interne e costi interni più elevati. Ciò è particolarmente vero perché il modello di costo assegna numeri di costo di I/O e CPU relativamente bassi ai riavvolgimenti dello spool della tabella (cache hit). Ricorda che uno spool di tabella su un join di loop nidificato sperimenta sempre e solo riavvolgimenti, perché la mancanza di parametri significa che il set di dati del lato interno è statico.
Uno spool può memorizzare i dati in modo più denso rispetto agli operatori che lo alimentano. Ad esempio, un indice cluster di tabella di base potrebbe memorizzare in media 100 righe per pagina. Supponiamo che una query richieda solo un singolo valore di colonna intero da ogni riga di indice cluster ampia. La memorizzazione del solo valore intero nella tabella di lavoro dello spool significa che è possibile memorizzare ben oltre 800 righe di questo tipo per pagina. Questo è importante perché l'ottimizzatore valuta in parte il costo della bobina del tavolo utilizzando una stima del numero di pagine del tavolo di lavoro necessario. Altri fattori di costo includono il costo della CPU per riga coinvolto nella scrittura e nella lettura dello spool, rispetto al numero stimato di iterazioni del ciclo.
L'ottimizzatore è probabilmente un po' troppo desideroso di aggiungere spool di tabella pigri al lato interno di un join di loop nidificato. Tuttavia, la decisione dell'ottimizzatore ha sempre senso in termini di costo stimato. Personalmente considero l'unione di loop nidificati come ad alto rischio , perché possono diventare rapidamente lenti se la stima della cardinalità dell'input di join è troppo bassa.
Una bobina da tavolo può aiutano a ridurre i costi, ma non possono nascondere completamente le prestazioni nel caso peggiore di un join ingenuo di loop nidificati. Un join applicato indicizzato è normalmente preferibile e più resiliente agli errori di stima. È anche una buona idea scrivere query che l'ottimizzatore può implementare con hash o merge join quando appropriato.
Applica spool Lazy Table
Per una applicazione , le possibilità di ottenere una bobina da tavolo pigra aumentare con il numero stimato di duplicati unisci i valori chiave nell'input esterno di apply. Con più duplicati, c'è una statistica maggiore possibilità che la bobina riavvolga i risultati attualmente memorizzati ad ogni iterazione. Un'applicazione della bobina del tavolo pigro con un costo stimato inferiore ha maggiori possibilità di essere inclusa nel piano di esecuzione finale.
Quando le righe che arrivano sull'input esterno dell'applicazione non hanno un ordinamento particolare, l'ottimizzatore effettua una valutazione statistica di quanto è probabile che ogni iterazione si traduca in un rewind economico o un rebind costoso. Questa valutazione utilizza i dati dei passaggi dell'istogramma quando disponibili, ma anche questo scenario migliore è più un'ipotesi plausibile. Senza una garanzia, l'ordine delle righe che arrivano sull'input esterno dell'applicazione è imprevedibile.
Le stesse regole di ottimizzazione che generano alternative di spool logico possono anche specificare che l'operatore applica richiede righe ordinate sul suo ingresso esterno. Ciò massimizza i riavvolgi della bobina pigra perché è garantito che tutti i duplicati vengano incontrati in un blocco. Quando l'ordinamento esterno dell'input è garantito, sia tramite un ordinamento conservato o un Ordinamento esplicito , il costo della bobina è molto ridotto. L'ottimizzatore tiene conto dell'impatto dell'ordinamento sul numero di riavvolgimenti e rilegature di spool.
Piani con un Ordinamento sull'input esterno di applicazione e un Lazy Table Spool sull'input interno sono abbastanza comuni. L'ottimizzazione dello smistamento sul lato esterno potrebbe comunque risultare controproducente. Ad esempio, ciò può accadere quando la stima della cardinalità del lato esterno è così bassa che l'ordinamento finisce per riversarsi su tempdb .
Applica spool indice pigro
Per una applicazione , ottenendo uno spool di indice pigro l'alternativa dipende dalla forma del piano e dai costi.
L'ottimizzatore richiede:
- Alcuni duplicati unisci i valori sull'input esterno.
- Una uguaglianza predicato join (o un equivalente logico compreso dall'ottimizzatore, come
x <= y AND x >= y). - Una garanzia che i riferimenti esterni siano unici sotto lo spool di indice pigro proposto.
Nei piani di esecuzione, l'unicità richiesta è spesso fornita da un raggruppamento aggregato in base ai riferimenti esterni o da un aggregato scalare (senza raggruppamento per). L'unicità può essere fornita anche in altri modi, ad esempio dall'esistenza di un indice o di un vincolo univoci.
Di seguito un esempio di giocattolo che mostra la forma del piano:
CREATE TABLE #T1
(
c1 integer NOT NULL
);
GO
INSERT #T1 (c1)
VALUES
-- Duplicate outer rows
(1), (2), (3), (4), (5), (6),
(1), (2), (3), (4), (5), (6),
(1), (2), (3), (4), (5), (6);
GO
SELECT *
FROM #T1 AS T1
CROSS APPLY
(
SELECT COUNT_BIG(*)
FROM (SELECT T1.c1 UNION SELECT NULL) AS U
) AS CA (c);
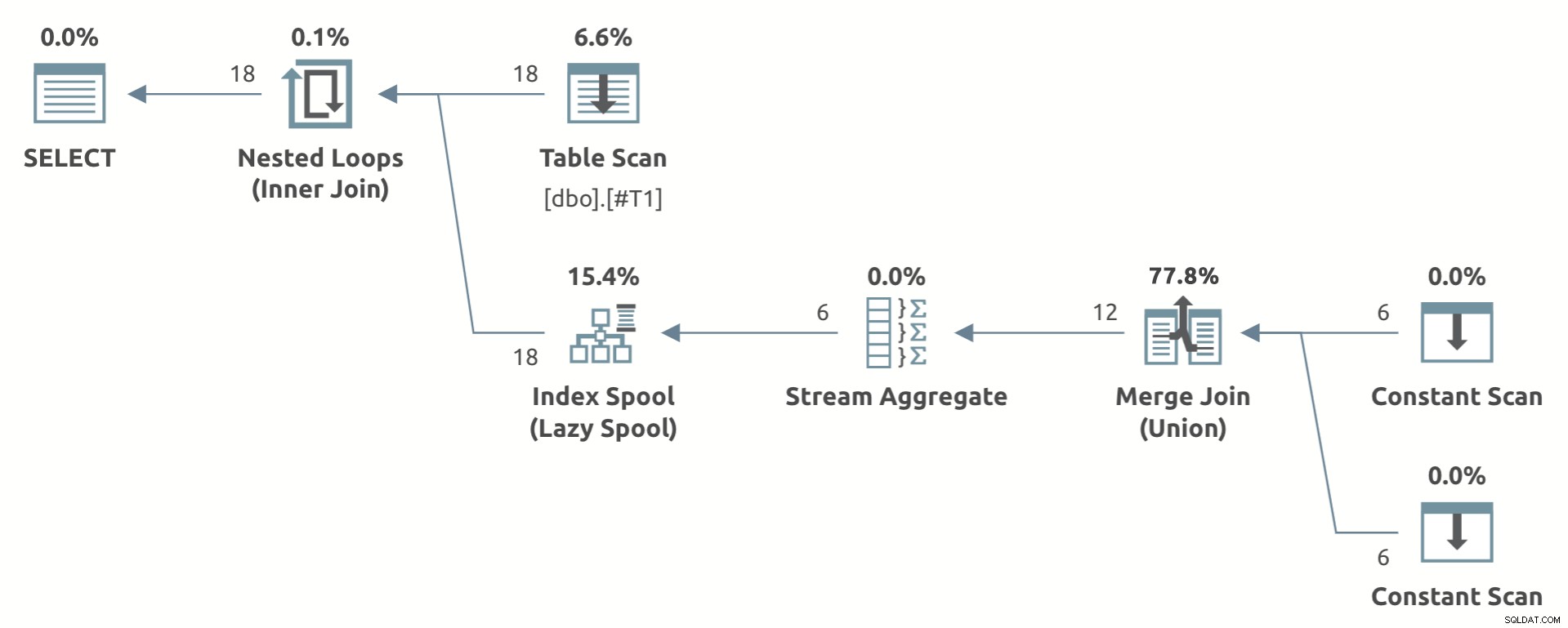
Notare l'aggregato di flusso sotto il Lazy Index Spool .
Se i requisiti di forma del piano sono soddisfatti, l'ottimizzatore genererà spesso un'alternativa di indice pigro (soggetto alle avvertenze menzionate in precedenza). Il fatto che il piano finale includa o meno uno spool di indice pigro dipende dai costi.
Spool di indice rispetto a Spool di tabella
Il numero stimato di riavvolgi e ricollega per uno spool di indice pigro è lo lo stesso come per un pigro rocchetto da tavola senza ordinato applica input esterno.
Questo può sembrare uno stato di cose piuttosto sfortunato. Il vantaggio principale di uno spool di indice è che memorizza nella cache tutti i risultati visti in precedenza. Questo dovrebbe fare in modo che lo spool dell'indice riavvolga più probabile che per uno spool di tabella (senza ordinamento dell'input esterno) nelle stesse circostanze. La mia comprensione è che questa stranezza esiste perché senza di essa, l'ottimizzatore sceglierebbe una bobina di indice troppo spesso.
Indipendentemente da ciò, il modello di costo si adatta a quanto sopra in una certa misura utilizzando diversi numeri di costo di I/O e CPU per le righe iniziali e successive per gli spool di indici e tabelle. L'effetto netto è che uno spool di indice ha solitamente un costo inferiore rispetto a uno spool di tabella senza input esterno ordinato, ma ricorda i requisiti restrittivi della forma del piano, che rendono gli spool di indice pigri relativamente raro.
Tuttavia, il principale concorrente di costo di un indice di spool pigro è uno spool da tavolo con input esterno ordinato. L'intuizione per questo è abbastanza semplice:l'input esterno ordinato significa che lo spool della tabella è garantito per vedere tutti i riferimenti esterni duplicati in sequenza. Ciò significa che si ricollegherà solo una volta per valore distinto e riavvolgere per tutti i duplicati. Questo è lo stesso del comportamento previsto di uno spool di indice (almeno logicamente parlando).
In pratica, è più probabile che uno spool di indice sia preferito a uno spool di tabella ottimizzato per l'ordinamento per un minor numero di valori chiave di applicazione duplicati. Avere meno chiavi duplicate riduce il riavvolgimento vantaggio dello spool di tabella ottimizzato per l'ordinamento, rispetto alle stime di spool dell'indice "sfortunate" annotate in precedenza.
L'opzione della bobina dell'indice beneficia anche del costo stimato di una bobina della tabella sul lato esterno Ordina aumenta. Questo sarebbe molto spesso associato a righe più (o più larghe) in quel punto del piano.
Traccia flag e suggerimenti
-
Gli spool delle prestazioni possono essere disabilitati con contrassegno di traccia poco documentato 8690 o il suggerimento per la query documentato
NO_PERFORMANCE_SPOOLsu SQL Server 2016 o versioni successive. -
Flag di traccia non documentato 8691 può essere utilizzato (su un sistema di test) per aggiungere sempre uno spool di prestazioni quando possibile. Il tipo di spool pigro che ottieni (conteggio righe, tabella o indice) non può essere forzato; dipende ancora dalla stima dei costi.
-
Flag di traccia non documentato 2363 può essere utilizzato con il nuovo modello di stima della cardinalità per vedere la derivazione della stima distinta sull'input esterno a un'applicazione e sulla stima della cardinalità in generale.
-
Flag di tracciamento non documentato 9198 può essere utilizzato per disabilitare gli spool pigri delle prestazioni dell'indice nello specifico. Potresti comunque ottenere una tabella pigra o uno spool di conteggio delle righe (con o senza ottimizzazione dell'ordinamento), a seconda dei costi.
-
Flag di traccia non documentato 2387 può essere utilizzato per ridurre il costo della CPU di leggere righe da uno spool di indice pigro . Questo flag influisce sulle stime generali dei costi della CPU per la lettura di un intervallo di righe da un b-tree. Questo flag tende a rendere più probabile la selezione dello spool dell'indice, per motivi di costo.
Altri metodi e flag di traccia per determinare quali regole di ottimizzazione sono state attivate durante la compilazione della query sono disponibili nella mia serie di approfondimenti su Query Optimizer.
Pensieri finali
Ci sono moltissimi dettagli interni che influiscono sul fatto che il piano di esecuzione finale utilizzi uno spool di prestazioni o meno. Ho cercato di coprire le considerazioni principali in questo articolo, senza entrare troppo nei dettagli estremamente intricati delle formule di costo dell'operatore di bobina. Si spera che qui ci siano abbastanza consigli generali per aiutarti a determinare i possibili motivi di un particolare tipo di spooling delle prestazioni in un piano di esecuzione (o della sua mancanza).
Gli spool delle prestazioni spesso subiscono un brutto colpo, penso sia giusto dirlo. Alcuni di questi sono senza dubbio meritati. Molti di voi avranno visto una demo in cui un piano viene eseguito più velocemente senza una "bobina di prestazioni" rispetto a. In una certa misura ciò non è inaspettato. Esistono casi limite, il modello di determinazione dei costi non è perfetto e, senza dubbio, le demo spesso presentano piani con stime di cardinalità scarse o altri problemi di limitazione dell'ottimizzazione.
Detto questo, a volte vorrei che SQL Server fornisse una sorta di avviso o altro feedback quando ricorre all'aggiunta di uno spool di tabella pigro a un join di loop nidificato (o un'applicazione senza un indice interno di supporto utilizzato). Come accennato nel corpo principale, queste sono le situazioni che trovo più spesso sbagliate, quando le stime di cardinalità si rivelano terribilmente basse.
Forse un giorno Query Optimizer terrà conto di alcuni concetti di rischio per pianificare le scelte o fornirà capacità più "adattive". Nel frattempo, è utile supportare i tuoi loop nidificati join con utili indici ed evitare di scrivere query che possono essere implementate solo utilizzando loop nidificati ove possibile. Sto generalizzando ovviamente, ma l'ottimizzatore tende a fare meglio quando ha più scelte, uno schema ragionevole, buoni metadati e istruzioni T-SQL gestibili con cui lavorare. Come me, a pensarci bene.
Altri articoli di spool
Gli spool senza prestazioni vengono utilizzati per molti scopi all'interno di SQL Server, tra cui:
- Protezione di Halloween
- Alcune funzioni della finestra in modalità riga
- Calcolo di più aggregati
- Ottimizzazione delle istruzioni che modificano i dati