FILESTREAM è stato introdotto da Microsoft nel 2008. Lo scopo era archiviare e gestire i file non strutturati in modo più efficace. Prima dell'introduzione di FILESTREAM, per archiviare i dati nel server SQL venivano utilizzati i seguenti approcci:
- I file non strutturati possono essere archiviati nella colonna VARBINARY o IMAGE di una tabella di SQL Server. Questo approccio è efficace per mantenere la coerenza transazionale e riduce la complessità della gestione dei file, ma quando l'applicazione client legge i dati dalla tabella SQL, utilizza la memoria SQL che porta a scarse prestazioni.
- Invece di archiviare l'intero file nella tabella SQL, archiviare la posizione fisica del file non strutturato nella tabella SQL. Questo approccio offre un enorme miglioramento delle prestazioni, ma non garantisce la coerenza transazionale, inoltre anche la gestione dei file è stata difficile.
La funzione FILESTREAM è molto efficace perché consente di archiviare file BLOB nel file system NT e mantiene la coerenza transazionale. Quando un'applicazione client legge i dati dal contenitore FILESTREAM, invece di utilizzare la memoria del buffer di SQL Server, utilizza Nla cache di sistema T che migliora le prestazioni.
FILESTREAM non è un tipo di dati. È un attributo che può essere assegnato alla colonna VARBINARY(MAX). Quando la colonna VARBINARY(MAX) viene assegnata all'attributo FILESTREAM, viene chiamata colonna FILESTREAM. I dati archiviati nella colonna FILESTREAM verranno archiviati nel sistema NT come file su disco e il puntatore del file verrà archiviato nella tabella. La colonna VARBINARY(max) con l'attributo FILESTREAM assegnato non ha un limite di archiviazione di 2 GB nella tabella. Quindi, possiamo archiviare anche file di grandi dimensioni.
In questo articolo, dimostrerò quanto segue:
- Come abilitare la funzione FILESTREAM.
- Come creare e configurare filegroup FILESTREAM e contenitore di dati FILESTREAM.
- Come archiviare e accedere ai dati dalle tabelle abilitate FILESTREAM.
Demo:
In questa demo userò:
- Server di database :SQL Server 2017
- Software :SQL Server Management Studio
- Banca dati :Demo_FileStream
Configura l'accesso a FILESTREAM nel database di SQL Server
Per configurare FileStream in SQL Server, apportare le seguenti modifiche a SQL Server.
- Abilita la funzionalità FILESTREAM da Gestione configurazione SQL Server.
- Abilita il livello di accesso FILESTREAM sull'istanza di SQL Server.
- Crea un filegroup FILESTREAM e un contenitore FileStream per archiviare i dati BLOB.
Abilita la funzione FILESTREAM
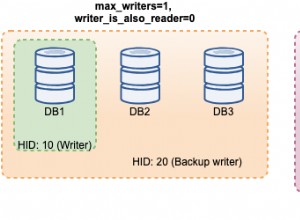
Per abilitare FileStream su qualsiasi database, abilitare innanzitutto la funzionalità FileStream nell'istanza di SQL Server. Per farlo, apri Gestione configurazione SQL Server, fai clic con il pulsante destro del mouse su Istanza SQL, seleziona Proprietà , come mostrato nell'immagine seguente:
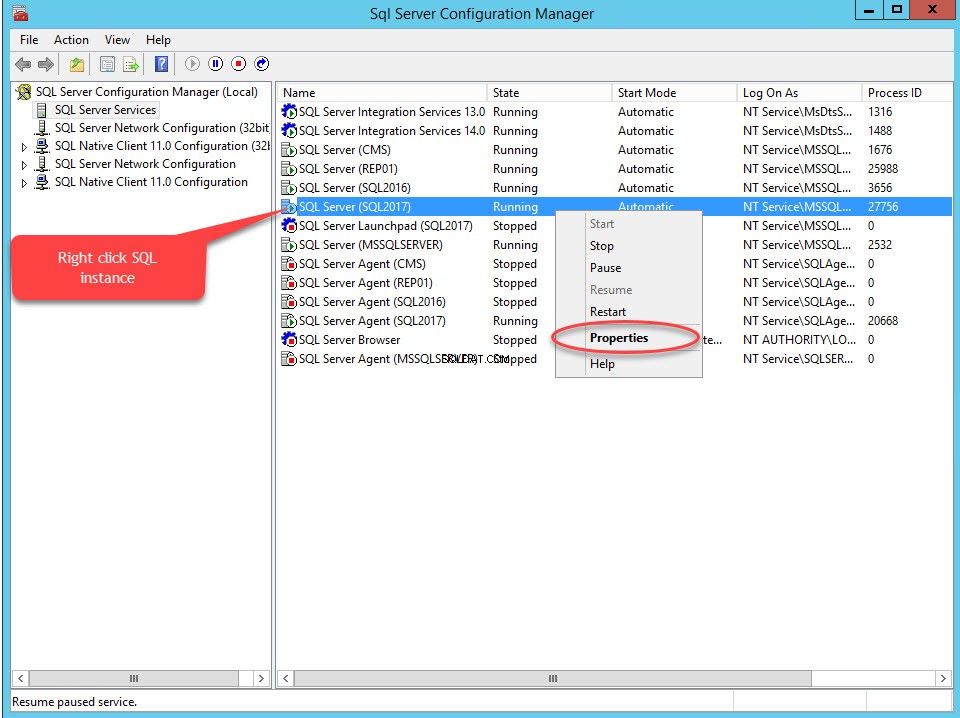
Si apre una finestra di dialogo per configurare le proprietà del server. Passa a FILESTREAM scheda. Seleziona Abilita FILESTREAM per l'accesso T-SQL . Seleziona Abilita FILESTREAM per l'accesso I/O quindi seleziona Consenti accesso client remoto ai dati FILESTREAM . Nel nome condivisione di Windows casella di testo, fornire un nome della directory in cui archiviare i file. Vedi l'immagine seguente:
Fare clic su OK e riavviare il servizio SQL.
Abilita il livello di accesso FILESTREAM sull'istanza di SQL Server
Una volta abilitata la funzione FILESTREAM, modificare il livello di accesso FILESTREAM. Per modificare il livello di accesso a FileStream, eseguire la query seguente:
EXEC sp_configure filestream_access_level, 2 RECONFIGURE
Nella query precedente, i parametri seguenti sono valori validi:
0 significa il supporto FILESTREAM per l'istanza SQL è disabilitato.
1 significa il supporto FILESTREAM per T-SQL è abilitato.
2 significa il supporto FILESTREAM per l'accesso allo streaming T-SQL e Win32 è abilitato.
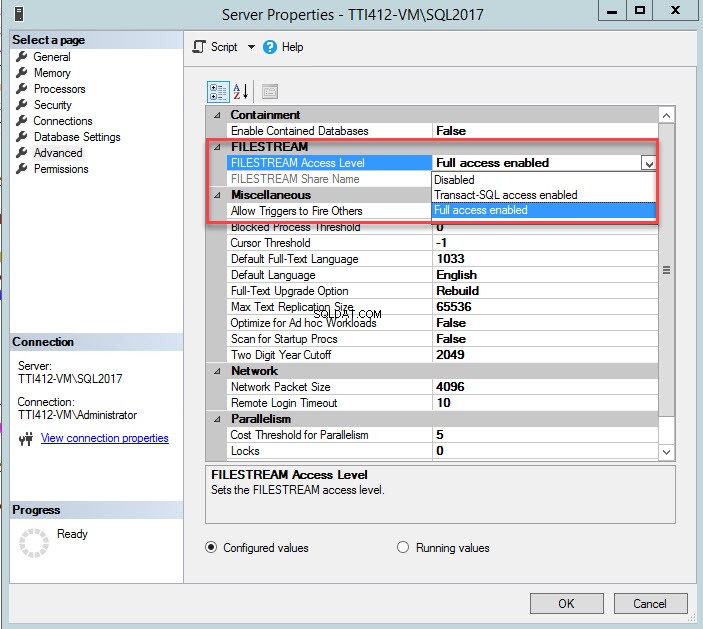
È possibile modificare il livello di accesso FILESTREAM utilizzando SQL Server Management Studio. Per farlo, fai clic con il pulsante destro del mouse su una connessione SQL Server>> seleziona Proprietà>> Nella finestra di dialogo delle proprietà del server, seleziona Livello di accesso FileStream dalla casella a discesa e seleziona Accesso completo abilitato , come mostrato nell'immagine seguente:
Una volta modificato il parametro, riavviare i servizi di SQL Server.
Aggiungi filegroup e file di dati FILESTREAM
Una volta abilitato FILESTREAM, aggiungi il filegroup FILESTREAM e il contenitore FILESTREAM.
Per farlo, fai clic con il pulsante destro del mouse su FileStream-Demo database>> seleziona Proprietà>> In un riquadro sinistro delle Proprietà database finestra di dialogo, seleziona Filegroup>> Nella griglia FILESTREAM, fai clic su Aggiungi filegroup pulsante>> Assegna un nome al filegroup come Documento fittizio . Vedi l'immagine seguente:
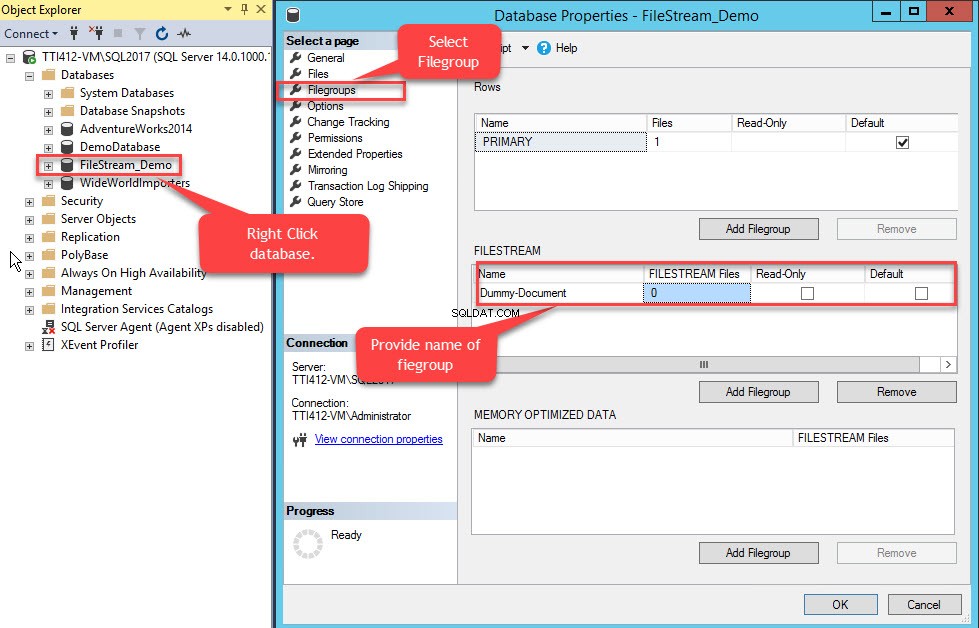
Una volta creato il filegroup, nella finestra di dialogo Proprietà database, seleziona file e fare clic sul pulsante Aggiungi. La griglia dei file di database è abilitata. Nella colonna Nome logico, fornisci il nome, – Documento fittizio . Seleziona Dati FILESTREAM nel Tipo di file casella a discesa. Seleziona Documento fittizio nel Filegroup colonna. Nel Percorso colonna, fornire la posizione della directory in cui verranno archiviati i file (E:\Dummy-Documents). Vedi l'immagine seguente:
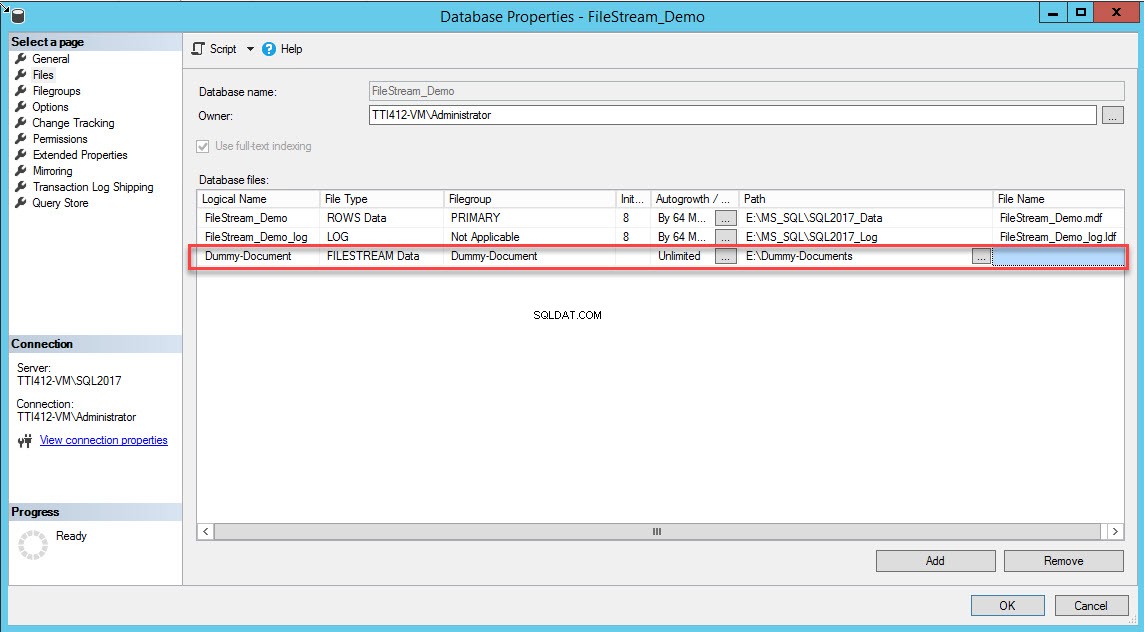
In alternativa, puoi aggiungere il filegroup e i contenitori FILESTREAM eseguendo la seguente query T-SQL:
USE [master] GO ALTER DATABASE [FileStream_Demo] ADD FILEGROUP [Dummy-Documents] CONTAINS FILESTREAM GO ALTER DATABASE [FileStream_Demo] ADD FILE ( NAME = N'Dummy-Documents', FILENAME = N'E:\Dummy-Documents' ) TO FILEGROUP [Dummy-Documents] GO
Per verificare che il contenitore FileStream sia stato creato, apri Esplora risorse e vai alla directory "E:\Dummy-Document".
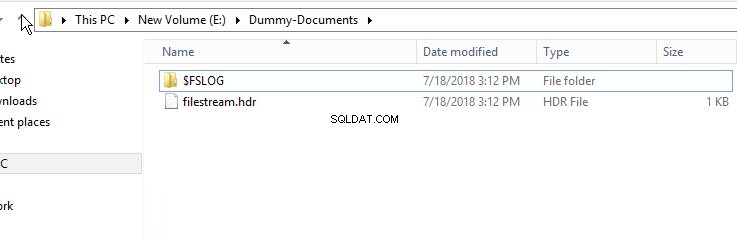
Come mostrato nell'immagine sopra, la directory $FSLOG e il filestream.hdr file sono stati creati. $FSLOG è come T-Log del server SQL e filestream.hdr contiene metadati di FILESTREAM. Assicurati di non modificare o modificare quei file.
Memorizza file nella tabella SQL
In questa demo creeremo una tabella per memorizzare vari file dal computer. La tabella ha le seguenti colonne:
- La “RootDirectory colonna ” per memorizzare il percorso del file.
- Il "Nome file ” per memorizzare il nome del file.
- Il "AttributoFile ” colonna per memorizzare l'attributo File (Raw/Directory.
- Il "FileCreateDate ” colonna per memorizzare l'ora di creazione del file.
- La "dimensione file ” per memorizzare la Dimensione del file.
- Il "FileStreamCol ” colonna per memorizzare il contenuto del file in formato binario.
Crea una tabella SQL con una colonna FILESTREAM
Dopo la configurazione di FILESTREAM, creare una tabella SQL con le colonne FILESTREAM per archiviare vari file nella tabella del server SQL. Come accennato in precedenza, FILESTREAM non è un tipo di dati. È un attributo che aggiungiamo alla colonna varbinary(max) nella tabella abilitata per FILESTREAM. Quando crei una tabella abilitata per FILESTREAM, assicurati di aggiungere un IDENTIFICATORE UNICO colonna che contiene ROWGUIDCOL e UNICO attributi.
Esegui lo script seguente per creare una tabella abilitata per FILESTREAM:
Use [FileStream_Demo]
go
Create Table [DummyDocuments]
(
ID uniqueidentifier ROWGUIDCOL unique NOT NULL,
RootDirectory varchar(max),
FileName varchar(max),
FileAttribute varchar(150),
FileCreateDate datetime,
FileSize numeric(10,5),
FileStreamCol varbinary (max) FILESTREAM
) Inserisci dati nella tabella
Ho il WorldWide_Importors.xls documento archiviato nel computer nella posizione “E:\Documents”. Usa OPENROWSET (in blocco) per caricare il suo contenuto dal disco a VARBINARY(max) variabile. Quindi archivia la variabile in FileStreamCol Colonna (VARBINARY(max)) del DummyDocumen tavolo. Per farlo, esegui il seguente script:
Use [FileStream-Demo]
Go
DECLARE @Document AS VARBINARY(MAX)
-- Load the image data
SELECT @Document = CAST(bulkcolumn AS VARBINARY(MAX))
FROM OPENROWSET(
BULK
'E:\Documents\WorldWide_Importors.xls',
SINGLE_BLOB ) AS Doc
-- Insert the data to the table
INSERT INTO [DummyDocuments] (ID, RootDirectory,FileName, FileAttribute, FileCreateDate,FileSize,FileStreamCol)
SELECT NEWID(), 'E:\Documents','WorldWide_Importors.xls','Raw',getdate(),10, @Document Accedi ai dati FILESTREAM
È possibile accedere ai dati FILESTREAM utilizzando T-SQL e Managed API. Quando si accede alla colonna FILESTREAM tramite query T-SQL, utilizza la memoria SQL per leggere il contenuto del file di dati e inviare i dati all'applicazione client. Quando si accede alla colonna FILESTREAM tramite l'API gestita da Win32, non utilizza la memoria di SQL Server. Utilizza la capacità di streaming del file system NT che offre vantaggi in termini di prestazioni.
Accedi ai dati FILESTREAM utilizzando T-SQL
Come accennato all'inizio dell'articolo, FILESTREAM è un attributo assegnato a una colonna di tabella che ha il tipo di dati varbinary(max), pertanto è possibile accedervi come qualsiasi altra colonna della tabella. Per recuperare i dati FILESTREAM insieme a tutte le informazioni della tabella, esegui la query sottostante
Use [FileStream-Demo] go select RootDirectory,FileName,FileAttribute,FileCreateDate,FileSize,FileStreamCol from DummyDocuments
Di seguito è riportato l'output della query:

Come mostrato nell'immagine sopra, il documento "WorldWide_Importors.xls" è stato convertito in un BLOB archiviato nella colonna "FileStreamCol".
Accedi ai dati FILESTREAM utilizzando l'API gestita
Sebbene l'accesso a FILESTREAM utilizzando l'API Win32 offra prestazioni e altri vantaggi, ha sintassi diverse e difficili rispetto alle sintassi T-SQL che rendono difficile l'accesso ai dati. In primo luogo, per individuare il file nell'archivio dati FILESTREAM, è necessario identificare il percorso logico per identificare il file nell'archivio dati FILESTREAM in modo univoco. Possiamo farlo usando il Percorso() metodo della colonna FILESTREAM. Fa distinzione tra maiuscole e minuscole.
Dopo aver recuperato il percorso di File, per accedere, dobbiamo ottenere il contesto della transazione utilizzando il Inizia transazione metodo. Una volta ottenuto il contesto della transazione, possiamo accedervi utilizzando SQLFileStream classe.
Il codice seguente ottiene il percorso locale di WorldWide_Importors.xls documento nell'archivio dati FILESTREAM.
SELECT
RootDirectory,
FileName,
FileAttribute,
FileCreateDate,
FileSize,
FileStreamCol.PathName() AS FilePath
FROM DummyDocuments Output della query:

Elimina file dal contenitore FILESTREAM
L'eliminazione dei file è semplice. È necessario eseguire la query di eliminazione per rimuovere il file dalla tabella SQL abilitata per FILESTREAM. Anche se il record è stato eliminato dalle tabelle, il file sarà disponibile fisicamente nell'archivio dati FILSTREAM. Verrà eliminato da Garbage Collector. Il processo Garbage Collector viene eseguito quando si verifica l'evento checkpoint. Dando un checkpoint esplicito, puoi eliminarlo subito dopo averlo eliminato dalla tabella.
Query per eliminare i file dalla tabella SQL:
Use [FileStream_Demo] go delete from DummyDocuments where ID='0D640ABC-8CF1-41E0-9FA8-28171047129F'
Riepilogo
In questo articolo ho trattato:
- Introduzione di FILESTREAM e quali sono i vantaggi.
- Come abilitare la funzione FILESTREAM sull'istanza del server SQL.
- Crea e configura l'archivio dati FILESTREAM e i filegroup.
- Esegui Inserisci ed Elimina file dall'archivio dati FILESTREAM.
Nei prossimi articoli spiegherò:
- Come eseguire il backup e il ripristino del database abilitato per FILESTREAM.
- Impostazione della replica e del porzionamento delle tabelle nelle tabelle FILESTREAM.
Resta sintonizzato!