Pensi a qualcosa quando crei un nuovo database? Immagino che la maggior parte di voi direbbe di no, dal momento che tutti usiamo parametri predefiniti, sebbene siano lontani dall'essere ottimali. Tuttavia, ci sono un sacco di impostazioni del disco e aiutano davvero ad aumentare l'affidabilità e le prestazioni del sistema.
Non parleremo dell'importanza del file system NTFS per l'affidabilità dei dati, sebbene questo file system consenta a MS SQL Server di utilizzare il disco nel modo più efficace.
Se sei a corto di risorse e qualcosa inizia a funzionare lentamente, la prima cosa che viene in mente è l'aggiornamento. Ma l'aggiornamento non è richiesto in ogni caso. Puoi farla franca con l'ottimizzazione, anche se dovrebbe essere eseguita non quando il server inizia a funzionare lentamente, ma nella fase di progettazione e installazione.
L'ottimizzazione è un processo complesso e spesso è correlato non solo a un determinato programma (nel nostro caso, a un determinato database) ma anche al sistema operativo e all'hardware. Sebbene parleremo principalmente di database, non possiamo ignorare le cose esteriori.
Architettura dei dati
SQL Server archivia, legge e scrive dati in blocchi da 8 KB ciascuno. Questi blocchi sono chiamati pagine. Un database può memorizzare 128 pagine per megabyte (1 megabyte o 1048576 byte divisi per 8 kilobyte o 8192 byte). Tutte le pagine sono memorizzate in un'estensione. Un'estensione è costituita dalle ultime 8 pagine sequenziali o 64 KB. Pertanto, 1 megabyte memorizza 16 estensioni.
Le pagine e le estensioni sono la base della struttura fisica del database di SQL Server. MS SQL Server utilizza vari tipi di pagina, alcuni tengono traccia dello spazio allocato, altri contengono dati utente e indici. Le pagine che tengono traccia dello spazio allocato contengono i dati densamente compressi. Consente a MS SQL Server di archiviarli in memoria in modo efficace per una facile lettura.
SQL Server utilizza due tipi di estensioni:
- Le estensioni che memorizzano pagine da due a più oggetti sono chiamate estensioni miste. Ogni tabella inizia come una misura mista. Utilizzi l'estensione mista principalmente per le pagine che memorizzano spazio e contengono piccoli oggetti.
- Le estensioni che hanno tutte le 8 pagine allocate a un oggetto sono chiamate estensioni uniformi. Vengono utilizzati quando una tabella o un indice richiede più di 64 KB.
La prima estensione per ogni file è uniforme e contiene le pagine dell'intestazione del file, le estensioni successive contengono 3 pagine allocate ciascuna. Il server alloca queste estensioni miste quando si crea un file di dati di base e utilizza queste pagine per le sue attività interne. La pagina di intestazione del file contiene attributi di file, come il nome del database archiviato nel file, il filegroup, la dimensione minima, la dimensione dell'incremento. Questa è la prima pagina di ogni file (pagina 0).
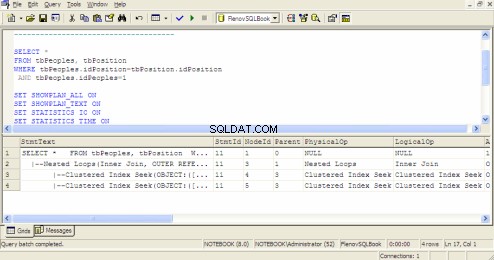
Piano di esecuzione delle query in SQL Query Analyzer
Spazio libero nella pagina (PFS ) in una pagina allocata che contiene informazioni sullo spazio libero disponibile nel file. Queste informazioni sono memorizzate a pagina 1. Ciascuna di queste pagine può estendersi a 8000 pagine contigue, ovvero circa 64 Mb di dati.
Il log delle transazioni raccoglie tutte le informazioni sulle modifiche in atto sul server per ripristinare un database al momento dell'errore di sistema e garantire l'integrità dei dati.
Si noti che tutti i numeri sono multipli di 8 o 16. Questo perché il controller del disco rigido legge i dati di queste dimensioni più facilmente. I dati vengono letti dal disco per pagine, ovvero 8 kilobyte, che è un valore abbastanza ottimale.
Protezione della pagina
A partire da MS SQL Server 2005, il server di database presenta una nuova opzione:il controllo dei dati a livello di pagina. Se il AGE_VERIFY_CHECKSUM parametro è abilitato (è abilitato di default), il server controllerà i checksum delle pagine. Se esaminiamo il manuale per questo parametro, vedremo che il checksum consente di tenere traccia degli errori di input/output che il sistema operativo non è in grado di tracciare. Che tipo di errori sono? Sembra che siano problemi interni del server di database.
Il controllo dell'integrità dei dati non va mai male, quindi è meglio abilitarlo. Per questo, dobbiamo eseguire il seguente comando:
ALTER DATABASE имя базы SET PAGE_VERIFY
Se c'è un errore nella pagina, il server ce lo avviserà. Ma come possiamo risolverlo rapidamente? C'è un'opzione per ripristinare i dati a livello di pagina per questo.
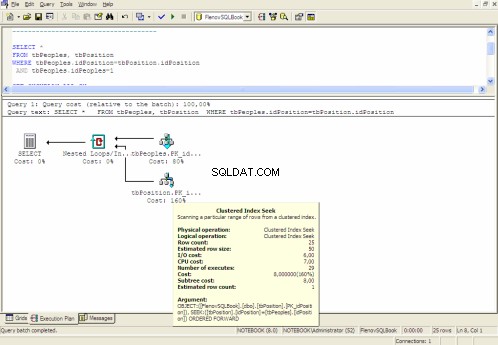
Piano di esecuzione grafico
Crescita dei file
Quando creiamo un database, ci viene chiesto di selezionare la dimensione iniziale e il metodo di incremento. Quando siamo a corto di spazio corrente, il server lo estende in corrispondenza del metodo di incremento preimpostato.
Esistono tre metodi di incremento per i file:
- Crescita in megabyte.
- Crescita in percentuale.
- Crescita manuale.
I primi due metodi vengono eseguiti automaticamente, ma sono consigliati solo per i database di test poiché un amministratore non ha il controllo sulla dimensione del file.
Se un file viene incrementato di una certa quantità di megabyte, a un certo punto, la velocità di inserimento dei dati potrebbe aumentare e la crescita del file potrebbe diventare troppo frequente, e questo è un costo aggiuntivo. Anche la crescita dei file in percentuale non è redditizia. Si consiglia di utilizzare una crescita del file del 10% e questo va bene per database di piccole e medie dimensioni. Ma quando raggiunge i 1000 gigabyte, saranno necessari 100 gigabyte per ogni crescita. Comporterà un inutile spreco di spazio su disco.
Controlla sempre le modifiche alle dimensioni dei file e dei registri delle transazioni. Ti consentirà di utilizzare le risorse del disco nel modo più efficace.
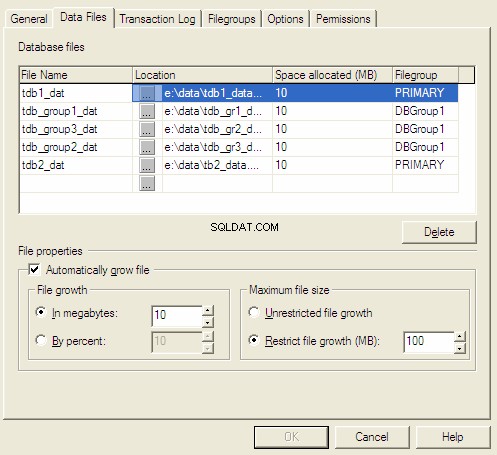
Proprietà del database di MS SQL Server
Compressione dati
Il disco rigido rimane un punto sensibile di un computer. Le prestazioni dei processori crescono vertiginosamente, mentre i dischi rigidi non possono offrire qualcosa di nuovo. Per salvare il numero di operazioni di input/output e ridurre i dati archiviati sul disco rigido, è possibile utilizzare dischi con compressione. Solo tali dischi sono utili per la memorizzazione di filegroup di sola lettura. Forse è perché la compressione è necessaria per le scritture e richiede costi aggiuntivi per il processore.
La compressione dei dati e lo stato di sola lettura sono utili per i dati di archiviazione. Ad esempio, i dati contabili degli ultimi anni non sono necessari per la scrittura e possono occupare troppo spazio. Inserendo i dati nella sezione di archiviazione del disco, risparmierai molto spazio.
Dischi per l'affidabilità
Il metodo seguente consente di aumentare l'affidabilità e le prestazioni allo stesso tempo e, ancora una volta, è correlato ai dischi rigidi. Ebbene, ecco qua, la meccanica non è solo la più lenta, ma anche la più inaffidabile. Per quanto riguarda l'affidabilità, non ho raccolto le statistiche, ma sia, a casa che al lavoro, mi occupo principalmente di hard disk.
Quindi, per aumentare le prestazioni e l'affidabilità, puoi semplicemente utilizzare due o più dischi rigidi anziché uno. Sarà ancora meglio se saranno collegati a controller separati. È possibile archiviare il database su un disco e i registri delle transazioni su un altro. Se è presente un terzo disco, può memorizzare il sistema.
L'archiviazione dei dati e di un registro su dischi separati consente di aumentare notevolmente l'affidabilità. Supponiamo di avere tutto su un disco e va giù. Cosa fare? Puoi raggiungere un'azienda che proverà a recuperare tutto o provare a fare lo stesso da solo, ma le possibilità di recupero sono ben lontane dal 100%. Inoltre, il ripristino del funzionamento del server potrebbe richiedere molto tempo. Il ripristino rapido può essere eseguito solo fino al momento dell'ultima copia di backup. Il resto è discutibile.
E ora, supponiamo di avere dati e un registro delle transazioni su dischi diversi. Se il disco con il registro si spegne, i dati saranno ancora lì. L'unica cosa è che non puoi aggiungere nuovi dati, ma se crei un nuovo log, puoi continuare a lavorare.
Se il disco con i dati si spegne, possiamo comunque prenotare il registro delle transazioni per evitare la minima perdita di dati. Successivamente, recuperiamo i dati dal backup completo (dovrebbe sempre essere fatto in anticipo, un buon amministratore lo fa almeno una volta al giorno) e aggiungiamo le modifiche dalla copia di backup del log.
Dischi per prestazioni
Se i dati e un registro si trovano su dischi separati, significa non solo sicurezza ma anche aumento delle prestazioni. Il fatto è che il server del database può scrivere simultaneamente i dati nel registro e nel file di dati.
Possiamo andare oltre e allocare un disco rigido al registro delle transazioni e diversi dischi rigidi ai dati. Il server lavora con i dati più spesso, ecco perché richiede più archivi con cui puoi lavorare contemporaneamente. E se questi storage sono collegati a controller diversi, il lavoro simultaneo è garantito.
La variante più veloce e affidabile consiste nell'usare RAID . Tuttavia, non tutti i RAID è affidabile e veloce allo stesso tempo. Per i gruppi di file, si consiglia di scegliere RAID10 , poiché contiene funzionalità ben bilanciate, ma a seconda dei dati del database, puoi scegliere un'altra variante.
Puoi utilizzare una soluzione software o hardware come RAID . Una soluzione software è più economica, ma richiede risorse aggiuntive di CPU. E un processore non ha risorse di riserva. Ecco perché è meglio utilizzare soluzioni hardware in cui un chip dedicato è responsabile del RAID .
Indici
Tutti sanno che gli indici aiutano ad aumentare la velocità di ricerca dei dati. La maggior parte di noi comprende che gli indici influiscono negativamente sull'inserimento e l'aggiornamento dei dati, quindi più indici hai, più difficile sarà per il server mantenerli. Per questo, non molti pensano nemmeno che gli indici richiedano manutenzione. Le pagine del database contenenti i dati dell'indice potrebbero traboccare e alla fine diventare sbilanciate.
Sì, possiamo ignorare vari parametri e ricreare semplicemente gli indici una volta al mese, il che è simile alla manutenzione. SQL Server include due parametri che impediscono l'obsolescenza degli indici entro mezz'ora dalla loro creazione:FILLFACTOR e PAD_INDEX .
È possibile utilizzare l'opzione FILLFACTOR per ottimizzare le prestazioni delle operazioni di inserimento e aggiornamento che contengono un indice cluster o non cluster. I dati dell'indice possono essere memorizzati in molte pagine di dati. Come accennato in precedenza, ogni pagina è composta da 8 KB. Quando una pagina di indice è piena, il server crea una nuova pagina e divide in due la pagina per l'inserimento dati.
Il server richiede tempo per la divisione delle pagine e la creazione di una nuova pagina. Per ottimizzare la divisione delle pagine, utilizza il FILLFACTOR opzione per determinare la percentuale di spazio libero su tutte le pagine della pagina indice. Maggiore è lo spazio su disco delle pagine a livello di foglia, meno frequente sarà la divisione delle pagine indice. A quel punto, l'albero dell'indice sarà troppo grande e il suo bypass richiederà più tempo.
Il PAD_INDEX opzione indica la percentuale di riempimento delle pagine non foglia. Puoi utilizzare PAD_INDEX solo quando il FILLFACTOR opzione è specificata poiché il valore percentuale di PAD_INDEX dipende dalla percentuale specificata in FILLFACTOR .
Statistiche
Le statistiche consentono al server di prendere la decisione giusta tra l'utilizzo dell'indice e la scansione completa della tabella. Supponiamo di avere un elenco di dipendenti di una fonderia. Tale elenco sarà composto da circa il 90% di uomini.
Supponiamo di dover trovare tutte le donne. Poiché non ce ne sono molti, l'opzione più efficace sarà utilizzare l'indice. Ma se dobbiamo trovare tutti gli uomini, l'efficienza dell'indice rallenta. Il numero di record selezionati è troppo grande e ignorare l'albero dell'indice per ciascuno di essi sarà un sovraccarico. È molto più semplice scansionare l'intera tabella:l'esecuzione sarà molto più veloce poiché il server dovrà leggere tutte le foglie di basso livello dell'indice una volta senza la necessità di letture multiple di tutti i livelli.
SQL Server raccoglie le statistiche leggendo tutti i valori dei campi o con un modello per la creazione dell'elenco valori distribuito e ordinato in modo uniforme. SQL Server rileva in modo dinamico la percentuale di righe che devono essere verificate in base al numero di righe nella tabella. Durante la raccolta delle statistiche, Query Optimizer eseguirà una scansione completa o modelli di riga.
Per far funzionare le statistiche, è necessario crearle. In caso di aggiornamento massiccio dei dati, le statistiche potrebbero contenere dati errati e il server prenderà una decisione sbagliata. Ma tutto può essere aggiustato, – è necessario monitorare le statistiche. Per informazioni più dettagliate, fare riferimento ai libri su Transact-SQL o MS SQL Server.
Riepilogo
Le impostazioni predefinite non consentono di utilizzare tutto il potenziale dell'hardware e funzionano con tutta la varietà di server. La responsabilità delle impostazioni spetta agli amministratori. Il fatto che i prodotti Microsoft abbiano programmi di installazione semplici, utilità di amministrazione grafica e capacità di lavorare offline non significa che questa sia una variante ottimale.
Non consideriamo tali opzioni di ottimizzazione del database come accelerazione hardware. Se tutte le opzioni di ottimizzazione sono esaurite, è meglio pensare all'aggiornamento, poiché l'accelerazione hardware influisce negativamente sull'affidabilità del sistema.
La cosa più importante è che qualsiasi ottimizzazione del server di database o qualsiasi aggiornamento non aiuterà se le query non sono ottimizzate.