Tutti i moderni sistemi di database supportano un modulo Query Optimizer per identificare automaticamente la strategia più efficiente per l'esecuzione delle query SQL. La strategia efficiente si chiama “Piano” ed è misurata in termini di costo che è direttamente proporzionale al “Tempo di esecuzione/risposta della query”. Il piano è rappresentato sotto forma di un output ad albero da Query Optimizer. I nodi dell'albero del piano possono essere suddivisi principalmente nelle seguenti 3 categorie:
- Scansione nodi :Come spiegato nel mio blog precedente "Una panoramica dei vari metodi di scansione in PostgreSQL", indica il modo in cui i dati di una tabella di base devono essere recuperati.
- Unisciti ai nodi :Come spiegato nel mio precedente blog "An Overview of the JOIN Methods in PostgreSQL", indica come due tabelle devono essere unite per ottenere il risultato di due tabelle.
- Nodi di materializzazione :Chiamati anche nodi ausiliari. I due tipi di nodi precedenti erano correlati a come recuperare i dati da una tabella di base e come unire i dati recuperati da due tabelle. I nodi in questa categoria vengono applicati in cima ai dati recuperati al fine di analizzare ulteriormente o preparare report, ecc. Ordinamento dei dati, aggregazione di dati, ecc.
Considera un semplice esempio di query come...
SELECT * FROM TBL1, TBL2 where TBL1.ID > TBL2.ID order by TBL.ID;Supponiamo un piano generato corrispondente alla query come di seguito:
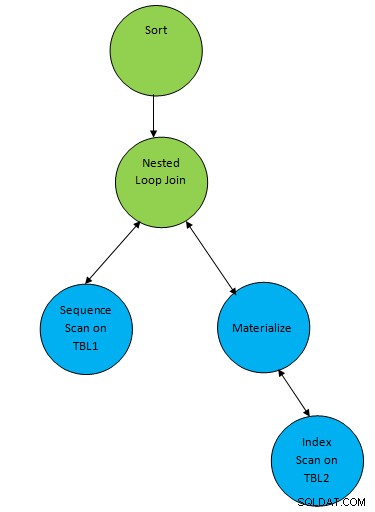
Quindi qui un nodo ausiliario "Ordina" viene aggiunto in cima al risultato di join per ordinare i dati nell'ordine richiesto.
Alcuni dei nodi ausiliari generati da PostgreSQL Query Optimizer sono i seguenti:
- Ordina
- Aggregati
- Raggruppa per aggregato
- Limite
- Unico
- LockRows
- SetOp
Capiamo ognuno di questi nodi.
Ordina
Come suggerisce il nome, questo nodo viene aggiunto come parte di un albero del piano ogni volta che è necessario disporre di dati ordinati. I dati ordinati possono essere richiesti in modo esplicito o implicito come di seguito nei due casi:
Lo scenario utente richiede dati ordinati come output. In questo caso, il nodo Ordina può essere in cima all'intero recupero dei dati, comprese tutte le altre elaborazioni.
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 10000);
INSERT 0 10000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demotable order by num;
QUERY PLAN
----------------------------------------------------------------------
Sort (cost=819.39..844.39 rows=10000 width=15)
Sort Key: num
-> Seq Scan on demotable (cost=0.00..155.00 rows=10000 width=15)
(3 rows)Nota: Anche se l'utente ha richiesto l'output finale in ordine, il nodo Ordina potrebbe non essere aggiunto al piano finale se è presente un indice nella tabella e nella colonna di ordinamento corrispondenti. In questo caso, può scegliere la scansione dell'indice che risulterà in un ordine di dati ordinato in modo implicito. Ad esempio, creiamo un indice sull'esempio sopra e vediamo il risultato:
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# explain select * from demotable order by num;
QUERY PLAN
--------------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.29..534.28 rows=10000 width=15)
(1 row)Come spiegato nel mio blog precedente Una panoramica dei metodi JOIN in PostgreSQL, Merge Join richiede che entrambi i dati della tabella siano ordinati prima di unirsi. Quindi può accadere che Merge Join sia più economico di qualsiasi altro metodo di join anche con un costo aggiuntivo di smistamento. Quindi, in questo caso, il nodo Sort verrà aggiunto tra il metodo join e scan della tabella in modo che i record ordinati possano essere passati al metodo join.
postgres=# create table demo1(id int, id2 int);
CREATE TABLE
postgres=# insert into demo1 values(generate_series(1,1000), generate_series(1,1000));
INSERT 0 1000
postgres=# create table demo2(id int, id2 int);
CREATE TABLE
postgres=# create index demoidx2 on demo2(id);
CREATE INDEX
postgres=# insert into demo2 values(generate_series(1,100000), generate_series(1,100000));
INSERT 0 100000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
------------------------------------------------------------------------------------
Merge Join (cost=65.18..109.82 rows=1000 width=16)
Merge Cond: (demo2.id = demo1.id)
-> Index Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(6 rows)Aggrega
Il nodo aggregato viene aggiunto come parte di un albero del piano se è presente una funzione di aggregazione utilizzata per calcolare risultati singoli da più righe di input. Alcune delle funzioni aggregate utilizzate sono COUNT, SUM, AVG (MEDIA), MAX (MASSIMO) e MIN (MINIMO).
Un nodo aggregato può trovarsi in cima a una scansione di relazioni di base o (e) all'unione di relazioni. Esempio:
postgres=# explain select count(*) from demo1;
QUERY PLAN
---------------------------------------------------------------
Aggregate (cost=17.50..17.51 rows=1 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=0)
(2 rows)
postgres=# explain select sum(demo1.id) from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
-----------------------------------------------------------------------------------------------
Aggregate (cost=112.32..112.33 rows=1 width=8)
-> Merge Join (cost=65.18..109.82 rows=1000 width=4)
Merge Cond: (demo2.id = demo1.id)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=4)
-> Sort (cost=64.83..67.33 rows=1000 width=4)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)HashAggregate/GroupAggregate
Questi tipi di nodi sono estensioni del nodo "Aggregate". Se le funzioni di aggregazione vengono utilizzate per combinare più righe di input in base al relativo gruppo, questi tipi di nodi vengono aggiunti a un albero del piano. Pertanto, se la query ha una funzione di aggregazione utilizzata e insieme a questa è presente una clausola GROUP BY nella query, il nodo HashAggregate o GroupAggregate verrà aggiunto all'albero del piano.
Poiché PostgreSQL utilizza Cost Based Optimizer per generare un albero del piano ottimale, è quasi impossibile indovinare quale di questi nodi verrà utilizzato. Ma cerchiamo di capire quando e come viene utilizzato.
HashAggregate
HashAggregate funziona costruendo la tabella hash dei dati per raggrupparli. Quindi HashAggregate può essere utilizzato dall'aggregato a livello di gruppo se l'aggregazione si verifica su un set di dati non ordinato.
postgres=# explain select count(*) from demo1 group by id2;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=20.00..30.00 rows=1000 width=12)
Group Key: id2
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)Qui i dati dello schema della tabella demo1 sono come nell'esempio mostrato nella sezione precedente. Poiché ci sono solo 1000 righe da raggruppare, la risorsa richiesta per creare una tabella hash è inferiore al costo dell'ordinamento. Il pianificatore di query decide di scegliere HashAggregate.
GroupAggregate
GroupAggregate funziona su dati ordinati, quindi non richiede alcuna struttura dati aggiuntiva. GroupAggregate può essere utilizzato dall'aggregato a livello di gruppo se l'aggregazione è su un set di dati ordinato. Per raggruppare i dati ordinati, può ordinare in modo esplicito (aggiungendo il nodo Ordina) o potrebbe funzionare sui dati recuperati dall'indice, nel qual caso viene ordinato implicitamente.
postgres=# explain select count(*) from demo2 group by id2;
QUERY PLAN
-------------------------------------------------------------------------
GroupAggregate (cost=9747.82..11497.82 rows=100000 width=12)
Group Key: id2
-> Sort (cost=9747.82..9997.82 rows=100000 width=4)
Sort Key: id2
-> Seq Scan on demo2 (cost=0.00..1443.00 rows=100000 width=4)
(5 rows) Qui i dati dello schema della tabella demo2 sono come nell'esempio mostrato nella sezione precedente. Poiché qui ci sono 100000 righe da raggruppare, la risorsa richiesta per creare una tabella hash potrebbe essere più costosa del costo dell'ordinamento. Quindi il pianificatore di query decide di scegliere GroupAggregate. Osserva qui che i record selezionati dalla tabella “demo2” sono ordinati in modo esplicito e per i quali è stato aggiunto un nodo nell'albero del piano.
Vedi sotto un altro esempio, dove i dati sono già recuperati ordinati a causa della scansione dell'indice:
postgres=# create index idx1 on demo1(id);
CREATE INDEX
postgres=# explain select sum(id2), id from demo1 where id=1 group by id;
QUERY PLAN
------------------------------------------------------------------------
GroupAggregate (cost=0.28..8.31 rows=1 width=12)
Group Key: id
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(4 rows) Vedi sotto un altro esempio, che anche se ha la scansione dell'indice, deve comunque ordinare in modo esplicito poiché la colonna su cui l'indice e la colonna di raggruppamento non sono gli stessi. Quindi deve ancora ordinare secondo la colonna di raggruppamento.
postgres=# explain select sum(id), id2 from demo1 where id=1 group by id2;
QUERY PLAN
------------------------------------------------------------------------------
GroupAggregate (cost=8.30..8.32 rows=1 width=12)
Group Key: id2
-> Sort (cost=8.30..8.31 rows=1 width=8)
Sort Key: id2
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(6 rows)Nota: GroupAggregate/HashAggregate può essere utilizzato per molte altre query indirette anche se l'aggregazione con il gruppo non è presente nella query. Dipende da come il pianificatore interpreta la query. Per esempio. Supponiamo di dover ottenere un valore distinto dalla tabella, quindi può essere visto come un gruppo dalla colonna corrispondente e quindi prendere un valore da ciascun gruppo.
postgres=# explain select distinct(id) from demo1;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=17.50..27.50 rows=1000 width=4)
Group Key: id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)Quindi qui viene utilizzato HashAggregate anche se non ci sono aggregazioni e gruppi coinvolti.
Limite
I nodi limite vengono aggiunti all'albero del piano se nella query SELECT viene utilizzata la clausola "limit/offset". Questa clausola viene utilizzata per limitare il numero di righe e, facoltativamente, fornire un offset per iniziare a leggere i dati. Esempio sotto:
postgres=# explain select * from demo1 offset 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.15..15.00 rows=990 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.00..0.15 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 offset 5 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.07..0.22 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)Unico
Questo nodo viene selezionato per ottenere un valore distinto dal risultato sottostante. Si noti che a seconda della query, della selettività e di altre informazioni sulle risorse, il valore distinto può essere recuperato utilizzando HashAggregate/GroupAggregate anche senza utilizzare il nodo Unique. Esempio:
postgres=# explain select distinct(id) from demo2 where id<100;
QUERY PLAN
-----------------------------------------------------------------------------------
Unique (cost=0.29..10.27 rows=99 width=4)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..10.03 rows=99 width=4)
Index Cond: (id < 100)
(3 rows)LockRows
PostgreSQL fornisce funzionalità per bloccare tutte le righe selezionate. Le righe possono essere selezionate in modalità “Condivisa” o “Esclusiva” a seconda rispettivamente delle clausole “FOR SHARE” e “FOR UPDATE”. Un nuovo nodo "LockRows" viene aggiunto all'albero del piano per realizzare questa operazione.
postgres=# explain select * from demo1 for update;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)
postgres=# explain select * from demo1 for share;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)SetOp
PostgreSQL fornisce funzionalità per combinare i risultati di due o più query. Quindi, quando il tipo di nodo Join viene selezionato per unire due tabelle, viene selezionato un tipo simile di nodo SetOp per combinare i risultati di due o più query. Ad esempio, considera una tabella con i dipendenti con il loro ID, nome, età e stipendio come di seguito:
postgres=# create table emp(id int, name char(20), age int, salary int);
CREATE TABLE
postgres=# insert into emp values(1,'a', 30,100);
INSERT 0 1
postgres=# insert into emp values(2,'b', 31,90);
INSERT 0 1
postgres=# insert into emp values(3,'c', 40,105);
INSERT 0 1
postgres=# insert into emp values(4,'d', 20,80);
INSERT 0 1 Ora prendiamo dipendenti con età superiore a 25 anni:
postgres=# select * from emp where age > 25;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
2 | b | 31 | 90
3 | c | 40 | 105
(3 rows) Ora prendiamo dipendenti con uno stipendio superiore a 95 milioni:
postgres=# select * from emp where salary > 95;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
3 | c | 40 | 105
(2 rows)Ora per ottenere dipendenti con età superiore a 25 anni e stipendio superiore a 95 milioni, possiamo scrivere di seguito la query di intersezione:
postgres=# explain select * from emp where age>25 intersect select * from emp where salary > 95;
QUERY PLAN
---------------------------------------------------------------------------------
HashSetOp Intersect (cost=0.00..72.90 rows=185 width=40)
-> Append (cost=0.00..64.44 rows=846 width=40)
-> Subquery Scan on "*SELECT* 1" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp (cost=0.00..25.88 rows=423 width=36)
Filter: (age > 25)
-> Subquery Scan on "*SELECT* 2" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp emp_1 (cost=0.00..25.88 rows=423 width=36)
Filter: (salary > 95)
(8 rows) Quindi qui viene aggiunto un nuovo tipo di nodo HashSetOp per valutare l'intersezione di queste due singole query.
Nota che ci sono altri due tipi di nuovi nodi aggiunti qui:
Aggiungi
Questo nodo viene aggiunto per combinare più risultati impostati in uno.
Scansione sottoquery
Questo nodo viene aggiunto per valutare qualsiasi sottoquery. Nel piano precedente, la sottoquery viene aggiunta per valutare un valore di colonna costante aggiuntivo che indica quale set di input ha contribuito a una riga specifica.
HashedSetop funziona utilizzando l'hash del risultato sottostante, ma è possibile generare un'operazione SetOp basata sull'ordinamento tramite Query Optimizer. Il nodo Setop basato sull'ordinamento è indicato come "Setop".
Nota:è possibile ottenere lo stesso risultato mostrato nel risultato precedente con una singola query, ma qui viene mostrato utilizzando intersect solo per una facile dimostrazione.
Conclusione
Tutti i nodi di PostgreSQL sono utili e vengono selezionati in base alla natura della query, dei dati, ecc. Molte delle clausole sono mappate uno a uno con i nodi. Per alcune clausole ci sono più opzioni per i nodi, che vengono decise in base ai calcoli del costo dei dati sottostanti.