I nomi dei prodotti software IRI e il modo in cui funzionano sono stati a volte fonte di mistero, o addirittura confusione, per chi non lo sapesse. Questo articolo spiega i pezzi e chiarisce la loro interazione, fornendo una rapida introduzione per potenziali utenti, partner e analisi del nuovo settore m.
Dove tutto ebbe inizio
Ha avuto inizio con IRI CoSort nel 1978, l'utilità di smistamento, trasformazione e reporting di big data per Unix e Windows ancora ampiamente utilizzata oggi. Prima di CoSort, questo primo prodotto IRI si chiamava CO-SORT, COSORT e CoSORT, in quest'ordine.

Nel 1992, IRI ha aggiunto il programma di manipolazione e sintassi per la definizione dei dati Sort Control Language (SortCL) alle altre utilità e API nel pacchetto CoSort. Oggi, SortCL è l'interfaccia utente più utilizzata e ricca di funzionalità nel pacchetto CoSort.
Gli script SortCL definiscono, e il programma sortcl viene eseguito, i lavori che eseguono e combinano molti movimenti di dati comuni e attività di mappatura che gli utenti di CoSort devono eseguire. SortCL non è solo un semplice 4GL da imparare, leggere e modificare, ma è anche supportato tramite un'API (chiamata sortcl_routine) e graficamente nell'IDE IRI Workbench gratuito, basato su Eclipse.
Con l'espansione della funzionalità SortCL, ha superato il tradizionale mercato CoSort per le migrazioni di ordinamento e l'accelerazione BI/DW. Oggi, l'eseguibile SortCL non è solo il motore che esegue la maggior parte dei lavori CoSort, ma è il cuore pulsante di numerosi prodotti spin-off, illustrati qui:

Prodotti spin-off CoSort/SortCL
In particolare, lo stesso motore SortCL e gli script di lavoro compatibili, generalmente progettati e spesso gestiti da IRI Workbench, elaborano origini dati strutturate in:
- IRI FieldShield e IRI DarkShield per il mascheramento dei dati
- IRI RowGen per la sintesi dei dati di test e il sottoinsieme di database
- IRI NextForm per la conversione e la replica di dati e database e, il
- Lavori della piattaforma di gestione dei dati IRI Voracity, che includono quelli in CoSort e i prodotti collegati sopra, più funzionalità front-end aggiuntive tramite la GUI di Workbench comune, come:
- Scoperta dei dati (profilazione, classificazione e ricerca)
- Data warehouse ETL, CDC e SDC
- Migrazione e prototipazione di Data Vault 2.0
- Qualità dei dati (convalida, pulizia, omogeneizzazione)
- Analisi o data wrangling per Splunk e KNIME e altri strumenti BI tramite handoff
Un altro modo per guardare alla gerarchia dei prodotti è questo:

dove l'IDE di Workbench è il luogo in cui vengono progettati tutti i lavori dei prodotti IRI, comprese quelle funzionalità aggiuntive supportate in Voracity.
Una domanda frequente
Dato che SortCL è iniziato con CoSort ed è comune a tutti questi prodotti, questo significa che posso usare CoSort o un altro prodotto sopra per fare ciò che fanno anche gli altri prodotti?
La risposta è sì e no. Sì, hai SortCL e in teoria puoi svolgere parte dello stesso lavoro che dovrebbe eseguire un altro prodotto IRI compatibile con SortCL. Ma sarebbe più difficile e rappresenta un rischio produttivo. IRI fornisce solo documentazione e supporto per le attività meglio associate ai prodotti IRI con licenza.
Pertanto, la capacità di crossover è in pratica limitata. Tuttavia, la funzionalità combinatoria è comune in molti casi (come un sottoinsieme DB ordinato) e in Voracity, i casi d'uso multi-task e multi-step (come mappatura incrementale, mascheratura, pulizia e riformattazione) sono altamente efficienti e completamente supportati.
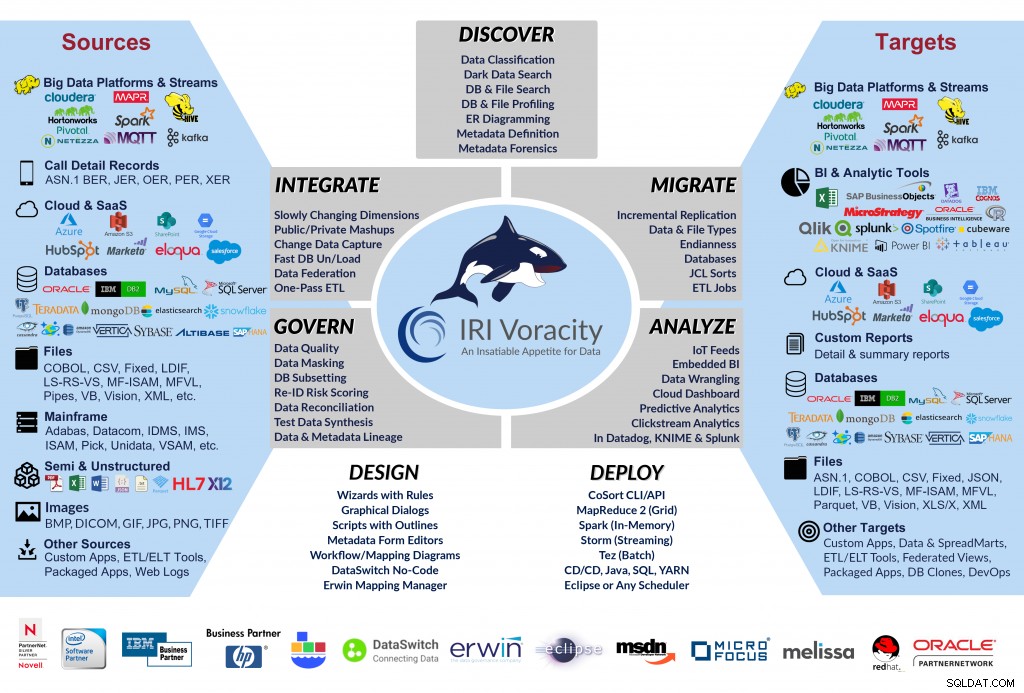 SortCL è il motore predefinito in tutti i CDC IRI Voracity, ETL, CDC, cleansing, reconciliation, subsetting ,
SortCL è il motore predefinito in tutti i CDC IRI Voracity, ETL, CDC, cleansing, reconciliation, subsetting ,
Mascheramento PII, sintesi dei dati di test, conversione, riformattazione, discussione, analisi e creazione di rapporti.
Architettura di runtime
Ora che conosci i nomi dei prodotti, spieghiamo come si relazionano e si distribuiscono.
Il software IRI di solito funziona in un modello client/server, in cui i lavori compatibili con SortCL sono definiti in un ambiente di editing front-end come IRI Workbench o un altro editor di testo, o tramite l'API IRI. Questi lavori di solito vengono eseguiti nel programma back-end SortCL su macchine Linux, Unix o Windows (fisiche o virtuali), on-premise o nel cloud:

Alcuni lavori scritti nella sintassi SortCL possono anche essere eseguiti senza modifiche direttamente in Map Reduce 2, Spark, Spark Stream, Story o Tez per i licenziatari dell'edizione Voracity Grid (VGrid) per Hadoop.
Si noti tuttavia che, a differenza di molti altri programmi ETL e di mascheramento dei dati, non esiste un server CoSort in cui SortCL deve essere eseguito o gestito centralmente. Il leggero eseguibile SortCL può essere eseguito ovunque, da un Raspberry Pi a un mainframe z/Linux.

È quindi comune, secondo il diagramma precedente, che i siti abbiano istanze di test e QA SortCL installate sui laptop degli sviluppatori che eseguono IRI Workbench, nonché su file centralizzati o server di database per ottimizzare le prestazioni. Questa FAQ copre la questione di dove concedere in licenza SortCL nel contesto dei prodotti di mascheramento dei dati IRI, ad esempio, e come calcolarne i costi di conseguenza.
In caso di domande sul prodotto IRI di cui hai bisogno o su come implementarlo al meglio sull'hardware di cui disponi (o prevedi di effettuare il provisioning), contatta il tuo rappresentante IRI.