Il bucket dei dati di data e ora implica l'organizzazione dei dati in gruppi che rappresentano intervalli di tempo fissi per scopi analitici. Spesso l'input è costituito da dati di serie temporali archiviati in una tabella in cui le righe rappresentano misurazioni effettuate a intervalli di tempo regolari. Ad esempio, le misurazioni potrebbero essere letture di temperatura e umidità effettuate ogni 5 minuti e si desidera raggruppare i dati utilizzando intervalli orari e calcolare aggregati come la media oraria. Anche se i dati delle serie temporali sono una fonte comune per l'analisi basata su bucket, il concetto è altrettanto rilevante per tutti i dati che coinvolgono attributi di data e ora e misure associate. Ad esempio, potresti voler organizzare i dati sulle vendite in bucket dell'anno fiscale e calcolare aggregati come il valore totale delle vendite per anno fiscale. In questo articolo, tratterò due metodi per il bucket dei dati di data e ora. Uno sta usando una funzione denominata DATE_BUCKET, che al momento della scrittura è disponibile solo in Azure SQL Edge. Un altro è l'uso di un calcolo personalizzato che emula la funzione DATE_BUCKET, che puoi usare in qualsiasi versione, edizione e versione di SQL Server e del database SQL di Azure.
Nei miei esempi, userò il database di esempio TSQLV5. Puoi trovare lo script che crea e popola TSQLV5 qui e il suo diagramma ER qui.
DATE_BUCKET
Come accennato, la funzione DATE_BUCKET è attualmente disponibile solo in Azure SQL Edge. SQL Server Management Studio dispone già del supporto IntelliSense, come illustrato nella figura 1:
 Figura 1:supporto di Intellisence per DATE_BUCKET in SSMS
Figura 1:supporto di Intellisence per DATE_BUCKET in SSMS
La sintassi della funzione è la seguente:
DATE_BUCKET (L'input origine rappresenta un punto di ancoraggio sulla freccia del tempo. Può essere di uno qualsiasi dei tipi di dati di data e ora supportati. Se non specificato, l'impostazione predefinita è 1900, 1 gennaio, mezzanotte. Puoi quindi immaginare la sequenza temporale divisa in intervalli discreti che iniziano con il punto di origine, dove la lunghezza di ciascun intervallo è basata sugli input larghezza del secchio e parte data . La prima è la quantità e la seconda è l'unità. Ad esempio, per organizzare la sequenza temporale in unità di 2 mesi, devi specificare 2 come larghezza del secchio input e mese come parte della data input.
L'input timestamp è un momento arbitrario che deve essere associato al suo bucket che lo contiene. Il suo tipo di dati deve corrispondere al tipo di dati dell'input origine . L'input timestamp è il valore di data e ora associato alle misure che stai acquisendo.
L'output della funzione è quindi il punto di partenza del bucket contenitore. Il tipo di dati dell'output è quello dell'input timestamp .
Se non fosse già ovvio, di solito dovresti usare la funzione DATE_BUCKET come elemento di raggruppamento nella clausola GROUP BY della query e naturalmente restituirla anche nell'elenco SELECT, insieme alle misure aggregate.
Ancora un po' confuso riguardo alla funzione, ai suoi input e al suo output? Forse un esempio specifico con una rappresentazione visiva della logica della funzione aiuterebbe. Inizierò con un esempio che utilizza le variabili di input e più avanti nell'articolo dimostrerai il modo più tipico in cui lo useresti come parte di una query su una tabella di input.
Considera il seguente esempio:
DECLARE @timestamp AS DATETIME2 = '20210510 06:30:00', @bucketwidth AS INT = 2, @origin AS DATETIME2 = '20210115 00:00:00'; SELECT DATE_BUCKET(month, @bucketwidth, @timestamp, @origin);
È possibile trovare una rappresentazione visiva della logica della funzione nella Figura 2.
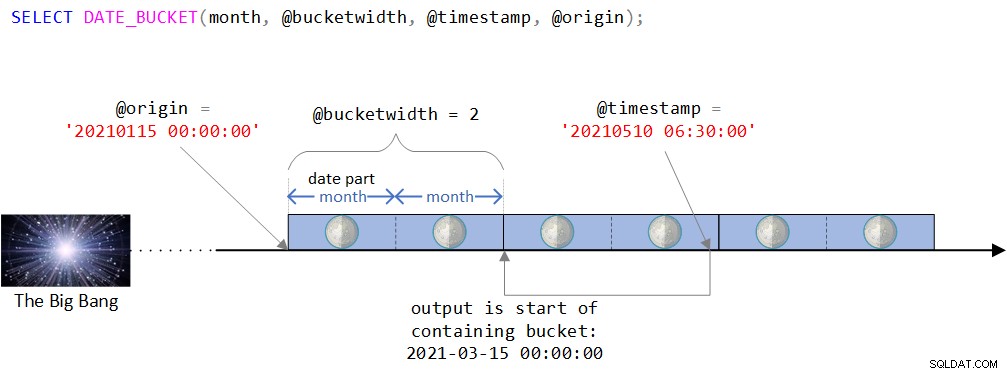 Figura 2:Rappresentazione visiva della logica della funzione DATE_BUCKET
Figura 2:Rappresentazione visiva della logica della funzione DATE_BUCKET
Come puoi vedere nella Figura 2, il punto di origine è il valore DATETIME2 15 gennaio 2021, mezzanotte. Se questo punto di origine sembra un po' strano, avresti ragione a percepire intuitivamente che normalmente ne useresti uno più naturale come l'inizio di un anno o l'inizio di un giorno. In effetti, saresti spesso soddisfatto dell'impostazione predefinita, che come ricordi è il 1 gennaio 1900 a mezzanotte. Volevo intenzionalmente utilizzare un punto di origine meno banale per poter discutere alcune complessità che potrebbero non essere rilevanti quando si utilizza uno più naturale. Maggiori informazioni su questo a breve.
La sequenza temporale viene quindi suddivisa in intervalli discreti di 2 mesi a partire dal punto di origine. Il timestamp di input è il valore DATETIME2 10 maggio 2021, 6:30.
Osserva che il timestamp di input fa parte del bucket che inizia il 15 marzo 2021 a mezzanotte. In effetti, la funzione restituisce questo valore come un valore digitato DATETIME2:
--------------------------- 2021-03-15 00:00:00.0000000
Emulare DATE_BUCKET
A meno che tu non stia usando Azure SQL Edge, se vuoi inserire in un bucket i dati di data e ora, per il momento dovrai creare la tua soluzione personalizzata per emulare ciò che fa la funzione DATE_BUCKET. Farlo non è eccessivamente complesso, ma non è nemmeno troppo semplice. La gestione dei dati di data e ora comporta spesso una logica complicata e insidie a cui devi prestare attenzione.
Costruirò il calcolo in passaggi e utilizzerò gli stessi input che ho usato con l'esempio DATE_BUCKET che ho mostrato in precedenza:
DECLARE @timestamp AS DATETIME2 = '20210510 06:30:00', @bucketwidth AS INT = 2, @origin AS DATETIME2 = '20210115 00:00:00';
Assicurati di includere questa parte prima di ciascuno degli esempi di codice che mostrerò se desideri effettivamente eseguire il codice.
Nel passaggio 1, utilizzi la funzione DATEDIFF per calcolare la differenza nella parte data unità tra origine e timestamp . Farò riferimento a questa differenza come diff1 . Questo viene fatto con il seguente codice:
SELECT DATEDIFF(month, @origin, @timestamp) AS diff1;
Con i nostri input di esempio, questa espressione restituisce 4.
La parte difficile qui è che devi calcolare quante unità intere di parte data esistono tra origine e timestamp . Con i nostri input di esempio, ci sono 3 mesi interi tra i due e non 4. Il motivo per cui la funzione DATEDIFF riporta 4 è che, quando calcola la differenza, guarda solo la parte richiesta degli input e le parti superiori ma non le parti inferiori . Quindi, quando chiedi la differenza in mesi, la funzione si preoccupa solo delle parti dell'anno e del mese degli input e non delle parti al di sotto del mese (giorno, ora, minuti, secondi, ecc.). In effetti, ci sono 4 mesi tra gennaio 2021 e maggio 2021, ma solo 3 mesi interi tra gli input completi.
Lo scopo del passaggio 2 è quindi calcolare quante unità intere di parte data esistono tra origine e timestamp . Farò riferimento a questa differenza come diff2 . Per ottenere ciò, puoi aggiungere diff1 unità di parte data all'origine . Se il risultato è maggiore di timestamp , sottrai 1 da diff1 per calcolare diff2 , altrimenti sottrai 0 e quindi usa diff1 come diff2 . Questo può essere fatto usando un'espressione CASE, in questo modo:
SELECT
DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END AS diff2; Questa espressione restituisce 3, che è il numero di mesi interi tra i due input.
Ricordiamo che prima ho menzionato che nel mio esempio ho usato intenzionalmente un punto di origine che non è naturale come l'inizio rotondo di un periodo in modo da poter discutere alcune complessità che poi potrebbero essere rilevanti. Ad esempio, se utilizzi mese come parte della data e l'inizio esatto di un mese (1 di un mese a mezzanotte) come origine, puoi tranquillamente saltare il passaggio 2 e utilizzare diff1 come diff2 . Questo perché origine + differenza1 non può mai essere> timestamp in tal caso. Tuttavia, il mio obiettivo è fornire un'alternativa logicamente equivalente alla funzione DATE_BUCKET che funzioni correttamente per qualsiasi punto di origine, comune o meno. Quindi, includerò la logica per il passaggio 2 nei miei esempi, ma ricorda solo che quando identifichi i casi in cui questo passaggio non è rilevante, puoi rimuovere in sicurezza la parte in cui sottrai l'output dell'espressione CASE.
Nel passaggio 3 identifichi quante unità di parte data ci sono interi bucket che esistono tra origine e timestamp . Farò riferimento a questo valore come diff3 . Questo può essere fatto con la seguente formula:
diff3 = diff2 / <bucket width> * <bucket width>
Il trucco qui è che quando si utilizza l'operatore di divisione / in T-SQL con operandi interi, si ottiene una divisione intera. Ad esempio, 3 / 2 in T-SQL è 1 e non 1,5. L'espressione diff2 /
SELECT
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth AS diff3; Questa espressione restituisce 2, che è il numero di mesi negli interi bucket di 2 mesi esistenti tra i due input.
Nel passaggio 4, che è il passaggio finale, aggiungi diff3 unità di parte data all'origine per calcolare l'inizio del bucket contenitore. Ecco il codice per raggiungere questo obiettivo:
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Questo codice genera il seguente output:
--------------------------- 2021-03-15 00:00:00.0000000
Come ricorderete, questo è lo stesso output prodotto dalla funzione DATE_BUCKET per gli stessi input.
Ti suggerisco di provare questa espressione con vari input e parti. Mostrerò qui alcuni esempi, ma sentiti libero di provare il tuo.
Ecco un esempio in cui origine è leggermente più avanti di timestamp nel mese:
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210110 06:30:01';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Questo codice genera il seguente output:
--------------------------- 2021-03-10 06:30:01.0000000
Nota che l'inizio del bucket di contenimento è a marzo.
Ecco un esempio in cui origine è nello stesso punto all'interno del mese di timestamp :
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210110 06:30:00';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Questo codice genera il seguente output:
--------------------------- 2021-05-10 06:30:00.0000000
Nota che questa volta l'inizio del bucket di contenimento è a maggio.
Ecco un esempio con bucket di 4 settimane:
DECLARE
@timestamp AS DATETIME2 = '20210303 21:22:11',
@bucketwidth AS INT = 4,
@origin AS DATETIME2 = '20210115';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
week,
( DATEDIFF(week, @origin, @timestamp)
- CASE
WHEN DATEADD(
week,
DATEDIFF(week, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Nota che il codice usa la settimana parte questa volta.
Questo codice genera il seguente output:
--------------------------- 2021-02-12 00:00:00.0000000
Ecco un esempio con intervalli di 15 minuti:
DECLARE
@timestamp AS DATETIME2 = '20210203 21:22:11',
@bucketwidth AS INT = 15,
@origin AS DATETIME2 = '19000101';
-- SELECT DATE_BUCKET(minute, @bucketwidth, @timestamp);
SELECT DATEADD(
minute,
( DATEDIFF(minute, @origin, @timestamp)
- CASE
WHEN DATEADD(
minute,
DATEDIFF(minute, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Questo codice genera il seguente output:
--------------------------- 2021-02-03 21:15:00.0000000
Nota che la parte è minuta . In questo esempio, desideri utilizzare intervalli di 15 minuti a partire dalla fine dell'ora, in modo che un punto di origine che sia la fine di qualsiasi ora funzionerebbe. In effetti, un punto di origine che ha un'unità dei minuti di 00, 15, 30 o 45 con zeri nelle parti inferiori, con qualsiasi data e ora funzionerebbe. Quindi l'impostazione predefinita utilizzata dalla funzione DATE_BUCKET per l'input origine funzionerebbe. Ovviamente, quando si utilizza l'espressione personalizzata, è necessario essere espliciti sul punto di origine. Quindi, per simpatizzare con la funzione DATE_BUCKET, potresti usare la data di base a mezzanotte come faccio nell'esempio sopra.
Per inciso, puoi capire perché questo sarebbe un buon esempio in cui è perfettamente sicuro saltare il passaggio 2 nella soluzione? Se hai scelto di saltare il passaggio 2, ottieni il seguente codice:
DECLARE
@timestamp AS DATETIME2 = '20210203 21:22:11',
@bucketwidth AS INT = 15,
@origin AS DATETIME2 = '19000101';
-- SELECT DATE_BUCKET(minute, @bucketwidth, @timestamp);
SELECT DATEADD(
minute,
( DATEDIFF( minute, @origin, @timestamp ) ) / @bucketwidth * @bucketwidth,
@origin
); Chiaramente, il codice diventa notevolmente più semplice quando il passaggio 2 non è necessario.
Raggruppamento e aggregazione dei dati per intervalli di data e ora
Ci sono casi in cui è necessario inserire in un bucket i dati di data e ora che non richiedono funzioni sofisticate o espressioni ingombranti. Si supponga, ad esempio, di voler eseguire una query sulla vista Sales.OrderValues nel database TSQLV5, raggruppare i dati ogni anno e calcolare i conteggi e i valori totali degli ordini per anno. Chiaramente, è sufficiente utilizzare la funzione YEAR(orderdate) come elemento del gruppo di raggruppamento, in questo modo:
USE TSQLV5; SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues GROUP BY YEAR(orderdate) ORDER BY orderyear;
Questo codice genera il seguente output:
orderyear numorders totalvalue ----------- ----------- ----------- 2017 152 208083.99 2018 408 617085.30 2019 270 440623.93
Ma cosa accadrebbe se volessi raggruppare i dati in un bucket in base all'anno fiscale della tua organizzazione? Alcune organizzazioni utilizzano un anno fiscale per scopi contabili, di budget e di rendicontazione finanziaria, non allineato con l'anno solare. Supponiamo, ad esempio, che l'anno fiscale della tua organizzazione operi in un calendario fiscale da ottobre a settembre e sia indicato dall'anno solare in cui termina l'anno fiscale. Quindi un evento che ha avuto luogo il 3 ottobre 2018 appartiene all'anno fiscale iniziato il 1 ottobre 2018, terminato il 30 settembre 2019 ed è indicato con l'anno 2019.
Questo è abbastanza facile da ottenere con la funzione DATE_BUCKET, in questo modo:
DECLARE @bucketwidth AS INT = 1, @origin AS DATETIME2 = '19001001'; -- this is Oct 1 of some year SELECT YEAR(startofbucket) + 1 AS fiscalyear, COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues CROSS APPLY ( VALUES( DATE_BUCKET( year, @bucketwidth, orderdate, @origin ) ) ) AS A(startofbucket) GROUP BY startofbucket ORDER BY startofbucket;
Ed ecco il codice che utilizza l'equivalente logico personalizzato della funzione DATE_BUCKET:
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATETIME2 = '19001001'; -- this is Oct 1 of some year
SELECT
YEAR(startofbucket) + 1 AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
DATEADD(
year,
( DATEDIFF(year, @origin, orderdate)
- CASE
WHEN DATEADD(
year,
DATEDIFF(year, @origin, orderdate),
@origin) > orderdate
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket; Questo codice genera il seguente output:
fiscalyear numorders totalvalue ----------- ----------- ----------- 2017 70 79728.58 2018 370 563759.24 2019 390 622305.40
Ho usato le variabili qui per la larghezza del bucket e il punto di origine per rendere il codice più generalizzato, ma puoi sostituirle con costanti se usi sempre le stesse, quindi semplificare il calcolo in base alle esigenze.
Come leggera variazione di quanto sopra, supponiamo che il tuo anno fiscale vada dal 15 luglio di un anno solare al 14 luglio dell'anno solare successivo e sia indicato dall'anno solare a cui appartiene l'inizio dell'anno fiscale. Quindi un evento che ha avuto luogo il 18 luglio 2018 appartiene all'anno fiscale 2018. Un evento che ha avuto luogo il 14 luglio 2018 appartiene all'anno fiscale 2017. Usando la funzione DATE_BUCKET, otterresti questo in questo modo:
DECLARE @bucketwidth AS INT = 1, @origin AS DATETIME2 = '19000715'; -- July 15 marks start of fiscal year SELECT YEAR(startofbucket) AS fiscalyear, -- no need to add 1 here COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues CROSS APPLY ( VALUES( DATE_BUCKET( year, @bucketwidth, orderdate, @origin ) ) ) AS A(startofbucket) GROUP BY startofbucket ORDER BY startofbucket;
Puoi vedere le modifiche rispetto all'esempio precedente nei commenti.
Ed ecco il codice che utilizza l'equivalente logico personalizzato della funzione DATE_BUCKET:
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATETIME2 = '19000715';
SELECT
YEAR(startofbucket) AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
DATEADD(
year,
( DATEDIFF(year, @origin, orderdate)
- CASE
WHEN DATEADD(
year,
DATEDIFF(year, @origin, orderdate),
@origin) > orderdate
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket; Questo codice genera il seguente output:
fiscalyear numorders totalvalue ----------- ----------- ----------- 2016 8 12599.88 2017 343 495118.14 2018 479 758075.20
Ovviamente, ci sono metodi alternativi che potresti usare in casi specifici. Prendi l'esempio prima dell'ultimo, dove l'anno fiscale va da ottobre a settembre ed è indicato dall'anno solare in cui finisce l'anno fiscale. In tal caso potresti usare la seguente, molto più semplice, espressione:
YEAR(orderdate) + CASE WHEN MONTH(orderdate) BETWEEN 10 AND 12 THEN 1 ELSE 0 END
E poi la tua domanda sarebbe simile a questa:
SELECT
fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
YEAR(orderdate)
+ CASE
WHEN MONTH(orderdate) BETWEEN 10 AND 12 THEN 1
ELSE 0
END ) ) AS A(fiscalyear)
GROUP BY fiscalyear
ORDER BY fiscalyear; Tuttavia, se si desidera una soluzione generalizzata che funzioni in molti più casi e che si possa parametrizzare, è naturale utilizzare la forma più generale. Se hai accesso alla funzione DATE_BUCKET, è fantastico. In caso contrario, puoi utilizzare l'equivalente logico personalizzato.
Conclusione
La funzione DATE_BUCKET è una funzione abbastanza utile che ti consente di inserire in un bucket i dati di data e ora. È utile per gestire i dati delle serie temporali, ma anche per inserire in un bucket tutti i dati che coinvolgono attributi di data e ora. In questo articolo ho spiegato come funziona la funzione DATE_BUCKET e fornito un equivalente logico personalizzato nel caso in cui la piattaforma che stai utilizzando non lo supporti.



