In questo articolo, continuo a esplorare soluzioni per la sfida della corrispondenza tra domanda e offerta. Grazie a Luca, Kamil Kosno, Daniel Brown, Brian Walker, Joe Obbish, Rainer Hoffmann, Paul White, Charlie, Ian e Peter Larsson, per aver inviato le vostre soluzioni.
Il mese scorso ho trattato soluzioni basate su un approccio alle intersezioni di intervallo rivisto rispetto a quello classico. La più veloce di queste soluzioni combinava le idee di Kamil, Luca e Daniel. Ha unificato due query con predicati sargable disgiunti. Ci sono voluti 1,34 secondi per completare la soluzione rispetto a un input di 400.000 righe. Non è troppo malandato considerando che la soluzione basata sul classico approccio delle intersezioni di intervallo ha impiegato 931 secondi per essere completata rispetto allo stesso input. Ricordiamo inoltre che Joe ha escogitato una soluzione brillante che si basa sul classico approccio di intersezione degli intervalli ma ottimizza la logica di abbinamento inserendo gli intervalli in bucket in base alla lunghezza dell'intervallo più grande. Con lo stesso input di 400.000 righe, la soluzione di Joe ha impiegato 0,9 secondi per essere completata. La parte difficile di questa soluzione è che le sue prestazioni si riducono all'aumentare della lunghezza dell'intervallo maggiore.
Questo mese esploro soluzioni affascinanti che sono più veloci della soluzione Kamil/Luca/Daniel Revised Intersections e sono neutre rispetto alla lunghezza dell'intervallo. Le soluzioni in questo articolo sono state create da Brian Walker, Ian, Peter Larsson, Paul White e me.
Ho testato tutte le soluzioni in questo articolo rispetto alla tabella di input delle aste con 100.000, 200.000, 300.000 e 400.000 righe e con i seguenti indici:
-- Indice per supportare la soluzione CREATE UNIQUE NON CLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity); -- Abilita aggregazione finestra in modalità batch CREA INDICE COLUMNSTORE NON CLUSTERED idx_cs SU dbo.Auctions(ID) DOVE ID =-1 AND ID =-2;
Quando si descrive la logica alla base delle soluzioni, presumo che la tabella Aste sia popolata con il seguente piccolo insieme di dati di esempio:
Codice ID Quantità----------- ---- ---------1 D 5.0000002 D 3.0000003 D 8.0000005 D 2.0000006 D 8.0000007 D 4.0000008 D 2.0000001000 S 8.0000002000 S 6.000 2.0000004000 S 2.0000005000 S 4.0000006000 S 3.0000007000 S 2.000000
Di seguito è riportato il risultato desiderato per questi dati di esempio:
DemandID SupplyID TradeQuantity----------- ----------- --------------1 1000 5.0000002 1000 3.0000003 2000 6.0000003 3000 2.0000005 4000 2.0000006 5000 4.0000006 6000 3.0000006 7000 1.0000007 7000 1.000000
Soluzione di Brian Walker
I join esterni sono abbastanza comunemente usati nelle soluzioni di query SQL, ma di gran lunga quando li usi, usi quelli a lato singolo. Quando insegno sui join esterni, ricevo spesso domande che chiedono esempi per casi d'uso pratici di join esterni completi, e non ce ne sono molti. La soluzione di Brian è un bellissimo esempio di un caso d'uso pratico di join esterni completi.
Ecco il codice completo della soluzione di Brian:
TABELLA A CADUTA SE ESISTE #MyPairings; CREATE TABLE #MyPairings( DemandID INT NOT NULL, SupplyID INT NOT NULL, TradeQuantity DECIMAL(19,06) NOT NULL); CON D AS( SELECT A.ID, SUM(A.Quantity) OVER (PARTITION BY A.Code ORDER BY A.ID ROWS UNBOUNDED PRECEDENTI) AS In esecuzione DA dbo.Auctions AS A WHERE A.Code ='D'),S AS( SELECT A.ID, SUM(A.Quantity) OVER (PARTITION BY A.Code ORDER BY A.ID ROWS UNBOUNDED PRECEDENTI) AS In esecuzione DA dbo.Auctions AS A WHERE A.Code ='S'),W AS( SELECT D.ID AS DemandID, S.ID AS SupplyID, ISNULL(D.Running, S.Running) AS Running FROM D FULL JOIN S ON D.Running =S.Running),Z AS( SELEZIONA CASO QUANDO W.DemandID È NOT NULL THEN W.DemandID ELSE MIN(W.DemandID) OVER (ORDINE PER W.RUNNING RIGHE TRA LA RIGA ATTUALE E UNBOUNDED SEGUENTE) FINE COME DemandID, CASO IN CUI W.SupplyID NON È NULL THEN W.SupplyID ELSE MIN(W.SupplyID ) OVER (ORDINE PER W.Running RIGA TRA LA RIGA ATTUALE E UNBOUNDED SEGUENTE) FINE COME SupplyID, W.Running DA W)INSERT #MyPair ings(DemandID, SupplyID, TradeQuantity) SELECT Z.DemandID, Z.SupplyID, Z.Running - ISNULL(LAG(Z.Running) OVER (ORDER BY Z.Running), 0.0) COME TradeQuantity DA Z DOVE Z.DemandID NON È NULL E Z.SupplyID NON È NULL;
Ho rivisto l'uso originale di Brian delle tabelle derivate con CTE per chiarezza.
Il CTE D calcola le quantità totali della domanda in esecuzione in una colonna dei risultati denominata D.Running e il CTE S calcola le quantità totali di fornitura in esecuzione in una colonna dei risultati denominata S.Running. Il CTE W esegue quindi un join esterno completo tra D e S, facendo corrispondere D.Running con S.Running, e restituisce il primo non NULL tra D.Running e S.Running come W.Running. Ecco il risultato che ottieni se esegui query su tutte le righe di W ordinate per Esecuzione:
DemandID SupplyID In esecuzione----------- ----------- ----------1 NULL 5.0000002 1000 8.000000NULL 2000 14.0000003 3000 16.0000005 4000 18.000000 NULL 5000 22.000000 NULL 6000 25.0000006 NULL 26.000000 NULL 7000 27.0000007 NULL 30.0000008 NULL 32.000000
L'idea di utilizzare un join esterno completo basato su un predicato che confronta i totali parziali della domanda e dell'offerta è un colpo di genio! La maggior parte delle righe in questo risultato, le prime 9 nel nostro caso, rappresentano accoppiamenti di risultati con un po' di calcoli extra mancanti. Le righe con ID NULL finali di uno dei tipi rappresentano voci che non possono essere abbinate. Nel nostro caso, le ultime due righe rappresentano movimenti di domanda che non possono essere abbinati a movimenti di fornitura. Quindi, ciò che resta qui è calcolare DemandID, SupplyID e TradeQuantity degli accoppiamenti di risultati e filtrare le voci che non possono essere abbinate.
La logica che calcola il risultato DemandID e SupplyID viene eseguita nel CTE Z come segue (supponendo l'ordinamento in W tramite Running):
- DemandID:se DemandID non è NULL allora DemandID, altrimenti il minimo DemandID che inizia con la riga corrente
- SupplyID:se SupplyID non è NULL allora SupplyID, altrimenti SupplyID minimo che inizia con la riga corrente
Ecco il risultato che ottieni se interroghi Z e ordini le righe in esecuzione:
DemandID SupplyID In esecuzione----------- ----------- -----------1 1000 5.0000002 1000 8.0000003 2000 14.0000003 3000 16.0000005 4000 18.0000006 5000 22.0000006 6000 25.0000006 7000 26.0000007 7000 27.0000007 NULL 30.0000008 NULL 32.000000
La query esterna filtra le righe da Z che rappresentano voci di un tipo che non possono essere abbinate a voci dell'altro tipo assicurando che sia DemandID che SupplyID non siano NULL. La quantità commerciale degli accoppiamenti risultanti viene calcolata come il valore corrente corrente meno il valore corrente precedente utilizzando una funzione LAG.
Ecco cosa viene scritto nella tabella #MyPairings, che è il risultato desiderato:
DemandID SupplyID TradeQuantity----------- ----------- --------------1 1000 5.0000002 1000 3.0000003 2000 6.0000003 3000 2.0000005 4000 2.0000006 5000 4.0000006 6000 3.0000006 7000 1.0000007 7000 1.000000
Il piano per questa soluzione è mostrato nella Figura 1.
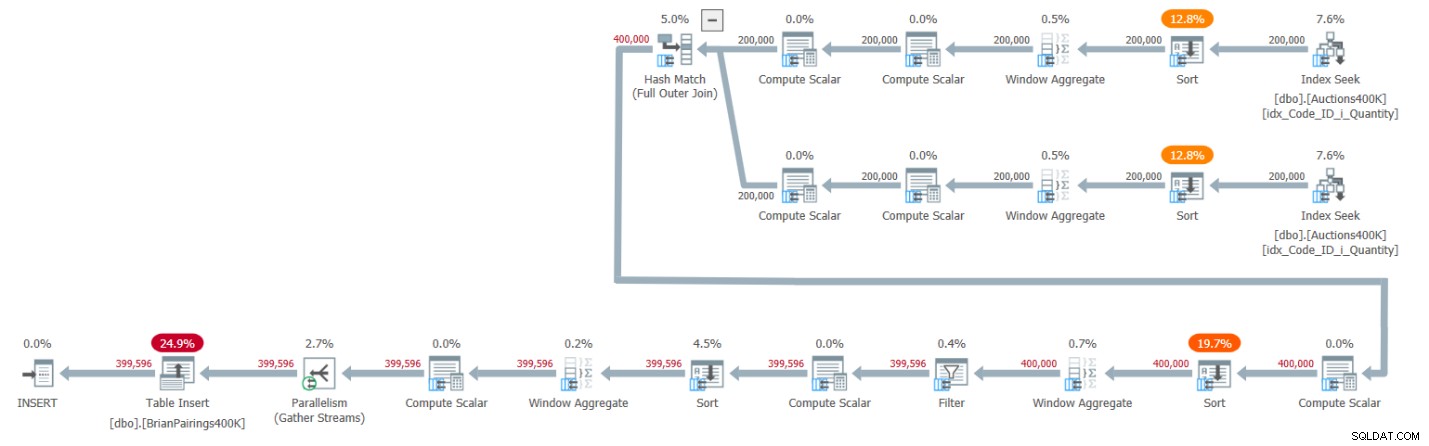 Figura 1:piano di query per la soluzione di Brian
Figura 1:piano di query per la soluzione di Brian
I primi due rami del piano calcolano i totali parziali della domanda e dell'offerta utilizzando un operatore Window Aggregate in modalità batch, ciascuno dopo aver recuperato le rispettive voci dall'indice di supporto. Come ho spiegato negli articoli precedenti della serie, poiché l'indice ha già le righe ordinate come gli operatori di Window Aggregate hanno bisogno che siano, penseresti che non dovrebbero essere richiesti operatori di ordinamento espliciti. Tuttavia, SQL Server non supporta attualmente una combinazione efficiente di operazioni parallele sull'indice di conservazione degli ordini prima di un operatore di aggregazione di finestre in modalità batch parallela, quindi, di conseguenza, un operatore di ordinamento parallelo esplicito precede ciascuno degli operatori di aggregazione di finestre paralleli.
Il piano utilizza un hash join in modalità batch per gestire il join esterno completo. Il piano utilizza anche due operatori Window Aggregate aggiuntivi in modalità batch preceduti da operatori di ordinamento espliciti per calcolare le funzioni della finestra MIN e LAG.
È un piano piuttosto efficiente!
Ecco i tempi di esecuzione che ho ottenuto per questa soluzione rispetto a dimensioni di input comprese tra 100.000 e 400.000 righe, in secondi:
100K:0,368200K:0,845300K:1,255400K:1,315
Soluzione di Itzik
La prossima soluzione per la sfida è uno dei miei tentativi di risolverla. Ecco il codice completo della soluzione:
TABELLA A CADUTA SE ESISTE #MyPairings; CON C1 AS( SELECT *, SUM(Quantity) OVER(PARTITION BY Code ORDER BY ID ROWS UNBOUNDED PRECEDENTI) COME SumQty FROM dbo.Auctions),C2 AS( SELECT *, SUM(Quantity * CASE Code WHEN 'D' THEN -1 QUANDO 'S' ALLORA 1 FINE) OVER(ORDINE PER SumQty, Code ROWS UNBOUNDED PRECEDENTI) AS StockLevel, LAG(SumQty, 1, 0.0) OVER(ORDINE PER SumQty, Code) AS PrevSumQty, MAX(CASE WHEN Code ='D' THEN ID END) OVER(ORDINE PER SumQty, Code ROWS UNBOUNDED PRECEDENTI) AS PrevDemandID, MAX(CASE WHEN Code ='S' THEN ID END) OVER(ORDINE PER SumQty, Code ROWS UNBOUNDED PRECEDENTI) AS PrevSupplyID, MIN(CASE WHEN Code ='D' THEN ID END) OVER(ORDINE PER Somma, codice RIGHE TRA LA RIGA ATTUALE E UNBOUNDED SEGUENTE) AS NextDemandID, MIN(CASE WHEN Code ='S' THEN ID END) OVER(ORDINE PER SumQty, codice RIGHE TRA LA RIGA CORRENTE E SENZA LIMITI DI SEGUITO) AS NextSupplyID DA C1),C3 AS( SELECT *, CASE Code QUANDO 'D ' THEN ID QUANDO 'S' THEN CASE QUANDO StockLevel> 0 THEN NextDemandID ELSE PrevDemandID END END AS DemandID, CASE Code WHEN 'S' THEN ID QUANDO 'D' THEN CASE WHEN StockLevel <=0 THEN NextSupplyID ELSE PrevSupplyID END END AS SupplyID, SumQty - PrevSumQty AS TradeQuantity FROM C2)SELECT DemandID, SupplyID, TradeQuantityINTO #MyPairingsDA C3WHERE TradeQuantity> 0.0 E DemandID NON È NULL E SupplyID NON È NULL;
Il CTE C1 interroga la tabella Aste e utilizza una funzione finestra per calcolare la domanda totale corrente e le quantità di offerta, chiamando la colonna dei risultati SumQty.
Il CTE C2 interroga C1 e calcola una serie di attributi utilizzando le funzioni della finestra basate su SumQty e Code ordering:
- StockLevel:il livello di stock corrente dopo l'elaborazione di ogni voce. Questo viene calcolato assegnando un segno negativo alle quantità richieste e un segno positivo alle quantità fornite e sommando tali quantità fino alla voce corrente inclusa.
- PrevSumQty:il valore SumQty della riga precedente.
- PrevDemandID:ultimo ID richiesta non NULL.
- PrevSupplyID:ultimo ID fornitura non NULL.
- NextDemandID:ID richiesta successivo non NULL.
- NextSupplyID:ID fornitura successiva non NULL.
Ecco il contenuto di C2 ordinato da SumQty e Code:
ID Codice Quantità SumQty StockLevel PrevSumQty PrevDemandID PrevSupplyID NextDemandID NextSupplyID----- ---- --------- ---------- --------- -- ----------- ------------ ------------ ------------ - ----------- 1 D 5.000000 5.000000 -5.000000 0.000000 1 NULL 1 10002 D 3.000000 8.000000 -8000000 5.000000 2 NULL 2 10001000 S 8.000000 8.000000 0,000000 8.000000 2 1000 3 10002000 S 6.000000 14.00000000000000000000 2 20003 D 8.000000 16.000000 -2.000000 14.000000 3 2000 3 30003000 S 2.000000 16.000000 0.000000 16.000000 3 3000 5 30005 D 2.000000 18.000000 -2.000000 16.000000 5 3000 5 40004000 S 2.000000 18.000000 0.000000 18.0000 5 4000 40005000 S 4.000000 22.000000 4.000000 18.000000 5 5000 6 50006000 S 3.000000 25.000000 7.000000 22.000000 5 6000 6 60006 D 8.000000 26.000000 -1.000000 25000000 20000 000000 6 6000 6 7000 S 2.000000 00000000 000000 DE 670000 DEC. 32.000000 -5.000000 30.000000 8 7000 8 NULL
Il CTE C3 interroga C2 e calcola DemandID, SupplyID e TradeQuantity degli accoppiamenti dei risultati, prima di rimuovere alcune righe superflue.
La colonna risultante C3.DemandID viene calcolata in questo modo:
- Se la voce corrente è una voce richiesta, restituire DemandID.
- Se la voce corrente è una voce di fornitura e il livello delle scorte corrente è positivo, restituire NextDemandID.
- Se la voce corrente è una voce di fornitura e il livello di scorte corrente non è positivo, restituire PrevDemandID.
La colonna C3.SupplyID del risultato viene calcolata in questo modo:
- Se la voce corrente è una voce di fornitura, restituire SupplyID.
- Se la voce corrente è una voce di domanda e il livello delle scorte corrente non è positivo, restituire NextSupplyID.
- Se la voce corrente è una voce di domanda e il livello delle scorte corrente è positivo, restituire PrevSupplyID.
Il risultato TradeQuantity viene calcolato come SumQty della riga corrente meno PrevSumQty.
Ecco il contenuto delle colonne relative al risultato di C3:
DemandID SupplyID TradeQuantity----------- ----------- --------------1 1000 5.0000002 1000 3.0000002 1000 0.0000003 2000 6.0000003 3000 2.0000003 3000 0.0000005 4000 2.0000005 4000 0.0000006 5000 4.0000006 6000 3.0000006 7000 1.0000007 7000 1.0000007 NULL 3.0000008 NULL 2.000000
Ciò che resta da fare per la query esterna è filtrare le righe superflue da C3. Questi includono due casi:
- Quando i totali correnti di entrambi i tipi sono gli stessi, la voce di fornitura ha una quantità di scambio pari a zero. Ricorda che l'ordine si basa su SumQty e Code, quindi quando i totali parziali sono gli stessi, la voce della domanda viene visualizzata prima della voce della fornitura.
- Voci finali di un tipo che non possono essere abbinate a voci dell'altro tipo. Tali voci sono rappresentate da righe in C3 in cui DemandID è NULL o SupplyID è NULL.
Il piano per questa soluzione è mostrato nella Figura 2.
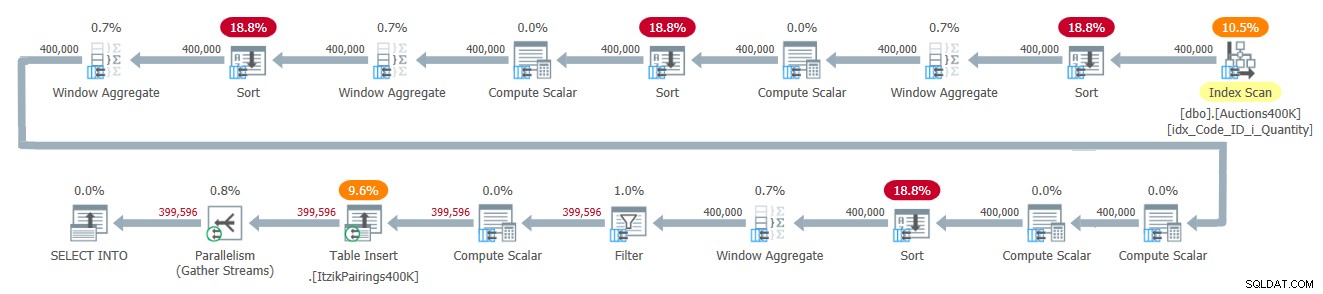 Figura 2:piano di query per la soluzione di Itzik
Figura 2:piano di query per la soluzione di Itzik
Il piano applica un passaggio sui dati di input e utilizza quattro operatori Window Aggregate in modalità batch per gestire i vari calcoli con finestra. Tutti gli operatori Window Aggregate sono preceduti da operatori di ordinamento espliciti, sebbene solo due di questi siano inevitabili qui. Gli altri due hanno a che fare con l'attuale implementazione dell'operatore Window Aggregate in modalità batch parallela, che non può fare affidamento su un input di conservazione dell'ordine parallelo. Un modo semplice per vedere quali operatori di ordinamento sono dovuti a questo motivo è forzare un piano seriale e vedere quali operatori di ordinamento scompaiono. Quando forzo un piano seriale con questa soluzione, il primo e il terzo operatore di ordinamento scompaiono.
Ecco i tempi di esecuzione in secondi che ho ottenuto per questa soluzione:
100K:0,246200K:0,427300K:0,616400K:0,841>
Soluzione di Ian
La soluzione di Ian è breve ed efficiente. Ecco il codice completo della soluzione:
TABELLA A CADUTA SE ESISTE #MyPairings; CON A AS ( SELECT *, SUM(Quantity) OVER (PARTITION BY Code ORDER BY ID ROWS UNBOUNDED PRECEDENTI) AS CumulativeQuantity FROM dbo.Auctions), B AS ( SELECT CumulativeQuantity, CumulativeQuantity - LAG(CumulativeQuantity, 1, 0) OVER (ORDINE PER CumulativeQuantity) AS TradeQuantity, MAX(CASE WHEN Code ='D' THEN ID END) AS DemandID, MAX(CASE WHEN Code ='S' THEN ID END) AS SupplyID FROM A GROUP BY CumulativeQuantity, ID/ID -- raggruppamento fasullo per migliorare la stima delle righe -- (conteggio righe di Aste invece di 2 righe)), C AS ( -- compilare NULL con la prossima domanda/offerta -- FIRST_VALUE(ID) IGNORA NULLS OVER ... -- sarebbe meglio, ma questo funzionerà perché gli ID sono nell'ordine CumulativeQuantity SELECT MIN(DemandID) OVER (ORDINE PER CumulativeQuantity RIGHE TRA LA RIGA CORRENTE E UNBOUNDED SEGUENTE) COME DemandID, MIN(SupplyID) OVER (ORDINE PER CumulativeQ uantity RIGHE TRA LA RIGA CORRENTE E IL SEGUENTE UNBOUNDED) COME SupplyID, TradeQuantity FROM B)SELECT DemandID, SupplyID, TradeQuantityINTO #MyPairingsDACWHERE SupplyID NON È NULL -- taglia le richieste non soddisfatte E DemandID NON È NULL; -- taglia le forniture inutilizzate
Il codice nella CTE A interroga la tabella Aste e calcola le quantità totali di domanda e offerta correnti utilizzando una funzione finestra, nominando la colonna dei risultati CumulativeQuantity.
Il codice in CTE B interroga CTE A e raggruppa le righe per CumulativeQuantity. Questo raggruppamento ottiene un effetto simile all'outer join di Brian basato sui totali correnti della domanda e dell'offerta. Ian ha anche aggiunto l'ID/ID dell'espressione fittizia al gruppo di raggruppamento per migliorare la cardinalità originale del raggruppamento sotto stima. Sulla mia macchina, questo ha comportato anche l'utilizzo di un piano parallelo invece di uno seriale.
Nell'elenco SELECT, il codice calcola DemandID e SupplyID recuperando l'ID del rispettivo tipo di voce nel gruppo utilizzando l'aggregazione MAX e un'espressione CASE. Se l'ID non è presente nel gruppo, il risultato è NULL. Il codice calcola anche una colonna di risultati denominata TradeQuantity come quantità cumulativa corrente meno quella precedente, recuperata utilizzando la funzione finestra LAG.
Ecco i contenuti di B:
Quantità Cumulativa TradeQuantity DemandId SupplyId------------------- -------------- --------- - -------- 5.000000 5.000000 1 NULL 8.000000 3.000000 2 100014.000000 6.000000 NULL 200016.000000 2.000000 3 300018.000000 2.000000 5 400022.0000 0000000000.0000 000000 000000000000 00000000000000 00000000000000 000000000000000000 000000000000000000 00000000000000000000 0000000000000000000000 000000000000000000000000000000000000000000000000000000000000 di>Il codice nel CTE C interroga quindi il CTE B e compila gli ID di domanda e offerta NULL con i successivi ID di domanda e offerta non NULL, utilizzando la funzione della finestra MIN con il frame ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING.
Ecco i contenuti di C:
DemandID SupplyID TradeQuantity --------- --------- --------------1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000 7 NULL 3.000000 8 NULL 2.000000L'ultimo passaggio gestito dalla query esterna su C consiste nel rimuovere voci di un tipo che non possono essere abbinate a voci dell'altro tipo. Ciò avviene filtrando le righe in cui SupplyID è NULL o DemandID è NULL.
Il piano per questa soluzione è mostrato nella Figura 3.
Figura 3:piano di query per la soluzione di Ian
Questo piano esegue una scansione dei dati di input e utilizza tre operatori di aggregazione della finestra in modalità batch paralleli per calcolare le varie funzioni della finestra, tutte precedute da operatori di ordinamento paralleli. Due di questi sono inevitabili come puoi verificare forzando un piano seriale. Il piano utilizza anche un operatore Hash Aggregate per gestire il raggruppamento e l'aggregazione nel CTE B.
Ecco i tempi di esecuzione in secondi che ho ottenuto per questa soluzione:
100K:0,214200K:0,363300K:0,546400K:0,701
Soluzione di Peter Larsson
La soluzione di Peter Larsson è sorprendentemente breve, dolce e altamente efficiente. Ecco il codice completo della soluzione di Peter:
TABELLA A CADUTA SE ESISTE #MyPairings; CON cteSource(ID, Code, RunningQuantity)AS( SELECT ID, Code, SUM(Quantity) OVER (PARTITION BY Code ORDER BY ID) AS RunningQuantity FROM dbo.Auctions)SELECT DemandID, SupplyID, TradeQuantityINTO #MyPairingsDA ( SELECT MIN(CASE QUANDO) Code ='D' THEN ID ELSE 2147483648 END) OVER (ORDINA PER RunningQuantity, Code ROWS TRA LA RIGA ATTUALE E UNBOUNDED SEGUENTE) COME DemandID, MIN(CASE WHEN Code ='S' THEN ID ELSE 2147483648 END) OVER (ORDINE PER RunningQuantity, Code ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING SEGUENTE) AS SupplyID, RunningQuantity - COALESCE(LAG(RunningQuantity) OVER (ORDER BY RunningQuantity, Code), 0.0) AS TradeQuantity FROM cteSource ) AS dWHERE DemandID <2147483648 AND SupplyID <2147483648 AND TradeQuantity> 0.0;Il CTE cteSource interroga la tabella Auctions e utilizza una funzione finestra per calcolare la domanda totale corrente e le quantità di offerta, chiamando la colonna dei risultati RunningQuantity.
Il codice che definisce la tabella derivata d interroga cteSource e calcola DemandID, SupplyID e TradeQuantity degli accoppiamenti di risultati, prima di rimuovere alcune righe superflue. Tutte le funzioni della finestra utilizzate in questi calcoli si basano su RunningQuantity e sull'ordinamento del codice.
La colonna dei risultati d.DemandID viene calcolata come l'ID della domanda minima che inizia con l'attuale o 2147483648 se non ne viene trovato nessuno.
La colonna dei risultati d.SupplyID viene calcolata come ID fornitura minimo che inizia con l'attuale o 2147483648 se non ne viene trovato nessuno.
Il risultato TradeQuantity viene calcolato come il valore RunningQuantity della riga corrente meno il valore RunningQuantity della riga precedente.
Ecco i contenuti di d:
DemandID SupplyID TradeQuantity--------- ----------- --------------1 1000 5.0000002 1000 3.0000003 1000 0.0000003 2000 6.0000003 3000 2.0000005 3000 0.0000005 4000 2.000000 4000 0.0000006 5000 4.000000 6000 3.0000006 7000 1.0000007 7000 1.0000007 2147483648 3.0000002 2147483648 2.000000Ciò che resta da fare per la query esterna è filtrare le righe superflue da d. Questi sono i casi in cui la quantità di scambio è zero, o voci di un tipo che non possono essere abbinate a voci dell'altro tipo (con ID 2147483648).
Il piano per questa soluzione è mostrato nella Figura 4.
Figura 4:piano di query per la soluzione di Peter
Come il piano di Ian, il piano di Peter si basa su una scansione dei dati di input e utilizza tre operatori di aggregazione di finestre in modalità batch paralleli per calcolare le varie funzioni della finestra, tutte precedute da operatori di ordinamento paralleli. Due di questi sono inevitabili come puoi verificare forzando un piano seriale. Nel piano di Peter, non è necessario un operatore aggregato raggruppato come nel piano di Ian.
L'intuizione critica di Peter che ha consentito una soluzione così breve è stata la consapevolezza che per una voce pertinente di uno dei tipi, l'ID corrispondente dell'altro tipo apparirà sempre in seguito (basato su RunningQuantity e Code ordering). Dopo aver visto la soluzione di Peter, mi sembrava di aver complicato le cose nelle mie!
Ecco i tempi di esecuzione in secondi che ho ottenuto per questa soluzione:
100K:0,197200K:0,412300K:0,558400K:0,696
La soluzione di Paul White
La nostra ultima soluzione è stata creata da Paul White. Ecco il codice completo della soluzione:
TABELLA A CADUTA SE ESISTE #MyPairings; CREATE TABLE #MyPairings( DemandID intero NOT NULL, SupplyID intero NOT NULL, TradeQuantity decimale(19, 6) NOT NULL);GO INSERT #MyPairings WITH (TABLOCK)( DemandID, SupplyID, TradeQuantity)SELECT Q3.DemandID, Q3.SupplyID, Q3.TradeQuantityFROM ( SELECT Q2.DemandID, Q2.SupplyID, TradeQuantity =-- Intervallo di sovrapposizione CASO QUANDO Q2.Code ='S' POI CASO QUANDO Q2.CumDemand>=Q2.IntEnd THEN Q2.IntLength QUANDO Q2.CumDemand> Q2. IntStart THEN Q2.CumDemand - Q2.IntStart ELSE 0.0 FINE QUANDO Q2.Code ='D' ALLORA CASO QUANDO Q2.CumSupply>=Q2.IntEnd THEN Q2.IntLength QUANDO Q2.CumSupply> Q2.IntStart THEN Q2.CumSupply - Q2. IntStart ELSE 0.0 FINE FINE DA ( SELEZIONA Q1.Code, Q1.IntStart, Q1.IntEnd, Q1.IntLength, DemandID =MAX(IIF(Q1.Code ='D', Q1.ID, 0)) OVER ( ORDER BY Q1.IntStart, Q1.ID ROWS UNBOUNDED PRECEDENTE), SupplyID =MAX(IIF(Q1.Code ='S', Q1.ID, 0)) OLTRE ( ORDINE PER Q1.IntStart, Q1.ID RIGHE UNBOUNDED PRECEDENTI), CumSupply =SUM(IIF(Q1.Code ='S', Q1.IntLength, 0)) OVER ( ORDINA PER Q1.IntStart, Q1.ID RIGA UNBOUNDED PRECEDENTI), CumDemand =SUM(IIF(Q1.Code ='D', Q1.IntLength, 0)) OVER ( ORDINA PER Q1.IntStart, Q1.ID RIGHE UNBOUNDED PRECEDENTI) DA ( -- Intervalli di domanda SELECT A.ID, A.Code, IntStart =SUM(A.Quantity) OVER ( ORDINA PER A.ID RIGHE UNBOUNDED PRECEDENTI) - A. quantità, IntEnd =SUM(A.Quantity) OVER (ORDINA PER RIGHE A.ID UNBOUNDED PRECEDENTI), IntLength =A.Quantity FROM dbo.Auctions AS A WHERE A.Code ='D' UNION ALL -- Intervalli di fornitura SELECT A.ID, A.Code, IntStart =SUM(A.Quantity) OVER ( ORDINE PER RIGHE A.ID SENZA LIMITI PRECEDENTI) - A.Quantity, IntEnd =SUM(A.Quantity) OVER ( ORDINE PER RIGHE A.ID SENZA LIMITI PRECEDENTI), IntLength =A.Quantity FROM dbo.Auctions COME DOVE A.Code ='S' ) AS Q1 ) AS Q2) AS Q3WHERE Q3.TradeQuantity> 0;Il codice che definisce la tabella derivata Q1 utilizza due query separate per calcolare gli intervalli di domanda e offerta in base ai totali parziali e unifica i due. Per ogni intervallo, il codice ne calcola l'inizio (IntStart), la fine (IntEnd) e la lunghezza (IntLength). Ecco i contenuti del primo trimestre ordinati per IntStart e ID:
Codice ID IntStart IntEnd IntLength----- ---- ---------- ---------- ----------1 D 0.000000 5.000000 5.0000001000 S 0.000000 8.000000 8.0000002 D 5.000000 8.000000 3.0000003 D 8.000000 16.000000 8.0000002000 S 8.000000 14.000000 6.0000003000 S 14.000000 16.000000 2.0000005 D 16.000000 18.000000 2.0000004000 S 16.000000 18.000000 2.0000006 D 18.000000 26.000000 8.0000005000 S 18.000000 22.000000 4.0000006000 S 22.000000 25.000000 3.0000007000 S 25.000000 27.000000 2.0000007 D 26.000000 30.000000 4.0000008 D 30.000000 32.000000 2.000000Il codice che definisce la tabella derivata Q2 interroga Q1 e calcola le colonne dei risultati denominate DemandID, SupplyID, CumSupply e CumDemand. Tutte le funzioni della finestra utilizzate da questo codice si basano sull'ordinamento IntStart e ID e sul frame ROWS UNBOUNDED PRECEDING (tutte le righe fino alla corrente).
DemandID è l'ID richiesta massimo fino alla riga corrente o 0 se non esiste.
SupplyID è l'ID fornitura massimo fino alla riga corrente o 0 se non esiste.
CumSupply è la quantità di fornitura cumulativa (lunghezze dell'intervallo di fornitura) fino alla riga corrente.
CumDemand è la quantità di domanda cumulativa (lunghezze dell'intervallo di domanda) fino alla riga corrente.
Ecco i contenuti del secondo trimestre:
Codice IntStart IntEnd IntLength DemandID SupplyID CumSupply CumDemand---- ---------- ---------- ---------- ----- ---- --------- ---------- ----------D 0.000000 5.000000 5.000000 1 0 0.000000 5.000000S 0.000000 8.000000 8.000000 1 1000 8.000000 5.0000 5.000000 8.000000 3.000000 2 1000 8.000000 8.000000D 8.000000 16.000000 8.000000 3 1000 8.000000 16.000000S 8.000000 14.000000 6.000000 3 2000 14.000000 16.000000S 14.000000 16.000000 2.000000 3 3000 16.000000 16.000000D 16.000000 18.000000 2.000000 5 3000 16.000000 18.000000S 16.000000 18.000000 2.000000 5 4000 18.000000 18.000000D 18.000000 26.000000 8.000000 6 4000 18.000000 26.000000S 18.000000 22.000000 4.000000 6 5000 22.000000 26.000000S 22.000000 25.000000 3.000000 6 6 000000 25.000000 26.000000s 25.000000 27.000000 2.000000 6 7000 27.000000 26.000000d 26.000000 30.000000 4.000000 7 7000 27.000000 30.000000d 30.000000 32.000000 2.00000000 8 7000 27.000000 32.0000Q2 already has the final result pairings’ correct DemandID and SupplyID values. The code defining the derived table Q3 queries Q2 and computes the result pairings’ TradeQuantity values as the overlapping segments of the demand and supply intervals. Finally, the outer query against Q3 filters only the relevant pairings where TradeQuantity is positive.
The plan for this solution is shown in Figure 5.
Figure 5:Query plan for Paul’s solution
The top two branches of the plan are responsible for computing the demand and supply intervals. Both rely on Index Seek operators to get the relevant rows based on index order, and then use parallel batch-mode Window Aggregate operators, preceded by Sort operators that theoretically could have been avoided. The plan concatenates the two inputs, sorts the rows by IntStart and ID to support the subsequent remaining Window Aggregate operator. Only this Sort operator is unavoidable in this plan. The rest of the plan handles the needed scalar computations and the final filter. That’s a very efficient plan!
Here are the run times in seconds I got for this solution:
100K:0.187200K:0.331300K:0.369400K:0.425These numbers are pretty impressive!
Performance Comparison
Figure 6 has a performance comparison between all solutions covered in this article.
Figure 6:Performance comparison
At this point, we can add the fastest solutions I covered in previous articles. Those are Joe’s and Kamil/Luca/Daniel’s solutions. The complete comparison is shown in Figure 7.
Figure 7:Performance comparison including earlier solutions
These are all impressively fast solutions, with the fastest being Paul’s and Peter’s.
Conclusione
When I originally introduced Peter’s puzzle, I showed a straightforward cursor-based solution that took 11.81 seconds to complete against a 400K-row input. The challenge was to come up with an efficient set-based solution. It’s so inspiring to see all the solutions people sent. I always learn so much from such puzzles both from my own attempts and by analyzing others’ solutions. It’s impressive to see several sub-second solutions, with Paul’s being less than half a second!
It's great to have multiple efficient techniques to handle such a classic need of matching supply with demand. Well done everyone!
[ Jump to:Original challenge | Solutions:Part 1 | Part 2 | Part 3 ]