Il primissimo post sul blog su questo sito, nel lontano luglio del 2012, parlava dei migliori approcci per i totali parziali. Da allora, mi è stato chiesto in più occasioni come avrei affrontato il problema se i totali parziali fossero più complessi, in particolare se avessi bisogno di calcolare i totali parziali per più entità, ad esempio gli ordini di ciascun cliente.
L'esempio originale utilizzava un caso fittizio di una città che emette multe per eccesso di velocità; il totale parziale era semplicemente l'aggregazione e il conteggio progressivo del numero di multe per eccesso di velocità di giorno (indipendentemente da chi fosse stato emesso il biglietto o da quanto costasse). Un esempio più complesso (ma pratico) potrebbe essere l'aggregazione del valore totale parziale delle multe per eccesso di velocità, raggruppato per patente, al giorno. Immaginiamo la seguente tabella:
CREATE TABLE dbo.SpeedingTickets ( IncidentID INT IDENTITY(1,1) PRIMARY KEY, LicenseNumber INT NOT NULL, IncidentDate DATE NOT NULL, TicketAmount DECIMAL(7,2) NOT NULL ); CREATE UNIQUE INDEX x ON dbo.SpeedingTickets(LicenseNumber, IncidentDate) INCLUDE(TicketAmount);
Potresti chiedere, DECIMAL(7,2) , veramente? A che velocità stanno andando queste persone? Bene, in Canada, ad esempio, non è poi così difficile ottenere una multa di $ 10.000 per eccesso di velocità.
Ora, popola la tabella con alcuni dati di esempio. Non entrerò in tutti i dettagli qui, ma questo dovrebbe produrre circa 6.000 righe che rappresentano più conducenti e più importi di biglietti per un periodo di un mese:
;WITH TicketAmounts(ID,Value) AS
(
-- 10 arbitrary ticket amounts
SELECT i,p FROM
(
VALUES(1,32.75),(2,75), (3,109),(4,175),(5,295),
(6,68.50),(7,125),(8,145),(9,199),(10,250)
) AS v(i,p)
),
LicenseNumbers(LicenseNumber,[newid]) AS
(
-- 1000 random license numbers
SELECT TOP (1000) 7000000 + number, n = NEWID()
FROM [master].dbo.spt_values
WHERE number BETWEEN 1 AND 999999
ORDER BY n
),
JanuaryDates([day]) AS
(
-- every day in January 2014
SELECT TOP (31) DATEADD(DAY, number, '20140101')
FROM [master].dbo.spt_values
WHERE [type] = N'P'
ORDER BY number
),
Tickets(LicenseNumber,[day],s) AS
(
-- match *some* licenses to days they got tickets
SELECT DISTINCT l.LicenseNumber, d.[day], s = RTRIM(l.LicenseNumber)
FROM LicenseNumbers AS l CROSS JOIN JanuaryDates AS d
WHERE CHECKSUM(NEWID()) % 100 = l.LicenseNumber % 100
AND (RTRIM(l.LicenseNumber) LIKE '%' + RIGHT(CONVERT(CHAR(8), d.[day], 112),1) + '%')
OR (RTRIM(l.LicenseNumber+1) LIKE '%' + RIGHT(CONVERT(CHAR(8), d.[day], 112),1) + '%')
)
INSERT dbo.SpeedingTickets(LicenseNumber,IncidentDate,TicketAmount)
SELECT t.LicenseNumber, t.[day], ta.Value
FROM Tickets AS t
INNER JOIN TicketAmounts AS ta
ON ta.ID = CONVERT(INT,RIGHT(t.s,1))-CONVERT(INT,LEFT(RIGHT(t.s,2),1))
ORDER BY t.[day], t.LicenseNumber; Potrebbe sembrare un po' troppo complicato, ma una delle sfide più grandi che mi capita spesso di incontrare durante la composizione di questi post del blog è la costruzione di una quantità adeguata di dati realistici "casuali" / arbitrari. Se hai un metodo migliore per la popolazione di dati arbitraria, con tutti i mezzi, non usare i miei borbottii come esempio:sono periferici fino al punto di questo post.
Approcci
Esistono vari modi per risolvere questo problema in T-SQL. Ecco sette approcci, insieme ai piani associati. Ho tralasciato tecniche come i cursori (perché saranno innegabilmente più lenti) e le CTE ricorsive basate sulla data (perché dipendono da giorni contigui).
Subquery n. 1
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = TicketAmount + COALESCE(
(
SELECT SUM(TicketAmount)
FROM dbo.SpeedingTickets AS s
WHERE s.LicenseNumber = o.LicenseNumber
AND s.IncidentDate < o.IncidentDate
), 0)
FROM dbo.SpeedingTickets AS o
ORDER BY LicenseNumber, IncidentDate;
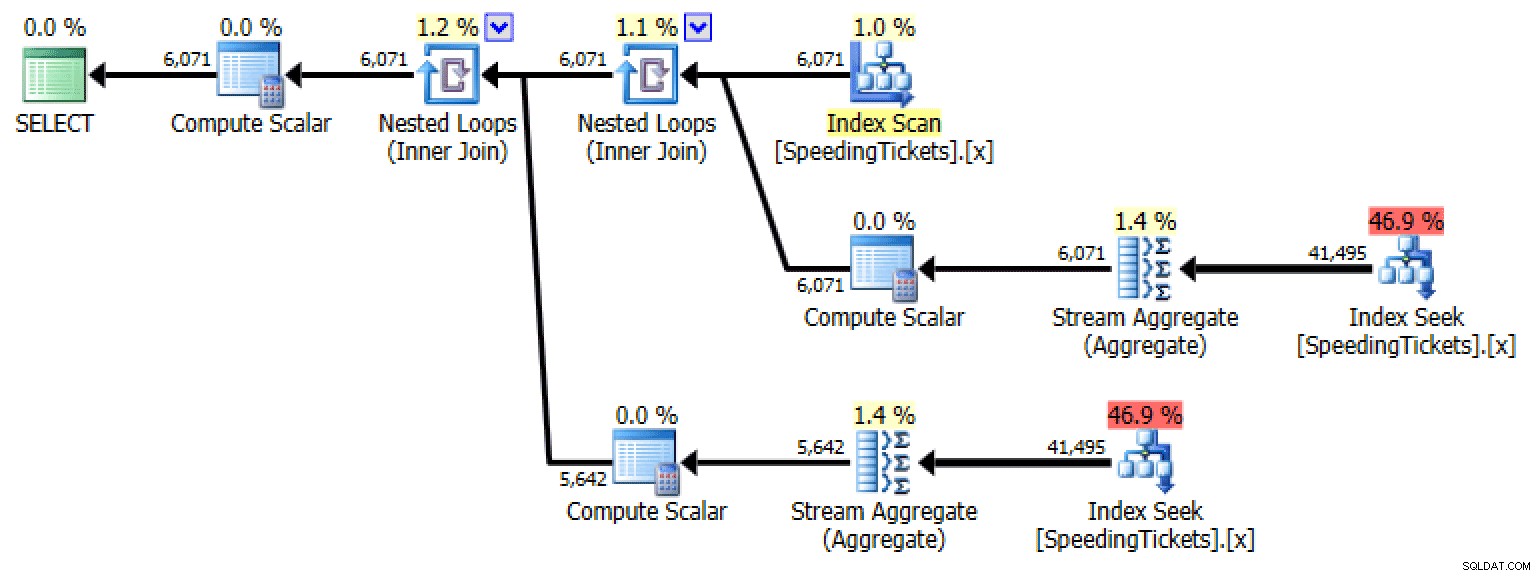
Pianifica per la sottoquery n. 1
Subquery n. 2
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal =
(
SELECT SUM(TicketAmount) FROM dbo.SpeedingTickets
WHERE LicenseNumber = t.LicenseNumber
AND IncidentDate <= t.IncidentDate
)
FROM dbo.SpeedingTickets AS t
ORDER BY LicenseNumber, IncidentDate;
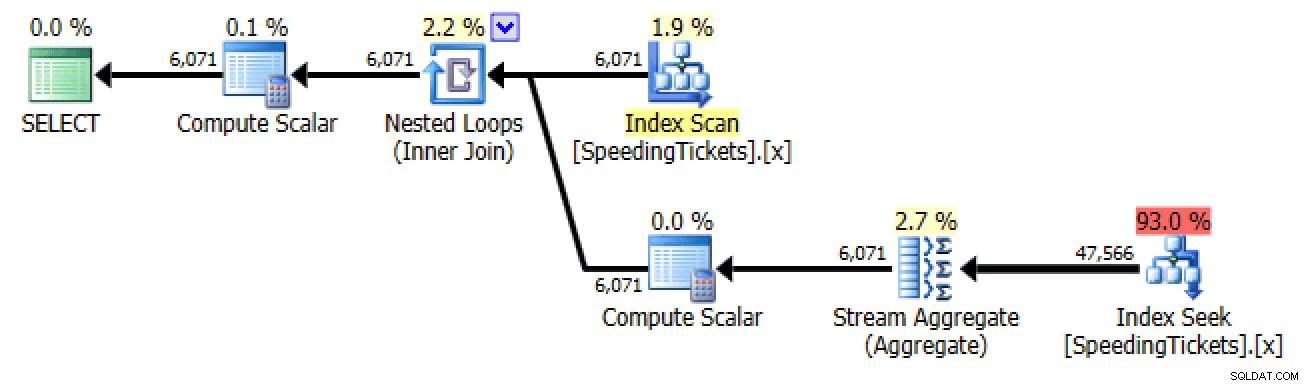
Pianifica per la sottoquery n. 2
Auto-unione
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount, RunningTotal = SUM(t2.TicketAmount) FROM dbo.SpeedingTickets AS t1 INNER JOIN dbo.SpeedingTickets AS t2 ON t1.LicenseNumber = t2.LicenseNumber AND t1.IncidentDate >= t2.IncidentDate GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount ORDER BY t1.LicenseNumber, t1.IncidentDate;
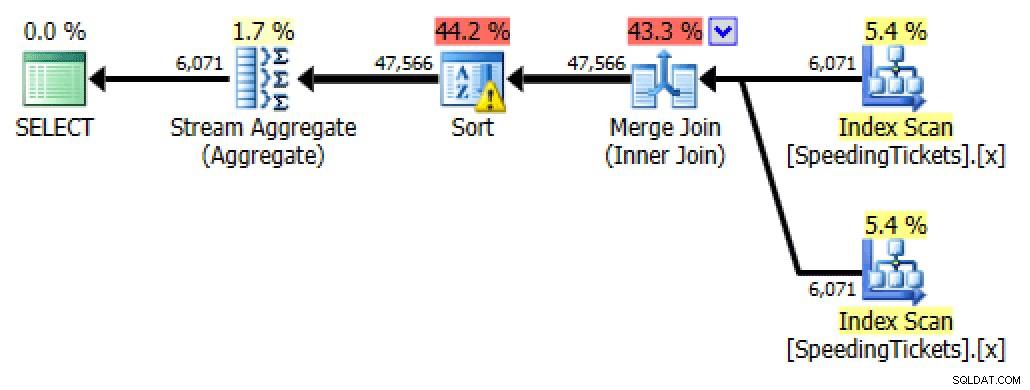
Pianifica per l'auto-iscrizione
Applicazione esterna
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount,
RunningTotal = SUM(t2.TicketAmount)
FROM dbo.SpeedingTickets AS t1
OUTER APPLY
(
SELECT TicketAmount
FROM dbo.SpeedingTickets
WHERE LicenseNumber = t1.LicenseNumber
AND IncidentDate <= t1.IncidentDate
) AS t2
GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount
ORDER BY t1.LicenseNumber, t1.IncidentDate;
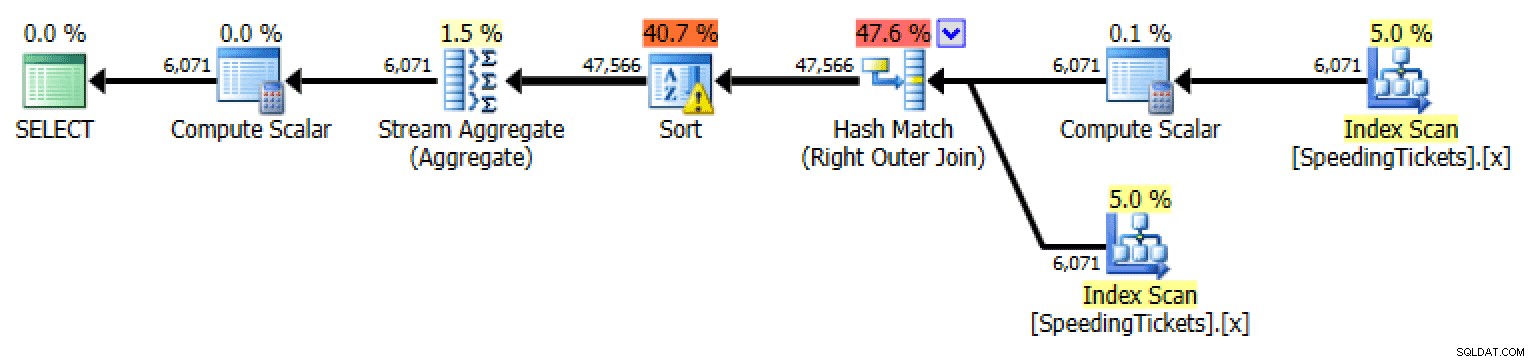
Piano per l'applicazione esterna
SUM OVER() utilizzando RANGE (solo 2012+)
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = SUM(TicketAmount) OVER
(
PARTITION BY LicenseNumber
ORDER BY IncidentDate RANGE UNBOUNDED PRECEDING
)
FROM dbo.SpeedingTickets
ORDER BY LicenseNumber, IncidentDate;

Pianifica per SUM OVER() utilizzando RANGE
SUM OVER() utilizzando ROWS (solo 2012+)
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = SUM(TicketAmount) OVER
(
PARTITION BY LicenseNumber
ORDER BY IncidentDate ROWS UNBOUNDED PRECEDING
)
FROM dbo.SpeedingTickets
ORDER BY LicenseNumber, IncidentDate;

Pianifica per SUM OVER() utilizzando ROWS
Iterazione basata su set
Con credito a Hugo Kornelis (@Hugo_Kornelis) per il capitolo 4 in SQL Server MVP Deep Dives Volume 1, questo approccio combina un approccio basato su set e un approccio cursore.
DECLARE @x TABLE
(
LicenseNumber INT NOT NULL,
IncidentDate DATE NOT NULL,
TicketAmount DECIMAL(7,2) NOT NULL,
RunningTotal DECIMAL(7,2) NOT NULL,
rn INT NOT NULL,
PRIMARY KEY(LicenseNumber, IncidentDate)
);
INSERT @x(LicenseNumber, IncidentDate, TicketAmount, RunningTotal, rn)
SELECT LicenseNumber, IncidentDate, TicketAmount, TicketAmount,
ROW_NUMBER() OVER (PARTITION BY LicenseNumber ORDER BY IncidentDate)
FROM dbo.SpeedingTickets;
DECLARE @rn INT = 1, @rc INT = 1;
WHILE @rc > 0
BEGIN
SET @rn += 1;
UPDATE [current]
SET RunningTotal = [last].RunningTotal + [current].TicketAmount
FROM @x AS [current]
INNER JOIN @x AS [last]
ON [current].LicenseNumber = [last].LicenseNumber
AND [last].rn = @rn - 1
WHERE [current].rn = @rn;
SET @rc = @@ROWCOUNT;
END
SELECT LicenseNumber, IncidentDate, TicketAmount, RunningTotal
FROM @x
ORDER BY LicenseNumber, IncidentDate; Per sua natura, questo approccio produce molti piani identici nel processo di aggiornamento della variabile table, che sono tutti simili ai piani di self-join e di applicazione esterna, ma sono in grado di utilizzare una ricerca:
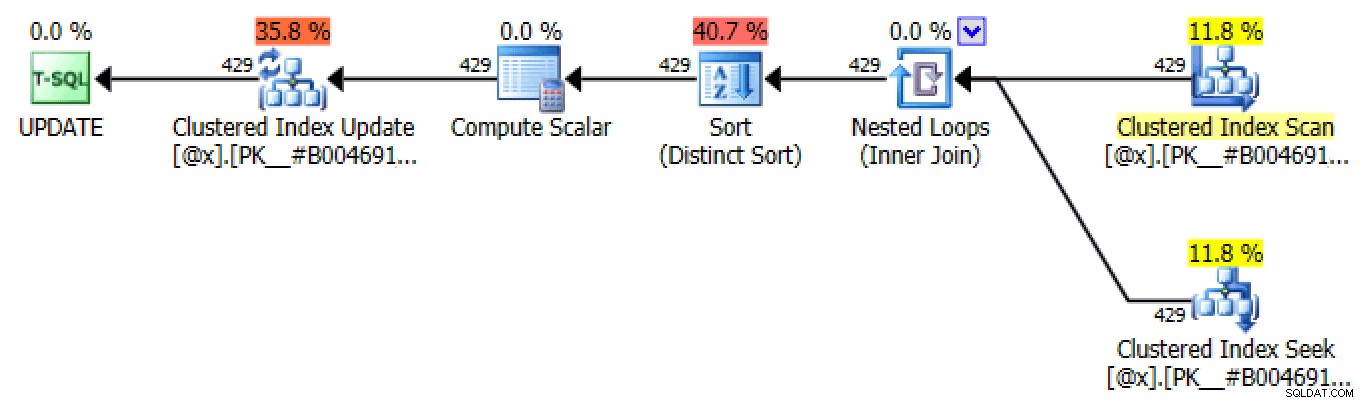
Uno dei tanti piani UPDATE prodotti attraverso l'iterazione basata su set
L'unica differenza tra ogni piano in ogni iterazione è il conteggio delle righe. Ad ogni iterazione successiva, il numero di righe interessate dovrebbe rimanere lo stesso o diminuire, poiché il numero di righe interessate ad ogni iterazione rappresenta il numero di conducenti con biglietti in quel numero di giorni (o, più precisamente, il numero di giorni a quel "grado").
Risultati delle prestazioni
Ecco come si accumulano gli approcci, come mostrato da SQL Sentry Plan Explorer, con l'eccezione dell'approccio di iterazione basato su set che, poiché consiste di molte singole istruzioni, non rappresenta bene rispetto al resto.
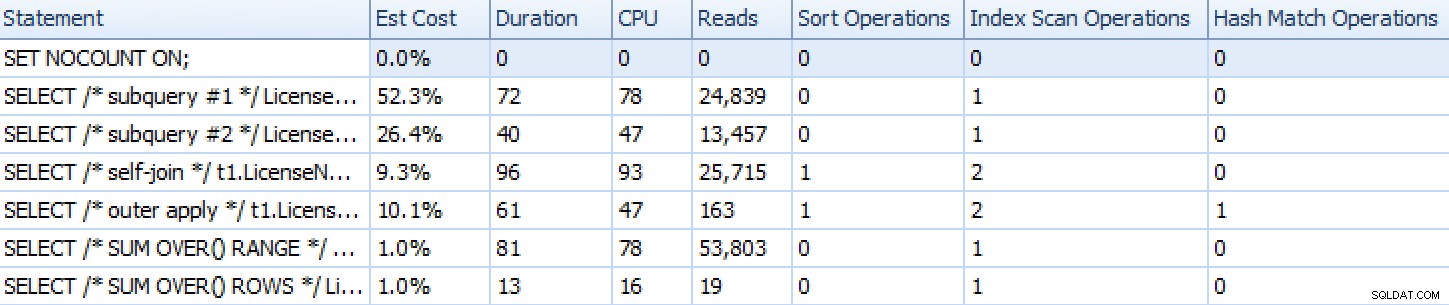
Metriche di runtime Plan Explorer per sei dei sette approcci
Oltre a rivedere i piani e confrontare le metriche di runtime in Plan Explorer, ho anche misurato il runtime non elaborato in Management Studio. Ecco i risultati dell'esecuzione di ciascuna query 10 volte, tenendo presente che ciò include anche il tempo di rendering in SSMS:
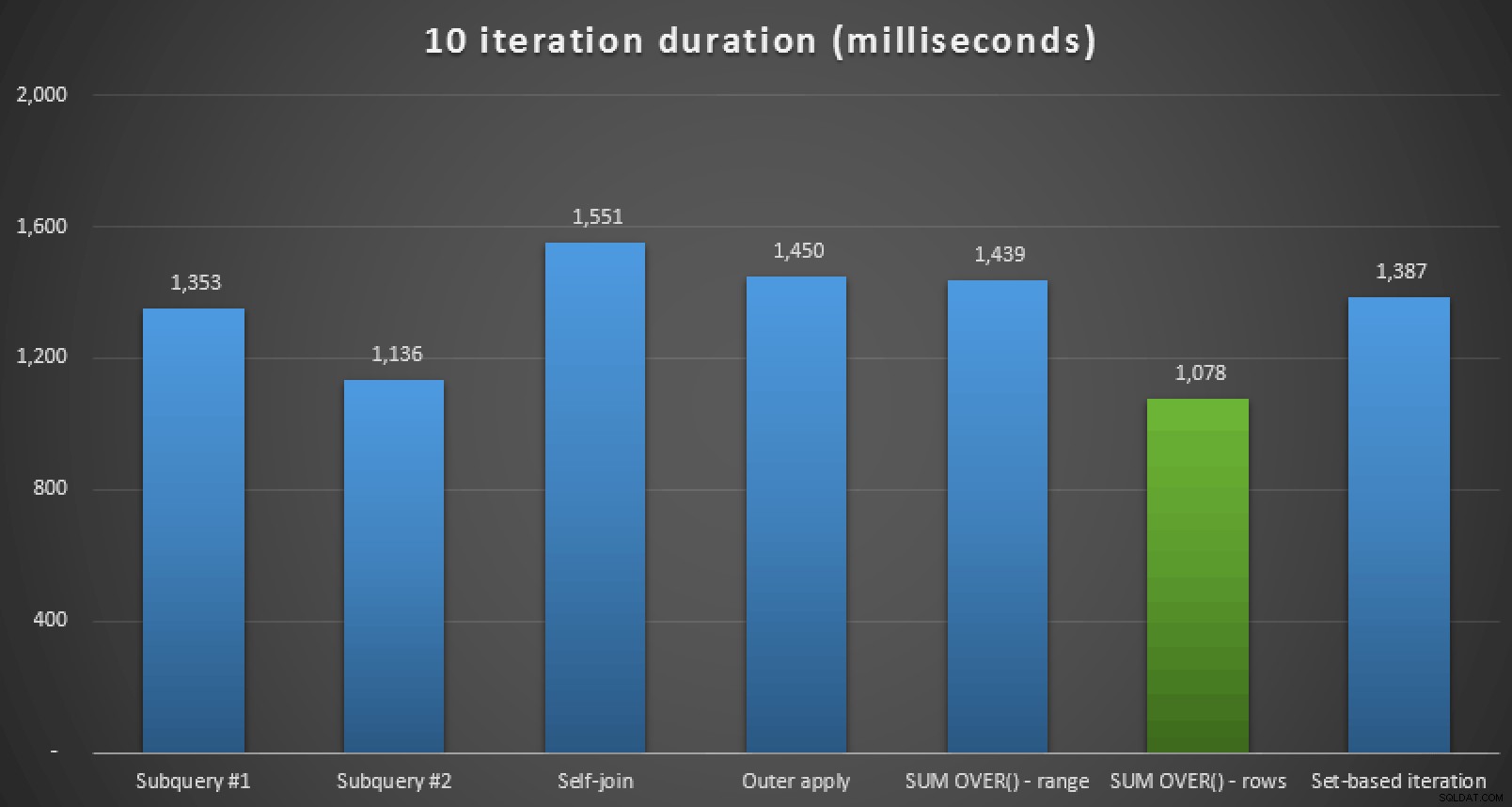
Durata del runtime, in millisecondi, per tutti e sette gli approcci (10 iterazioni )
Quindi, se utilizzi SQL Server 2012 o superiore, l'approccio migliore sembra essere SUM OVER() utilizzando ROWS UNBOUNDED PRECEDING . Se non utilizzi SQL Server 2012, il secondo approccio di sottoquery sembrava essere ottimale in termini di runtime, nonostante l'elevato numero di letture rispetto, ad esempio, a OUTER APPLY interrogazione. In tutti i casi, ovviamente, dovresti testare questi approcci, adattati al tuo schema, contro il tuo sistema. I tuoi dati, gli indici e altri fattori possono portare a una soluzione diversa che risulta ottimale nel tuo ambiente.
Altre complessità
Ora, l'indice univoco indica che qualsiasi combinazione LicenseNumber + IncidentDate conterrà un unico totale cumulativo, nel caso in cui un conducente specifico riceva più biglietti in un dato giorno. Questa regola aziendale aiuta a semplificare un po' la nostra logica, evitando la necessità di un pareggio per produrre totali parziali deterministici.
Se hai casi in cui potresti avere più righe per una determinata combinazione LicenseNumber + IncidentDate, puoi rompere il pareggio usando un'altra colonna che aiuta a rendere unica la combinazione (ovviamente la tabella di origine non avrebbe più un vincolo univoco su quelle due colonne) . Nota che questo è possibile anche nei casi in cui il DATE la colonna è in realtà DATETIME – molte persone presumono che i valori di data/ora siano univoci, ma questo non è certamente sempre garantito, indipendentemente dalla granularità.
Nel mio caso, potrei usare IDENTITY colonna, IncidentID; ecco come regolerei ciascuna soluzione (riconoscendo che potrebbero esserci modi migliori; semplicemente buttando via le idee):
/* --------- subquery #1 --------- */
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = TicketAmount + COALESCE(
(
SELECT SUM(TicketAmount)
FROM dbo.SpeedingTickets AS s
WHERE s.LicenseNumber = o.LicenseNumber
AND (s.IncidentDate < o.IncidentDate
-- added this line:
OR (s.IncidentDate = o.IncidentDate AND s.IncidentID < o.IncidentID))
), 0)
FROM dbo.SpeedingTickets AS o
ORDER BY LicenseNumber, IncidentDate;
/* --------- subquery #2 --------- */
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal =
(
SELECT SUM(TicketAmount) FROM dbo.SpeedingTickets
WHERE LicenseNumber = t.LicenseNumber
AND IncidentDate <= t.IncidentDate
-- added this line:
AND IncidentID <= t.IncidentID
)
FROM dbo.SpeedingTickets AS t
ORDER BY LicenseNumber, IncidentDate;
/* --------- self-join --------- */
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount,
RunningTotal = SUM(t2.TicketAmount)
FROM dbo.SpeedingTickets AS t1
INNER JOIN dbo.SpeedingTickets AS t2
ON t1.LicenseNumber = t2.LicenseNumber
AND t1.IncidentDate >= t2.IncidentDate
-- added this line:
AND t1.IncidentID >= t2.IncidentID
GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount
ORDER BY t1.LicenseNumber, t1.IncidentDate;
/* --------- outer apply --------- */
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount,
RunningTotal = SUM(t2.TicketAmount)
FROM dbo.SpeedingTickets AS t1
OUTER APPLY
(
SELECT TicketAmount
FROM dbo.SpeedingTickets
WHERE LicenseNumber = t1.LicenseNumber
AND IncidentDate <= t1.IncidentDate
-- added this line:
AND IncidentID <= t1.IncidentID
) AS t2
GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount
ORDER BY t1.LicenseNumber, t1.IncidentDate;
/* --------- SUM() OVER using RANGE --------- */
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = SUM(TicketAmount) OVER
(
PARTITION BY LicenseNumber
ORDER BY IncidentDate, IncidentID RANGE UNBOUNDED PRECEDING
-- added this column ^^^^^^^^^^^^
)
FROM dbo.SpeedingTickets
ORDER BY LicenseNumber, IncidentDate;
/* --------- SUM() OVER using ROWS --------- */
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = SUM(TicketAmount) OVER
(
PARTITION BY LicenseNumber
ORDER BY IncidentDate, IncidentID ROWS UNBOUNDED PRECEDING
-- added this column ^^^^^^^^^^^^
)
FROM dbo.SpeedingTickets
ORDER BY LicenseNumber, IncidentDate;
/* --------- set-based iteration --------- */
DECLARE @x TABLE
(
-- added this column, and made it the PK:
IncidentID INT PRIMARY KEY,
LicenseNumber INT NOT NULL,
IncidentDate DATE NOT NULL,
TicketAmount DECIMAL(7,2) NOT NULL,
RunningTotal DECIMAL(7,2) NOT NULL,
rn INT NOT NULL
);
-- added the additional column to the INSERT/SELECT:
INSERT @x(IncidentID, LicenseNumber, IncidentDate, TicketAmount, RunningTotal, rn)
SELECT IncidentID, LicenseNumber, IncidentDate, TicketAmount, TicketAmount,
ROW_NUMBER() OVER (PARTITION BY LicenseNumber ORDER BY IncidentDate, IncidentID)
-- and added this tie-breaker column ------------------------------^^^^^^^^^^^^
FROM dbo.SpeedingTickets;
-- the rest of the set-based iteration solution remained unchanged
Un'altra complicazione che potresti incontrare è quando non stai cercando l'intero tavolo, ma piuttosto un sottoinsieme (diciamo, in questo caso, la prima settimana di gennaio). Dovrai apportare modifiche aggiungendo WHERE clausole e tieni a mente questi predicati quando hai anche sottoquery correlate.