Nel precedente post del blog, abbiamo trattato le basi del ridimensionamento:cos'è, quali sono i tipi, cosa è indispensabile se vogliamo ridimensionare. Questo post del blog si concentrerà sulle sfide e sui modi in cui possiamo espanderci.
La sfida del ridimensionamento
Il ridimensionamento dei database non è il compito più semplice per molteplici ragioni. Concentriamoci un po' sulle sfide legate alla scalabilità orizzontale dell'infrastruttura del database.
Servizio con stato
Possiamo distinguere due diversi tipi di servizi:stateless e stateful. I servizi stateless sono quelli che non si basano su nessun tipo di dato esistente. Puoi semplicemente andare avanti, avviare un servizio del genere e funzionerà felicemente. Non devi preoccuparti dello stato dei dati né del servizio. Se è attivo, funzionerà correttamente e potrai facilmente distribuire il traffico su più istanze del servizio semplicemente aggiungendo più cloni o copie di VM esistenti, container o simili. Un esempio di tale servizio può essere un'applicazione Web:distribuita dal repository, con un server Web correttamente configurato, tale servizio si avvierà e funzionerà correttamente.
Il problema con i database è che il database è tutto tranne che senza stato. I dati devono essere inseriti nel database, devono essere elaborati e conservati. L'immagine del database non è altro che un paio di pacchetti installati sull'immagine del sistema operativo e, senza dati e una corretta configurazione, è piuttosto inutile. Ciò aumenta la complessità del ridimensionamento del database. Per i servizi stateless è sufficiente distribuirli e configurare alcuni loadbalancer per includere nuove istanze nel carico di lavoro. Per i database che distribuiscono il database, l'istanza è solo il punto di partenza. Più avanti c'è la gestione dei dati:devi trasferire i dati dall'istanza del database esistente a quella nuova. Questa può essere una parte significativa del problema e del tempo necessario affinché le nuove istanze inizino a gestire il traffico. Solo dopo che i dati sono stati trasferiti, possiamo configurare i nuovi nodi in modo che diventino parte della topologia di replica esistente:i dati devono essere aggiornati su di essi in tempo reale, in base al traffico che sta raggiungendo altri nodi.
Tempo necessario per aumentare
Il fatto che i database siano servizi con stato è una ragione diretta per la seconda sfida che dobbiamo affrontare quando vogliamo espandere l'infrastruttura del database. Servizi senza stato:li avvii e basta. È un processo abbastanza veloce. Per i database, devi trasferire i dati. Quanto tempo ci vorrà, dipende da più fattori. Quanto è grande il set di dati? Quanto è veloce l'archiviazione? Quanto è veloce la rete? Quali sono gli altri passaggi necessari per eseguire il provisioning del nuovo nodo con i nuovi dati? I dati vengono compressi/decompressi o crittografati/decrittografati durante il processo? Nel mondo reale, potrebbero essere necessarie da minuti a più ore per eseguire il provisioning dei dati su un nuovo nodo. Ciò limita seriamente i casi in cui è possibile aumentare la scalabilità dell'ambiente di database. Picchi di carico improvvisi e temporanei? Non proprio, potrebbero essere passati molto tempo prima che tu possa avviare nodi di database aggiuntivi. Aumento improvviso e costante del carico? Sì, sarà possibile gestirlo aggiungendo più nodi, ma potrebbero essere necessarie anche ore per attivarli e consentire loro di assumere il traffico dai nodi del database esistenti.
Carico aggiuntivo causato dal processo di scale-up
È molto importante tenere a mente che il tempo necessario per aumentare è solo un aspetto del problema. L'altro lato è il carico causato dal processo di ridimensionamento. Come accennato in precedenza, è necessario trasferire l'intero set di dati ai nodi appena aggiunti. Questo non è qualcosa che puoi ignorare, dopotutto, potrebbe essere un processo lungo ore per leggere i dati dal disco, inviarli sulla rete e archiviarli in una nuova posizione. Se il donatore, il nodo da cui leggi i dati, è sovraccarico, devi considerare come si comporterà se sarà costretto a svolgere attività di I/O aggiuntiva pesante? Il tuo cluster sarà in grado di sostenere un carico di lavoro aggiuntivo se è già sottoposto a forti pressioni e diffuso? La risposta potrebbe non essere facile da ottenere poiché il carico sui nodi può assumere forme diverse. Il carico legato alla CPU sarà lo scenario migliore in quanto l'attività di I/O dovrebbe essere bassa e le operazioni su disco aggiuntive saranno gestibili. Il carico legato all'I/O, d'altra parte, può rallentare notevolmente il trasferimento dei dati, con un grave impatto sulla capacità di scalabilità del cluster.
Scrivi ridimensionamento
Il processo di scalabilità orizzontale che abbiamo menzionato in precedenza è praticamente limitato al ridimensionamento delle letture. È fondamentale capire che il ridimensionamento delle scritture è una storia completamente diversa. Puoi ridimensionare le letture semplicemente aggiungendo più nodi e distribuendo le letture su più nodi back-end. Le scritture non sono così facili da ridimensionare. Per cominciare, non è possibile ridimensionare le scritture in questo modo. Ogni nodo che contiene l'intero set di dati è, ovviamente, necessario per gestire tutte le scritture eseguite da qualche parte nel cluster perché solo applicando tutte le modifiche al set di dati è possibile mantenere la coerenza. Quindi, quando ci pensi, non importa come progetti il tuo cluster e quale tecnologia usi, ogni membro del cluster deve eseguire ogni scrittura. Che si tratti di una replica, che replica tutte le scritture dal suo master o nodo in un cluster multi-master come Galera o InnoDB Cluster eseguendo tutte le modifiche al set di dati eseguite su tutti gli altri nodi del cluster, il risultato è lo stesso. Le scritture non vengono ridimensionate semplicemente aggiungendo più nodi al cluster.
Come possiamo aumentare il database?
Quindi, sappiamo che tipo di sfide stiamo affrontando. Quali sono le opzioni che abbiamo? Come possiamo espandere il database?
Aggiungendo repliche
Prima di tutto, scaleremo semplicemente aggiungendo più nodi. Certo, ci vorrà tempo e certo, non è un processo che puoi aspettarti che avvenga immediatamente. Certo, non sarai in grado di ridimensionare le scritture in questo modo. D'altra parte, il problema più tipico che dovrai affrontare è il carico della CPU causato dalle query SELECT e, come discusso, le letture possono essere semplicemente ridimensionate aggiungendo semplicemente più nodi al cluster. Più nodi da cui leggere significa che il carico su ciascuno di essi sarà ridotto. Quando sei all'inizio del tuo viaggio nel ciclo di vita della tua applicazione, supponi semplicemente che questo è ciò con cui avrai a che fare. Carico della CPU, query non efficienti. È molto improbabile che tu debba ridimensionare le scritture fino a molto più avanti nel ciclo di vita, quando la tua applicazione è già matura e devi gestire il numero di clienti.
Con partizionamento orizzontale
L'aggiunta di nodi non risolverà il problema di scrittura, è quello che abbiamo stabilito. Quello che devi fare invece è il partizionamento orizzontale, suddividendo il set di dati nel cluster. In questo caso ogni nodo contiene solo una parte dei dati, non tutto. Questo ci consente di iniziare finalmente a ridimensionare le scritture. Supponiamo di avere quattro nodi, ciascuno contenente metà del set di dati.
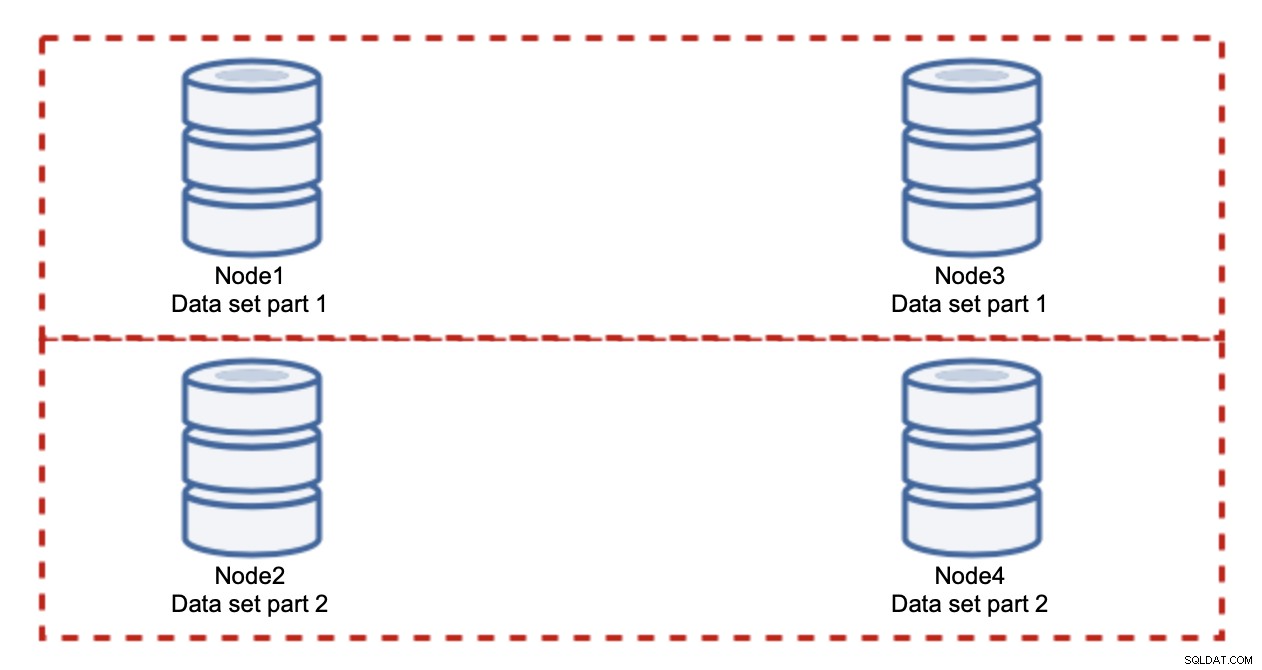
Come puoi vedere, l'idea è semplice. Se la scrittura è correlata alla parte 1 del set di dati, verrà eseguita su node1 e node3. Se è correlato alla parte 2 del set di dati, verrà eseguito su node2 e node4. Puoi pensare ai nodi del database come a dischi in un RAID. Qui abbiamo un esempio di RAID10, due coppie di mirror, per la ridondanza. Nell'implementazione reale potrebbe essere più complesso, potresti avere più di una replica dei dati per una migliore disponibilità elevata. Il succo è, supponendo una divisione perfettamente equa dei dati, metà delle scritture colpirà node1 e node3 e l'altra metà nodi 2 e 4. Se vuoi dividere ulteriormente il carico, puoi introdurre la terza coppia di nodi:
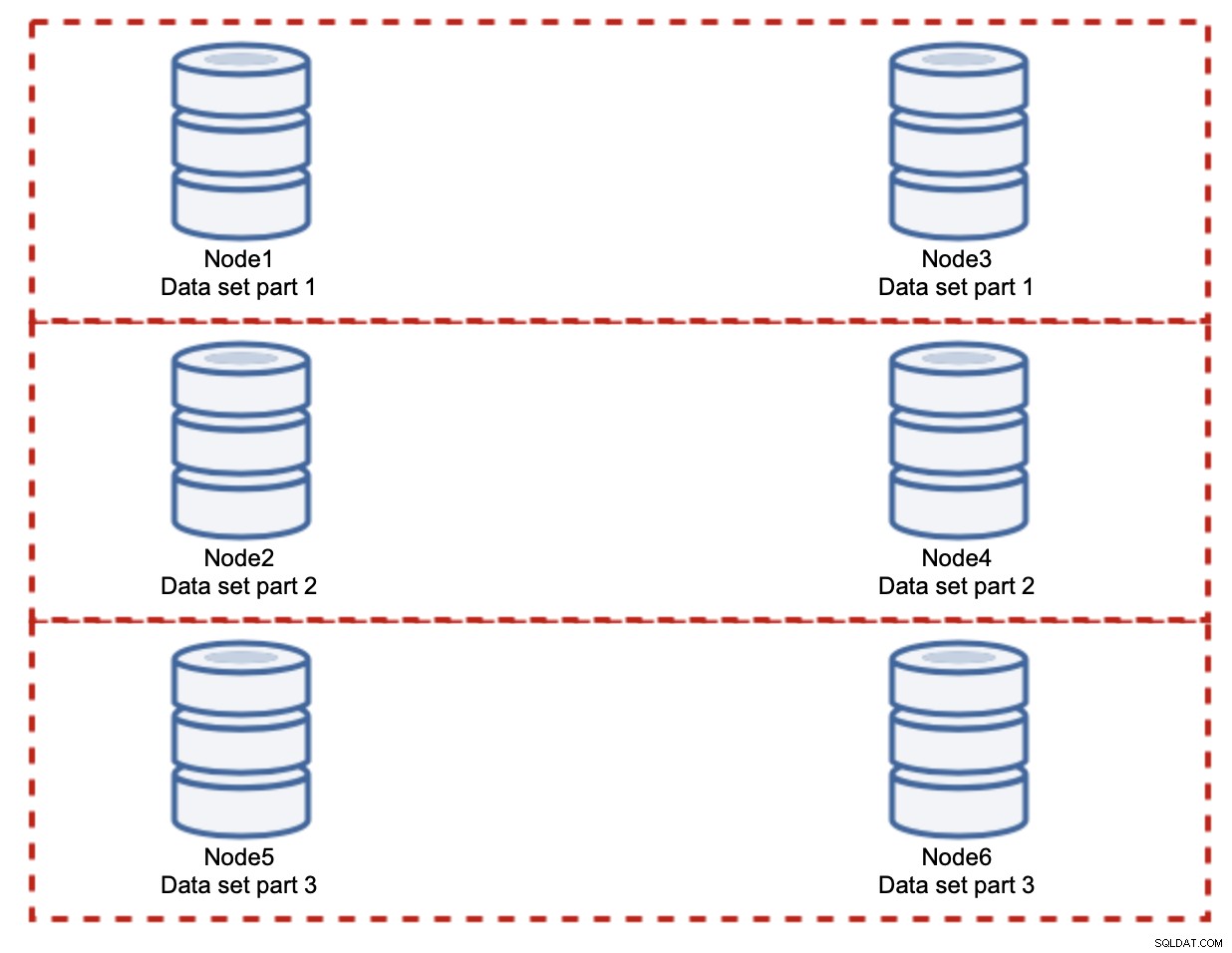
In questo caso, ancora una volta, supponendo una divisione perfettamente equa, ogni coppia essere responsabile del 33% di tutte le scritture nel cluster.
Questo riassume praticamente l'idea dello sharding. Nel nostro esempio, aggiungendo più shard, possiamo ridurre l'attività di scrittura sui nodi del database al 33% del carico di I/O originale. Come puoi immaginare, questo non è privo di inconvenienti.
Come faccio a trovare su quale shard si trovano i miei dati? I dettagli non rientrano nell'ambito di questa chiamata ma in breve, puoi implementare una sorta di funzione su una determinata colonna (modulo o hash sulla colonna 'id') oppure puoi creare un metadatabase separato in cui memorizzerai i dettagli di come vengono distribuiti i dati.
Ci auguriamo che tu abbia trovato informativa questa breve serie di blog e che tu abbia avuto una migliore comprensione delle diverse sfide che dobbiamo affrontare quando vogliamo espandere l'ambiente del database. Se hai commenti o suggerimenti su questo argomento, non esitare a commentare sotto questo post e condividi la tua esperienza