Di tanto in tanto, potresti notare che uno o più join in un piano di esecuzione sono annotati con un StarJoinInfo struttura. Lo schema ufficiale dello showplan ha quanto segue da dire su questo elemento del piano (clicca per ingrandire):
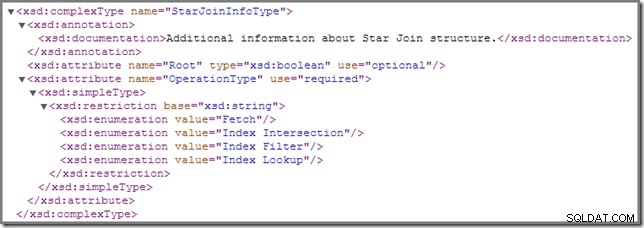
La documentazione in linea mostrata lì ("ulteriori informazioni sulla struttura di Star Join ") non è poi così illuminante, anche se gli altri dettagli sono piuttosto intriganti:li esamineremo in dettaglio.
Se consulti il tuo motore di ricerca preferito per ulteriori informazioni utilizzando termini come "Ottimizzazione dell'unione a stella di SQL Server", è probabile che vedrai risultati che descrivono filtri bitmap ottimizzati. Questa è una funzionalità separata solo per le aziende introdotta in SQL Server 2008 e non correlata a StarJoinInfo struttura del tutto.
Ottimizzazioni per le query stellari selettive
La presenza di StarJoinInfo indica che SQL Server ha applicato una di una serie di ottimizzazioni mirate a query con schema a stella selettive. Queste ottimizzazioni sono disponibili da SQL Server 2005, in tutte le edizioni (non solo Enterprise). Tieni presente che selettivo qui si riferisce al numero di righe recuperate dalla tabella dei fatti. La combinazione di predicati dimensionali in una query può comunque essere selettiva anche se i suoi singoli predicati qualificano un numero elevato di righe.
Intersezione dell'indice ordinario
Query Optimizer potrebbe prendere in considerazione la possibilità di combinare più indici non cluster in cui non esiste un singolo indice adatto, come dimostra la seguente query AdventureWorks:
SELECT COUNT_BIG(*) FROM Sales.SalesOrderHeader WHERE SalesPersonID = 276 AND CustomerID = 29522;
L'ottimizzatore determina che combinando due indici non cluster (uno su SalesPersonID e l'altro su CustomerID ) è il modo più economico per soddisfare questa query (non c'è indice su entrambe le colonne):
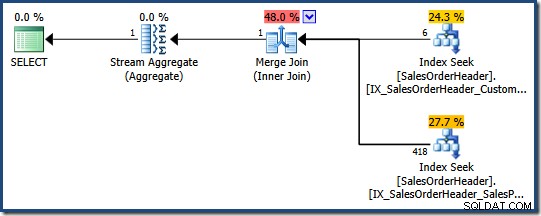
Ogni ricerca dell'indice restituisce la chiave dell'indice cluster per le righe che passano il predicato. Il join corrisponde alle chiavi restituite per garantire che solo le righe che corrispondono a entrambe i predicati vengono trasmessi.
Se la tabella fosse un heap, ogni ricerca restituirebbe identificatori di riga heap (RID) invece di chiavi di indice cluster, ma la strategia generale è la stessa:trova gli identificatori di riga per ogni predicato, quindi abbinali.
Intersezione manuale dell'indice di unione a stella
La stessa idea può essere estesa alle query che selezionano righe da una tabella dei fatti utilizzando predicati applicati alle tabelle delle dimensioni. Per vedere come funziona, considera la query seguente (usando il database di esempio Contoso BI) per trovare l'importo totale delle vendite per i lettori MP3 venduti nei negozi Contoso con esattamente 50 dipendenti:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; Per il confronto con gli sforzi successivi, questa query (molto selettiva) produce un piano di query come il seguente (fai clic per espandere):
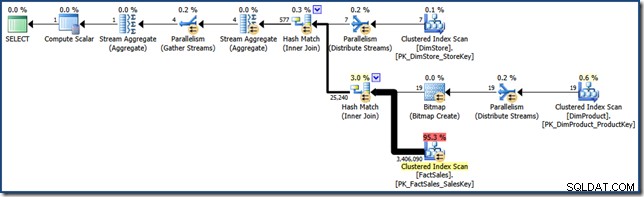
Tale piano di esecuzione ha un costo stimato di poco più di 15,6 unità . Presenta l'esecuzione parallela con una scansione completa della tabella dei fatti (sebbene con un filtro bitmap applicato).
Per impostazione predefinita, le tabelle dei fatti in questo database di esempio non includono indici non cluster sulle chiavi esterne della tabella dei fatti, quindi è necessario aggiungerne un paio:
CREATE INDEX ix_ProductKey ON dbo.FactSales (ProductKey); CREATE INDEX ix_StoreKey ON dbo.FactSales (StoreKey);
Con questi indici in atto, possiamo iniziare a vedere come utilizzare l'intersezione degli indici per migliorare l'efficienza. Il primo passaggio consiste nel trovare gli identificatori di riga della tabella dei fatti per ogni predicato separato. Le seguenti query applicano un predicato di dimensione singola, quindi tornano alla tabella dei fatti per trovare gli identificatori di riga (chiavi di indice cluster della tabella dei fatti):
-- Product dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
WHERE DP.ProductName LIKE N'%MP3%';
-- Store dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount = 50; I piani di query mostrano una scansione della tabella di piccole dimensioni, seguita da ricerche che utilizzano l'indice non cluster della tabella dei fatti per trovare gli identificatori di riga (ricorda che gli indici non cluster includono sempre la chiave di clustering della tabella di base o il RID dell'heap):
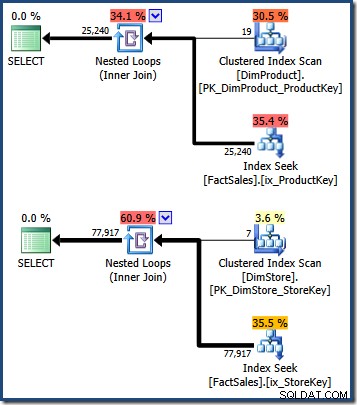
L'intersezione di questi due insiemi di chiavi dell'indice cluster della tabella dei fatti identifica le righe che dovrebbero essere restituite dalla query originale. Una volta che abbiamo questi identificatori di riga, dobbiamo solo cercare l'importo delle vendite in ogni riga della tabella dei fatti e calcolare la somma.
Query manuale sull'intersezione dell'indice
Mettendo tutto questo insieme in una query si ottiene quanto segue:
SELECT SUM(FS.SalesAmount)
FROM
(
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
WHERE DP.ProductName LIKE N'%MP3%'
INTERSECT
-- Store dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount = 50
) AS Keys
JOIN dbo.FactSales AS FS WITH (FORCESEEK)
ON FS.SalesKey = Keys.SalesKey
OPTION (MAXDOP 1);
Il FORCESEEK il suggerimento è lì per assicurarci di ottenere ricerche di punti nella tabella dei fatti. Senza questo, l'ottimizzatore sceglie di scansionare la tabella dei fatti, che è esattamente ciò che stiamo cercando di evitare. Il MAXDOP 1 suggerimento aiuta solo a mantenere il piano finale a una dimensione abbastanza ragionevole per scopi di visualizzazione (fai clic per vederlo a schermo intero):
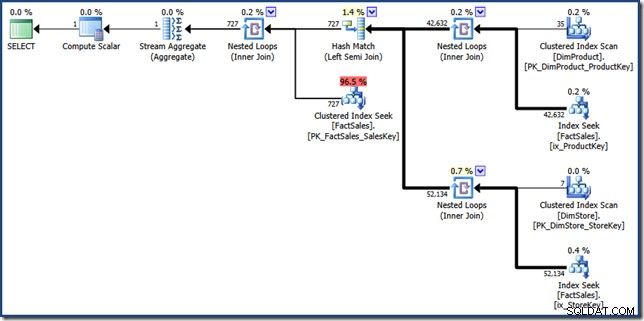
Le parti componenti del piano di intersezione dell'indice manuale sono abbastanza facili da identificare. Le due ricerche nell'indice non cluster della tabella dei fatti sul lato destro producono i due insiemi di identificatori di riga della tabella dei fatti. L'hash join trova l'intersezione di questi due insiemi. La ricerca dell'indice cluster nella tabella dei fatti trova gli importi delle vendite per questi identificatori di riga. Infine, lo Stream Aggregate calcola l'importo totale.
Questo piano di query esegue relativamente poche ricerche negli indici non cluster e cluster della tabella dei fatti. Se la query è sufficientemente selettiva, questa potrebbe essere una strategia di esecuzione più economica rispetto alla scansione completa della tabella dei fatti. Il database di esempio di Contoso BI è relativamente piccolo, con solo 3,4 milioni di righe nella tabella dei fatti di vendita. Per tabelle dei fatti più grandi, la differenza tra una scansione completa e alcune centinaia di ricerche potrebbe essere molto significativa. Sfortunatamente, la riscrittura manuale introduce alcuni gravi errori di cardinalità, risultando in un piano con un costo stimato di 46,5 unità .
Intersezione automatica dell'indice di unione a stella con ricerche
Fortunatamente, non dobbiamo decidere se la query che stiamo scrivendo è abbastanza selettiva da giustificare questa riscrittura del manuale. Le ottimizzazioni dell'unione a stella per query selettive significano che Query Optimizer può esplorare questa opzione per noi, utilizzando la sintassi della query originale più intuitiva:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; L'ottimizzatore produce il seguente piano di esecuzione con un costo stimato di 1,64 unità (clicca per ingrandire):
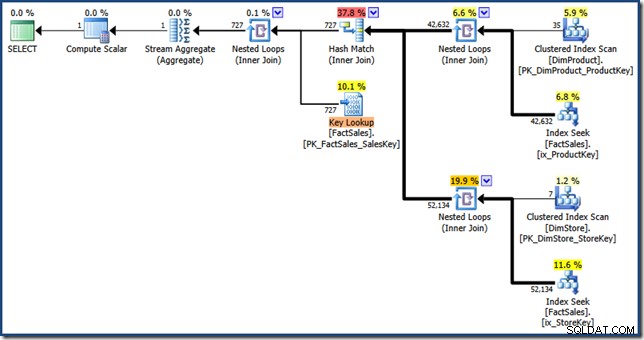
Le differenze tra questo piano e la versione manuale sono:l'intersezione dell'indice è un inner join anziché un semi join; e la ricerca nell'indice cluster viene mostrata come una ricerca chiave anziché come ricerca indice cluster. A rischio di complicare il punto, se la tabella dei fatti fosse un mucchio, la ricerca chiave sarebbe una ricerca RID.
Le proprietà StarJoinInfo
I join in questo piano hanno tutti un StarJoinInfo struttura. Per vederlo, fai clic su un iteratore di join e guarda nella finestra delle proprietà di SSMS. Fare clic sulla freccia a sinistra di StarJoinInfo elemento per espandere il nodo.
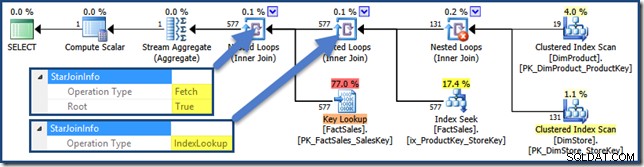
I join della tabella dei fatti non cluster a destra del piano sono ricerche nell'indice create dall'ottimizzatore:
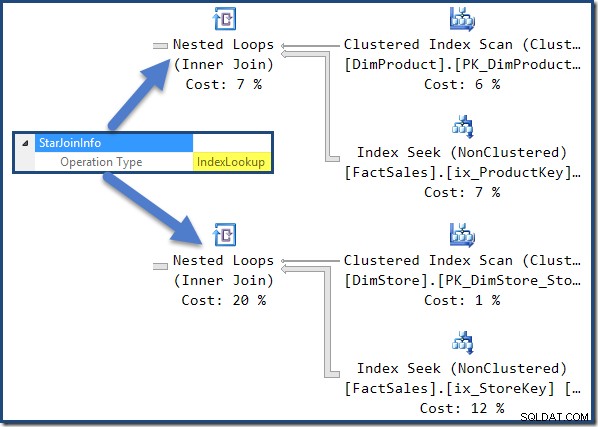
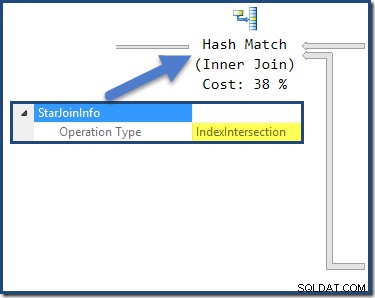
L'hash join ha un StarJoinInfo struttura che mostra che sta eseguendo un'intersezione dell'indice (di nuovo, prodotta dall'ottimizzatore):
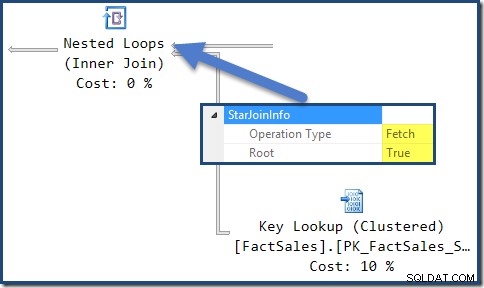
Il StarJoinInfo per il join di Nested Loops più a sinistra mostra che è stato generato per recuperare le righe della tabella dei fatti in base all'identificatore di riga. È alla radice del sottoalbero di join a stella generato dall'ottimizzatore:
Prodotti cartesiani e ricerca indici multicolonna
I piani di intersezione dell'indice considerati come parte delle ottimizzazioni dell'unione a stella sono utili per query selettive di tabelle dei fatti in cui esistono indici non cluster a colonna singola su chiavi esterne della tabella dei fatti (una pratica di progettazione comune).
A volte ha senso anche creare indici a più colonne sulle chiavi esterne della tabella dei fatti, per le combinazioni di query frequenti. Le ottimizzazioni delle query a stella selettive integrate contengono una riscrittura anche per questo scenario. Per vedere come funziona, aggiungi il seguente indice a più colonne alla tabella dei fatti:
CREATE INDEX ix_ProductKey_StoreKey ON dbo.FactSales (ProductKey, StoreKey);
Compila di nuovo la query di prova:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; Il piano di query non presenta più l'intersezione dell'indice (fare clic per ingrandire):
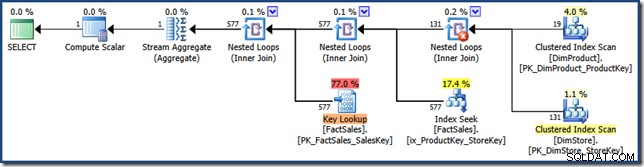
La strategia qui scelta consiste nell'applicare ciascun predicato alle tabelle dimensionali, prendere il prodotto cartesiano dei risultati e utilizzarlo per cercare in entrambe le chiavi dell'indice a più colonne. Il piano di query esegue quindi una ricerca chiave nella tabella dei fatti utilizzando gli identificatori di riga esattamente come visto in precedenza.
Il piano di query è particolarmente interessante perché combina tre caratteristiche che sono spesso considerate cose negative (scansioni complete, prodotti cartesiani e ricerche di chiavi) in un'ottimizzazione delle prestazioni . Questa è una strategia valida quando ci si aspetta che il prodotto delle due dimensioni sia molto piccolo.
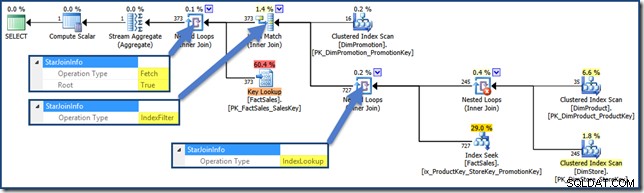
Non ci sono StarJoinInfo per il prodotto cartesiano, ma gli altri join hanno informazioni (clicca per ingrandire):
Filtro indice
Facendo riferimento allo schema dello showplan, c'è un altro StarJoinInfo operazione che dobbiamo coprire:
Il Index Filter il valore viene visualizzato con i join considerati sufficientemente selettivi da valere la pena di essere eseguiti prima del recupero della tabella dei fatti. I join non sufficientemente selettivi verranno eseguiti dopo il recupero e non avranno un StarJoinInfo struttura.
Per visualizzare un filtro indice utilizzando la nostra query di test, dobbiamo aggiungere una terza tabella di join al mix, rimuovere gli indici delle tabelle dei fatti non cluster creati finora e aggiungerne uno nuovo:
CREATE INDEX ix_ProductKey_StoreKey_PromotionKey
ON dbo.FactSales (ProductKey, StoreKey, PromotionKey);
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
JOIN dbo.DimPromotion AS DPR
ON DPR.PromotionKey = FS.PromotionKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'
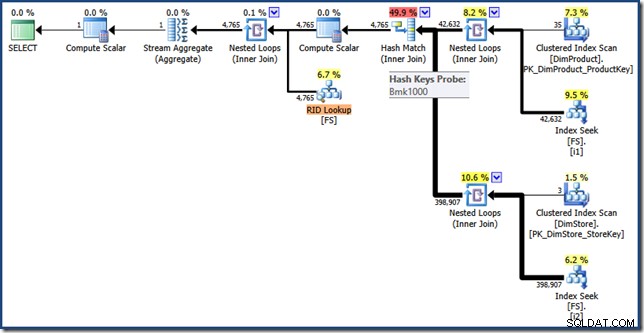
AND DPR.DiscountPercent <= 0.1; Il piano di query è ora (clicca per ingrandire):
Un piano di query di intersezione dell'indice heap
Per completezza, ecco uno script per creare una copia heap della tabella dei fatti con i due indici non cluster necessari per abilitare la riscrittura dell'ottimizzatore dell'intersezione dell'indice:
SELECT * INTO FS FROM dbo.FactSales;
CREATE INDEX i1 ON dbo.FS (ProductKey);
CREATE INDEX i2 ON dbo.FS (StoreKey);
SELECT SUM(FS.SalesAmount)
FROM FS AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount <= 10
AND DP.ProductName LIKE N'%MP3%'; Il piano di esecuzione per questa query ha le stesse funzionalità di prima, ma l'intersezione dell'indice viene eseguita utilizzando i RID anziché le chiavi di indice raggruppate della tabella dei fatti e il recupero finale è una ricerca RID (fai clic per espandere):
Pensieri finali
Le riscritture dell'ottimizzatore mostrate qui sono mirate a query che restituiscono un numero di righe relativamente piccolo da un grande tabella dei fatti. Queste riscritture sono disponibili in tutte le edizioni di SQL Server dal 2005.
Sebbene sia destinato a velocizzare le query selettive dello schema a stella (e fiocco di neve) nel data warehousing, l'ottimizzatore può applicare queste tecniche ovunque rilevi un insieme appropriato di tabelle e join. L'euristica utilizzata per rilevare le query sulle stelle è piuttosto ampia, quindi potresti incontrare forme di piano con StarJoinInfo strutture in quasi tutti i tipi di database. Qualsiasi tabella di dimensioni ragionevoli (diciamo 100 pagine o più) con riferimenti a tabelle più piccole (simili a dimensioni) è un potenziale candidato per queste ottimizzazioni (nota che le chiavi esterne esplicite non richiesto).
Per quelli di voi che amano queste cose, la regola dell'ottimizzatore responsabile della generazione di schemi di join a stella selettivi da un join logico di n-tabelle è chiamata StarJoinToIdxStrategy (stella unisciti alla strategia dell'indice).