Come DBA di SQL Server, abbiamo sentito che le strutture degli indici possono migliorare notevolmente le prestazioni di una determinata query (o set di query). Tuttavia, ci sono alcuni dettagli che molti DBA trascurano, come i seguenti:
- Le strutture degli indici possono frammentarsi, portando potenzialmente a problemi di degrado delle prestazioni.
- Una volta distribuita una struttura di indice per una tabella di database, SQL Server la aggiorna ogni volta che vengono eseguite operazioni di scrittura per quella tabella. Ciò accade se le colonne conformi all'indice sono interessate.
- In SQL Server sono presenti metadati che possono essere utilizzati per sapere quando le statistiche per una particolare struttura di indice sono state aggiornate (se mai) per l'ultima volta. Statistiche insufficienti o obsolete possono influire sulle prestazioni di determinate query.
- In SQL Server sono presenti metadati che possono essere usati per sapere quanto una struttura di indice è stata consumata da operazioni di lettura o aggiornata da operazioni di scrittura da SQL Server stesso. Queste informazioni potrebbero essere utili per sapere se esistono indici il cui volume di scrittura supera di gran lunga quello di lettura. Può essere potenzialmente una struttura di indice che non è così utile da tenere in giro.*
*È molto importante tenere presente che la vista di sistema che contiene questi particolari metadati viene cancellata ogni volta che l'istanza di SQL Server viene riavviata, quindi non si tratterà di informazioni dalla sua concezione.
Data l'importanza di questi dettagli, ho creato una stored procedure per tenere traccia delle informazioni relative alle strutture degli indici nel suo ambiente, per agire il più attivamente possibile.
Considerazioni iniziali
- Assicurati che l'account che esegue questa stored procedure disponga di privilegi sufficienti. Probabilmente potresti iniziare con quelli di sysadmin e poi andare il più granulare possibile per assicurarti che l'utente abbia il minimo di privilegi richiesti per il corretto funzionamento dell'SP.
- Gli oggetti del database (tabella del database e stored procedure) verranno creati all'interno del database selezionato al momento dell'esecuzione dello script, quindi scegliere con attenzione.
- Lo script è realizzato in modo da poter essere eseguito più volte senza che venga generato un errore. Per la stored procedure, ho utilizzato l'istruzione CREATE OR ALTER PROCEDURE, disponibile da SQL Server 2016 SP1.
- Sentiti libero di cambiare il nome degli oggetti di database creati se desideri utilizzare una convenzione di denominazione diversa.
- Quando si sceglie di rendere persistenti i dati restituiti dalla stored procedure, la tabella di destinazione verrà prima troncata in modo che venga archiviato solo il set di risultati più recente. Puoi apportare le modifiche necessarie se vuoi che si comporti in modo diverso, per qualsiasi motivo (forse per conservare le informazioni storiche?).
Come utilizzare la stored procedure?
- Copia e incolla il codice T-SQL (disponibile in questo articolo).
- L'SP prevede 2 parametri:
- @persistData:"Y" se il DBA desidera salvare l'output in una tabella di destinazione e "N" se il DBA desidera solo vedere direttamente l'output.
- @db:'all' per ottenere le informazioni per tutti i database (sistema e utente), 'user' per indirizzare i database degli utenti, 'system' per indirizzare solo i database di sistema (escluso tempdb) e infine il nome effettivo di un determinato database.
Campi presentati e loro significato
- dbName: il nome del database in cui risiede l'oggetto indice.
- Nome schema: il nome dello schema in cui risiede l'oggetto indice.
- Nometabella: il nome della tabella in cui risiede l'oggetto indice.
- nomeindice: il nome della struttura dell'indice.
- digita: il tipo di indice (ad es. Clustered, Non Clustered).
- tipo_unità_allocazione: specifica il tipo di dati a cui si fa riferimento (es. dati in-row, dati lob).
- frammentazione: la quantità di frammentazione (in %) che ha attualmente la struttura dell'indice.
- pagine: il numero di pagine da 8 KB che formano la struttura dell'indice.
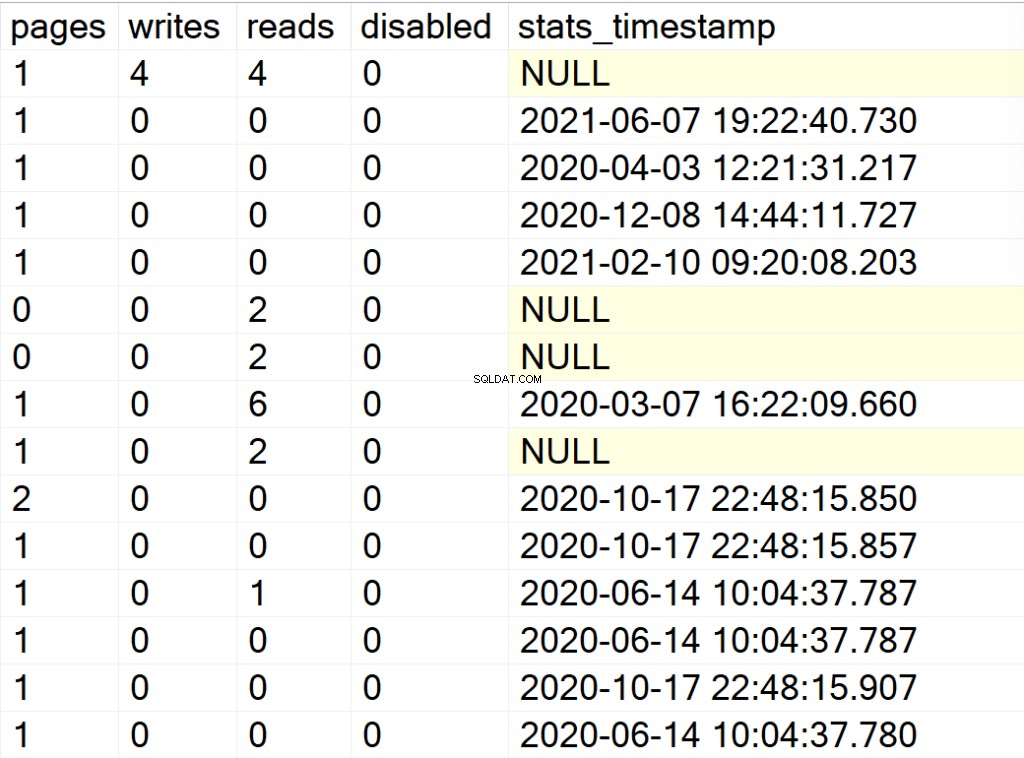
- scrive: il numero di scritture che la struttura dell'indice ha subito dall'ultimo riavvio dell'istanza di SQL Server.
- legge: il numero di letture che la struttura dell'indice ha subito dall'ultimo riavvio dell'istanza di SQL Server.
- disabilitato: 1 se la struttura dell'indice è attualmente disabilitata o 0 se la struttura è abilitata.
- stats_timestamp: il valore del timestamp dell'ultimo aggiornamento delle statistiche per la particolare struttura dell'indice (NULL se mai).
- data_collection_timestamp: visibile solo se 'Y' viene passato al parametro @persistData e viene utilizzato per sapere quando è stato eseguito l'SP e le informazioni sono state salvate correttamente nella tabella DBA_Indexes.
Test di esecuzione
Dimostrerò alcune esecuzioni della Stored Procedure in modo che tu possa farti un'idea di cosa aspettarti da essa:
*Puoi trovare il codice T-SQL completo dello script alla fine di questo articolo, quindi assicurati di eseguirlo prima di procedere con la sezione seguente.
*Il set di risultati sarà troppo ampio per adattarsi perfettamente a 1 screenshot, quindi condividerò tutti gli screenshot necessari per presentare le informazioni complete.
/* Visualizza tutte le informazioni sugli indici per tutti i database di sistema e utente */
EXEC GetIndexData @persistData = 'N',@db = 'all'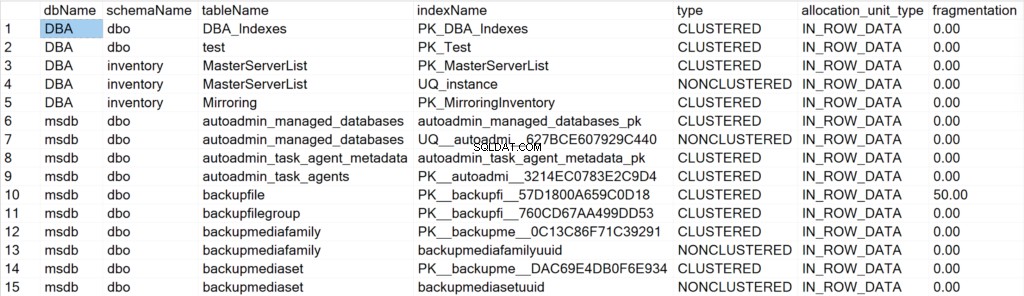
/* Visualizza tutte le informazioni sugli indici per tutti i database di sistema */
EXEC GetIndexData @persistData = 'N',@db = 'system'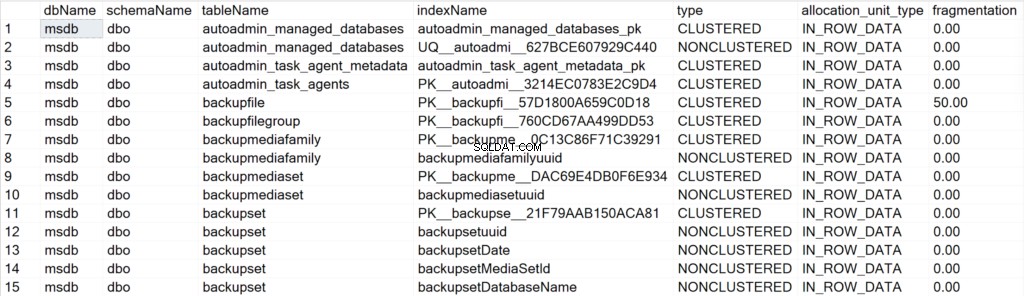
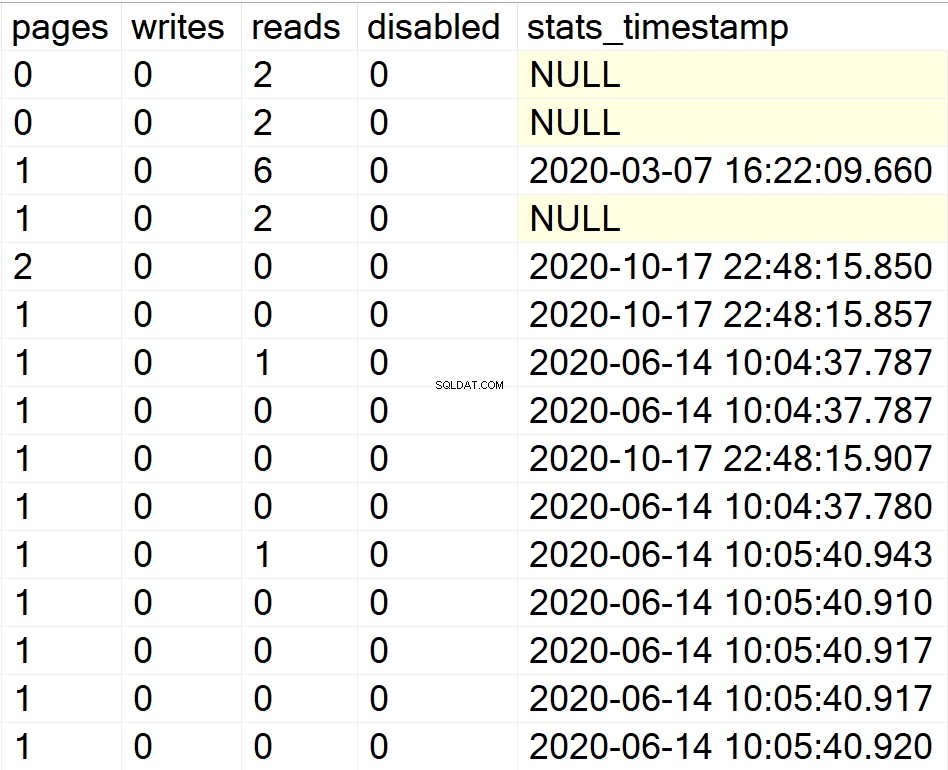
/* Visualizza tutte le informazioni sugli indici per tutti i database utente */
EXEC GetIndexData @persistData = 'N',@db = 'user'
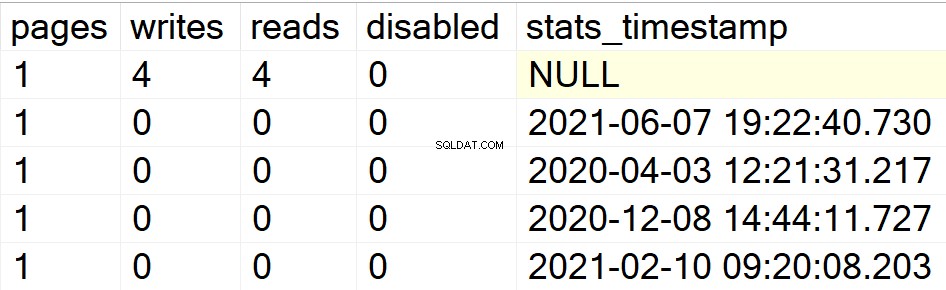
/* Visualizza tutte le informazioni sugli indici per database utente specifici */
Nei miei esempi precedenti, solo il database DBA è apparso come il mio unico database utente con indici al suo interno. Pertanto, permettimi di creare una struttura di indice in un altro database che ho in giro nella stessa istanza in modo che tu possa vedere se l'SP fa il suo lavoro o meno.
EXEC GetIndexData @persistData = 'N',@db = 'db2'
Tutti gli esempi mostrati finora dimostrano l'output che si ottiene quando non si desidera mantenere i dati in modo permanente, per le diverse combinazioni di opzioni per il parametro @db. L'output è vuoto quando si specifica un'opzione che non è valida o il database di destinazione non esiste. Ma cosa succede quando il DBA vuole mantenere i dati in una tabella di database? Scopriamolo.
*Eseguirò l'SP per un solo caso perché il resto delle opzioni per il parametro @db sono state mostrate più o meno sopra e il risultato è lo stesso ma persiste in una tabella di database.
EXEC GetIndexData @persistData = 'Y',@db = 'user'
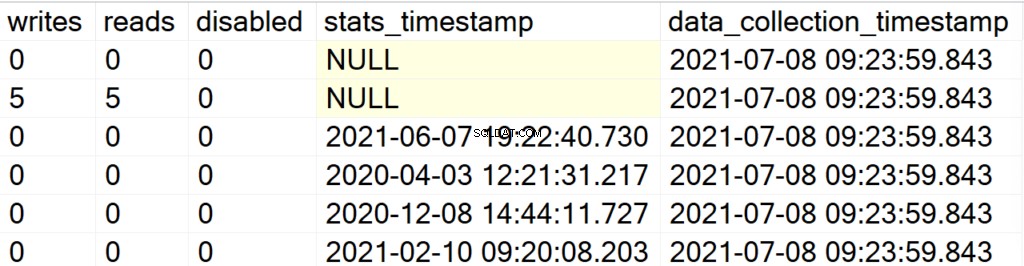
Ora, dopo aver eseguito la stored procedure, non otterrai alcun output. Per interrogare il set di risultati devi emettere un'istruzione SELECT sulla tabella DBA_Indexes. L'attrazione principale qui è che puoi interrogare il set di risultati ottenuto, per la post-analisi, e l'aggiunta del campo data_collection_timestamp che ti farà sapere quanto sono recenti/vecchi i dati che stai guardando.
Query laterali
Ora, per fornire più valore al DBA, ho preparato alcune query che possono aiutarti a ottenere informazioni utili dai dati persistenti nella tabella.
*Query per trovare indici molto frammentati nel complesso.
*Scegli il numero di % che ritieni adatto.
*Le 1500 pagine sono basate su un articolo che ho letto, basato su una raccomandazione di Microsoft.
SELECT * FROM DBA_Indexes WHERE fragmentation >= 85 AND pages >= 1500;*Query per trovare indici disabilitati all'interno del tuo ambiente.
SELECT * FROM DBA_Indexes WHERE disabled = 1;*Query per trovare indici (per lo più non in cluster) che non sono molto utilizzati dalle query, almeno non dall'ultimo riavvio dell'istanza di SQL Server.
SELECT * FROM DBA_Indexes WHERE writes > reads AND type <> 'CLUSTERED';*Query per trovare statistiche che non sono mai state aggiornate o sono vecchie.
*Decidi tu cosa c'è di vecchio nel tuo ambiente, quindi assicurati di modificare il numero di giorni di conseguenza.
SELECT * FROM DBA_Indexes WHERE stats_timestamp IS NULL OR DATEDIFF(DAY, stats_timestamp, GETDATE()) > 60;Ecco il codice completo della Stored Procedure:
*All'inizio dello script, vedrai il valore predefinito che la stored procedure assume se non viene passato alcun valore per ciascun parametro.
IF NOT EXISTS (SELECT * FROM dbo.sysobjects where id = object_id(N'DBA_Indexes') and OBJECTPROPERTY(id, N'IsTable') = 1)
BEGIN
CREATE TABLE DBA_Indexes(
[dbName] VARCHAR(128) NOT NULL,
[schemaName] VARCHAR(128) NOT NULL,
[tableName] VARCHAR(128) NOT NULL,
[indexName] VARCHAR(128) NOT NULL,
[type] VARCHAR(128) NOT NULL,
[allocation_unit_type] VARCHAR(128) NOT NULL,
[fragmentation] DECIMAL(10,2) NOT NULL,
[pages] INT NOT NULL,
[writes] INT NOT NULL,
[reads] INT NOT NULL,
[disabled] TINYINT NOT NULL,
[stats_timestamp] DATETIME NULL,
[data_collection_timestamp] DATETIME NOT NULL
CONSTRAINT PK_DBA_Indexes PRIMARY KEY CLUSTERED ([dbName],[schemaName],[tableName],[indexName],[type],[allocation_unit_type],[data_collection_timestamp])
) ON [PRIMARY]
END
GO
DECLARE @sqlCommand NVARCHAR(MAX)
SET @sqlCommand = '
CREATE OR ALTER PROCEDURE GetIndexData
@persistData CHAR(1) = ''N'',
@db NVARCHAR(64)
AS
BEGIN
SET NOCOUNT ON
DECLARE @query NVARCHAR(MAX)
DECLARE @tmp_IndexInfo TABLE(
[dbName] VARCHAR(128),
[schemaName] VARCHAR(128),
[tableName] VARCHAR(128),
[indexName] VARCHAR(128),
[type] VARCHAR(128),
[allocation_unit_type] VARCHAR(128),
[fragmentation] DECIMAL(10,2),
[pages] INT,
[writes] INT,
[reads] INT,
[disabled] TINYINT,
[stats_timestamp] DATETIME)
SET @query = ''
USE [?]
''
IF(@db = ''all'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') != 2
''
IF(@db = ''system'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') < 5 AND DB_ID(''''?'''') != 2
''
IF(@db = ''user'')
SET @query += ''
IF DB_ID(''''?'''') > 4
''
IF(@db != ''user'' AND @db != ''all'' AND @db != ''system'')
SET @query += ''
IF DB_NAME() = ''+CHAR(39)example@sqldat.com+CHAR(39)+''
''
SET @query += ''
BEGIN
DECLARE @DB_ID INT;
SET @DB_ID = DB_ID();
SELECT
db_name(@DB_ID) AS db_name,
s.name,
t.name,
i.name,
i.type_desc,
ips.alloc_unit_type_desc,
CONVERT(DECIMAL(10,2),ips.avg_fragmentation_in_percent),
ips.page_count,
ISNULL(ius.user_updates,0),
ISNULL(ius.user_seeks + ius.user_scans + ius.user_lookups,0),
i.is_disabled,
STATS_DATE(st.object_id, st.stats_id)
FROM sys.indexes i
JOIN sys.tables t ON i.object_id = t.object_id
JOIN sys.schemas s ON s.schema_id = t.schema_id
JOIN sys.dm_db_index_physical_stats (@DB_ID, NULL, NULL, NULL, NULL) ips ON ips.database_id = @DB_ID AND ips.object_id = t.object_id AND ips.index_id = i.index_id
LEFT JOIN sys.dm_db_index_usage_stats ius ON ius.database_id = @DB_ID AND ius.object_id = t.object_id AND ius.index_id = i.index_id
JOIN sys.stats st ON st.object_id = t.object_id AND st.name = i.name
WHERE i.index_id > 0
END''
INSERT INTO @tmp_IndexInfo
EXEC sp_MSForEachDB @query
IF @persistData = ''N''
SELECT * FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
ELSE
BEGIN
TRUNCATE TABLE DBA_Indexes
INSERT INTO DBA_Indexes
SELECT *,GETDATE() FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
END
END
'
EXEC (@sqlCommand)
GOConclusione
- Puoi distribuire questo SP in ogni istanza di SQL Server supportata e implementare un meccanismo di avviso nell'intero stack di istanze supportate.
- Se implementi un lavoro di agente che richiede queste informazioni con relativa frequenza, puoi rimanere in cima al gioco per occuparti delle strutture degli indici all'interno dei tuoi ambienti supportati.
- Assicurati di testare correttamente questo meccanismo in un ambiente sandbox e, quando pianifichi un'implementazione di produzione, assicurati di scegliere periodi di attività bassa.
I problemi di frammentazione dell'indice possono essere complicati e stressanti. Per trovarli e risolverli, puoi utilizzare diversi strumenti, come dbForge Index Manager che può essere scaricato qui.