Nel gennaio 2015, il mio buon amico e collega MVP di SQL Server Rob Farley ha scritto di una nuova soluzione al problema di trovare la mediana nelle versioni di SQL Server precedenti al 2012. Oltre ad essere una lettura interessante di per sé, risulta essere un ottimo esempio da utilizzare per dimostrare alcune analisi avanzate del piano di esecuzione e per evidenziare alcuni comportamenti sottili di Query Optimizer e del motore di esecuzione.
Mediana singola
Sebbene l'articolo di Rob si rivolga specificamente a un calcolo della mediana raggruppato, inizierò applicando il suo metodo a un grande problema di calcolo della mediana singola, perché mette in evidenza le questioni importanti in modo più chiaro. I dati di esempio proverranno ancora una volta dall'articolo originale di Aaron Bertrand:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); L'applicazione della tecnica di Rob Farley a questo problema fornisce il codice seguente:
-- 5800ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f;
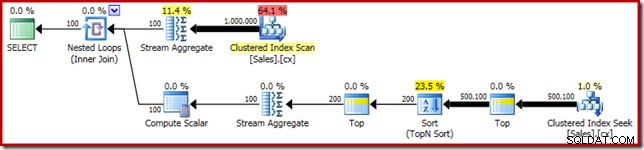
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Come al solito, ho commentato il conteggio del numero di righe nella tabella e l'ho sostituito con una costante per evitare una fonte di variazione delle prestazioni. Il piano di esecuzione per la query importante è il seguente:

Questa query viene eseguita per 5800 ms sulla mia macchina di prova.
La fuoriuscita di smistamento
La causa principale di queste scarse prestazioni dovrebbe essere chiara osservando il piano di esecuzione sopra:l'avviso sull'operatore Ordina mostra che una concessione di memoria insufficiente per l'area di lavoro ha causato uno spill di livello 2 (multi-pass) al tempdb disco:
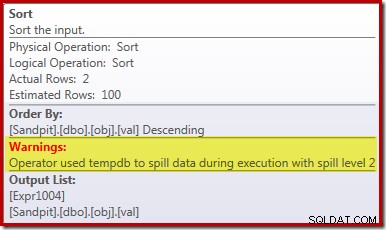
Nelle versioni di SQL Server precedenti al 2012, è necessario monitorare separatamente gli eventi di spill per l'ordinamento per vedere ciò. Ad ogni modo, la prenotazione della memoria di ordinamento insufficiente è causata da un errore di stima della cardinalità, come mostra il piano di pre-esecuzione (stimato):

La stima della cardinalità di 100 righe all'input Ordina è un'ipotesi (estremamente imprecisa) dell'ottimizzatore, a causa dell'espressione della variabile locale nell'operatore Top precedente:

Si noti che questo errore di stima della cardinalità non è un problema di riga obiettivo. L'applicazione del flag di traccia 4138 rimuoverà l'effetto riga-obiettivo sotto il primo Top, ma la stima post-Top sarà ancora un'ipotesi di 100 righe (quindi la riserva di memoria per l'ordinamento sarà ancora troppo piccola):

Suggerimento del valore della variabile locale
Esistono diversi modi per risolvere questo problema di stima della cardinalità. Un'opzione consiste nell'utilizzare un suggerimento per fornire all'ottimizzatore informazioni sul valore contenuto nella variabile:
-- 3250ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, OPTIMIZE FOR (@Count = 11000000)); -- NEW!
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); L'utilizzo del suggerimento migliora le prestazioni a 3250 ms da 5800 ms. Il piano successivo all'esecuzione mostra che l'ordinamento non si riversa più:

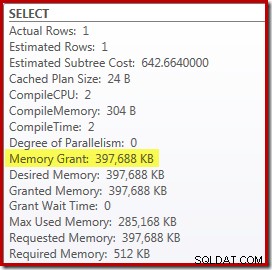
Ci sono un paio di aspetti negativi di questo però. Innanzitutto, questo nuovo piano di esecuzione richiede 388 MB concessione di memoria:memoria che potrebbe altrimenti essere utilizzata dal server per memorizzare nella cache piani, indici e dati:
In secondo luogo, può essere difficile scegliere un buon numero per il suggerimento che funzionerà bene per tutte le esecuzioni future, senza riservare memoria inutilmente.
Si noti inoltre che abbiamo dovuto suggerire un valore per la variabile superiore del 10% al valore effettivo della variabile per eliminare completamente lo spill. Questo non è raro, perché l'algoritmo di ordinamento generale è piuttosto più complesso di un semplice ordinamento sul posto. Riservare memoria pari alla dimensione del set da ordinare non sarà sempre (o anche in generale) sufficiente per evitare uno spill in fase di esecuzione.
Incorporamento e ricompilazione
Un'altra opzione consiste nell'utilizzare l'ottimizzazione dell'incorporamento dei parametri abilitata aggiungendo un suggerimento per la ricompilazione a livello di query in SQL Server 2008 SP1 CU5 o versioni successive. Questa azione consentirà all'ottimizzatore di vedere il valore di runtime della variabile e di ottimizzare di conseguenza:
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, RECOMPILE);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
Questo migliora il tempo di esecuzione a 3150 ms – 100 ms meglio rispetto all'utilizzo di OPTIMIZE FOR suggerimento. Il motivo di questo ulteriore piccolo miglioramento può essere individuato nel nuovo piano post-esecuzione:

L'espressione (2 – @Count % 2) – come visto in precedenza nel secondo operatore Top – ora può essere ripiegato fino a un unico valore noto. Una riscrittura post-ottimizzazione può quindi combinare il Top con l'Ordinamento, risultando in un unico Top N Ordina. Questa riscrittura non era possibile in precedenza perché la compressione di Top + Sort in un Top N Ordina funziona solo con un valore Top letterale costante (non variabili o parametri).
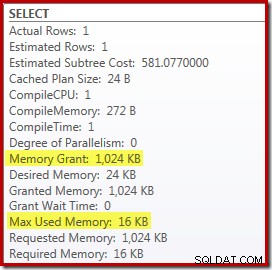
La sostituzione di Top and Sort con un Top N Sort ha un piccolo effetto benefico sulle prestazioni (100 ms qui), ma elimina quasi del tutto il requisito di memoria, perché un Top N Sort deve solo tenere traccia dell'N più alto (o più basso) righe, piuttosto che l'intero set. Come risultato di questa modifica dell'algoritmo, il piano di post-esecuzione per questa query mostra che il minimo 1 MB la memoria era riservata per l'ordinamento Top N in questo piano e solo 16 KB è stato utilizzato in fase di esecuzione (ricorda, il piano di ordinamento completo richiedeva 388 MB):
Evitare la ricompilazione
Lo svantaggio (ovvio) dell'utilizzo dell'hint per la query di ricompilazione è che richiede una compilazione completa a ogni esecuzione. In questo caso, l'overhead è piuttosto ridotto:circa 1 ms di tempo di CPU e 272 KB di memoria. Anche così, c'è un modo per modificare la query in modo da ottenere i vantaggi di un ordinamento Top N senza utilizzare alcun suggerimento e senza ricompilare.
L'idea nasce dal riconoscere che un massimo di due righe saranno necessarie per il calcolo della mediana finale. Potrebbe essere una riga o due in fase di esecuzione, ma non può mai essere di più. Questa intuizione significa che possiamo aggiungere un passaggio intermedio Top (2) logicamente ridondante alla query come segue:
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2) -- NEW!
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Il nuovo Top (con l'importantissimo valore letterale costante) significa che il piano di esecuzione finale presenta l'operatore Top N Sort desiderato senza ricompilare:

Le prestazioni di questo piano di esecuzione sono invariate rispetto alla versione con suggerimenti per la ricompilazione a 3150 ms e il requisito di memoria è lo stesso. Si noti tuttavia che la mancanza di incorporamento dei parametri significa che le stime di cardinalità al di sotto dell'ordinamento sono ipotesi di 100 righe (sebbene ciò non influisca sulle prestazioni qui).
L'aspetto principale in questa fase è che se si desidera un ordinamento Top N con memoria insufficiente, è necessario utilizzare un valore letterale costante o consentire all'ottimizzatore di visualizzare un valore letterale tramite l'ottimizzazione dell'incorporamento dei parametri.
Il calcolo scalare
Eliminando i 388 MB la concessione di memoria (mentre si apporta anche un miglioramento delle prestazioni di 100 ms) è sicuramente utile, ma è disponibile una vittoria in termini di prestazioni molto più grande. L'improbabile obiettivo di questo miglioramento finale è il calcolo scalare appena al di sopra della scansione dell'indice cluster.
Questo calcolo scalare si riferisce all'espressione (0E + f.val) contenuto nel AVG aggregare nella query. Nel caso ti sembri strano, questo è un trucco abbastanza comune per scrivere query (come moltiplicare per 1,0) per evitare l'aritmetica degli interi nel calcolo della media, ma ha alcuni effetti collaterali molto importanti.
C'è una particolare sequenza di eventi qui che dobbiamo seguire passo dopo passo.
Innanzitutto, nota che 0E è uno zero letterale costante, con un virgola mobile tipo di dati. Per aggiungerlo alla colonna intera val, il Query Processor deve convertire la colonna da intero a float (in conformità con le regole di precedenza del tipo di dati). Un simile tipo di conversione sarebbe necessario se avessimo scelto di moltiplicare la colonna per 1.0 (un valore letterale con un tipo di dati numerico implicito). Il punto importante è che questo trucco di routine introduce un'espressione .
Ora, SQL Server generalmente tenta di spingere le espressioni verso il basso il più possibile l'albero planimetrico durante la compilazione e l'ottimizzazione. Questo viene fatto per diversi motivi, incluso per rendere più semplici le espressioni di corrispondenza con le colonne calcolate e per facilitare le semplificazioni utilizzando le informazioni sui vincoli. Questa politica di push-down spiega perché Compute Scalar appare molto più vicino al livello foglia del piano di quanto suggerirebbe la posizione testuale originale dell'espressione nella query.
Un rischio dell'esecuzione di questo push-down è che l'espressione potrebbe finire per essere calcolata più volte del necessario. La maggior parte dei piani prevede un numero di righe ridotto man mano che si sale nell'albero del piano, a causa dell'effetto di join, aggregazione e filtri. Spingere le espressioni in basso nell'albero rischia quindi di valutare quelle espressioni più volte (cioè su più righe) del necessario.
Per mitigare questo, SQL Server 2005 ha introdotto un'ottimizzazione in base alla quale Compute Scalar può semplicemente definire un'espressione, con il lavoro di valutare concretamente l'espressione differito fino a quando un operatore successivo nel piano non richiede il risultato. Quando questa ottimizzazione funziona come previsto, l'effetto è quello di ottenere tutti i vantaggi di spingere le espressioni in basso nell'albero, pur continuando a valutare l'espressione solo tante volte quante effettivamente necessarie.
Cosa significa tutta questa roba Compute Scalar
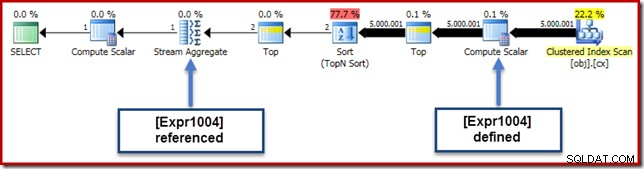
Nel nostro esempio in esecuzione, 0E + val espressione era originariamente associata a AVG aggregato, quindi potremmo aspettarci di vederlo (o poco dopo) lo Stream Aggregate. Tuttavia, questa espressione è stata repressa l'albero per diventare un nuovo Compute Scalar subito dopo la scansione, con l'espressione etichettata come [Expr1004].
Osservando il piano di esecuzione, possiamo vedere che [Expr1004] è referenziato dallo Stream Aggregate (l'estratto della scheda Plan Explorer Expressions mostrato di seguito):

A parità di condizioni, la valutazione dell'espressione [Expr1004] sarebbe differita fino a quando l'aggregato necessita di quei valori per la parte somma del calcolo della media. Poiché l'aggregato può eventualmente incontrare solo una o due righe, ciò dovrebbe comportare la valutazione di [Espr1004] solo una o due volte:
Sfortunatamente, non è proprio così che funziona qui. Il problema è l'operatore di ordinamento bloccante:
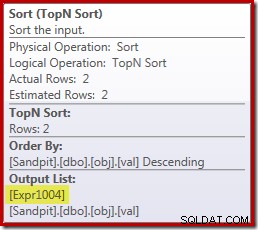
Questo forza la valutazione di [Expr1004], quindi invece di essere valutato solo una o due volte in Stream Aggregate, l'ordinamento significa che finiamo per convertire il val colonna a un float e aggiungendovi zero 5.000.001 volte!
Una soluzione alternativa
Idealmente, SQL Server sarebbe un po' più intelligente su tutto questo, ma non è così che funziona oggi. Non esiste alcun suggerimento per la query per impedire che le espressioni vengano spinte verso il basso nell'albero del piano e non possiamo nemmeno forzare il calcolo degli scalari con una guida del piano. C'è, inevitabilmente, un flag di traccia non documentato, ma non è uno di cui posso parlare in modo responsabile nel contesto attuale.
Quindi, nel bene e nel male, questo ci lascia con il tentativo di trovare una riscrittura della query che impedisca a SQL Server di separare l'espressione dall'aggregato e spingerla verso il basso oltre l'ordinamento, senza modificare il risultato della query. Non è così facile come potresti pensare, ma la modifica (certamente dall'aspetto leggermente strano) di seguito ottiene questo risultato utilizzando un CASE espressione su una funzione intrinseca non deterministica:
-- 2150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
-- NEW!
Median = AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + f.val END)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2)
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Il piano di esecuzione per questa forma finale della query è mostrato di seguito:

Si noti che un calcolo scalare non viene più visualizzato tra la scansione dell'indice cluster e la parte superiore. Il 0E + val l'espressione è ora calcolata in Stream Aggregate su un massimo di due righe (anziché cinque milioni!) e le prestazioni aumentano di un ulteriore 32% da 3150 ms a 2150 ms di conseguenza.
Questo ancora non si confronta molto bene con le prestazioni in meno di un secondo di OFFSET e soluzioni di calcolo della mediana del cursore dinamico, ma rappresenta comunque un miglioramento molto significativo rispetto ai 5800 ms originali per questo metodo su un grande insieme di problemi a mediana singola.
Il trucco CASE non è garantito per funzionare in futuro, ovviamente. L'obiettivo non riguarda tanto l'uso di strani trucchi di espressione delle maiuscole, quanto le potenziali implicazioni sulle prestazioni di Compute Scalars. Una volta che conosci questo genere di cose, potresti pensarci due volte prima di moltiplicare per 1.0 o aggiungere zero float all'interno di un calcolo medio.
Aggiornamento: si prega di vedere il primo commento per una bella soluzione alternativa di Robert Heinig che non richiede alcun trucco non documentato. Qualcosa da tenere a mente quando sei tentato di moltiplicare un intero per decimale (o float) in un aggregato medio.
Mediana raggruppata
Per completezza, e per ricollegare questa analisi più strettamente all'articolo originale di Rob, concluderemo applicando gli stessi miglioramenti a un calcolo della mediana raggruppata. Le dimensioni più piccole del set (per gruppo) significano che gli effetti saranno più piccoli, ovviamente.
I dati del campione della mediana raggruppati (sempre come originariamente creati da Aaron Bertrand) comprendono diecimila righe per ciascuno dei cento venditori immaginari:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount); L'applicazione diretta della soluzione di Rob Farley fornisce il codice seguente, che viene eseguito in 560 ms sulla mia macchina.
-- 560ms Original
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Il piano di esecuzione ha evidenti somiglianze con la singola mediana:
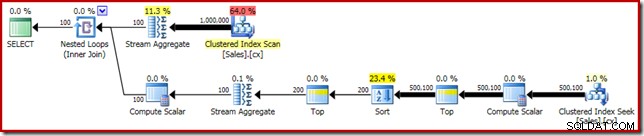
Il nostro primo miglioramento consiste nel sostituire l'ordinamento con un ordinamento Top N, aggiungendo un esplicito Top (2). Ciò migliora leggermente il tempo di esecuzione da 560 ms a 550 ms .
-- 550ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
-- NEW!
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Il piano di esecuzione mostra il Top N Ordina come previsto:
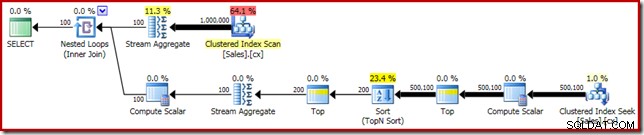
Infine, distribuiamo l'espressione CASE dall'aspetto strano per rimuovere l'espressione Compute Scalar spinta. Ciò migliora ulteriormente le prestazioni a 450 ms (un miglioramento del 20% rispetto all'originale):
-- 450ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
-- NEW!
SELECT AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + Amount END)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Il piano di esecuzione finito è il seguente: