La qualità di un piano di esecuzione dipende fortemente dall'accuratezza del numero stimato di righe emesse da ciascun operatore del piano. Se il numero stimato di righe è notevolmente distorto rispetto al numero effettivo di righe, ciò può avere un impatto significativo sulla qualità del piano di esecuzione di una query. La scarsa qualità del piano può essere responsabile di I/O eccessivi, CPU gonfiata, pressione della memoria, velocità effettiva ridotta e concorrenza generale ridotta.
Per "qualità del piano" - sto parlando di avere SQL Server genera un piano di esecuzione che si traduce in scelte dell'operatore fisico che riflettono lo stato corrente dei dati. Prendendo tali decisioni sulla base di dati accurati, c'è una migliore possibilità che la query funzioni correttamente. I valori della stima della cardinalità vengono utilizzati come input per i costi dell'operatore e quando i valori sono troppo lontani dalla realtà, l'impatto negativo sul piano di esecuzione può essere pronunciato. Queste stime vengono fornite ai vari modelli di costo associati alla query stessa e stime di righe errate possono influire su una varietà di decisioni tra cui selezione dell'indice, operazioni di ricerca rispetto a scansione, esecuzione parallela rispetto a seriale, selezione dell'algoritmo di join, join fisico interno o esterno selezione (ad es. build vs. probe), generazione di spool, ricerche di bookmark rispetto all'accesso completo a cluster o heap table, selezione di stream o aggregati hash e se una modifica dei dati utilizza o meno un piano ampio o ristretto.
Ad esempio, supponiamo che tu abbia il seguente SELECT query (utilizzando la banca dati Crediti):
SELECT m.member_no, m.lastname, p.payment_no, p.payment_dt, p.payment_amt FROM dbo.member AS m INNER JOIN dbo.payment AS p ON m.member_no = p.member_no;
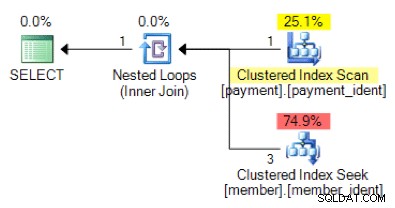
In base alla logica della query, la forma del piano seguente è quella che ti aspetteresti di vedere?
E che dire di questo piano alternativo, dove invece di un ciclo nidificato abbiamo una corrispondenza hash?
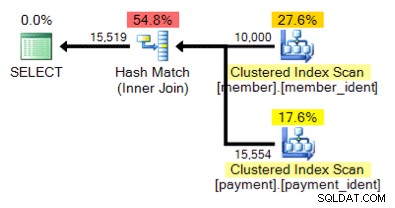
La risposta "corretta" dipende da alcuni altri fattori, ma uno dei fattori principali è il numero di righe in ciascuna delle tabelle. In alcuni casi, un algoritmo di join fisico è più appropriato dell'altro e se le ipotesi iniziali della stima della cardinalità non sono corrette, la tua query potrebbe utilizzare un approccio non ottimale.
Identificazione problemi di stima della cardinalità è relativamente semplice. Se si dispone di un piano di esecuzione effettivo, è possibile confrontare i valori di conteggio delle righe stimati rispetto a quelli effettivi per gli operatori e cercare gli asimmetrie. SQL Sentry Plan Explorer semplifica questa attività consentendo di visualizzare le righe effettive rispetto a quelle stimate per tutti gli operatori in una singola scheda della struttura ad albero del piano anziché dover passare il mouse sopra i singoli operatori nel piano grafico:

Ora, gli sbandamenti non sempre si traducono in piani di scarsa qualità, ma se riscontri problemi di prestazioni con una query e vedi tali disallineamenti nel piano, questa è un'area che merita quindi ulteriori indagini.
L'identificazione dei problemi di stima della cardinalità è relativamente semplice, ma la risoluzione spesso non lo è. Esistono diverse cause alla radice del motivo per cui possono verificarsi problemi di stima della cardinalità e tratterò dieci dei motivi più comuni in questo post.
Statistiche mancanti o non aggiornate
Di tutte le ragioni per problemi di stima della cardinalità, questa è quella che speri da vedere, poiché spesso è più facile da affrontare. In questo scenario, le tue statistiche sono mancanti o non aggiornate. Potresti avere le opzioni del database per la creazione automatica di statistiche e gli aggiornamenti disabilitati, "nessun ricalcolo" abilitato per statistiche specifiche o avere tabelle sufficientemente grandi che gli aggiornamenti automatici delle statistiche semplicemente non si verificano abbastanza frequentemente.
Problemi di campionamento
È possibile che la precisione dell'istogramma delle statistiche sia inadeguata, ad esempio se si dispone di una tabella molto grande con distorsioni di dati significative e/o frequenti. Potrebbe essere necessario modificare il campionamento rispetto a quello predefinito o, se anche questo non aiuta, eseguire analisi utilizzando tabelle separate, statistiche filtrate o indici filtrati.
Correlazioni di colonne nascoste
Query Optimizer presuppone che le colonne all'interno della stessa tabella siano indipendenti. Ad esempio, se disponi di una colonna città e stato, potremmo intuitivamente sapere che queste due colonne sono correlate, ma SQL Server non lo comprende a meno che non lo aiutiamo con un indice multicolonna associato o con multicolonna creato manualmente statistiche di colonna. Senza aiutare l'ottimizzatore con la correlazione, la selettività dei tuoi predicati potrebbe essere esagerata.
Di seguito è riportato un esempio di due predicati correlati:
SELECT lastname, firstname FROM dbo.member WHERE city = 'Minneapolis' AND state_prov - 'MN';
Mi è capitato di sapere che il 10% delle nostre 10.000 righe member tabella si qualifica per questa combinazione, ma Query Optimizer ipotizza che sia l'1% delle 10.000 righe:
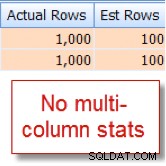
Ora confrontalo con la stima appropriata che vedo dopo aver aggiunto le statistiche su più colonne:
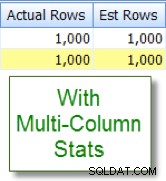
Confronti tra colonne all'interno della tabella
Possono verificarsi problemi di stima della cardinalità quando si confrontano le colonne all'interno della stessa tabella. Questo è un problema noto. In tal caso, puoi migliorare le stime della cardinalità dei confronti delle colonne utilizzando invece colonne calcolate o riscrivendo la query per utilizzare i join automatici o le espressioni di tabella comuni.
Utilizzo delle variabili della tabella
Usare molto le variabili di tabella? Le variabili di tabella mostrano una stima della cardinalità di "1", che per un numero limitato di righe potrebbe non rappresentare un problema, ma per set di risultati di grandi dimensioni o volatili può influire in modo significativo sulla qualità del piano di query. Di seguito è riportato uno screenshot della stima di un operatore di 1 riga rispetto alle 1.600.000 righe effettive da @charge variabile tabella:

Se questa è la tua causa principale, ti consigliamo di esplorare alternative come tabelle temporanee e/o tabelle di staging permanenti, ove possibile.
UDF scalari e MSTV
Simile alle variabili di tabella, le funzioni scalari e con valori di tabella a più istruzioni sono una scatola nera dal punto di vista della stima della cardinalità. Se riscontri problemi di qualità del piano a causa loro, considera le funzioni della tabella inline come un'alternativa, o addirittura estrai completamente il riferimento alla funzione e fai solo riferimento direttamente agli oggetti.
Di seguito viene mostrato un piano stimato rispetto a quello effettivo quando si utilizza una funzione con valori di tabella con più istruzioni:
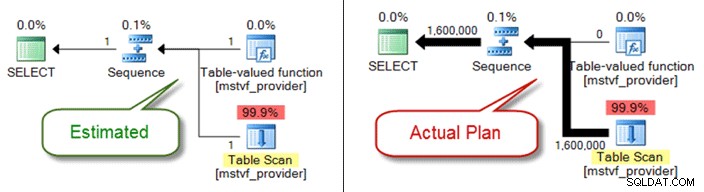
Problemi con il tipo di dati
I problemi impliciti del tipo di dati in combinazione con le condizioni di ricerca e unione possono causare problemi di stima della cardinalità. Possono anche consumare di nascosto risorse a livello di server (CPU, I/O, memoria), quindi è importante affrontarle quando possibile.
Predicati complessi
Probabilmente hai già visto questo modello prima:una query con un WHERE clausola che ha ogni riferimento di colonna della tabella racchiuso in varie funzioni, operazioni di concatenazione, operazioni matematiche e altro. E sebbene non tutte le funzioni di wrapping precludano stime di cardinalità corrette (come per LOWER , UPPER e GETDATE ) ci sono molti modi per seppellire il tuo predicato al punto che Query Optimizer non può più fare stime accurate.
Complessità delle query
Simili ai predicati sepolti, le tue domande sono straordinariamente complesse? Mi rendo conto che "complesso" è un termine soggettivo e la tua valutazione può variare, ma la maggior parte può concordare sul fatto che è probabile che nidificare viste all'interno di viste all'interno di viste che fanno riferimento a tabelle sovrapposte non sia ottimale, specialmente se accoppiato con oltre 10 join di tabelle, riferimenti a funzioni e predicati sepolti. Sebbene Query Optimizer svolga un lavoro ammirevole, non è magico e, se si dispone di disallineamenti significativi, la complessità della query (query con coltellino svizzero) può sicuramente rendere quasi impossibile ricavare stime di riga accurate per gli operatori.
Query distribuite
Stai utilizzando query distribuite con server collegati e noti problemi significativi nella stima della cardinalità? In tal caso, assicurati di controllare le autorizzazioni associate all'entità server collegata utilizzata per accedere ai dati. Senza il minimo db_ddladmin ruolo del database fisso per l'account del server collegato, questa mancanza di visibilità delle statistiche remote a causa di autorizzazioni insufficienti potrebbe essere l'origine dei problemi di stima della cardinalità.
E ce ne sono altri...
Ci sono altri motivi per cui le stime di cardinalità possono essere distorte, ma credo di aver coperto quelle più comuni. Il punto chiave è prestare attenzione agli sbalzi associati a query note e con scarse prestazioni. Non dare per scontato che il piano sia stato generato in base a condizioni di conteggio delle righe accurate. Se questi numeri sono distorti, devi prima provare a risolvere il problema.