Ci sono stati molti commenti dopo il mio post della scorsa settimana sulla divisione delle stringhe. Penso che il punto dell'articolo non fosse così ovvio come avrebbe potuto essere:che spendere un sacco di tempo e fatica cercando di "perfezionare" una funzione di divisione intrinsecamente lenta basata su T-SQL non sarebbe vantaggioso. Da allora ho raccolto la versione più recente della funzione di divisione delle stringhe di Jeff Moden e l'ho confrontata con le altre:
ALTER FUNCTION [dbo].[DelimitedSplitN4K]
(@pString NVARCHAR(4000), @pDelimiter NCHAR(1))
RETURNS TABLE WITH SCHEMABINDING AS
RETURN
WITH E1(N) AS (
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
cteTally(N) AS (SELECT TOP (ISNULL(DATALENGTH(@pString)/2,0))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E4),
cteStart(N1) AS (SELECT 1 UNION ALL
SELECT t.N+1 FROM cteTally t WHERE SUBSTRING(@pString,t.N,1) = @pDelimiter
),
cteLen(N1,L1) AS(SELECT s.N1,
ISNULL(NULLIF(CHARINDEX(@pDelimiter,@pString,s.N1),0)-s.N1,4000)
FROM cteStart s
)
SELECT ItemNumber = ROW_NUMBER() OVER(ORDER BY l.N1),
Item = SUBSTRING(@pString, l.N1, l.L1)
FROM cteLen l;
GO (Le uniche modifiche che ho apportato:l'ho formattato per la visualizzazione e ho rimosso i commenti. Puoi recuperare la fonte originale qui.)
Ho dovuto apportare un paio di modifiche ai miei test per rappresentare in modo equo la funzione di Jeff. Ancora più importante:ho dovuto scartare tutti i campioni che includevano stringhe> 4.000 caratteri. Quindi ho modificato le stringhe di 5.000 caratteri nella tabella dbo.strings in 4.000 caratteri e mi sono concentrato solo sui primi tre scenari non MAX (mantenendo i risultati precedenti per i primi due ed eseguendo nuovamente i terzi test per il nuovo lunghezze di stringa di 4.000 caratteri). Ho anche eliminato la tabella dei numeri da tutti i test tranne uno, perché era chiaro che le prestazioni erano sempre peggiori di un fattore di almeno 10. Il grafico seguente mostra le prestazioni delle funzioni in ciascuno dei quattro test, ancora una media di oltre 10 esecuzioni e sempre con una cache fredda e buffer puliti.
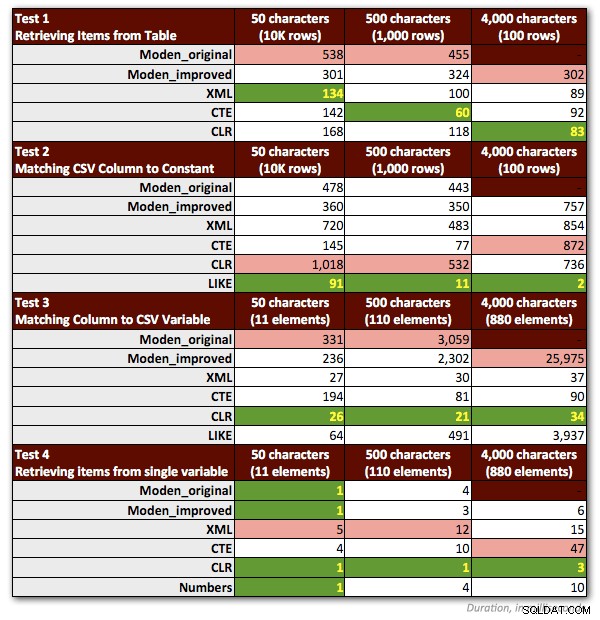
Quindi ecco i miei metodi preferiti leggermente rivisti, per ogni tipo di attività:
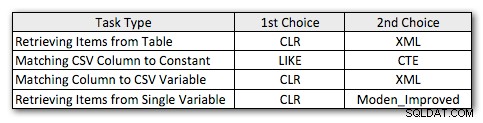
Noterai che CLR è rimasto il mio metodo preferito, tranne nel caso in cui la divisione non ha senso. E nei casi in cui CLR non è un'opzione, i metodi XML e CTE sono generalmente più efficienti, tranne nel caso della divisione di una singola variabile, dove la funzione di Jeff potrebbe benissimo essere l'opzione migliore. Ma dato che potrei aver bisogno di supportare più di 4.000 caratteri, la soluzione della tabella di Numbers potrebbe rientrare nel mio elenco in situazioni specifiche in cui non mi è consentito utilizzare CLR.
Prometto che il mio prossimo post sugli elenchi non parlerà affatto della divisione, tramite T-SQL o CLR, e dimostrerà come semplificare questo problema indipendentemente dal tipo di dati.
A parte questo, ho notato questo commento in una delle versioni delle funzioni di Jeff che è stata postata nei commenti:Ringrazio anche chi ha scritto il primo articolo che ho visto sulle “tabelle dei numeri” che si trova al seguente URL e ad Adam Machanic per avermelo condotto molti anni fa.https://web.archive.org/web/20150411042510/https://sqlserver2000.databases.aspfaq.com/why-should-i-consider-using-an -tabella-numeri-ausiliari.html
Quell'articolo è stato scritto da me nel 2004. Quindi, chiunque abbia aggiunto il commento alla funzione, è il benvenuto. :-)



