Uno scenario comune in molte applicazioni client-server consiste nel consentire all'utente finale di dettare l'ordinamento dei risultati. Alcune persone vogliono vedere prima gli articoli con il prezzo più basso, altri vogliono vedere prima gli articoli più recenti e alcuni vogliono vederli in ordine alfabetico. Questa è una cosa complessa da ottenere in Transact-SQL perché non puoi semplicemente dire:
CREATE PROCEDURE dbo.SortOnSomeTable @SortColumn NVARCHAR(128) = N'key_col', @SortDirection VARCHAR(4) = 'ASC' AS BEGIN ... ORDER BY @SortColumn; -- or ... ORDER BY @SortColumn @SortDirection; END GO
Questo perché T-SQL non consente variabili in queste posizioni. Se usi solo @SortColumn, ricevi:
Msg 1008, livello 16, stato 1, riga xL'elemento SELECT identificato dal numero ORDER BY 1 contiene una variabile come parte dell'espressione che identifica una posizione di colonna. Le variabili sono consentite solo quando si ordina in base a un'espressione che fa riferimento al nome di una colonna.
(E quando il messaggio di errore dice "un'espressione che fa riferimento al nome di una colonna", potresti trovarlo ambiguo e sono d'accordo. Ma posso assicurarti che questo non significa che una variabile sia un'espressione adatta.)
Se provi ad aggiungere @SortDirection, il messaggio di errore è un po' più opaco:
Msg 102, livello 15, stato 1, riga xSintassi errata vicino a '@SortDirection'.
Ci sono alcuni modi per aggirare questo problema e il tuo primo istinto potrebbe essere quello di utilizzare SQL dinamico o di introdurre l'espressione CASE. Ma come con la maggior parte delle cose, ci sono complicazioni che possono costringerti a percorrere una strada o l'altra. Quindi quale dovresti usare? Esaminiamo come potrebbero funzionare queste soluzioni e confrontiamo l'impatto sulle prestazioni di alcuni approcci diversi.
Dati di esempio
Usando una vista catalogo che probabilmente tutti comprendiamo abbastanza bene, sys.all_objects, ho creato la seguente tabella basata su un cross join, limitando la tabella a 100.000 righe (volevo dati che riempissero molte pagine ma non ci voleva molto tempo per interrogare e prova):
CREATE DATABASE OrderBy;
GO
USE OrderBy;
GO
SELECT TOP (100000)
key_col = ROW_NUMBER() OVER (ORDER BY s1.[object_id]), -- a BIGINT with clustered index
s1.[object_id], -- an INT without an index
name = s1.name -- an NVARCHAR with a supporting index
COLLATE SQL_Latin1_General_CP1_CI_AS,
type_desc = s1.type_desc -- an NVARCHAR(60) without an index
COLLATE SQL_Latin1_General_CP1_CI_AS,
s1.modify_date -- a datetime without an index
INTO dbo.sys_objects
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
ORDER BY s1.[object_id]; (Il trucco COLLATE è dovuto al fatto che molte viste del catalogo hanno colonne diverse con regole di confronto diverse e ciò garantisce che le due colonne corrispondano ai fini di questa demo.)
Quindi ho creato una tipica coppia di indici cluster / non cluster che potrebbe esistere su una tabella del genere, prima dell'ottimizzazione (non posso usare object_id per la chiave, perché il cross join crea duplicati):
CREATE UNIQUE CLUSTERED INDEX key_col ON dbo.sys_objects(key_col); CREATE INDEX name ON dbo.sys_objects(name);
Casi d'uso
Come accennato in precedenza, gli utenti potrebbero voler vedere questi dati ordinati in vari modi, quindi definiamo alcuni casi d'uso tipici che vogliamo supportare (e per supporto intendo dimostrare):
- Ordinato per key_col crescente ** predefinito se all'utente non interessa
- Ordinato per object_id (crescente/decrescente)
- Ordinato per nome (crescente/decrescente)
- Ordinato per type_desc (crescente/decrescente)
- Ordinato per modify_date (crescente/decrescente)
Lasceremo l'ordine key_col come predefinito perché dovrebbe essere il più efficiente se l'utente non ha una preferenza; poiché key_col è un surrogato arbitrario che non dovrebbe significare nulla per l'utente (e potrebbe non essere nemmeno esposto ad esso), non c'è motivo per consentire l'ordinamento inverso su quella colonna.
Approcci che non funzionano
L'approccio più comune che vedo quando qualcuno inizia ad affrontare questo problema è l'introduzione della logica di controllo del flusso nella query. Si aspettano di poterlo fare:
SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY
IF @SortColumn = 'key_col'
key_col
IF @SortColumn = 'object_id'
[object_id]
IF @SortColumn = 'name'
name
...
IF @SortDirection = 'ASC'
ASC
ELSE
DESC; Questo ovviamente non funziona. Quindi vedo che CASE viene introdotto in modo errato, usando una sintassi simile:
SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY CASE @SortColumn
WHEN 'key_col' THEN key_col
WHEN 'object_id' THEN [object_id]
WHEN 'name' THEN name
...
END CASE @SortDirection WHEN 'ASC' THEN ASC ELSE DESC END; Questo è più vicino, ma fallisce per due motivi. Uno è che CASE è un'espressione che restituisce esattamente un valore di un tipo di dati specifico; questo unisce i tipi di dati che sono incompatibili e quindi interromperà l'espressione CASE. L'altro è che non c'è modo di applicare condizionalmente la direzione di ordinamento in questo modo senza utilizzare SQL dinamico.
Approcci che funzionano
I tre approcci principali che ho visto sono i seguenti:
Raggruppa i tipi e le indicazioni compatibili
Per utilizzare CASE con ORDER BY, deve esserci un'espressione distinta per ogni combinazione di tipi e direzioni compatibili. In questo caso dovremmo usare qualcosa del genere:
CREATE PROCEDURE dbo.Sort_CaseExpanded
@SortColumn NVARCHAR(128) = N'key_col',
@SortDirection VARCHAR(4) = 'ASC'
AS
BEGIN
SET NOCOUNT ON;
SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY
CASE WHEN @SortDirection = 'ASC' THEN
CASE @SortColumn
WHEN 'key_col' THEN key_col
WHEN 'object_id' THEN [object_id]
END
END,
CASE WHEN @SortDirection = 'DESC' THEN
CASE @SortColumn
WHEN 'key_col' THEN key_col
WHEN 'object_id' THEN [object_id]
END
END DESC,
CASE WHEN @SortDirection = 'ASC' THEN
CASE @SortColumn
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
END
END,
CASE WHEN @SortDirection = 'DESC' THEN
CASE @SortColumn
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
END
END DESC,
CASE WHEN @SortColumn = 'modify_date'
AND @SortDirection = 'ASC' THEN modify_date
END,
CASE WHEN @SortColumn = 'modify_date'
AND @SortDirection = 'DESC' THEN modify_date
END DESC;
END Potresti dire, wow, è un brutto pezzo di codice e sarei d'accordo con te. Penso che questo sia il motivo per cui molte persone memorizzano nella cache i propri dati sul front-end e lasciano che il livello di presentazione si occupi di destreggiarsi in ordini diversi. :-)
Puoi ridurre ulteriormente questa logica convertendo tutti i tipi non stringa in stringhe che verranno ordinate correttamente, ad es.
CREATE PROCEDURE dbo.Sort_CaseCollapsed
@SortColumn NVARCHAR(128) = N'key_col',
@SortDirection VARCHAR(4) = 'ASC'
AS
BEGIN
SET NOCOUNT ON;
SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY
CASE WHEN @SortDirection = 'ASC' THEN
CASE @SortColumn
WHEN 'key_col' THEN RIGHT('000000000000' + RTRIM(key_col), 12)
WHEN 'object_id' THEN
RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0')
+ REPLICATE('0', 23) + RTRIM([object_id]), 24)
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
WHEN 'modify_date' THEN CONVERT(CHAR(19), modify_date, 120)
END
END,
CASE WHEN @SortDirection = 'DESC' THEN
CASE @SortColumn
WHEN 'key_col' THEN RIGHT('000000000000' + RTRIM(key_col), 12)
WHEN 'object_id' THEN
RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0')
+ REPLICATE('0', 23) + RTRIM([object_id]), 24)
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
WHEN 'modify_date' THEN CONVERT(CHAR(19), modify_date, 120)
END
END DESC;
END Tuttavia, è un pasticcio piuttosto brutto e devi ripetere le espressioni due volte per affrontare le diverse direzioni di ordinamento. Sospetterei anche che l'utilizzo di OPTION RECOMPILE su quella query impedirebbe di essere punto dallo sniffing dei parametri. Tranne nel caso predefinito, non è che la maggior parte del lavoro svolto qui sarà una compilazione.
Applica un grado usando le funzioni della finestra
Ho scoperto questo trucco accurato da AndriyM, anche se è molto utile nei casi in cui tutte le potenziali colonne di ordinamento sono di tipi compatibili, altrimenti l'espressione usata per ROW_NUMBER() è ugualmente complessa. La parte più intelligente è che per passare dall'ordine crescente a quello decrescente, moltiplichiamo semplicemente ROW_NUMBER() per 1 o -1. Possiamo applicarlo in questa situazione come segue:
CREATE PROCEDURE dbo.Sort_RowNumber
@SortColumn NVARCHAR(128) = N'key_col',
@SortDirection VARCHAR(4) = 'ASC'
AS
BEGIN
SET NOCOUNT ON;
;WITH x AS
(
SELECT key_col, [object_id], name, type_desc, modify_date,
rn = ROW_NUMBER() OVER (
ORDER BY CASE @SortColumn
WHEN 'key_col' THEN RIGHT('000000000000' + RTRIM(key_col), 12)
WHEN 'object_id' THEN
RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0')
+ REPLICATE('0', 23) + RTRIM([object_id]), 24)
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
WHEN 'modify_date' THEN CONVERT(CHAR(19), modify_date, 120)
END
) * CASE @SortDirection WHEN 'ASC' THEN 1 ELSE -1 END
FROM dbo.sys_objects
)
SELECT key_col, [object_id], name, type_desc, modify_date
FROM x
ORDER BY rn;
END
GO Anche in questo caso, OPTION RECOMPILE può aiutare qui. Inoltre, potresti notare in alcuni di questi casi che i legami sono gestiti in modo diverso dai vari piani:quando ordini per nome, ad esempio, di solito vedrai key_col passare in ordine crescente all'interno di ogni serie di nomi duplicati, ma potresti anche vedere i valori si sono confusi. Per fornire un comportamento più prevedibile in caso di parità, puoi sempre aggiungere una clausola ORDER BY aggiuntiva. Nota che se dovessi aggiungere key_col al primo esempio, dovrai renderlo un'espressione in modo che key_col non sia elencato due volte in ORDER BY (puoi farlo usando key_col + 0, per esempio).
SQL dinamico
Molte persone hanno delle riserve sull'SQL dinamico:è impossibile da leggere, è un terreno fertile per l'iniezione di SQL, porta a pianificare il rigonfiamento della cache, vanifica lo scopo dell'utilizzo delle procedure archiviate... Alcuni di questi sono semplicemente falsi e alcuni di essi sono facili da mitigare. Ho aggiunto qui alcune convalide che potrebbero essere facilmente aggiunte a qualsiasi delle procedure precedenti:
CREATE PROCEDURE dbo.Sort_DynamicSQL
@SortColumn NVARCHAR(128) = N'key_col',
@SortDirection VARCHAR(4) = 'ASC'
AS
BEGIN
SET NOCOUNT ON;
-- reject any invalid sort directions:
IF UPPER(@SortDirection) NOT IN ('ASC','DESC')
BEGIN
RAISERROR('Invalid parameter for @SortDirection: %s', 11, 1, @SortDirection);
RETURN -1;
END
-- reject any unexpected column names:
IF LOWER(@SortColumn) NOT IN (N'key_col', N'object_id', N'name', N'type_desc', N'modify_date')
BEGIN
RAISERROR('Invalid parameter for @SortColumn: %s', 11, 1, @SortColumn);
RETURN -1;
END
SET @SortColumn = QUOTENAME(@SortColumn);
DECLARE @sql NVARCHAR(MAX);
SET @sql = N'SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY ' + @SortColumn + ' ' + @SortDirection + ';';
EXEC sp_executesql @sql;
END Confronti delle prestazioni
Ho creato una stored procedure wrapper per ciascuna procedura precedente, in modo da poter testare facilmente tutti gli scenari. Le quattro procedure wrapper si presentano così, con il nome della procedura che varia ovviamente:
CREATE PROCEDURE dbo.Test_Sort_CaseExpanded AS BEGIN SET NOCOUNT ON; EXEC dbo.Sort_CaseExpanded; -- default EXEC dbo.Sort_CaseExpanded N'name', 'ASC'; EXEC dbo.Sort_CaseExpanded N'name', 'DESC'; EXEC dbo.Sort_CaseExpanded N'object_id', 'ASC'; EXEC dbo.Sort_CaseExpanded N'object_id', 'DESC'; EXEC dbo.Sort_CaseExpanded N'type_desc', 'ASC'; EXEC dbo.Sort_CaseExpanded N'type_desc', 'DESC'; EXEC dbo.Sort_CaseExpanded N'modify_date', 'ASC'; EXEC dbo.Sort_CaseExpanded N'modify_date', 'DESC'; END
E quindi, utilizzando SQL Sentry Plan Explorer, ho generato piani di esecuzione effettivi (e le metriche a corredo) con le seguenti query e ripetuto il processo 10 volte per sommare la durata totale:
DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; EXEC dbo.Test_Sort_CaseExpanded; --EXEC dbo.Test_Sort_CaseCollapsed; --EXEC dbo.Test_Sort_RowNumber; --EXEC dbo.Test_Sort_DynamicSQL; GO 10
Ho anche testato i primi tre casi con OPTION RECOMPILE (non ha molto senso per il caso SQL dinamico, poiché sappiamo che sarà ogni volta un nuovo piano) e tutti e quattro i casi con MAXDOP 1 per eliminare l'interferenza del parallelismo. Ecco i risultati:
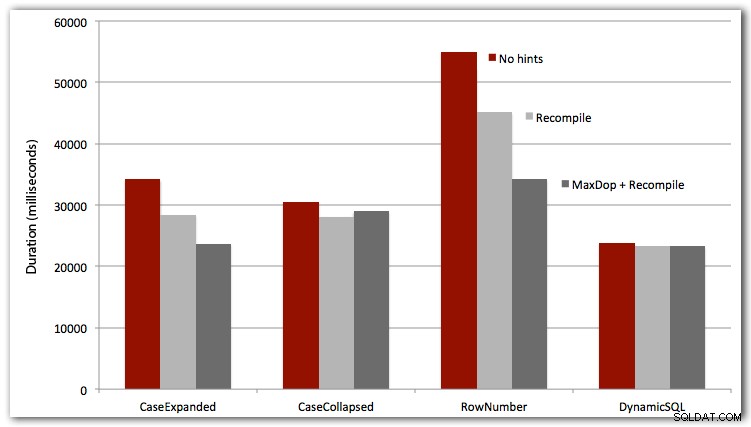
Conclusione
Per prestazioni definitive, SQL dinamico vince ogni volta (sebbene solo con un piccolo margine su questo set di dati). L'approccio ROW_NUMBER(), sebbene intelligente, è stato il perdente in ogni test (scusa AndriyM).
Diventa ancora più divertente quando vuoi introdurre una clausola WHERE, non importa il paging. Questi tre sono come la tempesta perfetta per introdurre complessità in ciò che inizia come una semplice query di ricerca. Più permutazioni ha la tua query, più è probabile che tu voglia eliminare la leggibilità dalla finestra e utilizzare SQL dinamico in combinazione con l'impostazione "ottimizza per carichi di lavoro ad hoc" per ridurre al minimo l'impatto dei piani monouso nella cache dei piani.