Il modello relazionale di gestione dei dati è stato sviluppato per la prima volta dal Dr. Edgar F. Codd nel 1969. I moderni sistemi di gestione dei database relazionali (RDBMS) sono allineati con il paradigma. La struttura chiave identificata con RDBMS è la struttura logica denominata “tabella”. Le tabelle sono composte principalmente da righe e colonne (chiamate anche record e attributi o tuple e campi). In senso stretto matematico, il termine tabella viene in realtà indicata come relazione e rappresenta il termine “Modello Relazionale”. In matematica, una relazione è una rappresentazione di un insieme.
L'attributo expression fornisce una buona descrizione dello scopo di una colonna:caratterizza l'insieme di righe ad essa associate. Ogni colonna deve essere di un particolare tipo di dati e ogni riga deve avere delle caratteristiche identificative univoche denominate “chiavi”. La modifica dei dati è in genere più efficiente se eseguita utilizzando il modello relazionale, mentre il recupero dei dati potrebbe essere più rapido con il modello gerarchico precedente che è stato ridefinito nei sistemi NoSQL modello.
La normalizzazione dei dati è un processo matematico di modellazione dei dati aziendali in una forma che garantisce che ogni entità sia rappresentata da una singola relazione (tabella). I primi sostenitori del modello relazionale proposero un concetto di Forme Normali. Edgar Codd ha definito la prima, la seconda e la terza forma normale. È stato poi raggiunto da Raymond F. Boyce. Insieme hanno definito la forma normale Boyce-Codd. A questo punto, sei Forme Normali sono definite in teoria, ma nella maggior parte delle applicazioni pratiche, in genere estendiamo la Normalizzazione fino alla Terza Forma Normale. Ciascun modulo normale si impegna a evitare anomalie durante la modifica dei dati, ridurre la ridondanza e la dipendenza dei dati all'interno di una tabella. Ogni livello di normalizzazione tende a introdurre più tabelle, ridurre la ridondanza, aumentare la semplicità di ogni tabella ma aumenta anche la complessità dell'intero sistema di gestione del database relazionale. Quindi, strutturalmente i sistemi RDBM tendono ad essere più complessi dei sistemi gerarchici.
Perché la normalizzazione del database:quattro anomalie
L'archiviazione dei dati senza normalizzazione causa una serie di problemi con il consumo dei dati. I fautori della normalizzazione chiamavano tali problemi anomalie. Per descrivere queste anomalie, osserviamo i dati presentati in Fig. 1.

Fig. 1 Tavolo Staff
Elenco 1. Tabella di base per dimostrare la normalizzazione del database.
1.1. Crea tabella
use privatework go create table staffers ( staffID int identity (1,1) ,StaffName varchar(50) ,Role varchar(50) ,Department varchar (100) ,Manager varchar (50) ,Gender char(1) ,DateofBirth datetime2 )
1.2. Inserisci righe
insert into staffers values ('John Doe','Engineering','Kweku Amarh','M','06-Oct-1965');
insert into staffers values ('Henry Ofori','Engineering','Kweku Amarh','M','06-Mar-1982');
insert into staffers values ('Jessica Yuiah','Engineering','Kweku Amarh','F','06-Oct-1965');
insert into staffers values ('Ahmed Assah','Engineering','Kweku Amarh','M','06-Oct-1965'); 1.3. Interroga la tabella
select * from staffers;
Questa tabella rappresenta essenzialmente due insiemi di dati che sono stati combinati inavvertitamente:nomi del personale e dipartimenti. Si noti che tutto il personale proviene dallo stesso dipartimento:Ingegneria. Ciò è stato fatto per semplicità e per dimostrare la normalizzazione. Ci sono tre problemi principali associati alla manipolazione di questa struttura:
L'anomalia di inserimento
Per inserire un nuovo record, dobbiamo continuare a ripetere i nomi dei dipartimenti e dei manager.
L'anomalia della cancellazione
Per eliminare il record di un membro dello staff, dobbiamo eliminare anche il manager e il dipartimento associati. Se è necessario rimuovere TUTTI i record del personale, dobbiamo rimuovere anche tutti i reparti e tutti i manager.
L'anomalia dell'aggiornamento
Se è necessario cambiare il manager di un dipartimento, dobbiamo apportare la modifica in ogni singola riga di questa tabella poiché i valori sono duplicati per ogni membro dello staff.
Forme normali del database
Nelle sezioni seguenti dell'articolo, cercheremo di descrivere la 1a, la 2a e la 3a forma normale che è molto più probabile che siano osservate nei sistemi RDBM reali. Ci sono altre estensioni della teoria come la quarta, la quinta e la forma normale di Boyce-Codd, ma in questo articolo ci limiteremo alle tre forme normali.
La prima forma normale
La prima forma normale è definita da quattro regole:
Ogni colonna deve contenere valori dello stesso tipo di dati.
La tabella Staffers soddisfa già questa regola.
Ogni colonna di una tabella deve essere atomica.
Ciò significa essenzialmente che dovresti dividere il contenuto di una colonna fino a quando non possono più essere divisi. Si noti che il Ruolo nella colonna Staff la tabella infrange la regola 2 per la riga con StaffID=3.
Ogni riga di una tabella deve essere univoca.
L'unicità nelle tabelle normalizzate si ottiene in genere utilizzando le chiavi primarie. Una chiave primaria definisce in modo univoco ogni riga in una tabella. La maggior parte delle volte una chiave primaria è definita da una sola colonna. Una chiave primaria composta da più di una colonna è chiamata chiave composita.
L'ordine in cui vengono archiviati i record non ha importanza.
Per allineare i dati negli Staff tabella con i principi della prima forma normale dobbiamo dividere la tabella come mostrato nelle figure 2, 3 e 4.
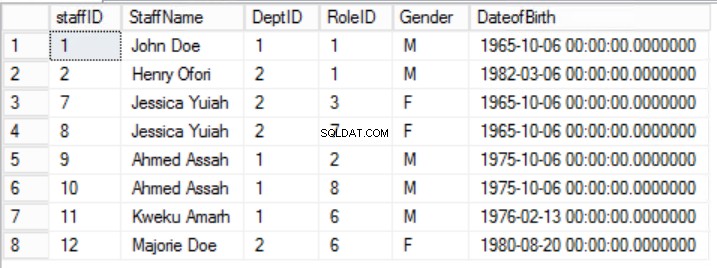
Fig. 2 Tavolo del personale
Abbiamo ristretto i dati negli Staff tabella e implementato una chiave primaria composita per garantire l'unicità. Abbiamo anche creato due tabelle aggiuntive Ruoli e Dipartimenti che hanno rapporti con i principali Staff tabella implementata utilizzando chiavi esterne. Esamina il DDL nel Listato 2.
Listato 2. DDL dei nuovi Staff Tabella per la prima forma normale.
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID] [int] NOT NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC, [RoleID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([RoleID]) REFERENCES [dbo].[Roles] ([RoleID]) GO
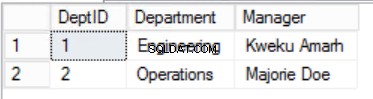
Fig. Tabella 3 Dipartimenti
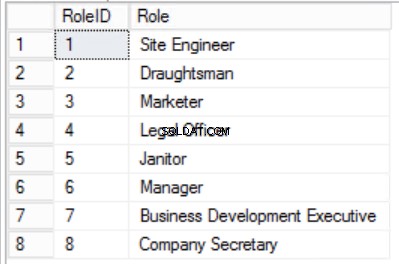
Fig. Tabella a 4 ruoli
La seconda forma normale
Il 1° modulo normale deve essere già attivo.
Ogni colonna non chiave non deve avere una dipendenza parziale dalla chiave primaria.
Lo scopo della seconda regola è che tutte le colonne della tabella devono dipendere da tutte le colonne che compongono la chiave primaria insieme. Guardando indietro alle tabelle nelle Figure 2, 3 e 4, scopriamo di aver raggiunto tutti i requisiti della Prima Forma Normale. Abbiamo anche raggiunto i requisiti della Second Normal Form per due tabelle Ruoli e Dipartimenti . Tuttavia, nel caso degli Staff tavolo, abbiamo ancora un problema. La nostra chiave primaria è composta dalle colonne StaffID e RoleID.
La regola 2 della seconda forma normale è violata dal fatto che il sesso e la data di nascita del personale non dipendono dal RoleID. Esiste una dipendenza parziale.
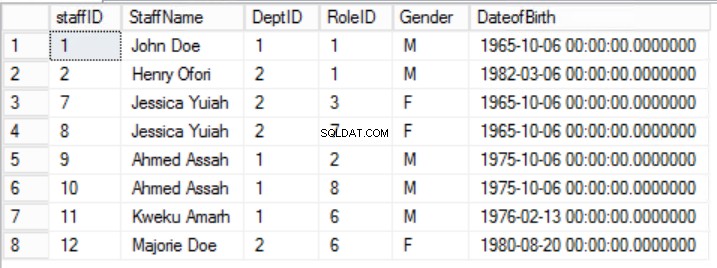
Fig. 5 Staff per la prima forma normale
Nell'esempio fornito, possiamo provare a risolvere questo problema rimuovendo RoleID dalla chiave primaria, ma se lo facciamo infrangiamo un'altra regola:il ruolo dell'unicità dichiarato nella prima forma normale. Dobbiamo adottare un altro approccio. Modificheremo gli Staff tavolo con la consapevolezza che un membro dello staff può svolgere più di un ruolo. Vedi Fig. 6.
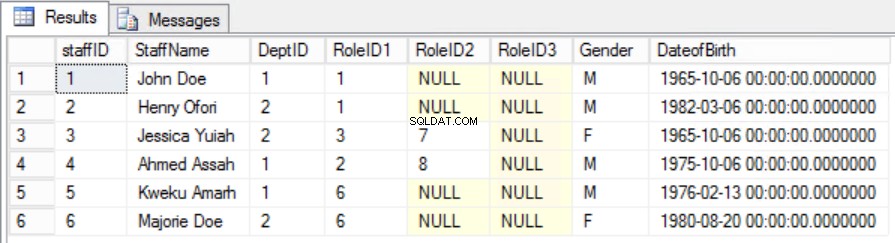
Fig. 6 Tavola del personale per la seconda forma normale
Siamo riusciti a mantenere l'unicità ea rimuovere la dipendenza parziale.
Listato 3. Tabella DDL di New Staffers per la seconda forma normale.
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers2NF]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID1] [int] NOT NULL, [RoleID2] [int] NULL, [RoleID3] [int] NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID1]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID2]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID3]) REFERENCES [dbo].[Roles] ([RoleID]) GO
La terza forma normale
Il 2° modulo normale deve essere già attivo.
Ogni colonna non chiave non deve avere una dipendenza transitiva dalla chiave primaria.
Il punto centrale della terza forma normale è che non devono esserci colonne che dipendono da colonne non chiave anche se quelle colonne non chiave dipendono già dalla chiave primaria.
Ad esempio, supponiamo di aver deciso di aggiungere una colonna aggiuntiva al Staff tabella come mostrato in Fig. 7 per vedere chiaramente il manager del personale. In questo modo avremmo infranto la seconda regola Third Normal Form, perché il Manager Name dipende dal DeptID e il DeptID, a sua volta, dipende dallo StaffID. Questa è una dipendenza transitiva.
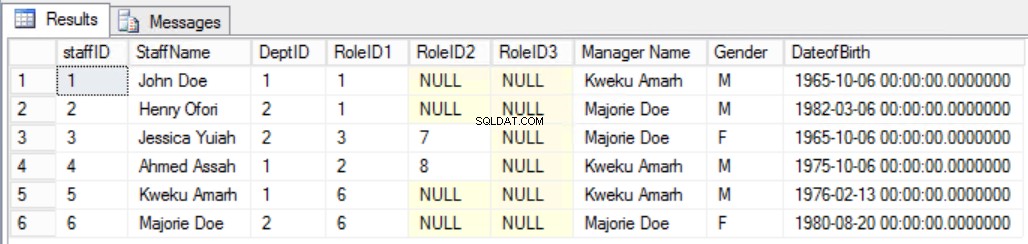
Fig. 7 Tabella degli Staff per la Terza Forma Normale (Regola Rotta)
Sarebbe meglio conservare il vecchio modulo e visualizzare le informazioni richieste utilizzando un join tra la tabella Staffers e la tabella Department.
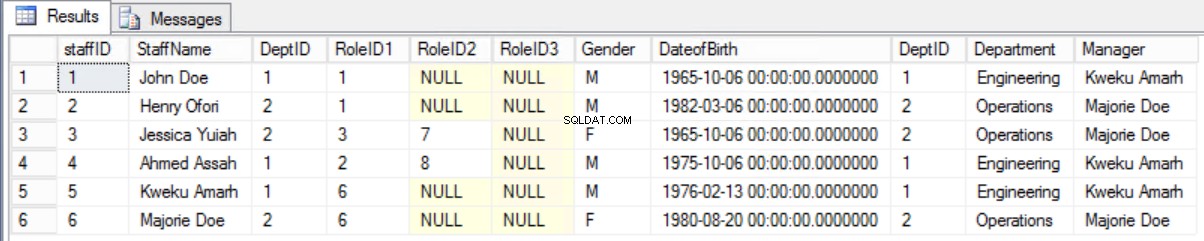
Fig. 8 Unisciti tra staff e reparto
Elenco 4. Interroga per visualizzare personale e manager.
select * from staffers2NF s join Department d on s.DeptID=d.DeptID;
Applicazione pratica
La maggior parte delle applicazioni mature implementa le regole di normalizzazione in misura ragionevole. Vediamo che l'implementazione della normalizzazione dei dati dà origine all'uso di vincoli di chiave primaria e vincoli di chiave esterna. Inoltre, mentre approfondiamo l'argomento, emergono anche problemi come l'indicizzazione delle chiavi esterne. In precedenza abbiamo menzionato come la mancanza di normalizzazione può influire sulla manipolazione regolare dei dati come descritto nelle Anomalie di inserimento, eliminazione e aggiornamento. Una mancanza di una corretta normalizzazione può anche influire indirettamente sulle prestazioni delle query.
Recentemente mi sono imbattuto in una tabella che aveva la forma mostrata nella tabella 1 che chiameremo Customer_Accounts.
S/No | Nome | Account_No | Numero_telefono |
1 | Kenneth Igiri | 9922344592 | 2348039988456, 2348039988456, 2348039988456 |
2 | Ernest Doe | 6677554897 | 2348022887546, 2348039988456 |
Tabella 1 Account_clienti
Il problema principale con questa tabella è che infrange la seconda regola della prima forma normale. Il risultato nel nostro caso è stato che la ricerca di clienti in base ai loro numeri di telefono richiedeva l'uso di un LIKE nella clausola WHERE e un %.
Select account_no from Customer_Accounts where Phone_No like ‘%2348039988456%’;
L'impatto del costrutto sopra è stato che l'ottimizzatore non ha mai utilizzato un indice, il che rappresentava un enorme problema di prestazioni.
Conclusione
La normalizzazione dei dati risiede nel regno della progettazione di database e sia gli sviluppatori che i DBA dovrebbero prestare attenzione alle regole delineate in questo articolo. È sempre meglio eseguire la normalizzazione prima che il database entri in produzione. I vantaggi di un sistema di gestione di database relazionali adeguatamente progettato valgono semplicemente lo sforzo.