Al PASS Summit di alcune settimane fa, Microsoft ha rilasciato CTP2.1 di SQL Server 2019 e uno dei grandi miglioramenti delle funzionalità inclusi nel CTP è Scalar UDF Inlining. Prima di questa versione volevo giocare con la differenza di prestazioni tra l'inlining di UDF scalari e l'esecuzione RBAR (row-by-agonizing-row) di UDF scalari nelle versioni precedenti di SQL Server e mi sono imbattuto in un'opzione di sintassi per il CREA FUNZIONE dichiarazione nella documentazione in linea di SQL Server che non avevo mai visto prima.
Il DDL per CREA FUNZIONE supporta una clausola WITH per le opzioni delle funzioni e durante la lettura della documentazione in linea ho notato che la sintassi includeva quanto segue:
-- Transact-SQL Function Clauses
<function_option>::=
{
[ ENCRYPTION ]
| [ SCHEMABINDING ]
| [ RETURNS NULL ON NULL INPUT | CALLED ON NULL INPUT ]
| [ EXECUTE_AS_Clause ]
} Ero davvero curioso di sapere RETURNS NULL ON NULL INPUT opzione della funzione, quindi ho deciso di fare alcuni test. Sono stato molto sorpreso di scoprire che in realtà è una forma di ottimizzazione UDF scalare presente nel prodotto almeno da SQL Server 2008 R2.
Si scopre che se si sa che una UDF scalare restituirà sempre un risultato NULL quando viene fornito un input NULL, l'UDF dovrebbe SEMPRE essere creata con RETURNS NULL ON NULL INPUT opzione, perché quindi SQL Server non esegue nemmeno la definizione della funzione per tutte le righe in cui l'input è NULL, cortocircuitandolo in effetti ed evitando l'esecuzione sprecata del corpo della funzione.
Per mostrarti questo comportamento, utilizzerò un'istanza di SQL Server 2017 con l'ultimo aggiornamento cumulativo applicato e AdventureWorks2017 database da GitHub (puoi scaricarlo da qui) che viene fornito con un dbo.ufnLeadingZeros funzione che aggiunge semplicemente zeri iniziali al valore di input e restituisce una stringa di otto caratteri che include quegli zeri iniziali. Creerò una nuova versione di quella funzione che include RETURNS NULL ON NULL INPUT opzione in modo da poterlo confrontare con la funzione originale per le prestazioni di esecuzione.
USE [AdventureWorks2017];
GO
CREATE FUNCTION [dbo].[ufnLeadingZeros_new](
@Value int
)
RETURNS varchar(8)
WITH SCHEMABINDING, RETURNS NULL ON NULL INPUT
AS
BEGIN
DECLARE @ReturnValue varchar(8);
SET @ReturnValue = CONVERT(varchar(8), @Value);
SET @ReturnValue = REPLICATE('0', 8 - DATALENGTH(@ReturnValue)) + @ReturnValue;
RETURN (@ReturnValue);
END;
GO Allo scopo di testare le differenze di prestazioni di esecuzione all'interno del motore di database delle due funzioni, ho deciso di creare una sessione di eventi estesi sul server per tenere traccia di sqlserver.module_end evento, che si attiva alla fine di ogni esecuzione dell'UDF scalare per ogni riga. Questo mi ha permesso di dimostrare la semantica dell'elaborazione riga per riga e anche di tenere traccia di quante volte la funzione è stata effettivamente invocata durante il test. Ho deciso di raccogliere anche sql_batch_completed e sql_statement_completed eventi e filtra tutto per id_sessione per assicurarmi che stavo solo acquisendo informazioni relative alla sessione su cui stavo effettivamente eseguendo i test (se vuoi replicare questi risultati, dovrai cambiare il 74 in tutti i punti nel codice seguente con qualsiasi ID sessione il tuo test il codice verrà eseguito). La sessione dell'evento utilizza TRACK_CAUSALITY in modo che sia facile contare quante esecuzioni della funzione sono avvenute tramite activity_id.seq_no valore per gli eventi (che aumenta di uno per ogni evento che soddisfa il id_sessione filtro).
CREATE EVENT SESSION [Session72] ON SERVER ADD EVENT sqlserver.module_end( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_batch_completed( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_batch_starting( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_statement_completed( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_statement_starting( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))) WITH (TRACK_CAUSALITY=ON) GO
Dopo aver avviato la sessione dell'evento e aperto il Visualizzatore dati live in Management Studio, ho eseguito due query; uno che utilizza la versione originale della funzione per inserire gli zeri in CurrencyRateID nella colonna Sales.SalesOrderHeader tabella e la nuova funzione per produrre l'output identico ma utilizzando RETURNS NULL ON NULL INPUT opzione e ho acquisito le informazioni sul piano di esecuzione effettivo per il confronto.
SELECT SalesOrderID, dbo.ufnLeadingZeros(CurrencyRateID) FROM Sales.SalesOrderHeader; GO SELECT SalesOrderID, dbo.ufnLeadingZeros_new(CurrencyRateID) FROM Sales.SalesOrderHeader; GO
La revisione dei dati sugli eventi estesi ha mostrato un paio di cose interessanti. Innanzitutto, la funzione originale è stata eseguita 31.465 volte (dal conteggio di module_end events) e il tempo CPU totale per sql_statement_completed l'evento è stato di 204 ms con 482 ms di durata.
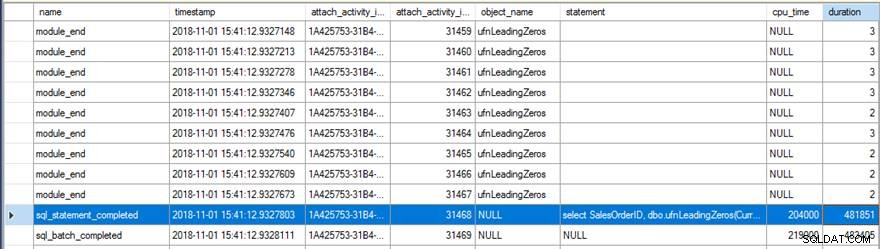
La nuova versione con RETURNS NULL ON NULL INPUT l'opzione specificata è stata eseguita solo 13.976 volte (di nuovo, dal conteggio di module_end events) e il tempo della CPU per sql_statement_completed l'evento è stato di 78 ms con 359 ms di durata.

L'ho trovato interessante, quindi per verificare i conteggi di esecuzione ho eseguito la seguente query per contare NON NULL righe valore, righe valore NULL e righe totali in Sales.SalesOrderHeader tabella.
SELECT SUM(CASE WHEN CurrencyRateID IS NOT NULL THEN 1 ELSE 0 END) AS NOTNULL, SUM(CASE WHEN CurrencyRateID IS NULL THEN 1 ELSE 0 END) AS NULLVALUE, COUNT(*) FROM Sales.SalesOrderHeader;
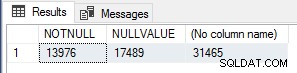
Questi numeri corrispondono esattamente al numero di module_end eventi per ciascuno dei test, quindi questa è sicuramente un'ottimizzazione delle prestazioni molto semplice per UDF scalari che dovrebbe essere utilizzata se si sa che il risultato della funzione sarà NULL se i valori di input sono NULL, per cortocircuitare/bypassare l'esecuzione della funzione interamente per quelle righe.
Le informazioni su QueryTimeStats nei piani di esecuzione effettivi riflettevano anche i guadagni in termini di prestazioni:
<QueryTimeStats CpuTime="204" ElapsedTime="482" UdfCpuTime="160" UdfElapsedTime="218" /> <QueryTimeStats CpuTime="78" ElapsedTime="359" UdfCpuTime="52" UdfElapsedTime="64" />
Questa è una riduzione piuttosto significativa del solo tempo della CPU, che può essere un punto dolente significativo per alcuni sistemi.
L'utilizzo di UDF scalari è un noto anti-pattern di progettazione per le prestazioni e sono disponibili una varietà di metodi per riscrivere il codice per evitarne l'uso e le prestazioni. Ma se sono già presenti e non possono essere facilmente modificati o rimossi, è sufficiente ricreare l'UDF con RETURNS NULL ON NULL INPUT L'opzione potrebbe essere un modo molto semplice per migliorare le prestazioni se sono presenti molti input NULL nel set di dati in cui viene utilizzato l'UDF.