Quando sei profondamente coinvolto nella risoluzione di un problema in SQL Server, a volte ti ritrovi a voler conoscere l'ordine esatto in cui sono state eseguite le query. Lo vedo con stored procedure più complicate che contengono livelli di logica o in scenari in cui c'è molto codice ridondante. Gli eventi estesi sono una scelta naturale in questo caso, poiché in genere vengono utilizzati per acquisire informazioni sull'esecuzione delle query. Spesso puoi usare session_id e il timestamp per capire l'ordine degli eventi, ma c'è un'opzione di sessione per XE che è ancora più affidabile:Traccia causalità.
Quando si abilita Traccia causalità per una sessione, viene aggiunto un GUID e un numero di sequenza a ogni evento, che è quindi possibile utilizzare per scorrere l'ordine in cui si sono verificati gli eventi. Il sovraccarico è minimo e può essere un notevole risparmio di tempo in molti scenari di risoluzione dei problemi.
Configura
Utilizzando il database WideWorldImporters creeremo una procedura memorizzata da utilizzare:
DROP PROCEDURE IF EXISTS [Sales].[usp_CustomerTransactionInfo]; GO CREATE PROCEDURE [Sales].[usp_CustomerTransactionInfo] @CustomerID INT AS SELECT [CustomerID], SUM([AmountExcludingTax]) FROM [Sales].[CustomerTransactions] WHERE [CustomerID] = @CustomerID GROUP BY [CustomerID]; SELECT COUNT([OrderID]) FROM [Sales].[Orders] WHERE [CustomerID] = @CustomerID GO
Quindi creeremo una sessione evento:
CREATE EVENT SESSION [TrackQueries] ON SERVER
ADD EVENT sqlserver.sp_statement_completed(
WHERE ([sqlserver].[is_system]=(0))),
ADD EVENT sqlserver.sql_statement_completed(
WHERE ([sqlserver].[is_system]=(0)))
ADD TARGET package0.event_file
(
SET filename=N'C:\temp\TrackQueries',max_file_size=(256)
)
WITH
(
MAX_MEMORY = 4096 KB,
EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY = 30 SECONDS,
MAX_EVENT_SIZE = 0 KB,
MEMORY_PARTITION_MODE = NONE,
TRACK_CAUSALITY = ON,
STARTUP_STATE = OFF
); Inoltre, eseguiremo query ad hoc, quindi acquisiremo sia sp_statement_completed (istruzioni completate all'interno di una procedura memorizzata) sia sql_statement_completed (istruzioni completate che non sono all'interno di una procedura memorizzata). Si noti che l'opzione TRACK_CAUSALITY per la sessione è impostata su ON. Anche in questo caso, questa impostazione è specifica per la sessione dell'evento e deve essere abilitata prima di avviarla. Non puoi abilitare l'impostazione al volo, ad esempio puoi aggiungere o rimuovere eventi e destinazioni mentre la sessione è in esecuzione.
Per avviare la sessione dell'evento tramite l'interfaccia utente, fai clic con il pulsante destro del mouse su di essa e seleziona Avvia sessione.
Test
All'interno di Management Studio eseguiremo il seguente codice:
EXEC [Sales].[usp_CustomerTransactionInfo] 490;
SELECT [c].[CustomerID], [c].[CustomerName], [p].[FullName], [o].[OrderID]
FROM [Application].[People] [p]
JOIN [Sales].[Customers] [c] ON [p].[PersonID] = [c].[PrimaryContactPersonID]
JOIN [Sales].[Orders] [o] ON [c].[CustomerID] = [o].[CustomerID]
WHERE [p].[FullName] = 'Naseem Radan'; Ecco il nostro output XE:

Si noti che la prima query eseguita, che è evidenziata, è SELECT @@SPID e ha un GUID di FDCCB1CF-CA55-48AA-8FBA-7F5EBF870674. Non abbiamo eseguito questa query, si è verificata in background e, anche se la sessione XE è impostata per filtrare le query di sistema, questa, per qualsiasi motivo, viene comunque acquisita.
Le quattro righe successive rappresentano il codice che abbiamo effettivamente eseguito. Ci sono le due query dalla stored procedure, la stored procedure stessa e quindi la nostra query ad hoc. Tutti hanno lo stesso GUID, ACBFFD99-2400-4AFF-A33F-351821667B24. Accanto al GUID c'è l'id della sequenza (seq) e le query sono numerate da uno a quattro.
Nel nostro esempio, non abbiamo utilizzato GO per separare le istruzioni in batch diversi. Nota come cambia l'output quando lo facciamo:
EXEC [Sales].[usp_CustomerTransactionInfo] 490;
GO
SELECT [c].[CustomerID], [c].[CustomerName], [p].[FullName], [o].[OrderID]
FROM [Application].[People] [p]
JOIN [Sales].[Customers] [c] ON [p].[PersonID] = [c].[PrimaryContactPersonID]
JOIN [Sales].[Orders] [o] ON [c].[CustomerID] = [o].[CustomerID]
WHERE [p].[FullName] = 'Naseem Radan';
GO

Abbiamo ancora lo stesso numero di righe totali, ma ora abbiamo tre GUID. Uno per SELECT @@SPID (E8D136B8-092F-439D-84D6-D4EF794AE753), uno per le tre query che rappresentano la procedura memorizzata (F962B9A4-0665-4802-9E6C-B217634D8787) e uno per la query ad hoc (5DD6A5FE -9702-4DE5-8467-8D7CF55B5D80).
Questo è ciò che molto probabilmente vedrai quando guardi i dati dalla tua applicazione, ma dipende da come funziona l'applicazione. Se utilizza il pool di connessioni e le connessioni vengono reimpostate regolarmente (come previsto), ogni connessione avrà il proprio GUID.
Puoi ricrearlo utilizzando il codice PowerShell di esempio di seguito:
while(1 -eq 1)
{
$SqlConn = New-Object System.Data.SqlClient.SqlConnection;
$SqlConn.ConnectionString = "Data Source=Hedwig\SQL2017;Initial Catalog=WideWorldImporters;Integrated Security=True;Application Name = MyCoolApp";
$SQLConn.Open()
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = "SELECT TOP 1 CustomerID FROM Sales.Customers ORDER BY NEWID();"
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlReader = $SqlCmd.ExecuteReader();
$Results = New-Object System.Collections.ArrayList;
while ($SqlReader.Read())
{
$Results.Add($SqlReader.GetSqlInt32(0)) | Out-Null;
}
$SqlReader.Close();
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = "Sales.usp_CustomerTransactionInfo"
$SqlCmd.CommandType = [System.Data.CommandType]::StoredProcedure;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CustomerID", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::Int;
$SqlCmd.ExecuteNonQuery();
$SqlConn.Close();
$Names = New-Object System.Collections.Generic.List``1[System.String]
$SqlConn = New-Object System.Data.SqlClient.SqlConnection
$SqlConn.ConnectionString = "Data Source=Hedwig\SQL2017;Initial Catalog=WideWorldImporters;User Id=aw_webuser;Password=12345;Application Name=AdventureWorks Online Ordering;Workstation ID=AWWEB01";
$SqlConn.Open();
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = "SELECT FullName FROM Application.People ORDER BY NEWID();";
$dr = $SqlCmd.ExecuteReader();
while($dr.Read())
{
$Names.Add($dr.GetString(0));
}
$SqlConn.Close();
$name = Get-Random -InputObject $Names;
$query = [String]::Format("SELECT [c].[CustomerID], [c].[CustomerName], [p].[FullName], [o].[OrderID]
FROM [Application].[People] [p]
JOIN [Sales].[Customers] [c] ON [p].[PersonID] = [c].[PrimaryContactPersonID]
JOIN [Sales].[Orders] [o] ON [c].[CustomerID] = [o].[CustomerID]
WHERE [p].[FullName] = '{0}';", $name);
$SqlConn = New-Object System.Data.SqlClient.SqlConnection
$SqlConn.ConnectionString = "Data Source=Hedwig\SQL2017;Initial Catalog=WideWorldImporters;User Id=aw_webuser;Password=12345;Application Name=AdventureWorks Online Ordering;Workstation ID=AWWEB01";
$SqlConn.Open();
$SqlCmd = $sqlconnection.CreateCommand();
$SqlCmd.CommandText = $query
$SqlCmd.ExecuteNonQuery();
$SqlConn.Close();
} Ecco un esempio dell'output di eventi estesi dopo aver eseguito il codice per un po':

Esistono quattro diversi GUID per le nostre cinque istruzioni e se guardi il codice sopra vedrai che sono state effettuate quattro diverse connessioni. Se modifichi la sessione dell'evento per includere l'evento rpc_completed, puoi vedere le voci con exec sp_reset_connection.
Il tuo output XE dipenderà dal tuo codice e dalla tua applicazione; Inizialmente ho detto che ciò era utile durante la risoluzione dei problemi di stored procedure più complesse. Considera il seguente esempio:
DROP PROCEDURE IF EXISTS [Sales].[usp_CustomerTransactionInfo]; GO CREATE PROCEDURE [Sales].[usp_CustomerTransactionInfo] @CustomerID INT AS SELECT [CustomerID], SUM([AmountExcludingTax]) FROM [Sales].[CustomerTransactions] WHERE [CustomerID] = @CustomerID GROUP BY [CustomerID]; SELECT COUNT([OrderID]) FROM [Sales].[Orders] WHERE [CustomerID] = @CustomerID GO DROP PROCEDURE IF EXISTS [Sales].[usp_GetFullCustomerInfo]; GO CREATE PROCEDURE [Sales].[usp_GetFullCustomerInfo] @CustomerID INT AS SELECT [o].[CustomerID], [o].[OrderDate], [ol].[StockItemID], [ol].[Quantity], [ol].[UnitPrice] FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [o].[CustomerID] = @CustomerID ORDER BY [o].[OrderDate] DESC; SELECT [o].[CustomerID], SUM([ol].[Quantity]*[ol].[UnitPrice]) FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [o].[CustomerID] = @CustomerID GROUP BY [o].[CustomerID] ORDER BY [o].[CustomerID] ASC; GO DROP PROCEDURE IF EXISTS [Sales].[usp_GetCustomerData]; GO CREATE PROCEDURE [Sales].[usp_GetCustomerData] @CustomerID INT AS BEGIN SELECT * FROM [Sales].[Customers] EXEC [Sales].[usp_CustomerTransactionInfo] @CustomerID EXEC [Sales].[usp_GetFullCustomerInfo] @CustomerID END GO
Qui abbiamo due stored procedure, usp_TransctionInfo e usp_GetFullCustomerInfo, che vengono chiamate da un'altra stored procedure, usp_GetCustomerData. Non è raro vederlo o addirittura vedere livelli aggiuntivi di nidificazione con le stored procedure. Se eseguiamo usp_GetCustomerData da Management Studio, vediamo quanto segue:
EXEC [Sales].[usp_GetCustomerData] 981;

Qui, tutte le esecuzioni si sono verificate sullo stesso GUID, BF54CD8F-08AF-4694-A718-D0C47DBB9593, e possiamo vedere l'ordine di esecuzione della query da uno a otto utilizzando la colonna seq. Nei casi in cui vengono richiamate più stored procedure, non è raro che il valore dell'ID sequenza raggiunga centinaia o migliaia.
Infine, nel caso in cui stai esaminando l'esecuzione della query e hai incluso Traccia causalità e trovi una query con scarse prestazioni, poiché hai ordinato l'output in base alla durata o ad un'altra metrica, tieni presente che puoi trovare l'altro query raggruppando sul GUID:
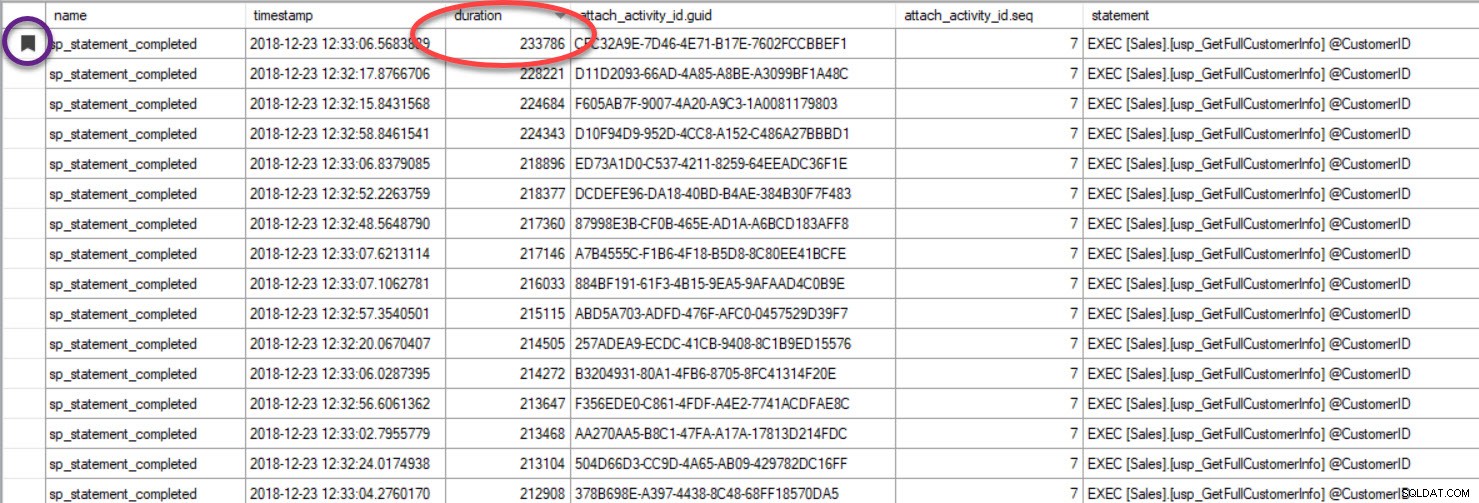
L'output è stato ordinato per durata (il valore più alto è cerchiato in rosso) e l'ho aggiunto ai segnalibri (in viola) utilizzando il pulsante Attiva/disattiva segnalibro. Se vogliamo vedere le altre query per il GUID, raggruppa per GUID (fai clic con il pulsante destro del mouse sul nome della colonna in alto, quindi seleziona Raggruppa per questa colonna), quindi usa il pulsante Segnalibro successivo per tornare alla nostra query:
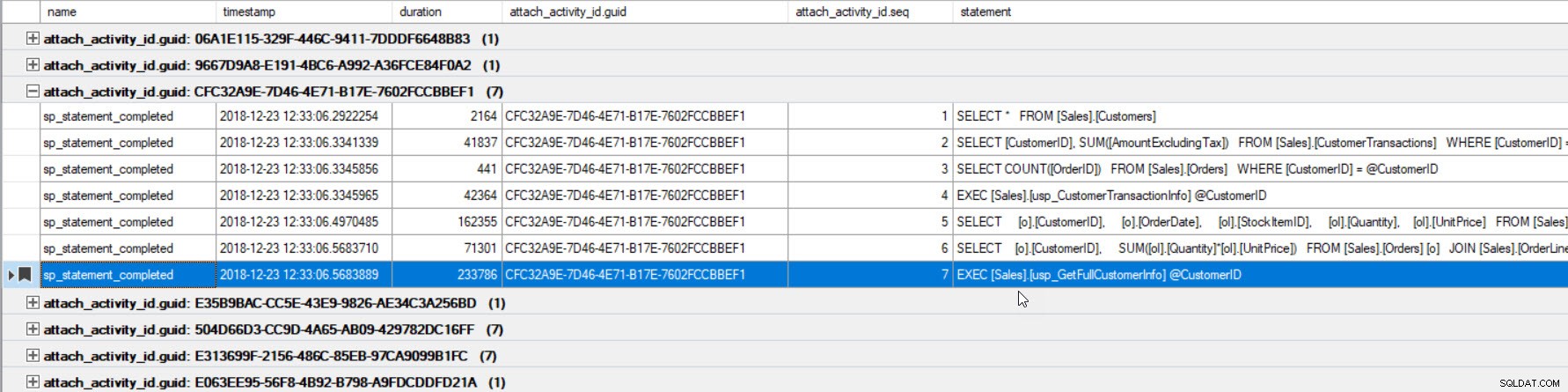
Ora possiamo vedere tutte le query eseguite all'interno della stessa connessione e nell'ordine eseguito.
Conclusione
L'opzione Rileva causalità può essere estremamente utile durante la risoluzione dei problemi relativi alle prestazioni delle query e nel tentativo di comprendere l'ordine degli eventi all'interno di SQL ServerSQL Server. È anche utile quando si imposta una sessione di eventi che utilizza l'obiettivo pair_matching, per garantire la corrispondenza sul campo/azione corretto e trovare l'evento non corrispondente corretto. Anche in questo caso, questa è un'impostazione a livello di sessione, quindi deve essere applicata prima di avviare la sessione dell'evento. Per una sessione in esecuzione, interrompere la sessione dell'evento, abilitare l'opzione, quindi riavviarla.