Il martedì di T-SQL di questo mese è ospitato da Mike Donnelly (@SQLMD) e riassume l'argomento come segue:
L'argomento di questo mese è semplice, ma molto aperto. Devi imparare qualcosa di nuovo e poi scrivere un post sul blog che lo spieghi.Bene, dal momento in cui Mike ha annunciato l'argomento, non ho davvero deciso di imparare nulla di nuovo, e mentre il fine settimana si avvicinava e sapevo che lunedì mi avrebbe aggredito con il dovere di giuria, ho pensato che avrei dovuto sedermi a questo mese fuori.
Poi, Martin Smith mi ha insegnato qualcosa che non ho mai saputo, o che conoscevo molto tempo fa, ma che ho dimenticato (a volte non sai cosa non sai, e a volte non riesci a ricordare cosa non hai mai saputo e cosa non puoi ricordare). Il mio ricordo era che la modifica di una colonna da NOT NULL a NULL dovrebbe essere un'operazione di soli metadati, con le scritture su qualsiasi pagina rinviate fino a quando quella pagina non viene aggiornata per altri motivi, poiché NULL la bitmap non dovrebbe esistere fino a quando almeno una riga potrebbe diventare NULL .
In quello stesso post, @ypercube mi ha anche ricordato questa citazione pertinente da Books Online (errore di battitura e tutto):
La modifica di una colonna da NOT NULL a NULL non è supportata come operazione in linea quando la colonna modificata fa riferimento a indici non cluster."Non è un'operazione online" può essere interpretata come "non un'operazione di soli metadati", il che significa che sarà effettivamente un'operazione sulla dimensione dei dati (più grande è l'indice, più tempo ci vorrà).
Ho deciso di dimostrarlo con un esperimento piuttosto semplice (ma lungo) su una specifica colonna target da convertire da NOT NULL a NULL . Creerei 3 tabelle, tutte con una chiave primaria in cluster, ma ognuna con un indice non in cluster diverso. Uno avrebbe la colonna di destinazione come colonna chiave, il secondo come INCLUDE colonna e il terzo non farebbe affatto riferimento alla colonna di destinazione.
Ecco le mie tabelle e come le ho popolate:
CREATE TABLE dbo.test1
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t1 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix1 ON dbo.test1(b,c);
GO
CREATE TABLE dbo.test2
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t2 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix2 ON dbo.test2(b) INCLUDE(c);
GO
CREATE TABLE dbo.test3
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t3 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix3 ON dbo.test3(b);
GO
INSERT dbo.test1(a,b,c) -- repeat for test2 / test3
SELECT n1, n2, ABS(n2)-ABS(n1)
FROM
(
SELECT TOP (100000) s1.[object_id], s2.[object_id]
FROM master.sys.all_objects AS s1
CROSS JOIN master.sys.all_objects AS s2
GROUP BY s1.[object_id], s2.[object_id]
) AS n(n1, n2);
Ogni tabella aveva 100.000 righe, gli indici raggruppati avevano 310 pagine e gli indici non raggruppati avevano 272 pagine (test1 e test2 ) o 174 pagine (test3 ). (Questi valori sono facili da ottenere da sys.dm_db_index_physical_stats .)
Successivamente, avevo bisogno di un modo semplice per acquisire le operazioni registrate a livello di pagina:ho scelto sys.fn_dblog() , anche se avrei potuto scavare più a fondo e guardare direttamente le pagine. Non mi sono preoccupato di incasinare i valori LSN per passare alla funzione, dal momento che non lo stavo eseguendo in produzione e non mi importava molto delle prestazioni, quindi dopo i test ho semplicemente scaricato i risultati della funzione, escludendo tutti i dati che è stato registrato prima di ALTER TABLE operazioni.
-- establish an exclusion set SELECT * INTO #x FROM sys.fn_dblog(NULL, NULL);
Ora potevo eseguire i miei test, che erano molto più semplici della configurazione.
ALTER TABLE dbo.test1 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test2 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test3 ALTER COLUMN c BIGINT NULL;
Ora potrei esaminare le operazioni che sono state registrate in ogni caso:
SELECT AllocUnitName, [Operation], Context, c = COUNT(*)
FROM
(
SELECT * FROM sys.fn_dblog(NULL, NULL)
WHERE [Operation] = N'LOP_FORMAT_PAGE'
AND AllocUnitName LIKE N'dbo.test%'
EXCEPT
SELECT * FROM #x
) AS x
GROUP BY AllocUnitName, [Operation], Context
ORDER BY AllocUnitName, [Operation], Context; I risultati sembrano suggerire che ogni pagina foglia dell'indice non cluster viene toccata per i casi in cui la colonna target è stata menzionata in alcun modo nell'indice, ma non si verificano tali operazioni nel caso in cui la colonna target non sia menzionata in alcun modo indice non cluster:
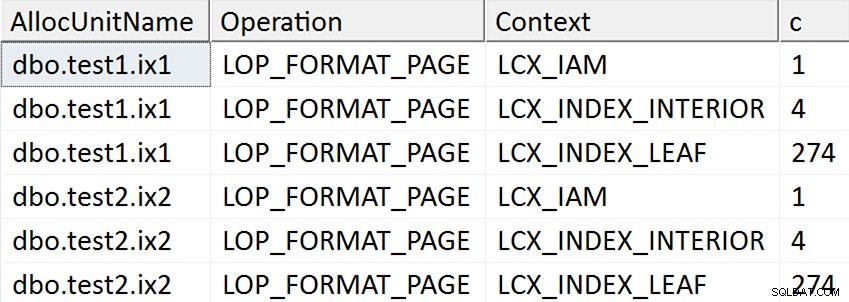
Nei primi due casi, infatti, vengono allocate nuove pagine (puoi convalidarlo con DBCC IND , come ha fatto Spörri nella sua risposta), quindi l'operazione può avvenire online, ma ciò non significa che sia veloce (dal momento che deve ancora scrivere una copia di tutti quei dati e rendere NULL modifica della bitmap come parte della scrittura di ogni nuova pagina e registra tutta quell'attività).
Penso che la maggior parte delle persone sospetti che la modifica di una colonna da NOT NULL a NULL sarebbe solo metadati in tutti gli scenari, ma ho mostrato qui che questo non è vero se la colonna è referenziata da un indice non cluster (e cose simili accadono sia che si tratti di una chiave o di INCLUDE colonna). Forse questa operazione può anche essere forzata per essere ONLINE nel database SQL di Azure oggi o sarà possibile nella prossima versione principale? Ciò non renderà necessariamente più veloci le effettive operazioni fisiche, ma impedirà il blocco di conseguenza.
Non ho testato quello scenario (e l'analisi del fatto che sia davvero online è comunque più difficile in Azure), né l'ho testato su un mucchio. Qualcosa che posso rivedere in un post futuro. Nel frattempo, fai attenzione a qualsiasi ipotesi che potresti fare sulle operazioni di soli metadati.