Nemmeno questa è una buona frammentazione
Il mese scorso ho scritto della frammentazione inaspettata dell'indice cluster, quindi, questa volta, vorrei discutere alcune delle cose che puoi fare per evitare che si verifichi la frammentazione dell'indice. Presumo che tu abbia letto il post precedente e abbia familiarità con i termini che ho definito lì, e nel resto di questo articolo, quando dico "frammentazione" mi riferisco sia alla frammentazione logica che ai problemi di bassa densità di pagina.
Scegli una buona chiave cluster
La struttura dati più costosa su cui operare per rimuovere la frammentazione è l'indice cluster di una tabella, perché è la struttura più grande in quanto contiene tutti i dati della tabella. Dal punto di vista della frammentazione, ha senso scegliere una chiave cluster che corrisponda al modello di inserimento della tabella, quindi non c'è alcuna possibilità che un inserimento avvenga su una pagina dove non c'è spazio e quindi provochi una divisione della pagina e introduca la frammentazione.
Ciò che costituisce la migliore chiave del cluster per una determinata tabella è oggetto di molti dibattiti, ma in generale non sbaglierai se la tua chiave del cluster ha le seguenti semplici proprietà:
- Stretto (vale a dire il minor numero di colonne possibile)
- Statico (cioè non lo aggiorni mai)
- Unico
- Sempre in aumento
È la proprietà in costante aumento che è la più importante per la prevenzione della frammentazione, poiché evita inserimenti casuali che possono causare divisioni di pagina su pagine già piene. Esempi di tale scelta chiave sono le colonne int identity e bigint identity, o anche un GUID sequenziale dalla funzione NEWSEQUENTIALID().
Con questi tipi di chiavi, le nuove righe avranno un valore chiave garantito superiore a tutte le altre nella tabella, quindi il punto di inserimento della nuova riga sarà alla fine della pagina più a destra nella struttura dell'indice cluster. Alla fine le nuove righe riempiranno quella pagina e un'altra pagina verrà aggiunta sul lato destro dell'indice, ma senza che si verifichi una divisione della pagina dannosa.
Ora, se hai una chiave di indice cluster che non aumenta mai, potrebbe essere una procedura molto complessa e sgradevole cambiarla in una sempre crescente, quindi non preoccuparti, invece puoi usare un fattore di riempimento come ho discusso sotto.
A proposito, per una visione molto più approfondita della scelta di una chiave cluster e di tutte le sue ramificazioni, dai un'occhiata alla categoria del blog di Kimberly Clustering Key (leggi dal basso verso l'alto).
Non aggiornare le colonne chiave dell'indice
Ogni volta che una colonna chiave viene aggiornata, non si tratta solo di un semplice aggiornamento sul posto, sebbene molti posti online e nei libri affermino che lo è (si sbagliano). Non è possibile aggiornare una colonna chiave in quanto il nuovo valore della chiave significherebbe che la riga è nell'ordine della chiave errato per l'indice. Invece un aggiornamento della colonna chiave viene convertito in un'eliminazione di riga completa più un inserimento di riga completa con il nuovo valore della chiave. Se la pagina in cui verrà inserita la nuova riga non ha spazio sufficiente su di essa, si verificherà una divisione della pagina, causando la frammentazione.
Evitare gli aggiornamenti delle colonne chiave dovrebbe essere facile per l'indice cluster, poiché è una progettazione scadente che richiede l'aggiornamento della chiave cluster di una riga di tabella. Per gli indici non cluster, tuttavia, è inevitabile se gli aggiornamenti della tabella coinvolgono colonne in cui è presente un indice non cluster. In questi casi, dovrai utilizzare un fattore di riempimento.
Non aggiornare le colonne a lunghezza variabile
Questo è più facile a dirsi che a farsi. Se devi utilizzare colonne a lunghezza variabile ed è possibile che vengano aggiornate, è possibile che crescano e quindi richiedano più spazio per la riga aggiornata, con conseguente divisione della pagina se la pagina è già piena.
Ci sono alcune cose che potresti fare per evitare la frammentazione in questo caso:
- Utilizza un fattore di riempimento
- Utilizza invece una colonna di lunghezza fissa, se l'overhead di tutti i byte di riempimento extra è meno problematico della frammentazione o dell'utilizzo di un fattore di riempimento
- Utilizza un valore segnaposto per "riservare" spazio per la colonna:questo è un trucco che puoi utilizzare se l'applicazione inserisce una nuova riga e poi torna per riempire alcuni dettagli, causando l'espansione della colonna a lunghezza variabile
- Esegui un'eliminazione più inserimento invece di un aggiornamento
Utilizza un fattore di riempimento
Come puoi vedere, molti dei modi per evitare la frammentazione sono sgradevoli poiché implicano modifiche all'applicazione o allo schema, quindi l'utilizzo di un fattore di riempimento è un modo semplice per mitigare la frammentazione.
Un fattore di riempimento dell'indice è un'impostazione per l'indice che specifica la quantità di spazio vuoto da lasciare su ciascuna pagina a livello di foglia quando l'indice viene creato, ricostruito o riorganizzato. L'idea è che c'è abbastanza spazio libero sulla pagina per consentire inserimenti casuali o espansioni di riga (da un tag di controllo delle versioni aggiunto o da colonne di lunghezza variabile aggiornate) senza che la pagina si riempia e richieda una divisione della pagina. Tuttavia, alla fine la pagina si riempirà e quindi periodicamente lo spazio libero deve essere aggiornato ricostruendo o riorganizzando l'indice (generalmente chiamato eseguire la manutenzione dell'indice). Il trucco sta nel trovare il giusto fattore di riempimento da utilizzare, insieme alla corretta periodicità di manutenzione dell'indice.
Puoi leggere ulteriori informazioni sull'impostazione di un fattore di riempimento in MSDN qui. Non cadere nella trappola dell'impostazione del fattore di riempimento per l'intera istanza (usando sp_configure), poiché ciò significa che tutti gli indici verranno ricostruiti o riorganizzati utilizzando quel valore del fattore di riempimento, anche quegli indici che non presentano problemi di frammentazione. Non vuoi che i tuoi indici cluster di grandi dimensioni, con belle chiavi sempre crescenti, abbiano tutti il 30% del loro spazio a livello di foglia sprecato per prepararsi a inserti casuali che non accadranno mai. È molto meglio capire quali indici sono effettivamente interessati dalla frammentazione e impostare solo un fattore di riempimento per quelli.
Non c'è una risposta giusta o una formula magica che posso darti per questo. La pratica generalmente accettata è quella di inserire un fattore di riempimento di 70 (che significa lasciare il 30% di spazio libero) per quegli indici in cui la frammentazione è un problema, monitorare la velocità con cui si verifica la frammentazione e quindi modificare il fattore di riempimento o la frequenza di manutenzione dell'indice (o entrambi).
Sì, questo significa che stai deliberatamente sprecando spazio negli indici per evitare la frammentazione, ma è un buon compromesso da fare, dato quanto sono costose le divisioni di pagina e quanto la frammentazione può essere dannosa per le prestazioni. E sì, nonostante quello che qualcuno potrebbe dire, questo è comunque importante anche se stai usando SSD.
Riepilogo
Ci sono alcune semplici cose che puoi fare per evitare che si verifichi la frammentazione, ma non appena entri in indici non cluster, o usi l'isolamento delle istantanee o secondari leggibili, la frammentazione alza la sua brutta testa e devi cercare di prevenirla.
Ora non pensare a un istantaneo e pensare che dovresti impostare un fattore di riempimento di 70 su tutte le tue istanze:devi sceglierle e impostarle con attenzione, come ho descritto sopra.
E non dimenticare SQL Sentry Fragmentation Manager, che puoi utilizzare (come componente aggiuntivo di Performance Advisor) per capire dove si trovano i problemi di frammentazione e quindi risolverli. Ad esempio, nella scheda Indici, puoi facilmente ordinare prima i tuoi indici in base alla frammentazione più alta (e, se lo desideri, applicare un filtro alla colonna del conteggio delle righe, per ignorare le tabelle più piccole):
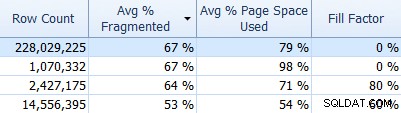
E poi controlla se quegli indici utilizzano il fattore di riempimento predefinito (0%) o forse un fattore di riempimento non predefinito, che potrebbe non essere una buona corrispondenza per i tuoi dati e i modelli DML. Ti farò indovinare quali nella schermata qui sopra sarei più interessato a indagare. L'implementazione di fattori di riempimento dell'indice più appropriati è il modo più semplice per risolvere eventuali problemi che rilevi.