Vuoi imparare come progettare un sistema di database e mappare un processo aziendale su un modello di dati? Allora questo post è per te.
In questo articolo, vedrai come progettare un semplice schema di database per una società di reclutamento. Dopo aver letto questo tutorial, sarai in grado di capire come sono progettati gli schemi di database per le applicazioni del mondo reale.
Il processo aziendale del sistema di reclutamento
Prima di progettare qualsiasi database o modello di dati, è fondamentale comprendere il processo aziendale di base per quel sistema. Lo schema del database che creeremo è per una società o un team di reclutamento immaginari. Vediamo prima i passaggi necessari per l'assunzione di nuovi dipendenti:
- Le aziende contattano le agenzie di reclutamento per assumere per loro conto. In alcuni casi, le aziende assumono direttamente i dipendenti.
- La persona responsabile del reclutamento avvia il processo di reclutamento. Questo processo può avere più fasi, come lo screening iniziale, un test scritto, il primo colloquio, il colloquio di follow-up, l'effettiva decisione di assunzione, ecc.
- Una volta che i reclutatori hanno concordato un particolare processo, e questo può cambiare a seconda del cliente, dell'azienda o del lavoro in questione, il posto vacante viene pubblicizzato su varie piattaforme.
- I candidati iniziano a fare domanda per il lavoro.
- I candidati vengono selezionati e invitati a un test oa un colloquio iniziale.
- I candidati si presentano per il test/colloquio.
- I test sono valutati dai reclutatori. In alcuni casi, i test vengono inoltrati a specialisti per la valutazione.
- Le interviste dei candidati sono valutate da uno o più reclutatori.
- I candidati vengono valutati sulla base di test e colloqui.
- La decisione di assunzione è presa.
Uno schema del database del sistema di reclutamento
Alla luce del suddetto processo, il nostro schema di database è suddiviso in cinque aree tematiche:
ProcessJobsApplication, Applicant, and DocumentsTest and InterviewsRecruiters and Application Evaluation
Esamineremo ciascuna di queste aree in dettaglio, nell'ordine in cui sono elencate. Di seguito, puoi vedere l'intero modello di dati.
Processo
La categoria processo contiene informazioni relative ai processi di reclutamento. Contiene tre tabelle:process , step e process_step . Esamineremo ciascuno di essi.
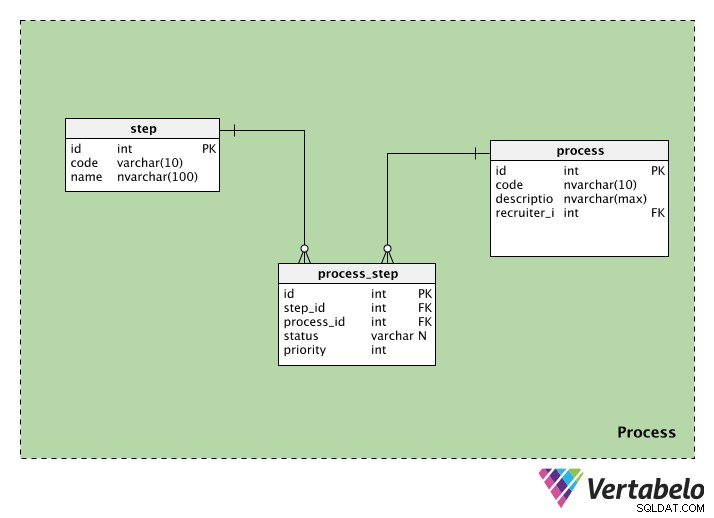
Il process la tabella memorizza le informazioni su ogni processo di reclutamento. Ogni processo avrà un ID speciale, un codice e una description di quel processo. Avremo anche il recruiter_id della persona che avvia il processo.
Il step la tabella contiene informazioni sui passaggi seguiti durante il processo di reclutamento. Ogni passaggio ha un id e un code nome. La colonna del nome può avere valori come "screening iniziale", "test scritto", "colloquio delle risorse umane", ecc.
Poiché un processo può avere più passaggi e un passaggio può far parte di molti processi, è necessaria una tabella di ricerca. Il process_step la tabella contiene informazioni su ogni passaggio (in step_id ) e il processo a cui appartiene (in process_id ). Abbiamo anche uno stato, che ci dice lo stato di quel passaggio in quel processo; questo può essere NULL se il passaggio non è stato ancora avviato. Infine, abbiamo una priority , che ci dice in quale ordine eseguire i passaggi. I passaggi con la priority più alta il valore verrà eseguito per primo.
Lavori
Poi abbiamo i Jobs area tematica, che memorizza tutte le informazioni relative al lavoro per cui stiamo reclutando. Lo schema per questa categoria è simile al seguente:
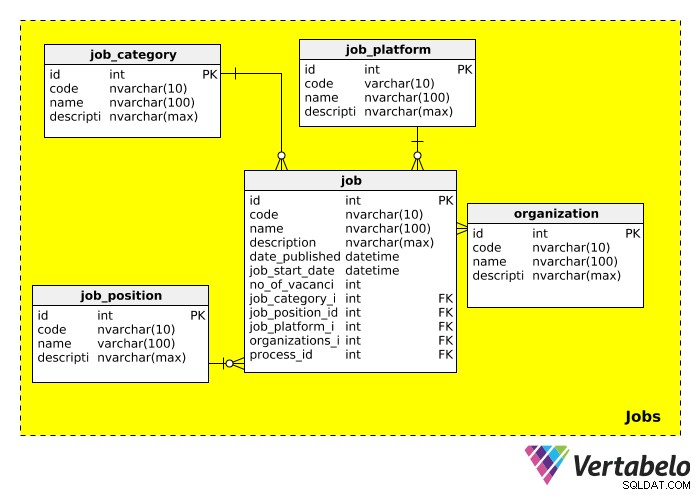
Spieghiamo in dettaglio ciascuna delle tabelle.
Il job_category la tabella descrive ampiamente il tipo di lavoro. Potremmo aspettarci di vedere categorie di lavoro come "IT", "gestione", "finanza", "istruzione", ecc.
Il job_position la tabella contiene il titolo di lavoro effettivo. Poiché un titolo può essere pubblicizzato per più lavori (ad es. "Responsabile IT", "Responsabile vendite"), abbiamo creato una tabella separata per le posizioni lavorative. Potremmo aspettarci di vedere valori come "IT Team Lead", "Vice President" e "Manager" in questa tabella.
Il job_platform tabella si riferisce al mezzo utilizzato per pubblicizzare l'apertura di lavoro. Ad esempio, un lavoro potrebbe essere pubblicato su Facebook, una bacheca di lavoro online o su un giornale locale. Un link a quell'annuncio di lavoro può essere aggiunto nella description campo.
L'organization la tabella memorizza le informazioni su tutte le società che hanno utilizzato questo database come parte del loro processo di assunzione. Ovviamente, questa tabella è importante quando si sta facendo il reclutamento per un'altra azienda.
L'ultima tabella in questa area tematica, job , contiene la descrizione del lavoro effettivo. La maggior parte degli attributi sono autoesplicativi. Dovremmo notare che questa tabella ha molte chiavi esterne, il che significa che può essere utilizzata per cercare la categoria, la posizione, la piattaforma, l'organizzazione di assunzione e il processo di reclutamento relativo a quell'apertura di lavoro.
Domanda, richiedente e documenti
La terza parte dello schema è costituita dalle tabelle che memorizzano le informazioni sui candidati al lavoro, le loro domande e tutti i documenti forniti con le domande.
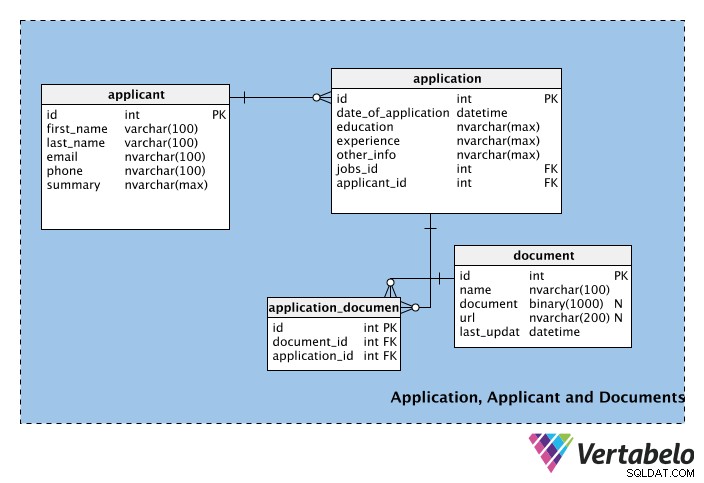
La prima tabella, applicant , memorizza le informazioni personali dei richiedenti, come nome, cognome, e-mail, numero di telefono, ecc. Il campo di riepilogo può essere utilizzato per memorizzare un breve profilo del richiedente (ad esempio un paragrafo).
La tabella successiva contiene informazioni per ogni application , compresa la sua data. La tabella contiene anche l'experience e education colonne. Queste colonne potrebbero far parte del applicant tabella, ma un richiedente può o meno voler mostrare un particolare titolo di studio o esperienza lavorativa su ogni domanda che presenta. Pertanto, queste colonne fanno parte dell'application tavolo. Le other_info la colonna memorizza qualsiasi altra informazione relativa all'applicazione. Nell'application table, jobs_id e richiedente_id sono chiavi esterne rispettivamente dalle tabelle job e richiedente.
Poiché possono esserci più domande per ogni lavoro, ma ogni domanda riguarda un solo lavoro, ci sarà una relazione uno-a-molti tra i jobs e applications tavoli. Allo stesso modo, un candidato può presentare più domande (cioè per lavori diversi), ma ogni domanda proviene da un solo partecipante; abbiamo implementato un'altra relazione uno-a-molti tra i applicants e applications tabelle per gestire questo.
Il document tabella gestisce i documenti giustificativi che i richiedenti possono allegare alla loro domanda. Questi possono essere CV, curriculum, lettere di referenza, lettere di presentazione, ecc. Notare che questa tabella ha una colonna binaria denominata document, che memorizzerà il file in formato binario. Un collegamento al documento può essere memorizzato nell'url campo; la colonna del nome memorizza il nome del documento e last_update indica la versione più recente caricata dal richiedente. Nota che entrambi document e url sono annullabili; nessuno dei due è obbligatorio e un richiedente può scegliere di utilizzare uno o entrambi i metodi per aggiungere informazioni alla propria domanda.
Non tutte le domande avranno un documento allegato. Un documento può essere allegato a più domande e un'applicazione può avere più documenti giustificativi. Ciò significa che esiste una relazione molti-a-molti tra l'application e document tavoli. Per gestire questa relazione, la tabella di ricerca application_document è stato creato.
Test e interviste
Passiamo ora alle tabelle che memorizzano le informazioni sui test e sui colloqui relativi al processo di reclutamento.
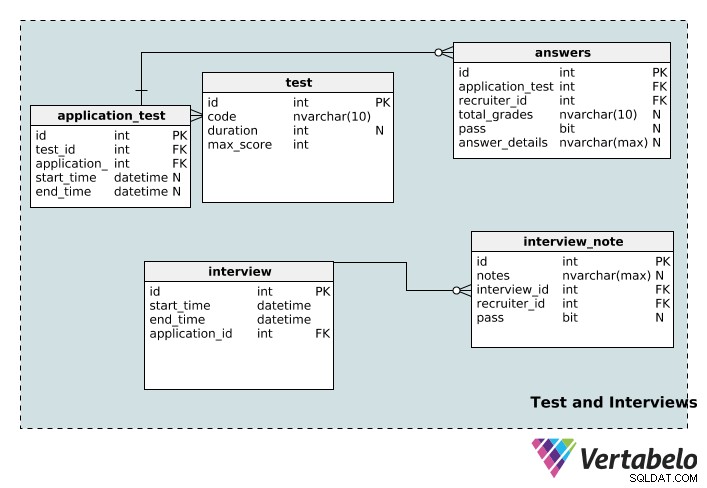
Il test la tabella memorizza i dettagli del test incluso il suo id univoco , code nome, la sua duration in minuti e il maximum punteggio possibile per quel test.
Un'applicazione può essere associata a più test e un test può essere associato a più applicazioni. Ancora una volta, abbiamo una tabella di ricerca per implementare questa relazione:application_test . Il start_time e end_time le colonne sono annullabili, poiché un test potrebbe non avere una durata, un'ora di inizio o un'ora di fine specifica.
Un test può essere valutato da più reclutatori e un reclutatore può valutare più test. Il answers table è la tabella che lo rende possibile. I total_grades la colonna registra quanto bene il candidato ha fatto il test e la colonna del superamento indica semplicemente se quella persona ha superato o meno. Le specifiche di ogni singolo test sono registrate nei answer_details colonna. Si noti che queste tre colonne sono annullabili; un test dell'applicazione potrebbe essere assegnato a un reclutatore che non lo ha ancora valutato. Inoltre, a un recruiter può essere assegnato un test prima che venga effettivamente sostenuto.
Il interview la tabella memorizza le informazioni di base (il start_time , end_time , un id univoco e il relativo application_id ) per ogni colloquio. Un colloquio può essere associato a una sola domanda. D'altra parte, un'applicazione può avere più interviste. Pertanto, esiste una relazione uno-a-molti tra la domanda e la tabella del colloquio.
Un'intervista può essere condotta da più revisori e un revisore può sostenere più interviste. È un'altra relazione molti-a-molti, quindi abbiamo creato la tabella di ricerca interview_note . Memorizza le informazioni sull'intervista (in interview_id ), il reclutatore (in recruiter_id ), e le note del reclutatore sul colloquio. I reclutatori possono anche registrare se il richiedente ha superato o meno il colloquio nella colonna del pass, che è annullabile.
Valutazione e stato della domanda dei reclutatori
L'ultima parte del nostro modello di reclutamento memorizza le informazioni sui reclutatori, lo stato delle candidature e le valutazioni delle candidature.
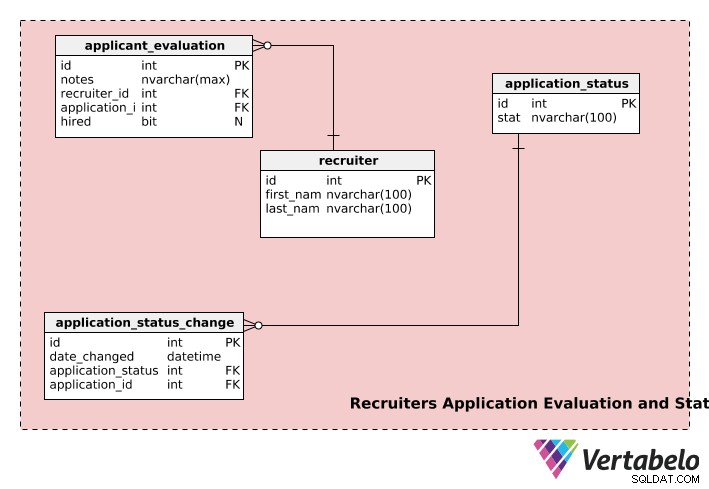
I recruiters la tabella memorizza il first_name di ogni reclutatore , last_name e id univoco numero.
Il application_evaluation la tabella contiene informazioni sulle valutazioni delle applicazioni. Oltre a application_id e recruiter_id , contiene il feedback del reclutatore (in notes ) e l'eventuale decisione di assunzione finale in hired . Una domanda può essere valutata da più reclutatori e un reclutatore può valutare più domande, quindi sia il recruiter e l'application tabella hanno una relazione uno-a-molti con application_evaluation tavolo.
Un'applicazione può passare attraverso più fasi durante il processo di assunzione, ad es. "non inviata", "in corso di revisione", "in attesa di decisione", "decisione presa", ecc. Una domanda avrà lo stato di "non_inviata" quando l'utente ha avviato una domanda ma non l'ha inviata per essere esaminata dai reclutatori. Una volta inviata la domanda, lo stato passa a "in revisione" e così via. Il application_status la tabella viene utilizzata per memorizzare tali informazioni.
Il application_status_change La tabella viene utilizzata per mantenere un registro delle modifiche di stato per tutte le domande inviate. Il date_changed la colonna memorizza la data della modifica dello stato. Questa tabella può essere utile se si desidera analizzare il tempo di elaborazione per ogni fase delle diverse applicazioni. Inoltre, lo stato di qualsiasi colonna particolare può essere recuperato utilizzando il application_id colonna dal application_status_change tavolo.
Un semplice caso d'uso per il reclutamento
Vediamo come il nostro database potrebbe aiutare il processo di reclutamento.
Supponiamo che un'azienda ti abbia incaricato di assumere un IT Manager con esperienza di programmazione. Il nostro database può aiutarci ad assumere tale persona eseguendo i seguenti passaggi:
- Il primo passo è avviare un nuovo processo di assunzione. A tal fine, i dati vengono inseriti nel
processestepstavoli. Un reclutatore può aggiungere tutti i passaggi di cui ha bisogno. - Durante l'attività di cui sopra, il reclutatore potrebbe creare un nuovo lavoro e inserire i dettagli nel
job,job_category,job_positioneorganizationtavoli. Infine, verrà inserito un annuncio di lavoro in una delle piattaforme memorizzate nellajob_platformtabella. - In seguito, i candidati creeranno un profilo inviando i propri dati al
applicanttavolo. Quindi avvieranno una nuova applicazione inserendo più dati nell'applicationtabella. - I candidati possono anche allegare documenti alle loro domande. Questi dati verranno archiviati nel
documenteapplication_documenttabelle. - Se un utente desidera candidarsi a più di un lavoro, ripeterà i passaggi 3 e 4.
- Una volta inviata la domanda, lo stato della domanda verrà impostato su "inviato" (o un altro nome di stato scelto dal reclutatore).
- Il recruiter valuterà la candidatura e inserirà il proprio feedback nel
application_evaluationtavolo. In questa fase, la colonna assunto non conterrà alcuna informazione. - Una volta ricevuto un numero adeguato di candidature, il recruiter eseguirà il passaggio successivo mostrato nel
process_steptabella. - Se il passaggio successivo consiste nell'amministrare una sorta di test, il reclutatore creerà un test aggiungendo dati nel
testtabella. - I test creati nel passaggio 9 verranno assegnati a una particolare applicazione. Le informazioni che assegnano ciascun test a ciascuna applicazione verranno archiviate nel
application_testtavolo. Tieni presente che, durante ogni fase, lo stato dell'applicazione continuerà a cambiare. Questo verrà registrato nelapplication_status_changetabella. - Una volta che il candidato ha completato il test, i voti di ogni test di candidatura saranno contrassegnati dal selezionatore e inseriti nella
answertabella. - Una volta eseguito il test, il passaggio successivo da
process_stepla tabella verrà eseguita. Diciamo che il prossimo passo è l'intervista. - I dati del colloquio verranno inseriti nel
interviewtavolo. Il reclutatore inserirà i propri commenti e dirà se la persona ha superato il colloquio o meno. Questo sarà memorizzato nelinterview_notetabella. - Se il
processla tabella contiene ulteriori passaggi di colloquio e test, verranno eseguiti fino al raggiungimento dell'ultimo passaggio. - L'ultimo passaggio del
process_steptavolo è normalmente la decisione di assunzione. Se il candidato supera i test e i colloqui e l'azienda decide di assumerlo, i dati vengono inseriti nella colonna noleggio delapplication_evaluationtavolo e la persona viene assunta.
Cosa ne pensi del nostro modello di dati del sistema di reclutamento?
In questo articolo abbiamo visto come creare uno schema di database molto semplice per un sistema di reclutamento. Abbiamo diviso lo schema in quattro categorie e poi abbiamo spiegato ciascuna di esse in dettaglio. Infine, abbiamo eseguito un caso d'uso per dimostrare che il nostro schema può effettivamente aiutare a reclutare un dipendente.
I lavori di progettazione di database sono in forte espansione. Vuoi aggiungere competenze al tuo database? Che tu sia un principiante che cerca di apprendere le basi di SQL o un professionista esperto che desidera espandersi nella creazione di tabelle in SQL | Corso interattivo | Vertabelo Academy" target="_blank">progettazione del database, dai un'occhiata ai corsi di autoapprendimento di LearnSQL.com.