In questo articolo, ci concentreremo sull'analisi operativa in tempo reale e su come applicare questo approccio a un database OLTP. Quando osserviamo il modello analitico tradizionale, possiamo vedere OLTP e gli ambienti analitici sono strutture separate. Innanzitutto, gli ambienti dei modelli analitici tradizionali devono creare attività ETL (Extract, Transform and Load). Perché abbiamo bisogno di trasferire i dati transazionali al data warehouse. Questi tipi di architettura presentano alcuni svantaggi. Sono costi, complessità e latenza dei dati. Per eliminare questi svantaggi, abbiamo bisogno di un approccio diverso.
Analisi operativa in tempo reale
Microsoft ha annunciato l'analisi operativa in tempo reale in SQL Server 2016. La capacità di questa funzionalità è di combinare il database transazionale e il carico di lavoro delle query analitiche senza alcun problema di prestazioni. L'analisi operativa in tempo reale fornisce:
- struttura ibrida
- Le query transazionali e di analisi possono essere eseguite contemporaneamente
- non causa problemi di prestazioni e di latenza.
- una semplice implementazione.
Questa caratteristica può superare gli svantaggi dell'ambiente analitico tradizionale. Il tema principale di questa funzionalità è che l'indice di archivio colonne conserva una copia dei dati senza influire sulle prestazioni del sistema transazionale. Questo tema consente l'esecuzione delle query analitiche senza influire sulle prestazioni. Quindi questo riduce al minimo l'impatto sulle prestazioni. Il limite principale di questa funzione è che non possiamo raccogliere dati da diverse origini dati.
Indice archivio colonne non cluster
SQL Server 2016 introduce "Indice archivio colonne non cluster" aggiornabile. L'indice dell'archivio colonne non in cluster è un indice basato su colonne che offre vantaggi in termini di prestazioni per le query analitiche. Questa funzione ci consente di creare il framework di analisi operativa in tempo reale. Ciò significa che possiamo eseguire transazioni e query analitiche contemporaneamente. Considera che abbiamo bisogno di vendite totali mensili. In un modello tradizionale, dobbiamo sviluppare attività ETL, data mart e data warehouse. Ma nell'analisi operativa in tempo reale, possiamo farlo senza richiedere alcun data warehouse o modifiche alla struttura OLTP. Abbiamo solo bisogno di creare un adeguato indice di archivio di colonne non in cluster.
Architettura dell'indice dell'archivio colonne non in cluster
Esaminiamo brevemente l'architettura dell'indice di archivio di colonne non in cluster e il meccanismo di esecuzione. L'indice dell'archivio colonne non in cluster contiene una copia di una parte o di tutte le righe e colonne nella tabella sottostante. Il tema principale dell'indice dell'archivio colonne non in cluster consiste nel mantenere una copia dei dati e utilizzare questa copia dei dati. Quindi questo meccanismo riduce al minimo l'impatto sulle prestazioni del database transazionale. L'indice dell'archivio colonne non in cluster può creare una o più colonne e può applicare un filtro alle colonne.
Quando inseriamo una nuova riga in una tabella che ha un indice di archivio di colonne non in cluster, in primo luogo, SQL Server crea un "rowgroup". Rowgroup è una struttura logica che rappresenta un insieme di righe. Quindi SQL Server archivia queste righe in una memoria temporanea. Il nome di questa memoria temporanea è "deltastore". SQL ServerSQL Server utilizza questa area di archiviazione temporanea perché questo meccanismo migliora il rapporto di compressione e riduce la frammentazione dell'indice. Quando il numero di righe raggiunge 1.048.577, SQL Server chiude lo stato del gruppo di righe. SQL Server comprime questo gruppo di righe e modifica lo stato in "compresso".
Ora creeremo una tabella e aggiungeremo l'indice dell'archivio colonne non in cluster.
DROP TABLE IF EXISTS Analysis_TableTest CREATE TABLE Analysis_TableTest (ID INT PRIMARY KEY IDENTITY(1,1), Continent_Name VARCHAR(20), Country_Name VARCHAR(20), City_Name VARCHAR(20), Sales_Amnt INT, Profit_Amnt INT) GO
CREATE NONCLUSTERED COLUMNSTORE INDEX [NonClusteredColumnStoreIndex] ON [dbo].[Analysis_TableTest]
(
[Country_Name],
[City_Name] ,
Sales_Amnt
)WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0) ON [PRIMARY]
In questo passaggio, inseriremo diverse righe e esamineremo le proprietà dell'indice dell'archivio colonne non in cluster.
INSERT INTO Analysis_TableTest VALUES('Europe','Germany','Munich','100','12')
INSERT INTO Analysis_TableTest VALUES('Europe','Turkey','Istanbul','200','24')
INSERT INTO Analysis_TableTest VALUES('Europe','France','Paris','190','23')
INSERT INTO Analysis_TableTest VALUES('America','USA','Newyork','180','19')
INSERT INTO Analysis_TableTest VALUES('Asia','Japan','Tokyo','190','17')
GO
Questa query visualizzerà gli stati del gruppo di righe, il numero totale di dimensioni delle righe e altri valori.
SELECT i.object_id, object_name(i.object_id) AS TableName,
i.name AS IndexName, i.index_id, i.type_desc,
CSRowGroups.*,
100*(total_rows - ISNULL(deleted_rows,0))/total_rows AS PercentFull
FROM sys.indexes AS i
JOIN sys.column_store_row_groups AS CSRowGroups
ON i.object_id = CSRowGroups.object_id
AND i.index_id = CSRowGroups.index_id
ORDER BY object_name(i.object_id), i.name, row_group_id;

L'immagine sopra ci mostra lo stato del deltastore e il numero totale di righe che non sono compresse. Ora popoleremo più dati nella tabella e quando il numero di righe raggiunge 1.048.577, SQL Server chiuderà il primo gruppo di righe e aprirà un nuovo gruppo di righe.
INSERT INTO Analysis_TableTest VALUES('Europe','Germany','Munich','100','12')
INSERT INTO Analysis_TableTest VALUES('Europe','Turkey','Istanbul','200','24')
INSERT INTO Analysis_TableTest VALUES('Europe','France','Paris','190','23')
INSERT INTO Analysis_TableTest VALUES('America','USA','Newyork','180','19')
INSERT INTO Analysis_TableTest VALUES('Asia','Japan','Tokyo','190','17')
GO 2000000

SQL Server comprimerà questo rowgroup e creerà un nuovo rowgroup. L'opzione "COMPRESSION_DELAY" ci consente di controllare per quanto tempo il rowgroup attende nello stato chiuso.

Quando eseguiamo i comandi di mantenimento dell'indice (riorganizzazione, ricostruzione) le righe eliminate vengono rimosse fisicamente e l'indice viene deframmentato.

Quando aggiorniamo (cancella + inseriamo) alcune righe in questa tabella, le righe eliminate vengono contrassegnate come "cancellate" e le nuove righe aggiornate vengono inserite nel deltastore.
Benchmark delle prestazioni delle query analitiche
In questa intestazione popoleremo i dati nella tabella Analysis_TableTest. Ho inserito 4 milioni di record. (Devi testare questo passaggio e i passaggi successivi nel tuo ambiente di test. Possono verificarsi problemi di prestazioni e anche il comando DBCC DROPCLEANBUFFERS può compromettere le prestazioni. Questo comando rimuoverà tutti i dati del buffer nel pool di buffer.)
Ora eseguiremo la seguente query analitica ed esamineremo i valori delle prestazioni.
SET STATISTICS TIME ON SET STATISTICS IO ON DBCC DROPCLEANBUFFERS select Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount] from Analysis_TableTest group by Country_Name ,City_Name

Nell'immagine sopra, possiamo vedere l'operatore di scansione dell'indice dell'archivio di colonne non in cluster. La tabella seguente mostra la CPU e i tempi di esecuzione. Questa query consuma 1,765 millisecondi di CPU e viene completata in 0,791 millisecondi. Il tempo della CPU è maggiore del tempo trascorso perché il piano di esecuzione utilizza processori paralleli e distribuisce le attività a 4 processori. Possiamo vederlo nelle proprietà dell'operatore "Columnstore Index Scan". Il valore "Numero di esecuzioni" lo indica.

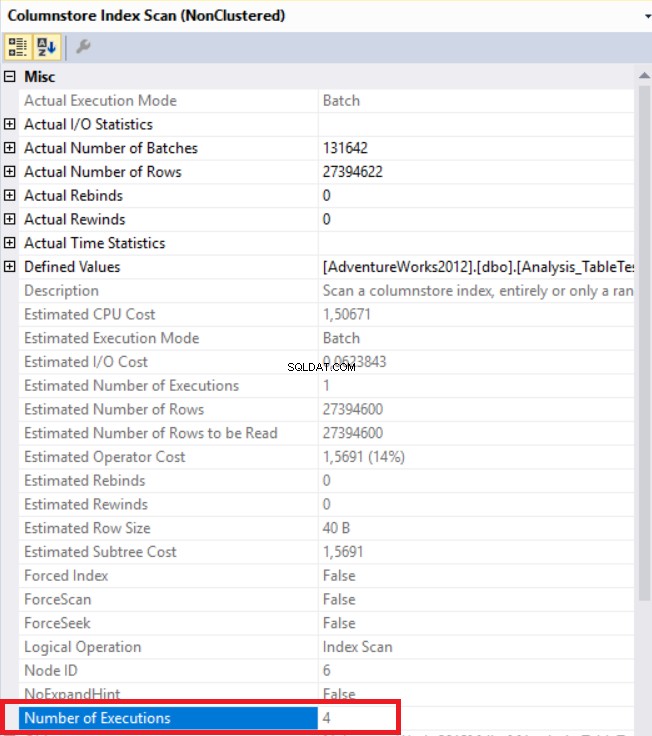
Ora aggiungeremo un suggerimento alla query per ridurre il numero di processori. Non vedremo alcun operatore di parallelismo.
SET STATISTICS TIME ON SET STATISTICS IO ON DBCC DROPCLEANBUFFERS select Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount] from Analysis_TableTest group by Country_Name ,City_Name OPTION (MAXDOP 1)
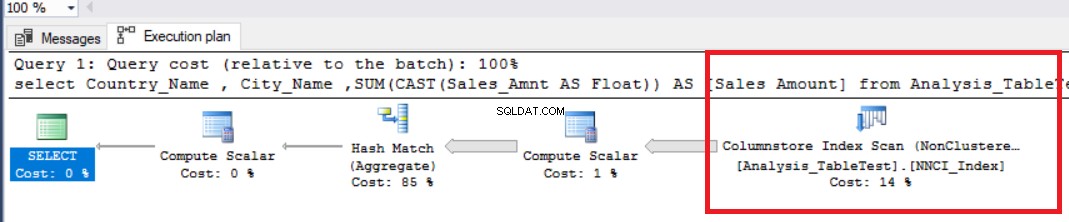

La tabella seguente definisce i tempi di esecuzione. In questo grafico, possiamo vedere che il tempo trascorso è maggiore del tempo della CPU perché SQL Server utilizzava un solo processore.
Ora disabiliteremo l'indice dell'archivio colonne non in cluster ed eseguiremo la stessa query.
ALTER INDEX [NNCI_Index] ON [dbo].[Analysis_TableTest] DISABLE GO SET STATISTICS TIME ON SET STATISTICS IO ON DBCC DROPCLEANBUFFERS select Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount] from Analysis_TableTest group by Country_Name ,City_Name OPTION (MAXDOP 1)

La tabella sopra ci mostra che l'indice dell'archivio colonne non in cluster offre prestazioni incredibili nelle query analitiche. Approssimativamente, la query indicizzata dell'archivio colonne è cinque volte migliore dell'altra.
Conclusione
L'analisi operativa in tempo reale offre un'incredibile flessibilità perché possiamo eseguire query analitiche nei sistemi OLTP senza alcuna latenza dei dati. Allo stesso tempo, queste query analitiche non influiscono sulle prestazioni del database OLTP. Questa funzionalità ci dà la possibilità di gestire i dati transazionali e le query analitiche nello stesso ambiente.
Riferimenti
Indici archivio colonne:indicazioni per il caricamento dei dati
Inizia con Column Store per analisi operative in tempo reale
Analisi operativa in tempo reale
Ulteriori letture:
Scansione all'indietro dell'indice di SQL Server:comprensione, ottimizzazione
Utilizzo degli indici nelle tabelle con ottimizzazione per la memoria di SQL Server



