Nota:questo post è stato originariamente pubblicato solo nel nostro eBook, High Performance Techniques for SQL Server, Volume 2. Puoi trovare informazioni sui nostri eBook qui.
Riepilogo:questo articolo esamina alcuni comportamenti sorprendenti dei trigger INSTEAD OF e rivela un grave bug di stima della cardinalità in SQL Server 2014.
Trigger e controllo delle versioni delle righe
Solo i trigger DML AFTER utilizzano il controllo delle versioni delle righe (da SQL Server 2005 in poi) per fornire l'inserito e eliminato pseudo-tabelle all'interno di una procedura trigger. Questo punto non è chiaramente indicato in gran parte della documentazione ufficiale. Nella maggior parte dei casi, la documentazione dice semplicemente che il controllo delle versioni delle righe viene utilizzato per compilare il file inserted e eliminato tabelle in trigger senza qualifica (esempi di seguito):
Utilizzo delle risorse per il controllo delle versioni delle righe
Comprensione dei livelli di isolamento basati sul controllo delle versioni delle righe
Controllo dell'esecuzione dei trigger durante l'importazione in blocco dei dati
Presumibilmente, le versioni originali di queste voci sono state scritte prima dell'aggiunta dei trigger INSTEAD OF al prodotto e non sono mai state aggiornate. O quello, o è una semplice (ma ripetuta) svista.
Ad ogni modo, il modo in cui il controllo delle versioni delle righe funziona con i trigger AFTER è abbastanza intuitivo. Questi attivatori si attivano dopo le modifiche in questione sono state eseguite, quindi è facile vedere come il mantenimento delle versioni delle righe modificate consenta al motore di database di fornire gli inseriti e eliminato pseudo-tabelle. Il eliminato la pseudo-tabella è costruita dalle versioni delle righe interessate prima che avvenissero le modifiche; l'inserito pseudo-tabella è formata dalle versioni delle righe interessate come al momento dell'avvio della procedura di attivazione.
Invece di trigger
INVECE DI trigger sono diversi perché questo tipo di trigger DML completamente sostituisce l'azione innescata. L'inserito e eliminato le pseudo-tabelle ora rappresentano le modifiche che avrebbero stato eseguito, se l'istruzione di attivazione è stata effettivamente eseguita. Il controllo delle versioni delle righe non può essere utilizzato per questi trigger perché non sono state apportate modifiche, per definizione. Quindi, se non si utilizzano versioni di riga, come fa SQL Server a farlo?
La risposta è che SQL Server modifica il piano di esecuzione per l'istruzione DML di attivazione quando esiste un trigger INSTEAD OF. Anziché modificare direttamente le tabelle interessate, il piano di esecuzione scrive informazioni sulle modifiche in una tabella di lavoro nascosta. Questa tabella di lavoro contiene tutti i dati necessari per eseguire le modifiche originali, il tipo di modifica da eseguire su ciascuna riga (eliminare o inserire), nonché tutte le informazioni necessarie nel trigger per una clausola OUTPUT.
Piano di esecuzione senza trigger
Per vedere tutto questo in azione, eseguiremo prima un semplice test senza che sia presente un trigger INSTEAD OF:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
INSERT dbo.Test
(RowID, Data)
VALUES
(1, 100),
(2, 200),
(3, 300);
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Il piano di esecuzione per l'eliminazione è molto semplice:
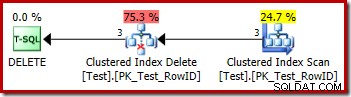
Ogni riga che si qualifica viene passata direttamente a un operatore Clustered Index Delete, che la elimina. Facile.
Piano di esecuzione con un trigger INVECE DI
Ora modifichiamo il test per includere un trigger INSTEAD OF DELETE (uno che esegue semplicemente la stessa azione di eliminazione per semplicità):
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
INSERT dbo.Test
(RowID, Data)
VALUES
(1, 100),
(2, 200),
(3, 300);
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Il piano di esecuzione per DELETE è ora molto diverso:
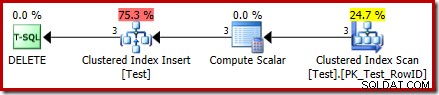
L'operatore Clustered Index Delete è stato sostituito da un Clustered Index Inserisci . Questo è l'inserto della tabella di lavoro nascosta, che viene rinominata (nella rappresentazione del piano di esecuzione pubblica) con il nome della tabella di base interessata dall'eliminazione. La ridenominazione si verifica quando il piano di visualizzazione XML viene generato dalla rappresentazione interna del piano di esecuzione, quindi non esiste un modo documentato per vedere la tabella di lavoro nascosta.
A seguito di questa modifica, il piano sembra quindi eseguire un inserimento alla tabella di base per eliminare righe da esso. Questo è fonte di confusione, ma almeno rivela la presenza di un trigger INSTEAD OF. Sostituire l'operatore Inserisci con un Elimina potrebbe creare ancora più confusione. Forse l'ideale sarebbe una nuova icona grafica per un piano di lavoro INVECE DI trigger? Comunque, è quello che è.
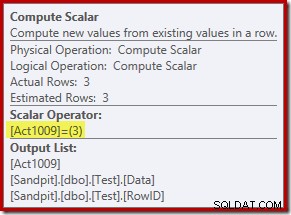
Il nuovo operatore Calcola scalare definisce il tipo di azione eseguita su ciascuna riga. Questo codice azione è un numero intero, con i seguenti significati:
- 3 =ELIMINA
- 4 =INSERIRE
- 259 =ELIMINA in un piano MERGE
- 260 =INSERT in un piano MERGE
Per questa query, l'azione è una costante 3, il che significa che ogni riga deve essere eliminata :
Azioni di aggiornamento
Per inciso, un piano di esecuzione INSTEAD OF UPDATE sostituisce un singolo operatore di aggiornamento con due Inserzioni di indice raggruppate sullo stesso tavolo di lavoro nascosto, uno per gli inseriti righe pseudo-tabella e una per eliminati righe pseudo-tabella. Un esempio di piano di esecuzione:

Un MERGE che esegue un UPDATE produce anche un piano di esecuzione con due inserimenti nella stessa tabella di base per motivi simili:

Il piano di esecuzione del trigger
Il piano di esecuzione per il corpo del trigger ha anche alcune caratteristiche interessanti:
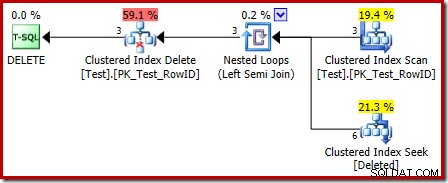
La prima cosa da notare è che l'icona grafica utilizzata per la tabella eliminata non è la stessa dell'icona utilizzata nei piani di attivazione DOPO:
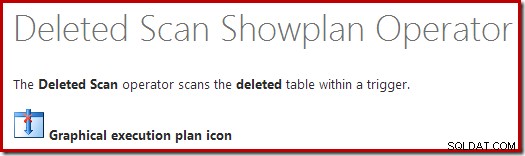
La rappresentazione nel piano trigger INSTEAD OF è un Clustered Index Seek. L'oggetto sottostante è lo stesso tavolo di lavoro interno che abbiamo visto in precedenza, anche se qui è chiamato eliminato invece di ricevere il nome della tabella di base, presumibilmente per una sorta di coerenza con i trigger AFTER.
L'operazione di ricerca sul eliminato la tabella potrebbe non essere quella che ti aspettavi (se ti aspettavi una ricerca su RowID):
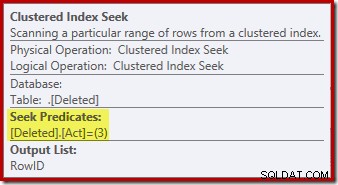
Questa "ricerca" restituisce tutte le righe del tavolo di lavoro che hanno un codice azione 3 (elimina), rendendolo esattamente equivalente alla Scansione eliminata operatore visto nei piani di attivazione DOPO. Lo stesso piano di lavoro interno viene utilizzato per contenere le righe per entrambi gli inseriti e eliminato pseudo-tabelle in INSTEAD OF trigger. L'equivalente di una scansione inserita è una ricerca sul codice di azione 4 (che è possibile in un elimina trigger, ma il risultato sarà sempre vuoto). Non sono presenti indici sul tavolo di lavoro interno a parte l'indice cluster non univoco sull'azione sola colonna. Inoltre, non ci sono statistiche associate a questo indice interno.
L'analisi finora potrebbe farti chiedere dove viene eseguita l'unione tra le colonne RowID. Questo confronto si verifica sull'operatore Nested Loops Left Semi Join come predicato residuo:
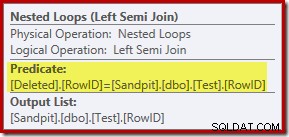
Ora che sappiamo che la "ricerca" è effettivamente una scansione completa dei eliminati tabella, il piano di esecuzione scelto da Query Optimizer sembra piuttosto inefficiente. Il flusso complessivo del piano di esecuzione è che ogni riga della tabella Test viene potenzialmente confrontata con l'intero set di eliminati righe, che suona molto come un prodotto cartesiano.
La grazia salvifica è che il join è un semi join, il che significa che il processo di confronto si interrompe per una determinata riga di test non appena il primo eliminato riga soddisfa il predicato residuo. Tuttavia, la strategia sembra curiosa. Forse il piano di esecuzione sarebbe migliore se la tabella Test contenesse più righe?
Test di trigger con 1.000 righe
Lo script seguente può essere utilizzato per testare il trigger con un numero maggiore di righe. Inizieremo con 1.000:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
SET STATISTICS XML OFF;
SET NOCOUNT ON;
GO
DECLARE @i integer = 1;
WHILE @i <= 1000
BEGIN
INSERT dbo.Test (RowID, Data)
VALUES (@i, @i * 100);
SET @i += 1;
END;
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
SET STATISTICS XML ON;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Il piano di esecuzione per il corpo del trigger è ora:
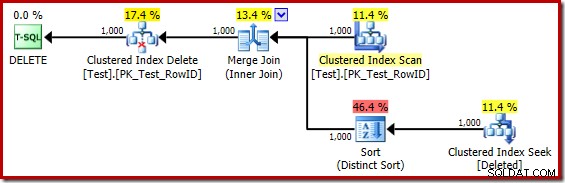
Sostituendo mentalmente la (fuorviante) ricerca di indici in cluster con una scansione eliminata, il piano sembra generalmente abbastanza buono. L'ottimizzatore ha scelto un join di unione uno a molti invece di un semi join di loop nidificati, il che sembra ragionevole. Tuttavia, il Distinct Sort è un'aggiunta curiosa:
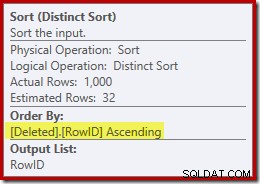
Questo ordinamento esegue due funzioni. Innanzitutto, fornisce l'unione di unione con l'input ordinato di cui ha bisogno, il che è abbastanza corretto perché non esiste un indice sul tavolo di lavoro interno per fornire l'ordine necessario. La seconda cosa che sta facendo l'ordinamento è distinguere su RowID. Potrebbe sembrare strano, perché RowID è la chiave primaria della tabella di base.
Il problema è che le righe nel eliminato table sono semplicemente righe candidate identificate dalla query DELETE originale. A differenza di un trigger AFTER, queste righe non sono state ancora controllate per la presenza di vincoli o violazioni delle chiavi, quindi il Query Processor non ha alcuna garanzia che siano effettivamente univoche.
In generale, questo è un punto molto importante da tenere a mente con i trigger INSTEAD OF:non vi è alcuna garanzia che le righe fornite soddisfino nessuno dei vincoli sulla tabella di base (incluso NOT NULL). Questo non è importante solo per l'autore del trigger da ricordare; limita inoltre le semplificazioni e le trasformazioni che Query Optimizer può eseguire.
Un secondo problema mostrato nelle proprietà di ordinamento sopra, ma non evidenziato, è che la stima di output è di sole 32 righe. Il tavolo di lavoro interno non ha statistiche ad esso associate, quindi l'ottimizzatore congettura per effetto dell'operazione Distinct. "Sappiamo" che i valori di RowID sono univoci, ma senza alcuna informazione concreta su cui procedere, l'ottimizzatore fa un'ipotesi sbagliata. Questo problema tornerà a perseguitarci nel prossimo test.
Test trigger con 5.000 righe
Ora modifica lo script di test per generare 5.000 righe:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
SET STATISTICS XML OFF;
SET NOCOUNT ON;
GO
DECLARE @i integer = 1;
WHILE @i <= 5000
BEGIN
INSERT dbo.Test (RowID, Data)
VALUES (@i, @i * 100);
SET @i += 1;
END;
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
SET STATISTICS XML ON;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Il piano di esecuzione del trigger è:
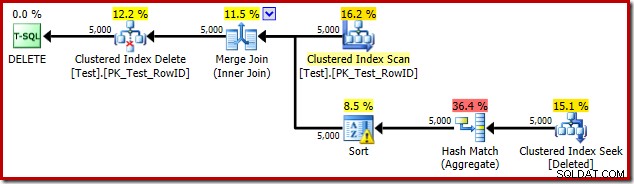
Questa volta l'ottimizzatore ha deciso di dividere le operazioni distinte e di ordinamento. Il distinto su RowID viene eseguito dall'operatore Hash Match (aggregato):
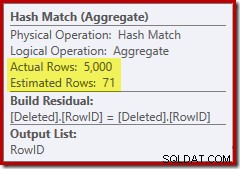
Si noti che la stima dell'ottimizzatore per l'output è di 71 righe. In effetti, tutte le 5.000 righe sopravvivono al distinto perché RowID è univoco. La stima imprecisa significa che una frazione inadeguata della concessione di memoria della query viene allocata all'ordinamento, che finisce per riversarsi su tempdb :
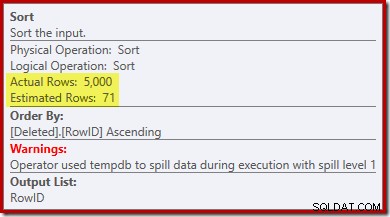
Questo test deve essere eseguito su SQL Server 2012 o versioni successive per visualizzare l'avviso di ordinamento nel piano di esecuzione. Nelle versioni precedenti, il piano non conteneva informazioni sugli spill:sarebbe necessaria una traccia Profiler sull'evento Sort Warnings per rivelarlo (e in qualche modo avresti bisogno di correlarlo alla query di origine).
Test di trigger con 5.000 righe su SQL Server 2014
Se il test precedente viene ripetuto su SQL Server 2014, in un database impostato sul livello di compatibilità 120 quindi viene utilizzato il nuovo stimatore di cardinalità (CE), il piano di esecuzione del trigger è di nuovo diverso:
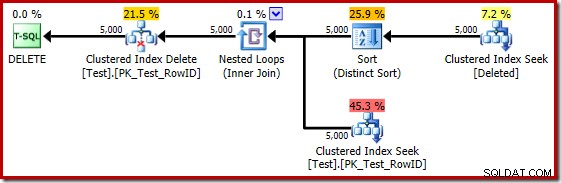
In un certo senso, questo piano di esecuzione sembra un miglioramento. Il (non necessario) Distinct Sort è ancora presente, ma la strategia generale sembra più naturale:per ogni RowID candidato distinto nel eliminato tabella, unisciti alla tabella di base (verificando così che la riga candidata esista effettivamente) e quindi eliminala.
Sfortunatamente, il piano 2014 si basa su stime di cardinalità peggiori rispetto a quelle viste in SQL Server 2012. Modifica di SQL Sentry Plan Explorer per visualizzare il stimato il conteggio delle righe mostra chiaramente il problema:
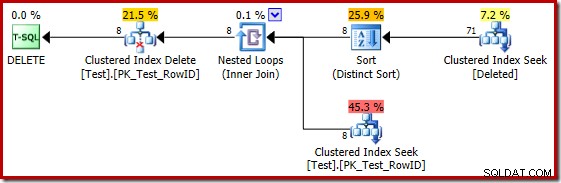
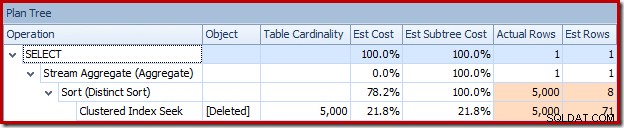
L'ottimizzatore ha scelto una strategia Nested Loops per il join perché prevedeva un numero molto ridotto di righe nell'input superiore. Il primo problema si verifica in Clustered Index Seek. L'ottimizzatore sa che la tabella eliminata contiene 5.000 righe a questo punto, come possiamo vedere passando alla vista Plan Tree e aggiungendo la colonna opzionale Table Cardinality (che vorrei fosse inclusa per impostazione predefinita):
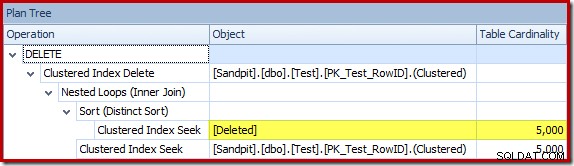
Il "vecchio" stimatore di cardinalità in SQL Server 2012 e versioni precedenti è abbastanza intelligente da sapere che la "ricerca" sul tavolo di lavoro interno restituirebbe tutte le 5.000 righe (quindi ha scelto un join di unione). Il nuovo CE non è così intelligente. Vede il tavolo di lavoro come una "scatola nera" e indovina l'effetto della ricerca sul codice azione =3:
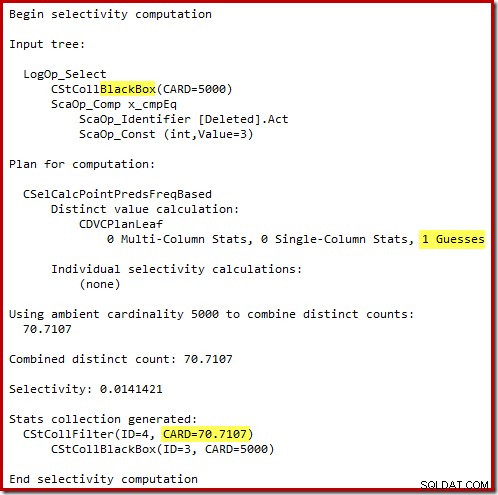
L'ipotesi di 71 righe (arrotondata per eccesso) è un risultato piuttosto miserabile, ma l'errore è aggravato quando il nuovo CE stima le righe per l'operazione distinta su quelle 71 righe:
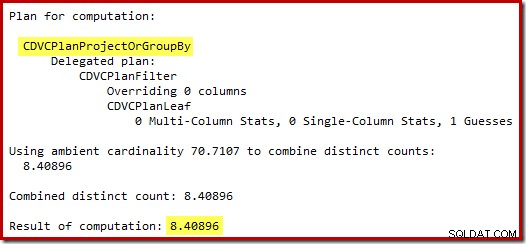
Sulla base delle 8 righe previste, l'ottimizzatore sceglie la strategia Nested Loops. Un altro modo per vedere questi errori di stima consiste nell'aggiungere la seguente istruzione al corpo del trigger (solo a scopo di test):
SELECT COUNT_BIG(DISTINCT RowID) FROM Deleted;
Il piano stimato mostra chiaramente gli errori di stima:
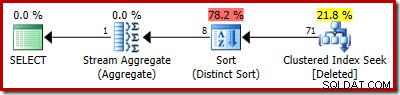
Il piano attuale mostra ancora 5.000 righe ovviamente:
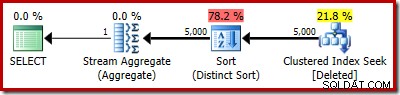
Oppure puoi confrontare la stima con l'effettiva allo stesso tempo nella visualizzazione Plan Tree:
Un milione di righe...
Le scarse stime approssimative quando si utilizza lo stimatore di cardinalità 2014 fanno sì che l'ottimizzatore selezioni una strategia Nested Loops anche quando la tabella Test contiene un milione di righe. Il nuovo CE 2014 stimato il piano per quel test è:
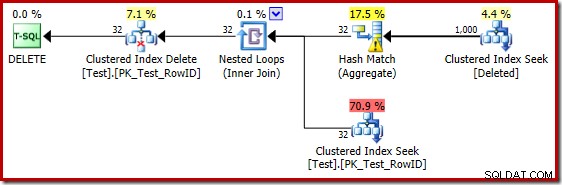
La "ricerca" stima 1.000 righe dalla cardinalità nota di 1.000.000 e la stima distinta è di 32 righe. Il piano post-esecuzione rivela l'effetto sulla memoria riservata all'Hash Match:
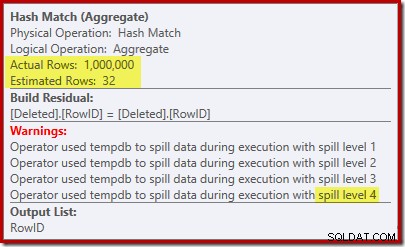
Con solo 32 righe, l'Hash Match finisce nei guai, rovesciando ricorsivamente la sua tabella hash prima di completarlo.
Pensieri finali
Se è vero che un trigger non dovrebbe mai essere scritto per fare qualcosa che può essere ottenuto con integrità referenziale dichiarativa, è anche vero che un ben scritto trigger che utilizza un efficiente il piano di esecuzione può essere paragonabile in termini di prestazioni al costo del mantenimento di un indice extra non cluster.
Ci sono due problemi pratici con la dichiarazione di cui sopra. Innanzitutto (e con la migliore volontà del mondo) le persone non scrivono sempre un buon codice trigger. In secondo luogo, ottenere un buon piano di esecuzione da Query Optimizer in tutte le circostanze può essere difficile. La natura dei trigger è che vengono chiamati con un'ampia gamma di cardinalità di input e distribuzioni di dati.
Anche per i trigger AFTER, la mancanza di indici e statistiche sui eliminati e inserito pseudo-tabelle significa che la selezione del piano è spesso basata su supposizioni o disinformazione. Anche se inizialmente viene selezionato un buon piano, le esecuzioni successive potrebbero riutilizzare lo stesso piano quando una ricompilazione sarebbe stata una scelta migliore. Ci sono modi per aggirare le limitazioni, principalmente attraverso l'uso di tabelle temporanee e indici/statistiche esplicite, ma anche lì è necessaria una grande attenzione (poiché i trigger sono una forma di stored procedure).
Con i trigger INSTEAD OF, i rischi possono essere ancora maggiori perché il contenuto dell'inserito e eliminato le tabelle sono candidati non verificati:Query Optimizer non può utilizzare i vincoli sulla tabella di base per semplificare e perfezionare il proprio piano di esecuzione. Il nuovo stimatore di cardinalità in SQL Server 2014 rappresenta anche un vero passo indietro quando si tratta di piani trigger INSTEAD OF. Indovinare l'effetto di un'operazione di ricerca che il motore stesso ha introdotto è una svista sorprendente e sgradita.