È molto facile dimostrare che le seguenti due espressioni danno esattamente lo stesso risultato:il primo giorno del mese corrente.
SELECT DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0),
CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE())); E impiegano all'incirca la stessa quantità di tempo per il calcolo:
SELECT SYSDATETIME(); GO DECLARE @d DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); GO 1000000 GO SELECT SYSDATETIME(); GO DECLARE @d DATE = DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()); GO 1000000 SELECT SYSDATETIME();
Sul mio sistema, il completamento di entrambi i batch ha richiesto circa 175 secondi.
Quindi, perché preferiresti un metodo rispetto all'altro? Quando uno di loro sbaglia davvero con le stime della cardinalità .
Come introduzione rapida, confrontiamo questi due valori:
SELECT DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0), -- today: 2013-09-01
DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0); -- today: 1786-05-01
--------------------------------------^^^^^^^^^^^^ notice how these are swapped
(Nota che i valori effettivi rappresentati qui cambieranno, a seconda di quando stai leggendo questo post – "oggi" a cui si fa riferimento nel commento è il 5 settembre 2013, il giorno in cui è stato scritto questo post. Nell'ottobre 2013, ad esempio, l'output sarà essere 2013-10-01 e 1786-04-01 .)
Detto questo, lascia che ti mostri cosa intendo...
Una riproduzione
Creiamo una tabella molto semplice, con solo un cluster DATE colonna e carica 15.000 righe con il valore 1786-05-01 e 50 righe con il valore 2013-09-01 :
CREATE TABLE dbo.DateTest ( CreateDate DATE ); CREATE CLUSTERED INDEX x ON dbo.DateTest(CreateDate); INSERT dbo.DateTest(CreateDate) SELECT TOP (15000) DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0) FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 UNION ALL SELECT TOP (50) DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0) FROM sys.all_objects;
E poi diamo un'occhiata ai piani effettivi per queste due query:
SELECT /* Query 1 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); SELECT /* Query 2 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0);
I piani grafici sembrano corretti:
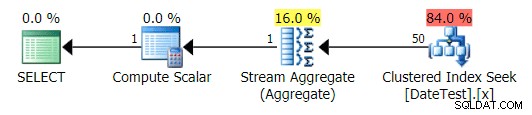
Piano grafico per DATEDIFF(MESE, 0, GETDATE()) interrogare
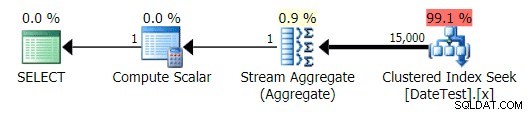
Piano grafico per DATEDIFF(MESE, GETDATE(), 0) interrogare
Ma i costi stimati sono fuori luogo:nota quanto sono più alti i costi stimati per la prima query, che restituisce solo 50 righe, rispetto alla seconda query, che restituisce 15.000 righe!

Griglia dell'estratto conto che mostra i costi stimati
E la scheda Operazioni principali mostra che la prima query (cercando 2013-09-01 ) ha stimato che avrebbe trovato 15.000 righe, mentre in realtà ne ha trovate solo 50; la seconda query mostra il contrario:prevedeva di trovare 50 righe corrispondenti a 1786-05-01 , ma ne ha trovati 15.000. Sulla base di stime di cardinalità errate come questa, sono sicuro che puoi immaginare quale tipo di effetto drastico potrebbe avere su query più complesse rispetto a set di dati molto più grandi.
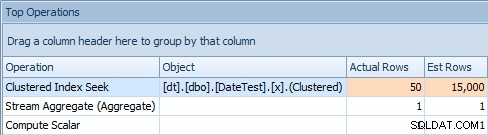
Scheda Operazioni in alto per la prima query [DATEDIFF(MESE, 0, GETDATE())]
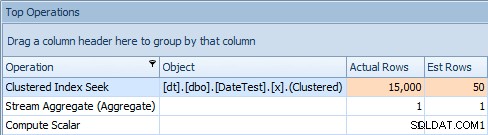
Scheda Operazioni principali per la seconda query [DATEDIFF(MESE, 0, GETDATE())]
Una variazione leggermente diversa della query, che utilizza un'espressione diversa per calcolare l'inizio del mese (a cui si fa riferimento all'inizio del post), non mostra questo sintomo:
SELECT /* Query 3 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()));
Il piano è molto simile alla query 1 sopra, e se non guardassi più da vicino penseresti che questi piani sono equivalenti:
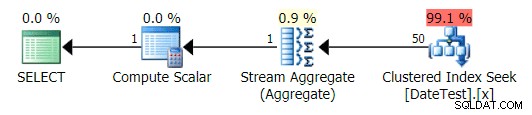
Piano grafico per query non DATEDIFF
Quando guardi la scheda Operazioni principali qui, tuttavia, vedi che la stima è perfetta:
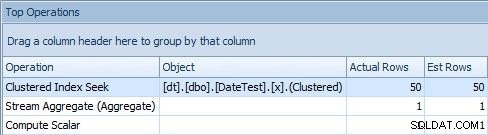
Scheda Operazioni principali che mostra stime accurate
Su questa particolare dimensione dei dati e query, l'impatto netto sulle prestazioni (in particolare durata e letture) è in gran parte irrilevante. Ed è importante notare che le query stesse restituiscono comunque dati corretti; è solo che le stime sono sbagliate (e potrebbero portare a un piano peggiore di quello che ho dimostrato qui). Detto questo, se stai derivando costanti usando DATEDIFF all'interno delle tue query in questo modo, dovresti davvero testare questo impatto nel tuo ambiente.
Allora perché succede?
Per dirla semplicemente, SQL Server ha un DATEDIFF bug in cui scambia il secondo e il terzo argomento durante la valutazione dell'espressione per la stima della cardinalità. Ciò sembra implicare una piegatura costante, almeno perifericamente; ci sono molti più dettagli sulla piegatura costante in questo articolo di Libri in linea ma, sfortunatamente, l'articolo non rivela alcuna informazione su questo particolare bug.
C'è una soluzione – o c'è?
C'è un articolo della knowledge base (KB #2481274) che pretende di affrontare il problema, ma presenta alcuni problemi propri:
- L'articolo della Knowledge Base afferma che il problema è stato risolto in vari service pack o aggiornamenti cumulativi per SQL Server 2005, 2008 e 2008 R2. Tuttavia, il sintomo è ancora presente nei rami che non sono menzionati esplicitamente, anche se hanno visto molte CU aggiuntive da quando l'articolo è stato pubblicato. Posso ancora riprodurre questo problema su SQL Server 2008 SP3 CU n. 8 (10.0.5828) e SQL Server 2012 SP1 CU n. 5 (11.0.3373).
- Tralascia di menzionare che, per beneficiare della correzione, è necessario attivare il flag di traccia 4199 (e "beneficiare" di tutti gli altri modi in cui il flag di traccia specifico può influire sull'ottimizzatore). Il fatto che questo flag di traccia sia necessario per la correzione è menzionato in un elemento Connect correlato, #630583, ma queste informazioni non sono tornate all'articolo della Knowledge Base. Né l'articolo della Knowledge Base né l'elemento Connect forniscono informazioni sulla causa (che gli argomenti per
DATEDIFFsono stati scambiati durante la valutazione). Tra i lati positivi, eseguire le query precedenti con il flag di traccia attivato (utilizzandoOPTION (QUERYTRACEON 4199)) produce piani che non presentano il problema della stima errata.
- Suggerisce di utilizzare SQL dinamico per aggirare il problema. Nei miei test, usando un'espressione diversa (come quella sopra che non usa
DATEDIFF) ha risolto il problema nelle build moderne di SQL Server 2008 e SQL Server 2012. La raccomandazione di SQL dinamico qui è inutilmente complessa e probabilmente eccessiva, dato che un'espressione diversa potrebbe risolvere il problema. Ma se dovessi utilizzare SQL dinamico, lo farei in questo modo invece del modo in cui raccomandano nell'articolo della Knowledge Base, soprattutto per ridurre al minimo i rischi di SQL injection:DECLARE @date DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0), @sql NVARCHAR(MAX) = N'SELECT COUNT(*) FROM dbo.DateTest WHERE CreateDate = @date;'; EXEC sp_executesql @sql, N'@date DATE', @date;(E puoi aggiungere
OPTION (RECOMPILE)lì, a seconda di come vuoi che SQL Server gestisca lo sniffing dei parametri.)Questo porta allo stesso piano della query precedente che non utilizza
DATEDIFF, con stime corrette e il 99,1% del costo nella ricerca dell'indice cluster.Un altro approccio che potrebbe tentarti (e con te, intendo me, quando ho iniziato a indagare) è utilizzare una variabile per calcolare in anticipo il valore:
DECLARE @d DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); SELECT COUNT(*) FROM dbo.DateTest WHERE CreateDate = @d;
Il problema con questo approccio è che, con una variabile, ti ritroverai con un piano stabile, ma la cardinalità sarà basata su un'ipotesi (e il tipo di ipotesi dipenderà dalla presenza o assenza di statistiche) . In questo caso, ecco la stima rispetto a quella reale:
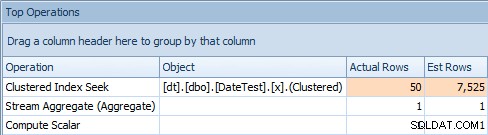
Scheda Operazioni principali per query che utilizzano una variabileQuesto chiaramente non è giusto; sembra che SQL Server abbia intuito che la variabile corrisponderebbe al 50% delle righe nella tabella.
SQL Server 2014
Ho riscontrato un problema leggermente diverso in SQL Server 2014. Le prime due query sono state risolte (tramite modifiche allo stimatore di cardinalità o altre correzioni), il che significa che DATEDIFF gli argomenti non vengono più scambiati. Sìì!
Tuttavia, sembra che sia stata introdotta una regressione alla soluzione alternativa dell'utilizzo di un'espressione diversa:ora soffre di una stima imprecisa (basata sulla stessa ipotesi del 50% dell'utilizzo di una variabile). Queste sono le query che ho eseguito:
SELECT /* 0, GETDATE() (2013) */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0);
SELECT /* GETDATE(), 0 (1786) */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0);
SELECT /* Non-DATEDIFF */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()));
DECLARE @d DATE = DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE());
SELECT /* Variable */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = @d;
DECLARE
@date DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0),
@sql NVARCHAR(MAX) = N'SELECT /* Dynamic SQL */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = @date;';
EXEC sp_executesql @sql, N'@date DATE', @date; Ecco la griglia del rendiconto che confronta i costi stimati e le metriche di runtime effettive:
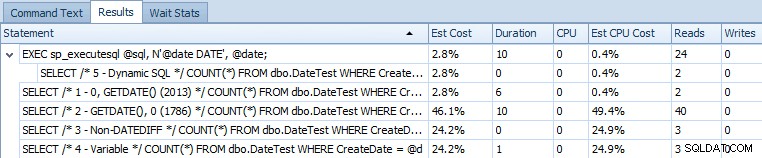
Costi stimati per le 5 query campione su SQL Server 2014
E questi sono i conteggi delle righe stimati ed effettivi (assemblati utilizzando Photoshop):

Numero di righe stimato ed effettivo per le 5 query su SQL Server 2014
È chiaro da questo output che l'espressione che in precedenza risolveva il problema ne ha ora introdotta un'altra. Non sono sicuro se questo sia un sintomo dell'esecuzione in un CTP (ad esempio qualcosa che verrà corretto) o se questa sia davvero una regressione.
In questo caso, il flag di traccia 4199 (da solo) non ha effetto; il nuovo stimatore di cardinalità sta facendo ipotesi e semplicemente non è corretto. Il fatto che porti a un problema di prestazioni effettivo dipende molto da molti altri fattori oltre lo scopo di questo post.
Se riscontri questo problema, puoi, almeno negli attuali CTP, ripristinare il vecchio comportamento utilizzando OPTION (QUERYTRACEON 9481, QUERYTRACEON 4199) . Il flag di traccia 9481 disabilita il nuovo stimatore di cardinalità, come descritto in queste note di rilascio (che sicuramente scomparirà o almeno si sposterà ad un certo punto). Questo a sua volta ripristina le stime corrette per il non DATEDIFF versione della query, ma sfortunatamente non risolve ancora il problema in cui viene effettuata un'ipotesi in base a una variabile (e l'utilizzo di TF9481 da solo, senza TF4199, costringe le prime due query a regredire al vecchio comportamento di scambio di argomenti).
Conclusione
Devo ammettere che questa è stata una grande sorpresa per me. Complimenti a Martin Smith e t-clausen.dk per aver perseverato e convinto che si trattava di un problema reale e non immaginario. Un grande ringraziamento anche a Paul White (@SQL_Kiwi) che mi ha aiutato a mantenere la mia sanità mentale e mi ha ricordato le cose che non dovrei dire. :-)
Non essendo a conoscenza di questo bug, ero fermamente convinto che il piano di query migliore fosse generato semplicemente modificando il testo della query, non a causa della modifica specifica. A quanto pare, a volte una modifica a una query che potresti assumere non farà alcuna differenza, anzi lo farà. Pertanto, se nel tuo ambiente sono presenti modelli di query simili, ti consiglio di testarli e assicurarti che le stime di cardinalità riescano correttamente. E prendi nota per testarli di nuovo quando esegui l'upgrade.