Il partizionamento è una funzionalità di SQL Server spesso implementata per alleviare i problemi relativi alla gestibilità, alle attività di manutenzione o al blocco e al blocco. L'amministrazione di tabelle di grandi dimensioni può diventare più semplice con il partizionamento e può migliorare la scalabilità e la disponibilità. Inoltre, un sottoprodotto del partizionamento può essere il miglioramento delle prestazioni delle query. Non è una garanzia o un dato di fatto e non è il motivo trainante per implementare il partizionamento, ma è qualcosa che vale la pena rivedere quando si partiziona una tabella di grandi dimensioni.
Sfondo
Per una rapida rassegna, la funzionalità di partizionamento di SQL Server è disponibile solo nelle edizioni Enterprise e Developer. Il partizionamento può essere implementato durante la progettazione iniziale del database oppure può essere implementato dopo che una tabella contiene già dei dati. Comprendi che cambiare una tabella esistente con dati in una tabella partizionata non è sempre veloce e semplice, ma è abbastanza fattibile con una buona pianificazione e i vantaggi possono essere realizzati rapidamente.
Una tabella partizionata è quella in cui i dati sono separati in strutture fisiche più piccole in base al valore di una colonna specifica (denominata colonna di partizionamento, definita nella funzione di partizione). Se desideri separare i dati per anno, puoi utilizzare una colonna denominata DateSold come colonna di partizionamento e tutti i dati per il 2013 risiedono in un'unica struttura, tutti i dati per il 2012 risiedono in una struttura diversa, ecc. Questi insiemi separati di dati consentire una manutenzione mirata (è possibile ricostruire solo una partizione di un indice, anziché l'intero indice) e consentire ai dati di essere aggiunti e rimossi rapidamente perché possono essere organizzati prima di essere effettivamente aggiunti o rimossi dalla tabella.
La configurazione
Per esaminare le differenze nelle prestazioni delle query per una tabella partizionata rispetto a una non partizionata, ho creato due copie della tabella Sales.SalesOrderHeader dal database AdventureWorks2012. La tabella non partizionata è stata creata con solo un indice cluster su SalesOrderID, la chiave primaria tradizionale per la tabella. La seconda tabella è stata partizionata su OrderDate, con OrderDate e SalesOrderID come chiave di clustering e non ha indici aggiuntivi. Si noti che ci sono numerosi fattori da considerare quando si decide quale colonna utilizzare per il partizionamento. Il partizionamento spesso, ma certamente non sempre, utilizza un campo data per definire i limiti della partizione. Pertanto, per questo esempio è stato selezionato OrderDate e sono state utilizzate query di esempio per simulare l'attività tipica rispetto alla tabella SalesOrderHeader. Le istruzioni per creare e popolare entrambe le tabelle possono essere scaricate qui.
Dopo aver creato le tabelle e aggiunto i dati, sono stati verificati gli indici esistenti e quindi aggiornate le statistiche con FULLSCAN:
EXEC sp_helpindex 'Sales.Big_SalesOrderHeader'; GO EXEC sp_helpindex 'Sales.Part_SalesOrderHeader'; GO UPDATE STATISTICS [Sales].[Big_SalesOrderHeader] WITH FULLSCAN; GO UPDATE STATISTICS [Sales].[Part_SalesOrderHeader] WITH FULLSCAN; GO SELECT sch.name + '.' + so.name AS [Table], ss.name AS [Statistic], sp.last_updated AS [Stats Last Updated], sp.rows AS [Rows], sp.rows_sampled AS [Rows Sampled], sp.modification_counter AS [Row Modifications] FROM sys.stats AS ss INNER JOIN sys.objects AS so ON ss.[object_id] = so.[object_id] INNER JOIN sys.schemas AS sch ON so.[schema_id] = sch.[schema_id] OUTER APPLY sys.dm_db_stats_properties(so.[object_id], ss.stats_id) AS sp WHERE so.[object_id] IN (OBJECT_ID(N'Sales.Big_SalesOrderHeader'), OBJECT_ID(N'Sales.Part_SalesOrderHeader')) AND ss.stats_id = 1;
Inoltre, entrambe le tabelle hanno la stessa identica distribuzione dei dati e una frammentazione minima.
Prestazioni per una query semplice
Prima di aggiungere ulteriori indici, è stata eseguita una query di base su entrambe le tabelle per calcolare i totali guadagnati dal venditore per gli ordini effettuati a dicembre 2012:
SELECT [SalesPersonID], SUM([TotalDue]) FROM [Sales].[Big_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' GROUP BY [SalesPersonID]; GO SELECT [SalesPersonID], SUM([TotalDue]) FROM [Sales].[Part_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' GROUP BY [SalesPersonID]; GOSTATISTICHE IO USCITA
Tavolo 'Tavolo da lavoro'. Conteggio scansioni 0, letture logiche 0, letture fisiche 0, letture read-ahead 0, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
Tabella 'Big_SalesOrderHeader'. Conteggio scansioni 9, letture logiche 2710440, letture fisiche 2226, letture read-ahead 2658769, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
Tavolo 'Tavolo da lavoro'. Conteggio scansioni 0, letture logiche 0, letture fisiche 0, letture read-ahead 0, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
Tabella 'Part_SalesOrderHeader'. Conteggio scansioni 9, letture logiche 248128, letture fisiche 3, letture read-ahead 245030, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.

Totali per venditore per dicembre – Tabella non partizionata
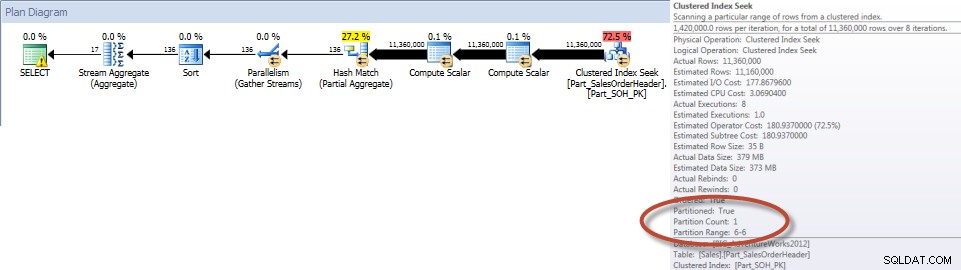
Totali per venditore per dicembre – Tabella partizionata
Come previsto, la query sulla tabella non partizionata doveva eseguire un'analisi completa della tabella poiché non esisteva un indice per supportarla. Al contrario, la query sulla tabella partizionata necessitava solo di accedere a una partizione della tabella.
Per essere onesti, se si trattasse di una query eseguita ripetutamente con intervalli di date diversi, esisterebbe l'indice non cluster appropriato. Ad esempio:
CREATE NONCLUSTERED INDEX [Big_SalesOrderHeader_SalesPersonID] ON [Sales].[Big_SalesOrderHeader] ([OrderDate]) INCLUDE ([SalesPersonID], [TotalDue]);
Con questo indice creato, quando la query viene rieseguita, le statistiche di I/O cadono e il piano cambia per utilizzare l'indice non cluster:
STATISTICHE IO USCITA
Tavolo 'Tavolo da lavoro'. Conteggio scansioni 0, letture logiche 0, letture fisiche 0, letture read-ahead 0, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
Tabella 'Big_SalesOrderHeader'. Conteggio scansioni 9, letture logiche 42901, letture fisiche 3, letture read-ahead 42346, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.

Totali per venditore per dicembre – NCI su tabella non partizionata
Con un indice di supporto, la query su Sales.Big_SalesOrderHeader richiede un numero notevolmente inferiore di letture rispetto alla scansione dell'indice cluster su Sales.Part_SalesOrderHeader, il che non è imprevisto poiché l'indice cluster è molto più ampio. Se creiamo un indice non cluster comparabile per Sales.Part_SalesOrderHeader, vediamo numeri di I/O simili:
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_SalesPersonID] ON [Sales].[Part_SalesOrderHeader]([SalesPersonID]) INCLUDE ([TotalDue]);STATISTICHE IO USCITA
Tabella 'Part_SalesOrderHeader'. Conteggio scansioni 9, letture logiche 42894, letture fisiche 1, letture read-ahead 42378, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
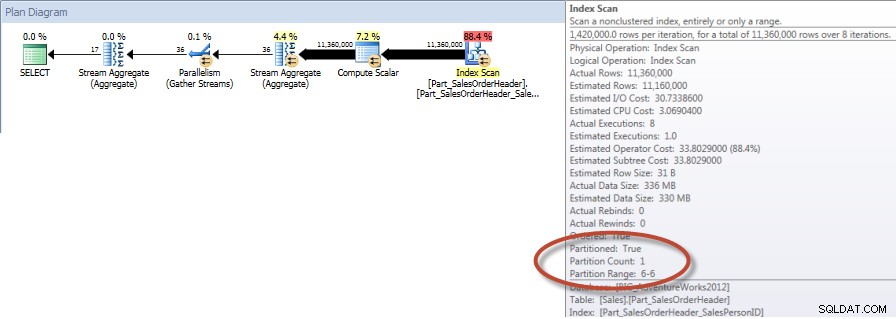
Totali per venditore per dicembre – NCI su tabella partizionata con eliminazione
E se osserviamo le proprietà della scansione dell'indice non cluster, possiamo verificare che il motore abbia avuto accesso a una sola partizione (6).
Come affermato in origine, il partizionamento non viene in genere implementato per migliorare le prestazioni. Nell'esempio mostrato sopra, la query sulla tabella partizionata non ha prestazioni significativamente migliori finché esiste l'indice non cluster appropriato.
Prestazioni per una query ad hoc
Una query sulla tabella partizionata can in alcuni casi superano la stessa query rispetto alla tabella non partizionata, ad esempio quando la query deve utilizzare l'indice cluster. Sebbene sia l'ideale avere la maggior parte delle query supportata da indici non cluster, alcuni sistemi consentono query ad hoc da parte degli utenti e altri hanno query che potrebbero essere eseguite così di rado da non giustificare il supporto degli indici. Nella tabella SalesOrderHeader, un utente potrebbe eseguire la seguente query per trovare gli ordini di dicembre 2012 che dovevano essere spediti entro la fine dell'anno ma non lo hanno fatto, per un particolare gruppo di clienti e con un TotalDue maggiore di $ 1000:
SELECT [SalesOrderID], [OrderDate], [DueDate], [ShipDate], [AccountNumber], [CustomerID], [SalesPersonID], [SubTotal], [TotalDue] FROM [Sales].[Big_SalesOrderHeader] WHERE [TotalDue] > 1000 AND [CustomerID] BETWEEN 10000 AND 20000 AND [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' AND [DueDate] < '2012-12-31' AND [ShipDate] > '2012-12-31'; GO SELECT [SalesOrderID], [OrderDate], [DueDate], [ShipDate], [AccountNumber], [CustomerID], [SalesPersonID], [SubTotal], [TotalDue] FROM [Sales].[Part_SalesOrderHeader] WHERE [TotalDue] > 1000 AND [CustomerID] BETWEEN 10000 AND 20000 AND [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' AND [DueDate] < '2012-12-31' AND [ShipDate] > '2012-12-31'; GOSTATISTICHE IO USCITA
Tabella 'Big_SalesOrderHeader'. Conteggio scansioni 9, letture logiche 2711220, letture fisiche 8386, letture read-ahead 2662400, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
Tabella 'Part_SalesOrderHeader'. Conteggio scansioni 9, letture logiche 248128, letture fisiche 0, letture read-ahead 243792, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
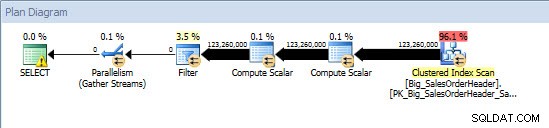
Query ad hoc – Tabella non partizionata
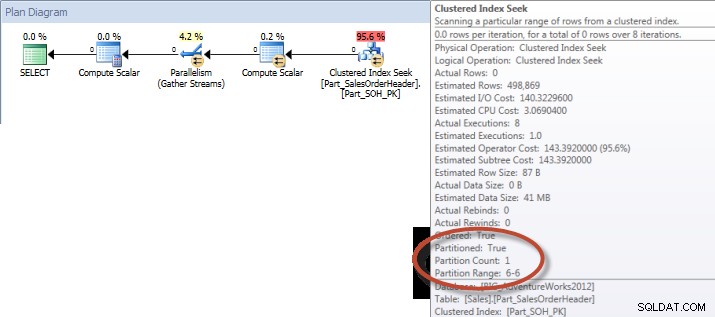
Query ad hoc – Tabella partizionata
Sulla tabella non partizionata la query richiedeva una scansione completa rispetto all'indice cluster, ma sulla tabella partizionata la query eseguiva una ricerca dell'indice dell'indice cluster, poiché il motore utilizzava l'eliminazione della partizione e leggeva solo i dati di cui aveva assolutamente bisogno. In questo esempio, si tratta di una differenza significativa in termini di I/O e, a seconda dell'hardware, potrebbe essere una notevole differenza nel tempo di esecuzione. La query può essere ottimizzata aggiungendo l'indice appropriato, ma in genere non è possibile indicizzare per ogni singolo interrogazione. In particolare, per le soluzioni che consentono query ad hoc, è giusto dire che non si sa mai cosa faranno gli utenti. Una query può essere eseguita una volta e non essere più eseguita e la creazione di un indice dopo il fatto è inutile. Pertanto, quando si passa da una tabella non partizionata a una tabella partizionata, è importante applicare lo stesso sforzo e approccio della normale ottimizzazione dell'indice; vuoi verificare che esistano gli indici appropriati per supportare la maggior parte delle query.
Rendimento e allineamento dell'indice
Un ulteriore fattore da considerare quando si creano indici per una tabella partizionata è se allineare o meno l'indice. Gli indici devono essere allineati con la tabella se prevedi di cambiare i dati dentro e fuori le partizioni. La creazione di un indice non cluster su una tabella partizionata crea un indice allineato per impostazione predefinita, in cui la colonna di partizionamento viene aggiunta all'indice come colonna inclusa.
Un indice non allineato viene creato specificando uno schema di partizione diverso o un filegroup diverso. La colonna di partizionamento può far parte dell'indice come colonna chiave o colonna inclusa, ma se non viene utilizzato lo schema di partizione della tabella o viene utilizzato un filegroup diverso, l'indice non verrà allineato.
Un indice allineato è partizionato proprio come la tabella – i dati esisteranno in strutture separate – e quindi può verificarsi l'eliminazione della partizione. Un indice non allineato esiste come una struttura fisica e potrebbe non fornire il vantaggio previsto per una query, a seconda del predicato. Considera una query che conteggi le vendite per numero di conto, raggruppate per mese:
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);
Se non hai familiarità con il partizionamento, potresti creare un indice come questo per supportare la query (nota che il filegroup PRIMARY è specificato):
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_AccountNumber_NotAL] ON [Sales].[Part_SalesOrderHeader]([AccountNumber]) ON [PRIMARY];
Questo indice non è allineato, anche se include OrderDate perché fa parte della chiave primaria. Le colonne sono incluse anche se creiamo un indice allineato, ma nota la differenza nella sintassi:
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_AccountNumber_AL] ON [Sales].[Part_SalesOrderHeader]([AccountNumber]);
Possiamo verificare quali colonne esistono nell'indice utilizzando sp_helpindex:
di Kimberly TrippEXEC sp_SQLskills_SQL2008_helpindex 'Sales.Part_SalesOrderHeader’;

sp_helpindex per Sales.Part_SalesOrderHeader
Quando eseguiamo la nostra query e la forziamo a utilizzare l'indice non allineato, viene scansionato l'intero indice. Anche se OrderDate fa parte dell'indice, non è la colonna principale, quindi il motore deve controllare il valore OrderDate per ogni AccountNumber per vedere se è compreso tra il 1 gennaio 2013 e il 31 luglio 2013:
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_NotAL])) WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);STATISTICHE IO USCITA
Tavolo 'Tavolo da lavoro'. Conteggio scansioni 0, letture logiche 0, letture fisiche 0, letture read-ahead 0, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
Tabella 'Part_SalesOrderHeader'. Conteggio scansioni 9, letture logiche 786861, letture fisiche 1, letture read-ahead 770929, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
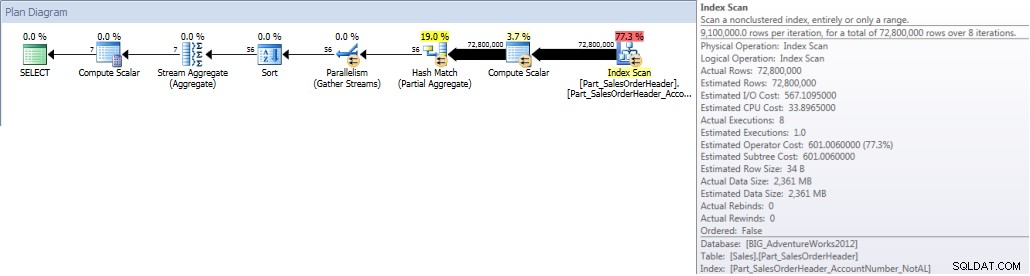
Totali account per mese (gennaio-luglio 2013) utilizzando non- Allineato NCI (forzato)
Al contrario, quando la query è forzata a utilizzare l'indice allineato, è possibile utilizzare l'eliminazione della partizione e sono necessari meno I/O, anche se OrderDate non è una colonna iniziale nell'indice.
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_AL])) WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);STATISTICHE IO USCITA
Tavolo 'Tavolo da lavoro'. Conteggio scansioni 0, letture logiche 0, letture fisiche 0, letture read-ahead 0, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
Tabella 'Part_SalesOrderHeader'. Conteggio scansioni 9, letture logiche 456258, letture fisiche 16, letture read-ahead 453241, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
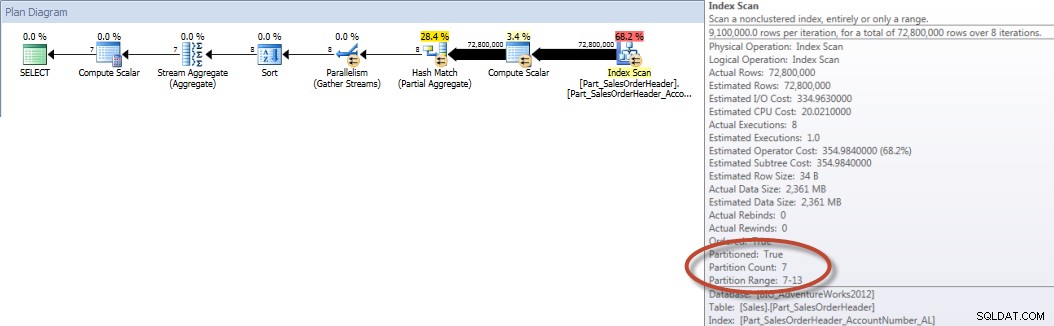
Totali account per mese (gennaio-luglio 2013) Utilizzo di NCI allineato (forzato)
Riepilogo
La decisione di implementare il partizionamento richiede la dovuta considerazione e pianificazione. Facilità di gestione, maggiore scalabilità e disponibilità e una riduzione del blocco sono motivi comuni per partizionare le tabelle. Il miglioramento delle prestazioni delle query non è un motivo per utilizzare il partizionamento, sebbene in alcuni casi possa essere un vantaggioso effetto collaterale. In termini di prestazioni, è importante assicurarsi che il piano di implementazione includa una revisione delle prestazioni delle query. Verifica che i tuoi indici continuino a supportare adeguatamente le tue query dopo la tabella è partizionata e verifica che le query che utilizzano gli indici cluster e non cluster traggano vantaggio dall'eliminazione della partizione, ove applicabile.