La strategia generale utilizzata dal motore di database di SQL Server per mantenere una vista indicizzata sincronizzata con le sue tabelle di base, che ho descritto più dettagliatamente nel mio ultimo post, consiste nell'eseguire la manutenzione incrementale della vista ogni volta che si verifica un'operazione di modifica dei dati su una delle tabelle a cui si fa riferimento nella vista. In termini generali, l'idea è di:
- Raccogliere informazioni sulle modifiche alla tabella di base
- Applica le proiezioni, i filtri e i join definiti nella vista
- Aggrega le modifiche per chiave cluster della vista indicizzata
- Decidi se ogni modifica deve comportare un inserimento, un aggiornamento o un'eliminazione rispetto alla vista
- Calcola i valori da modificare, aggiungere o rimuovere nella vista
- Applica le modifiche alla vista
O, ancora più sinteticamente (seppur a rischio di grossolane semplificazioni):
- Calcola gli effetti di visualizzazione incrementale delle modifiche ai dati originali;
- Applica queste modifiche alla vista
Questa è in genere una strategia molto più efficiente rispetto alla ricostruzione dell'intera vista dopo ogni modifica dei dati sottostante (l'opzione sicura ma lenta), ma si basa sul fatto che la logica di aggiornamento incrementale sia corretta per ogni possibile modifica dei dati, rispetto a ogni possibile definizione di vista indicizzata.
Come suggerisce il titolo, questo articolo riguarda un caso interessante in cui la logica di aggiornamento incrementale si interrompe, risultando in una vista indicizzata corrotta che non corrisponde più ai dati sottostanti. Prima di arrivare al bug stesso, dobbiamo rivedere rapidamente gli aggregati scalari e vettoriali.
Aggregati scalari e vettoriali
Nel caso in cui non si abbia familiarità con il termine, esistono due tipi di aggregati. Un aggregato associato a una clausola GROUP BY (anche se l'elenco raggruppa per è vuoto) è noto come aggregato vettoriale . Un aggregato senza una clausola GROUP BY è noto come aggregato scalare .
Mentre è garantito che un aggregato vettoriale produca una singola riga di output per ciascun gruppo presente nel set di dati, gli aggregati scalari sono leggermente diversi. Aggregazioni scalari sempre produrre una singola riga di output, anche se il set di input è vuoto.
Esempio di aggregato vettoriale
L'esempio AdventureWorks seguente calcola due aggregati vettoriali (una somma e un conteggio) su un set di input vuoto:
-- There are no TransactionHistory records for ProductID 848 -- Vector aggregate produces no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID;
Queste query producono il seguente output (nessuna riga):

Il risultato è lo stesso, se sostituiamo la clausola GROUP BY con un set vuoto (richiede SQL Server 2008 o successivo):
-- Equivalent vector aggregate queries with -- an empty GROUP BY column list -- (SQL Server 2008 and later required) -- Still no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY (); SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY ();
Anche i piani di esecuzione sono identici in entrambi i casi. Questo è il piano di esecuzione per la query di conteggio:
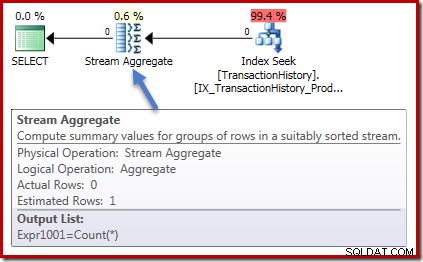
Zero righe in input per Stream Aggregate e zero righe in uscita. Il piano di esecuzione della somma si presenta così:

Ancora una volta, zero righe nell'aggregato e zero righe fuori. Finora tutte cose buone e semplici.
Aggregati scalari
Ora guarda cosa succede se rimuoviamo completamente la clausola GROUP BY dalle query:
-- Scalar aggregate (no GROUP BY clause) -- Returns a single output row from an empty input SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848;
Invece di un risultato vuoto, l'aggregato COUNT produce uno zero e SUM restituisce un NULL:
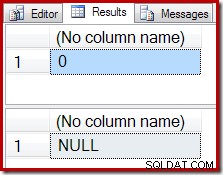
Il piano di esecuzione del conteggio conferma che zero righe di input producono una singola riga di output dallo Stream Aggregate:
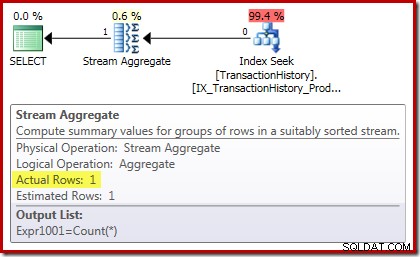
Ancora più interessante il piano di esecuzione delle somme:
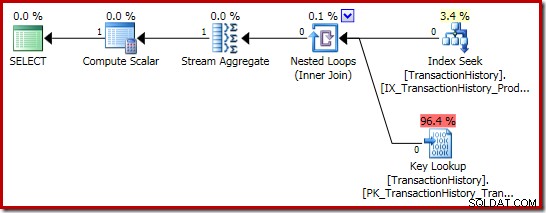
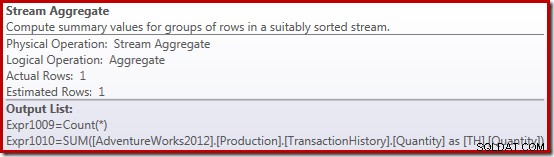
Le proprietà Stream Aggregate mostrano un conteggio aggregato calcolato in aggiunta alla somma che abbiamo chiesto:
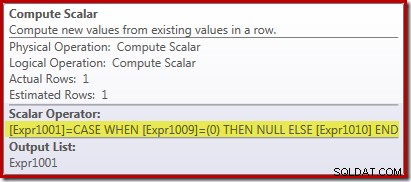
Il nuovo operatore Compute Scalar viene utilizzato per restituire NULL se il conteggio delle righe ricevute dallo Stream Aggregate è zero, altrimenti restituisce la somma dei dati incontrati:
Tutto ciò potrebbe sembrare un po' strano, ma è così che funziona:
- Un aggregato vettoriale di zero righe restituisce zero righe;
- Un aggregato scalare produce sempre esattamente una riga di output, anche per un input vuoto;
- Il conteggio scalare di zero righe è zero; e
- La somma scalare di zero righe è NULL (non zero).
Il punto importante per i nostri scopi attuali è che gli aggregati scalari producono sempre una singola riga di output, anche se ciò significa crearne una dal nulla. Inoltre, la somma scalare di zero righe è NULL, non zero.
Questi comportamenti sono tutti "corretti" tra l'altro. Le cose stanno così perché lo standard SQL originariamente non definiva il comportamento degli aggregati scalari, lasciandolo all'implementazione. SQL Server mantiene la sua implementazione originale per motivi di compatibilità con le versioni precedenti. Gli aggregati vettoriali hanno sempre avuto comportamenti ben definiti.
Viste indicizzate e aggregazione vettoriale
Consideriamo ora una semplice vista indicizzata che incorpora un paio di aggregati (vettoriali):
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
GroupSum = SUM(T1.Value),
RowsInGroup = COUNT_BIG(*)
FROM dbo.T1 AS T1
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); Le query seguenti mostrano il contenuto della tabella di base, il risultato dell'interrogazione della vista indicizzata e il risultato dell'esecuzione della query della vista sulla tabella sottostante la vista:
-- Sample data SELECT * FROM dbo.T1 AS T1; -- Indexed view contents SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Underlying view query results SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
I risultati sono:
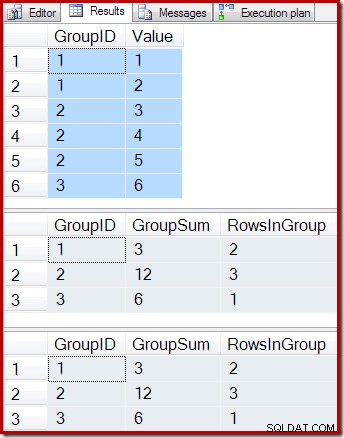
Come previsto, la vista indicizzata e la query sottostante restituiscono esattamente gli stessi risultati. I risultati continueranno a rimanere sincronizzati dopo tutte le possibili modifiche alla tabella di base T1. Per ricordarci come funziona tutto questo, consideriamo il semplice caso di aggiungere una singola nuova riga alla tabella di base:
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); Il piano di esecuzione di questo inserto contiene tutta la logica necessaria per mantenere sincronizzata la vista indicizzata:
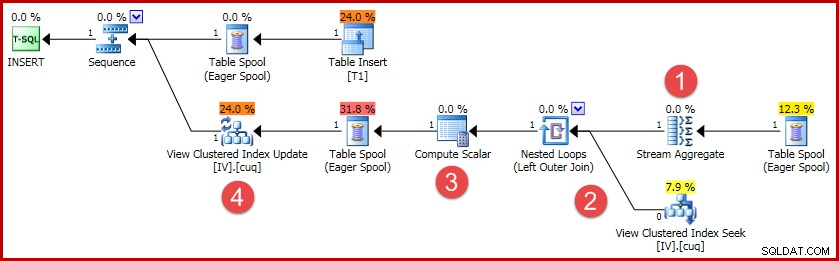
Le principali attività del piano sono:
- Lo Stream Aggregate calcola le modifiche per chiave di visualizzazione indicizzata
- The Outer Join to the view collega il riepilogo delle modifiche alla riga della vista di destinazione, se presente
- Compute Scalar decide se ogni modifica richiede un inserimento, aggiornamento o eliminazione rispetto alla vista e calcola i valori necessari.
- L'operatore di aggiornamento della vista esegue fisicamente ogni modifica all'indice del cluster della vista.
Esistono alcune differenze di piano per diverse operazioni di modifica rispetto alla tabella di base (ad es. aggiornamenti ed eliminazioni), ma l'idea generale alla base di mantenere sincronizzata la vista rimane la stessa:aggrega le modifiche per chiave di visualizzazione, trova la riga della vista se esiste, quindi esegui una combinazione di operazioni di inserimento, aggiornamento ed eliminazione sull'indice di visualizzazione, se necessario.
Indipendentemente dalle modifiche apportate alla tabella di base in questo esempio, la vista indicizzata rimarrà sincronizzata correttamente:le query NOEXPAND ed EXPAND VIEWS sopra restituiranno sempre lo stesso set di risultati. È così che le cose dovrebbero sempre funzionare.
Viste indicizzate e aggregazione scalare
Ora prova questo esempio, in cui la vista indicizzata utilizza l'aggregazione scalare (nessuna clausola GROUP BY nella vista):
DROP VIEW dbo.IV;
DROP TABLE dbo.T1;
GO
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); Questa è una vista indicizzata perfettamente legale; non si verificano errori durante la creazione. C'è un indizio che potremmo fare qualcosa di un po' strano, però:quando arriva il momento di materializzare la vista creando l'indice cluster univoco richiesto, non c'è una colonna ovvia da scegliere come chiave. Normalmente, sceglieremmo le colonne di raggruppamento dalla clausola GROUP BY della vista, ovviamente.
Lo script sopra sceglie arbitrariamente la colonna NumRows. Quella scelta non è importante. Sentiti libero di creare l'indice cluster univoco come preferisci. La vista conterrà sempre esattamente una riga a causa degli aggregati scalari, quindi non vi è alcuna possibilità di una violazione della chiave univoca. In tal senso, la scelta della chiave dell'indice di visualizzazione è ridondante, ma comunque obbligatoria.
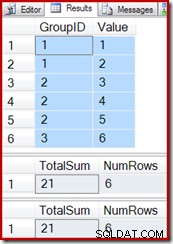
Riutilizzando le query di test dell'esempio precedente, possiamo vedere che la vista indicizzata funziona correttamente:
SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
Anche l'inserimento di una nuova riga nella tabella di base (come abbiamo fatto con la vista indicizzata aggregata vettoriale) continua a funzionare correttamente:
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); Il piano di esecuzione è simile, ma non del tutto identico:
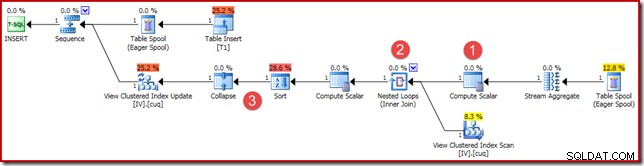
Le differenze principali sono:
- Questo nuovo Compute Scalar è disponibile per le stesse ragioni di quando abbiamo confrontato i risultati dell'aggregazione vettoriale e scalare in precedenza:garantisce che venga restituita una somma NULL (invece di zero) se l'aggregato opera su un set vuoto. Questo è il comportamento richiesto per una somma scalare di nessuna riga.
- L'Outer Join visto in precedenza è stato sostituito da un Inner Join. Ci sarà sempre esattamente una riga nella vista indicizzata (a causa dell'aggregazione scalare), quindi non c'è dubbio che sia necessario un join esterno per verificare se una riga della vista corrisponde o meno. L'unica riga presente nella vista rappresenta sempre l'intero set di dati. Questo Inner Join non ha predicato, quindi tecnicamente è un cross join (a una tabella con una singola riga garantita).
- Gli operatori Ordina e Comprimi sono presenti per motivi tecnici trattati nel mio precedente articolo sulla manutenzione della vista indicizzata. Non influiscono sul corretto funzionamento della manutenzione della vista indicizzata qui.
In effetti, molti diversi tipi di operazioni di modifica dei dati possono essere eseguite con successo sulla tabella di base T1 in questo esempio; gli effetti si rifletteranno correttamente nella vista indicizzata. È possibile eseguire tutte le seguenti operazioni di modifica rispetto alla tabella di base mantenendo corretta la vista indicizzata:
- Elimina le righe esistenti
- Aggiorna le righe esistenti
- Inserisci nuove righe
Potrebbe sembrare un elenco completo, ma non lo è.
Il bug rivelato
Il problema è piuttosto sottile e si riferisce (come dovresti aspettarti) ai diversi comportamenti degli aggregati vettoriali e scalari. I punti chiave sono che un aggregato scalare produrrà sempre una riga di output, anche se non riceve righe in input e la somma scalare di un insieme vuoto è NULL, non zero.
Per causare un problema, tutto ciò che dobbiamo fare è inserire o eliminare nessuna riga nella tabella di base.
Questa affermazione non è così folle come potrebbe sembrare a prima vista.
Il punto è che una query di inserimento o eliminazione che non interessa le righe della tabella di base aggiornerà comunque la vista perché lo Stream Aggregate scalare nella parte di manutenzione della vista indicizzata del piano di query produrrà una riga di output anche quando viene presentata senza input. Il calcolo scalare che segue lo Stream Aggregate genererà anche una somma NULL quando il conteggio delle righe è zero.
Il seguente script mostra il bug in azione:
-- So we can undo BEGIN TRANSACTION; -- Show the starting state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- A table variable intended to hold new base table rows DECLARE @NewRows AS table (GroupID integer NOT NULL, Value integer NOT NULL); -- Insert to the base table (no rows in the table variable!) INSERT dbo.T1 SELECT NR.GroupID,NR.Value FROM @NewRows AS NR; -- Show the final state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Undo the damage ROLLBACK TRANSACTION;
L'output di quello script è mostrato di seguito:
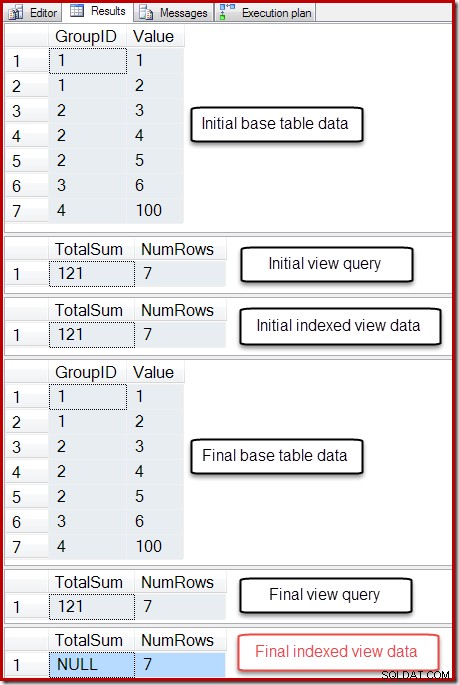
Lo stato finale della colonna Somma totale della vista indicizzata non corrisponde alla query della vista sottostante o ai dati della tabella di base. La somma NULL ha danneggiato la vista, il che può essere confermato eseguendo DBCC CHECKTABLE (nella vista indicizzata).
Di seguito il piano di esecuzione responsabile della corruzione:
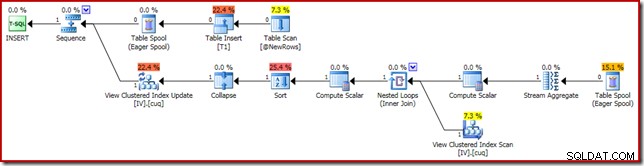
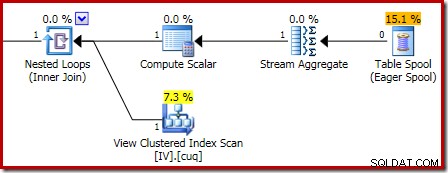
L'ingrandimento mostra l'input di zero righe per Stream Aggregate e l'output di una riga:
Se vuoi provare lo script di corruzione sopra con un'eliminazione invece di un inserimento, ecco un esempio:
-- No rows match this predicate DELETE dbo.T1 WHERE Value BETWEEN 10 AND 50;
L'eliminazione non interessa le righe della tabella di base, ma modifica comunque la colonna della somma della vista indicizzata su NULL.
Generalizzazione del bug
Probabilmente puoi trovare un numero qualsiasi di query di inserimento ed eliminazione della tabella di base che non influiscono su righe e causano questo danneggiamento della vista indicizzata. Tuttavia, lo stesso problema di base si applica a una classe di problemi più ampia rispetto ai semplici inserimenti ed eliminazioni che non interessano le righe della tabella di base.
È possibile, ad esempio, produrre la stessa corruzione utilizzando un inserto che fa aggiungere righe alla tabella di base. L'ingrediente essenziale è che nessuna riga aggiunta deve essere qualificata per la visualizzazione . Ciò comporterà un input vuoto per Stream Aggregate e l'output della riga NULL che causa il danneggiamento dal seguente Compute Scalar.
Un modo per ottenere ciò è includere una clausola WHERE nella vista che rifiuta alcune delle righe della tabella di base:
ALTER VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
-- New!
T1.GroupID BETWEEN 1 AND 3;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); Data la nuova restrizione sugli ID di gruppo inclusi nella vista, il seguente inserto aggiungerà righe alla tabella di base, ma ancora danneggiata la vista indicizzata sarà una somma NULL:
-- So we can undo
BEGIN TRANSACTION;
-- Show the starting state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- The added row does not qualify for the view
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100);
-- Show the final state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- Undo the damage
ROLLBACK TRANSACTION; L'output mostra la corruzione dell'indice ormai familiare:
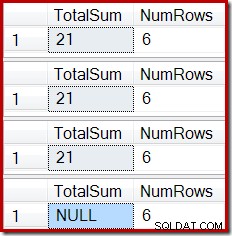
Un effetto simile può essere prodotto utilizzando una vista che contiene uno o più inner join. Finché le righe aggiunte alla tabella di base vengono rifiutate (ad esempio se non si uniscono), Stream Aggregate non riceverà righe, Compute Scalar genererà una somma NULL e la vista indicizzata sarà probabilmente danneggiata.
Pensieri finali
Questo problema non si verifica per le query di aggiornamento (almeno per quanto posso dire) ma sembra essere più per caso che per la progettazione:il problematico Stream Aggregate è ancora presente nei piani di aggiornamento potenzialmente vulnerabili, ma Compute Scalar che genera la somma NULL non viene aggiunta (o forse ottimizzata). Per favore fatemi sapere se riuscite a riprodurre il bug utilizzando una query di aggiornamento.
Fino a quando questo bug non viene corretto (o, forse, gli aggregati scalari non sono consentiti nelle viste indicizzate), fai molta attenzione all'utilizzo di aggregati in una vista indicizzata senza una clausola GROUP BY.
Questo articolo è stato suggerito da un articolo Connect inviato da Vladimir Moldovanenko, che è stato così gentile da lasciare un commento su un mio vecchio post sul blog (che riguarda una diversa corruzione della vista indicizzata causata dalla dichiarazione MERGE). Vladimir utilizzava aggregati scalari in una vista indicizzata per validi motivi, quindi non essere troppo veloce nel giudicare questo bug come un caso limite che non incontrerai mai in un ambiente di produzione! Ringrazio Vladimir per avermi avvisato del suo articolo Connect.